利用聚类分析分离验证码图片的字符并识别
本文识别的验证码来源于http://www.miitbeian.gov.cn/getVerifyCode?80,类型如下:



由于这些验证码的不同的字符大部分的色彩差异比较大,所以就试着对这些验证码进行kmeans聚类同时做一些简单的干扰线清除可得到如下结果:
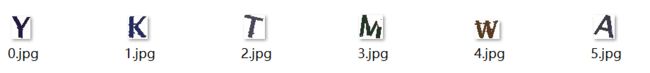

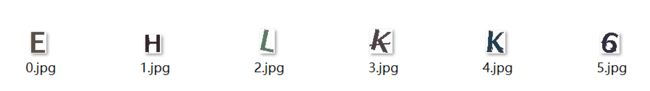
最后在利用简单训练的卷积神经网络进行识别,准确率大概在45%左右,可以往模型中加点噪声,还需要改进!!!
图片分离部分:
1,根据聚类分离图片
在进行kmeans聚类之前需要对原始图图片进行平滑处理,因为在验证码中基本每个字符都会有一些噪声点,这里用了双边滤波去除噪声
im = cv2.imread(self.filename)
blur = cv2.bilateralFilter(im,9,75,75) # 双边滤波去除噪声
由于有6个字符和一种背景色,所以用了7个质心进行聚类,重建得到7个图 
2,删除背景图,
我们用一个框包住图片,框外面都是白色,会发现背景图的框肯定是最大的,而且基本就是原始的框大小,如上图0.jpg
3,图片进一步切割
我们会发现有些字符之间的由于颜色接近会被分到一块,所以需要进行水平切割,同时也对图片进行取框,找到一个刚刚好包住图片的框,同时如果这个框太小了,基本上可以肯定不是字符直接删除

比如上图的0.jpg,8和N就被分到一块,水平扫描图片,根据是否为255确定图像的位置,分离出图像
4,删除为干扰线的图
由于如果框里面如果是干扰线的,那么里面大部分是白色的255,所以里面的均值也是正常字符的大,保留前面最小的6个
im_sort = sorted(self.im_dict,key=lambda k:np.mean(self.im_dict[k][1]))
new_key = im_sort[6:]
for key in new_key:
self.im_dict.pop(key)
5,删除图中的干扰线

得到图可能是这个样子,由于用于自己生成的样本都比较规范,所以对于这种图,神经网络预测不出来,所以需要进一步把A上面的那条干扰线去掉,先把图片转成二值图,去除干扰线主要利用一个3X3的卷积核,对每个像素点的8领域进行探测,如果8个领域包括自己本身跟卷积核的卷积值全部都大于一个255则把这个块区域判断为白色的,最后就可以得到

然后就可以保存用于预测
训练权重部分:
1,首先是生成样本图
由于opencv的字体比较少,所以同时利用PIL作图,对得出来的进行正负25°偏移
2,训练样本
利用卷积神经网络映射到128通道,添加drop层,最后保存sess权重
完整代码:
验证码分离并预测image_predict.py:
import numpy as np
from sklearn.cluster import KMeans
import cv2
from sklearn import metrics
from scipy.spatial.distance import cdist
from generate_alphabet import *
import copy
import os
from optparse import OptionParser
import tensorflow as tf
from train import *
from img_process2 import *
import shutil
class ImagePredict:
sess = tf.Session()
result = None
x = None
def __init__(self):
self.option = None
self.parser_options()
if ImagePredict.result is None:
self.reload_model()
def reload_model(self):
new_saver = tf.train.import_meta_graph(os.path.join(self.option.modeldir,'model.ckpt.meta'))
new_saver.restore(ImagePredict.sess, os.path.join(self.option.modeldir, "model.ckpt"))
ImagePredict.result = tf.get_collection('result')[0]
graph = tf.get_default_graph()
ImagePredict.x = graph.get_operation_by_name('input_x').outputs[0]
# rr = sess.run(result, feed_dict={x: arr})
def parser_options(self):
optParser = OptionParser()
optParser.add_option('-m',"--modeldir",default=r'D:\pthon_learn\kmeans\mode',
help="Special model sess directory")
self.option, args = optParser.parse_args()
# 对图片进行像素聚类切割
def split(self):
im = cv2.imread(self.filename)
blur = cv2.bilateralFilter(im,9,75,75) # 双边滤波去除噪声
#cv2.imshow("code",im)
h,w,d = im.shape
self.w = w # 原图像的宽
X = blur.reshape(-1,3)
k = 7
