Glove模型笔记
Glove
优点:融合了矩阵分解Latent Semantic Analysis (LSA)的全局统计信息和local context window优势。融入全局的先验统计信息,可以加快模型的训练速度,又可以控制词的相对权重。
模型
词向量模型:
w i T w ~ j + b i + b ~ j = log ( X i j ) w_{i}^{T} \tilde{w}_{j}+b_{i}+\tilde{b}_{j}=\log \left(X_{i j}\right) wiTw~j+bi+b~j=log(Xij)
Loss function:
J = ∑ i , j N f ( X i , j ) ( v i T v j + b i + b j − log ( X i , j ) ) 2 J=\sum_{i, j}^{N} f\left(X_{i, j}\right)\left(v_{i}^{T} v_{j}+b_{i}+b_{j}-\log \left(X_{i, j}\right)\right)^{2} J=i,j∑Nf(Xi,j)(viTvj+bi+bj−log(Xi,j))2
原理
共现矩阵
共现矩阵为 X X X,其中的元素为 X i , j X_{i,j} Xi,j,表示词汇 j j j出现在词汇 i i i上下文中的次数总和,这个 j j j由两个单词的上下文窗口距离决定
X i X_i Xi表示出现在 i i i上下文的所有词汇的总数。然后** P i j = X i j X i = P ( j ∣ i ) P_{ij}=\frac{X_{ij}}{X_i}=P(j|i) Pij=XiXij=P(j∣i)**表示词汇 j j j出现的词汇 i i i上下文的概率
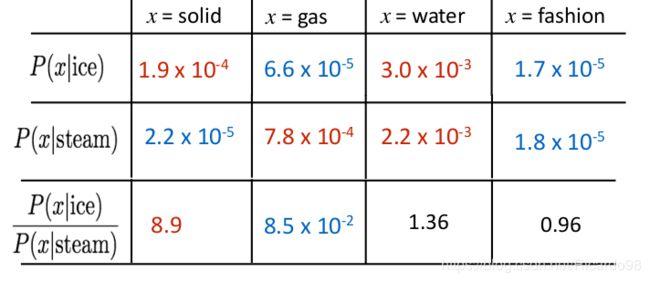

这个比率能够更好地区分相关词(solid 和 gas)与不相关词(ice和fashion),并且还能够更好地区分(discriminate)两个相关词。ratio取决于三个单词 i , j , k i,j,k i,j,k。
构建词向量
先假设有一个词向量模型可以代表这个比例
F ( w i , w j , w ~ k ) = P i k P j k F\left(w_{i}, w_{j}, \tilde{w}_{k}\right)=\frac{P_{i k}}{P_{j k}} F(wi,wj,w~k)=PjkPik
其中 w ∈ R d w\in R^d w∈Rd是词向量, w ^ k \hat{w}_k w^k是单独的上下文词向量。等式右侧是从预料库中获得
如何确定函数F呢。首先由于向量空间本质上是线性的,并且我们希望F能够在词向量空间中呈现上面说的比率信息(相似性)。而用向量差异是最自然的方法。于是可以得到
F ( w i − w j , w ~ k ) = P i k P j k F\left(w_{i}-w_{j}, \tilde{w}_{k}\right)=\frac{P_{i k}}{P_{j k}} F(wi−wj,w~k)=PjkPik
然后可以看到左边F的参数是向量,右边是标量,为了使得F的结果也是标量,所以F的参数可以采用内积的形式
于是有
F ( ( w i − w j ) T w ~ k ) = P i k P j k F\left(\left(w_{i}-w_{j}\right)^{T} \tilde{w}_{k}\right)=\frac{P_{i k}}{P_{j k}} F((wi−wj)Tw~k)=PjkPik
再然后,因为在共现矩阵中,可以任意划分为中心词或上下文单词,所以要保证 w ↔ w ~ w \leftrightarrow \tilde{w} w↔w~和 X ↔ X T X \leftrightarrow X^{T} X↔XT的时候模型保持对称性。于是有
F ( ( w i − w j ) T w ~ k ) = F ( w i T w ~ k ) F ( w j T w ~ k ) F\left(\left(w_{i}-w_{j}\right)^{T} \tilde{w}_{k}\right)=\frac{F\left(w_{i}^{T} \tilde{w}_{k}\right)}{F\left(w_{j}^{T} \tilde{w}_{k}\right)} F((wi−wj)Tw~k)=F(wjTw~k)F(wiTw~k)