k_model = KMeans(n_clusters=k).fit(X)
#根据聚类的结果重建图像
self.x_dict = {}
for label in range(7):
x1 = np.ones(X.shape) * 255
x1[np.nonzero(k_model.labels_ == label)] = X[np.nonzero(k_model.labels_ == label)]
xx = x1.reshape(h,w,d)
self.x_dict[label] = xx
# cv2.imwrite(str(label)+'.jpg',xx)
# 去掉背景图片
# 最多不为255的高和宽都是原图的为背景色或者高和宽和原图一样
def drop_back(self):
value = -1
index = -1
for i in range(7):
im = self.x_dict[i]
im_mean = np.mean(im,axis=2)
sp_left,sp_right,sz_up,sz_down = self.get_box(im_mean)
h_w = (sp_right-sp_left)*(sz_down - sz_up)
if value < h_w:
value = h_w
index = i
back = self.x_dict.pop(index)
# cv2.imwrite('back.jpg',back)
@staticmethod
def calc_sp_long(im):
ii = np.mean(np.mean(im,axis=0),axis=1)
ll = len(ii[np.nonzero(ii != 255)])
return ll
# 去除干扰线后对图片里面的元素进行排序
# 有些是需要切分的,则进行切分
# 根据水平均值特征进行切分
# 同时纪录下水平的第一个不为255的索引用来排序
def get_index(self,im):
# xx = np.mean(np.mean(im,axis=0),axis=1)
xx = np.mean(np.mean(im,axis=2),axis=0)
xx = np.append(xx,255)
im_dict = {} # 里面包含索引和图像
start = -1
end = -1
for i in range(len(xx)):
if xx[i] < 255 and start == -1:
start = i - 1
if xx[i] == 255 and end == -1 and start != -1:
end = i + 1
if end-start <= 8:
pass
else:
tmp_im = im[:,start:end+1,:]
im_dict[start] = [start,tmp_im]
start = -1
end = -1
return im_dict
def clean_im_(self,im):
mm = copy.copy(im)
mm = mm.astype('uint8')
gray = cv2.cvtColor(mm, cv2.COLOR_RGB2GRAY)
iim = cv2.adaptiveThreshold(gray, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 25, 10)
ii = del_noise(iim,1)
sp_left,sp_right,sz_up,sz_down = self.get_box(ii)
sp_left = sp_left - 3 if sp_left >= 3 else 0
sp_right = sp_right + 3 #if sp_right != None else None
sz_up = sz_up - 3 if sz_up >= 3 else 0
sz_down = sz_down + 3 #if sz_down != None else None
return im[sz_up:sz_down,sp_left:sp_right,:],sp_left
@staticmethod
#获取框,用于还原图片
def get_box(im):
# 水平均值为
sp_mean = np.mean(im,axis=0)
h,w = im.shape
# 竖直均值
sz_mean = np.mean(im,axis=1)
sp_left = 0 # 用于左边探测
sp_right = w # 用于右边探测
sz_up = 0 # 用于上边探测
sz_down = h # 用于下边探测
for i in range(w):
if sp_mean[i] < 255:
sp_left = i
break
for i in range(1,w):
if sp_mean[-i] < 255:
sp_right = w -i + 1
break
for i in range(h):
if sz_mean[i] < 255:
sz_up = i
break
for i in range(1,h):
if sz_mean[-i] < 255:
sz_down = h - i + 1
break
return sp_left,sp_right,sz_up,sz_down
# 对得出来的图像字典进行精细切分得出最后的字母数字
def spilt_image(self):
self.im_dict = {}
for k in self.x_dict.keys():
tmp_im_dict = self.get_index(self.x_dict[k])
self.im_dict.update(tmp_im_dict)
# 把图片的上下空白去掉保留一个255像素
@staticmethod
def drop_blank(im):
xx = np.mean(np.mean(im,axis=2),1)
start = -1
end = -1
for i in range(len(xx)):
if xx[i] < 255:
start = i
break
for i in range(1,len(xx)):
if xx[-i] < 255:
end = len(xx) - i + 1
break
return im[start:end+1,:,:]
# 对im_dict里面的图片根据均值进行排序,均值越大越有可能是干扰线,保留前面6个
# 先根据图像的高度和宽度判断是否可能是干扰线
def drop_disturb_line(self):
for k in list(self.im_dict.keys()):
h,w,_ = self.im_dict[k][1].shape
if h <= 15 or w <= 8:
self.im_dict.pop(k)
im_sort = sorted(self.im_dict,key=lambda k:np.mean(self.im_dict[k][1]))
new_key = im_sort[6:]
for key in new_key:
self.im_dict.pop(key)
# 由于有些最后的元素中带有干扰线
# 所以需要利用卷积核去除干扰线
def clean_im_line(self):
for k in list(self.im_dict.keys()):
im,sp_left = self.clean_im_(self.im_dict[k][1])
# im = self.clean_im_(im)
# self.im_dict[k][1] = im
self.im_dict.pop(k)
self.im_dict[k+sp_left] = [k+sp_left,im]
# 保存图片
# 创建路径
def save_image(self):
pwd = os.getcwd()
newfile = os.path.splitext(self.filename)[0]
os.mkdir(newfile)
self.fd = os.path.join(pwd, newfile)
for i,k in enumerate(sorted(self.im_dict.keys())):
fn = os.path.join(self.fd,str(i)+'.jpg')
mm = self.drop_blank(self.im_dict[k][1])
cv2.imwrite(fn,mm)
# 数据处理,把切分得到的图像转化为二值图
def get_image(self):
alphabet_list = []
for i in range(6):
filename = os.path.join(self.fd,str(i)+'.jpg')
im = cv2.imread(filename)
gray = cv2.cvtColor(im, cv2.COLOR_RGB2GRAY)
im = cv2.adaptiveThreshold(gray, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 25, 10)
h, w = im.shape
ii = cv2.resize(im, (30, 30))
dilation = ii / 255.
alphabet_list.append(dilation)
alphabet_list = np.array(alphabet_list)
alphabet_arr = alphabet_list[:, :, :, np.newaxis]
return alphabet_arr
# 判断是否加载模型并预测
def predict_(self):
arr = self.get_image()
rr = self.sess.run(self.result, feed_dict={self.x: arr})
rr = np.argmax(rr, axis=1)
string = ''
for i in rr:
# print(ch_dict_T[i])
string += ch_dict_T[i]
print(string)
return string
def predict(self,filename='ccc.jpg'):
self.filename = filename
self.split() # 根据聚类分离图片
self.drop_back() # 删除背景图
self.spilt_image() # 图像进一步切分
self.drop_disturb_line() # 删除为干扰线的图
self.clean_im_line() # 删除图中的干扰线
self.save_image() # 保存用于预测
code = self.predict_()
shutil.rmtree(self.fd)
return code
if __name__ == '__main__':
app = ImagePredict()
app.predict('PC6881.jpg')
干扰线清除img_process2.py:
import cv2
import numpy as np
import tensorflow as tf
import os
from collections import Counter
import copy
def del_noise(binary,thresh=1):
conv_filter = np.ones((3,3))
nextbinary = copy.copy(binary)
for i in range(1,binary.shape[0]-1-3):
for j in range(1,binary.shape[1]-1-3):
# 当前区域
area = binary[i:i+3,j:j+3]