其中
F ( w i T w ~ k ) = P i k = X i k X i F\left(w_{i}^{T} \tilde{w}_{k}\right)=P_{i k}=\frac{X_{i k}}{X_{i}} F(wiTw~k)=Pik=XiXik
由上面的式子,可以得到F(x)要等于exp(x)才满足条件,所以可以知道F=exp
于是有
w i T w ~ k = log ( P i k ) = log ( X i k ) − log ( X i ) w_{i}^{T} \tilde{w}_{k}=\log \left(P_{i k}\right)=\log \left(X_{i k}\right)-\log \left(X_{i}\right) wiTw~k=log(Pik)=log(Xik)−log(Xi)
有 l o g ( X i ) log(X_i) log(Xi)在,左边有对称性,但是右边没有, w i T w k = w k T w i w^T_iw_k=w_k^Tw_i wiTwk=wkTwi但是 l o g ( P i k ) 不 等 于 l o g ( P k i ) log(P_{ik})不等于log(P_{ki}) log(Pik)不等于log(Pki)。又因为 l o g ( X i ) log(X_i) log(Xi)独立于k,所以让 w i w_i wi吸收掉 l o g ( X i ) log(X_i) log(Xi)作为偏置项 b i b_i bi
再添加一个偏置项给 b k ~ \tilde{b_k} bk~给 w k w_k wk保持对称性。
于是有
l o g ( X i , j ) = w i T w j ~ + b i + b j ~ log(X_{i,j})= w^T_i\tilde{w_j}+b_i+\tilde{b_j} log(Xi,j)=wiTwj~+bi+bj~
于是代价函数如下:
最小二乘
J = ∑ i , j = 1 V ( w i T w j ~ + b i + b j ~ − l o g X i j ) 2 J=\sum\limits_{i,j=1}^V (w^T_i\tilde{w_j}+b_i+\tilde{b_j}-logX_{ij})^2 J=i,j=1∑V(wiTwj~+bi+bj~−logXij)2
其中V是单词的总个数。但是上述目标函数还有一个问题,就是无论单词i和单词k之间出现的频率多少,都作为一个样本进行训练。那么对于那么单词i和单词k之间不常见的组合,或偶尔出现的组合,也进行拟合,其实这些拟合的是一些噪声,这显然不利于模型的鲁棒性/健壮性(robust)。怎么办呢?最简单的办法就来了,让那些出现次数较少的组合权重低一些。
于是最后有了
J = ∑ i , j = 1 V f ( X i j ) ( w i T w j ~ + b i + b j ~ − l o g X i j ) 2 J=\sum\limits_{i,j=1}^V f(X_{ij})(w^T_i\tilde{w_j}+b_i+\tilde{b_j}-logX_{ij})^2 J=i,j=1∑Vf(Xij)(wiTwj~+bi+bj~−logXij)2
而权重函数应该满足
-
f(0)=0f(0)=0。
-
f(x)递增,以保证罕见的组合不会给与过多的权重。
-
对于较大的x值,f(X)应该比较小,以保证频繁出现的组合不会给过多的权重。
根据原则可得到如下函数:
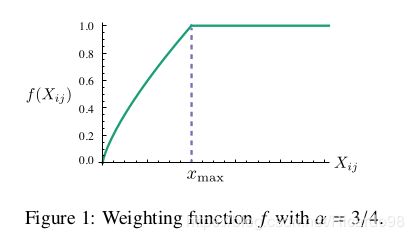
f ( x ) = { ( x / x max ) α if x < x max 1 otherwise f(x)=\left\{\begin{array}{cc} \left(x / x_{\max }\right)^{\alpha} & \text { if } x
论文作者的实验结果:
待解决问题:homomorphism
https://www.zhihu.com/search?type=content&q=glove%E5%90%8C%E6%80%81
对比word2vec
本质是count based 对比 prediction

参考资料
理解GloVe模型
GloVe和word2vec
川陀学者