ff = np.sum(conv_filter * area / 255)
# 右上一个
area_1 = binary[i-1:i-1+3,j+1:j+1+3]
ff_1 = np.sum(conv_filter * area_1 / 255)
# 右下一个
area_2 = binary[i+1:i+1+3,j+1:j+1+3]
ff_2 = np.sum(conv_filter * area_2 / 255)
# 往右一个
area_3 = binary[i:i+3,j+1:j+1+3]
ff_3 = np.sum(conv_filter * area_3 / 255)
# 往下一个
area_4 = binary[i+1:i+1+3,j:j+3]
ff_4 = np.sum(conv_filter * area_4 / 255)
# 左上一个
area_5 = binary[i-1:i-1+3,j-1:j-1+3]
ff_5 = np.sum(conv_filter * area_5 / 255)
# 左下一个
area_6 = binary[i+1:i+1+3,j-1:j-1+3]
ff_6 = np.sum(conv_filter * area_6 / 255)
# 往左一个
area_7 = binary[i:i+3,j-1:j-1+3]
ff_7 = np.sum(conv_filter * area_7 / 255)
if ff >= thresh and ff_1 >= thresh and ff_2 >= thresh and ff_3 >= thresh and ff_4 >= thresh \
and ff_5 >= thresh and ff_6 >= thresh and ff_7 >= thresh:
nextbinary[i:i+3,j:j+3] = 255
return nextbinary
验证码生成generate_alphabet.py
import numpy as np
import cv2
from PIL import Image,ImageDraw,ImageFont
np.random.seed(12)
chr_list = [chr(i) for i in range(65,91)]
digist_list = [chr(i) for i in range(48,58)]
ch_list = chr_list + digist_list
ch_dict = dict(zip(ch_list,range(len(ch_list))))
ch_dict_T = dict(zip(range(len(ch_list)),ch_list))
font_list = [
cv2.FONT_HERSHEY_DUPLEX,
cv2.FONT_HERSHEY_PLAIN,
cv2.FONT_HERSHEY_SIMPLEX,
# cv2.FONT_HERSHEY_TRIPLEX,
cv2.FONT_ITALIC,
]
def generate(ch):
angle = np.random.uniform(-25,25)
imm = np.zeros((30,30)) + 255
cv2.putText(imm,ch,(2,25),np.random.choice(font_list),1.1,0,2,cv2.LINE_AA)
rows,cols=imm.shape
M=cv2.getRotationMatrix2D((cols/2,rows/2),angle,1)
dst=cv2.warpAffine(imm,M,(cols,rows),borderValue=255)
# 配合样本的格式,需调整成统一格式
# 先剔除两边为255的然后在平均补上
# 先剔除上空白
sp_mean = np.mean(dst,axis=0)
sz_mean = np.mean(dst,axis=1)
sp_start = -1
sp_end = -1
sz_start = -1
sz_end = -1
for i in range(len(sp_mean)):
if sp_mean[i] <255:
sp_start = i
break
for i in range(1,len(sp_mean)):
if sp_mean[-i] < 255:
sp_end = len(sp_mean) -i + 1
break
for j in range(len(sz_mean)):
if sz_mean[j] < 255:
sz_start = j
break
for j in range(1,len(sz_mean)):
if sz_mean[-j] < 255:
sz_end = len(sz_mean) - j + 1
break
dd = dst[sz_start:sz_end+1,sp_start:sp_end+1]
dst = cv2.resize(dd,(30,30))
dst = dst.astype('uint8')
return dst
def generate2(ch='W'):
font_list = [
ImageFont.truetype(r'C:\Windows\Fonts\ARIALN.TTF',40),
ImageFont.truetype(r'C:/Windows/Fonts/ARLRDBD.TTF',40),
ImageFont.truetype(r'C:/Windows/Fonts/ARIBLK.TTF',40),
ImageFont.truetype(r'C:/Windows/Fonts/MSYHBD.TTC',40),
ImageFont.truetype(r'C:/Windows/Fonts/MSYH.TTC',40)
]
arr = np.ones((40,40)) + 255.
im = Image.fromarray(arr)
draw = ImageDraw.Draw(im)
draw.text((3,-8),ch, fill=0,font=np.random.choice(font_list))
arr = np.array(im) - 1
arr[np.nonzero(arr == -1)] = 0
angle = np.random.uniform(-25,25)
# angle = 25
rows,cols=arr.shape
M=cv2.getRotationMatrix2D((cols/2,rows/2),angle,1)
dst=cv2.warpAffine(arr,M,(cols,rows),borderValue=255)
sp_mean = np.mean(dst,axis=0)
sz_mean = np.mean(dst,axis=1)
sp_start = -1
sp_end = -1
sz_start = -1
sz_end = -1
for i in range(len(sp_mean)):
if sp_mean[i] <255:
sp_start = i
break
for i in range(1,len(sp_mean)):
if sp_mean[-i] < 255:
sp_end = len(sp_mean) -i + 1
break
for j in range(len(sz_mean)):
if sz_mean[j] < 255:
sz_start = j
break
for j in range(1,len(sz_mean)):
if sz_mean[-j] < 255:
sz_end = len(sz_mean) - j + 1
break
dd = dst[sz_start:sz_end+1,sp_start:sp_end+1]
dst = cv2.resize(dd,(30,30))
dst = dst.astype('uint8')
return dst
def get_batch_data(batch_size):
X = np.zeros((1,900))
label = []
n = -1
for _ in range(batch_size):
ch = np.random.choice(ch_list)
if n == -1:
dst = generate2(ch)
else:
dst = generate(ch)
dst = dst.reshape(1,-1)
X = np.concatenate((X,dst),axis=0)
label.append(ch)
n = -n
return X[1:],label
验证码训练train.py
import tensorflow as tf
import numpy as np
import os
import cv2
from generate_alphabet import *
def get_data(batch_size=32):
x,label = get_batch_data(batch_size)
x = x.reshape(-1,30,30,1) / 255.
yy = np.zeros((batch_size,36))
for i in range(batch_size):
yy[i,int(ch_dict[label[i]])] = 1
return x,yy.astype(float)
def init_xy():
x =tf.placeholder(shape=[None,30,30,1],dtype=tf.float32,name='input_x')
y = tf.placeholder(shape=[None,36],dtype=tf.float32)
return x,y
def w_b(shape):
initial = tf.truncated_normal(shape, stddev=0.05)
w = tf.Variable(initial,dtype=tf.float32)
initial = tf.constant(0.)
b = tf.Variable(initial,dtype=tf.float32)
return w,b
def conv2d(x,w,b):
with tf.variable_scope("conv2d"):
conv = tf.nn.conv2d(x, w, strides=[1, 1, 1, 1], padding='SAME')
return tf.nn.relu(conv+b)
def maxpool2d(x):
with tf.variable_scope('maxpool2d'):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='SAME')
def fp(x,w,b):
with tf.variable_scope("fp"):
down = tf.matmul(x,w) + b
return tf.nn.softmax(down)
def build_net():
x,y = init_xy()
w_c1,b_c1 = w_b(shape=[5,5,1,32])
conv1 = conv2d(x,w_c1,b_c1)
pool1 = maxpool2d(conv1)
w_c2,b_c2 = w_b(shape=[3,3,32,64])
conv2 = conv2d(pool1,w_c2,b_c2)
pool2 = maxpool2d(conv2)
w_c3,b_c3 = w_b(shape=[3,3,64,128])
conv3 = conv2d(pool2,w_c3,b_c3)
pool3 = maxpool2d(conv3)
flat = tf.reshape(pool3, [-1, 4*4*128])
h_fc1_drop = tf.nn.dropout(flat, 0.6)
w,b = w_b(shape=[4*4*128,36])
result = fp(h_fc1_drop,w,b)
return x,y,result
if __name__ == '__main__':
x,y,result = build_net()
sess = tf.Session()
saver = tf.train.Saver()
tf.add_to_collection('result', result)
init = tf.global_variables_initializer()
sess.run(init)
loss = -tf.reduce_sum(y*tf.log(result))
train_step = tf.train.GradientDescentOptimizer(1e-3).minimize(loss)
correct_prediction = tf.equal(tf.argmax(result,1), tf.argmax(y,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
for i in range(10000):
tmp_x,tmp_y = get_data(batch_size=64)
sess.run(train_step,feed_dict={x:tmp_x,y:tmp_y})
if i % 100 == 0:
acc = sess.run(accuracy,feed_dict={x:tmp_x,y:tmp_y})
print('iter:',i,'acc:',acc)
if acc > 0.98:
break
saver.save(sess,"mode/model.ckpt")