特殊的表dual
dual是一个虚拟表,用来构成select的语法规则,oracle保证dual里面永远只有一条记录。
个人感觉这个可以理解为经过特殊处理的内部表,每个数据库都可以直接使用不报错,常用来做一些用户查询,以及像是sysdate时间测试,等等,更加方便。这里百度百科的解释百度百科Oracle的dual表
数据库sql语句的划分
数据检索语言:select
数据操作语言DML:insert delete update
数据定义语言DDL:create alter drop rename turncate
事务控制语言:commit rollback savepoint
数据控制语言DCL:grant revoke
注意:数据的提交涉及到数据库的“锁”,这部分内容以后再深入研究。
DML语言,比如update,delete,insert等修改表中数据的需要commit;
DDL语言,比如create,drop等改变表结构的,就不需要写commit(因为内部隐藏了commit)
零碎的点:
null值:不是空的字符串,也不是0,而是一种标记,用于表示没有数据,涉及到计算时通常用,nvl(空值部分,替换值)函数对null值进行替换。
查询员工名字以及加提成后的薪水(有些员工没有提成)
eg:select name, salary+salary*nvl(commission_pct,0) from s_emp;
注意:nvl函数使用时,表示字符串和时间类型值时要用单引号。
eg:select last_name,nvl(title,’sale’) from s_emp;
eg:select last_name,nvl(start_date,’05-4月-08’) from s_emp;
sql语句的拼接单引号问题
如果列拼接的过程中间需要输入特殊字符或字符串用单引号引起来
eg:select last_name||‘.’||firstname name from s_emp;
如果拼接的内容有单引号,单引号自身是自身的转义
eg:select last_name||'''s salary is :'||salary from s_emp;
如果再jdbc以及其他情境下需要构造拼接语句,一般需要借助双引号完成拼接。个人感觉可以理解为''单引号对是这个sql语句本身需要的,""双引号对是函数执行时需要的(可能这种理解还不够精准深入,后续再补充更新)。尤其是在jdbc中,构造设计到单引号的语句时可以这样处理:
先把原语句写出来,保证能正确执行,然后在需要相应字段的值时可以把原数据用 "++" 替换,要拼接的值写在加号中间。
eg:通过jdbc向数据库s_tea表中插入数据,id、name、age的值均来自函数变量。
处理前暂称为实体sql语句为
insert into s_tea values(1,'lisi',33)
将原数据均用"++"替换,在加号中间放变量名。
String sql="insert into s_tea values("+id+",'"+name+"',"+age+")";
like模糊查询遇到特殊符号需要转义
_表示占位,占位一个字符
%表示占位,0~多个字符
escape '' 单引号内指定作为转义符的字符
like模糊匹配的时候如遇到特殊符号,需要转义,转义可以是任意的字符,通过escape,指定转义符。通常都是指定 \ 为转义符,当然如果指定a或者其他任何字符都是可以的。
如:查询名字中第一个字母为_的员工信息
select id,last_name
from s_emp
where last_name like ‘\_%’ escape ‘\’;
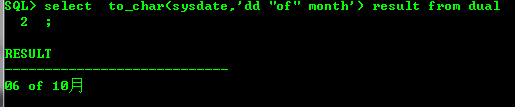
时间转换为字符串过程中,如果格式中有特定的单词符号等,要用双引号括起来
eg:select to_char(sysdate,'dd" of "month') from dual
结果为:
多表查询笛卡尔积的理解
笛卡尔积相当于把两个表所有数据展示出来,一般通过where条件,将两表连接,将符合要求的数据取出来。
如,s_emp是员工表,维护了id、name、dept_id(部门编号,用于跟部门表连接),s_dept是部门表,维护了id、name、region_id(地区编号,用于跟地区表连接)。
通过where s_emp.dept_id=s_dept.id条件即可取出相对应的数据。(对表起别名,方便书写)
eg:
select s.id,s.name,d.id
from s_emp s,s_dept d
where s.dept_id=d.id
等值连接、非等值连接、外连接
等值链接:基于主外键获取两张表相关联的数据
eg:如上
非等值链接:把两张没有关联关系的表基于表中的列建立关系
eg:
先建rank表,表示薪资等级
create table rank(
id number primary key,
name varchar2(6),
minsal number,
maxsal number
);
insert into rank values(1,’白领’,0,1000);
insert into rank values(2,’蓝领’,1001,2000);
insert into rank values(3,’金领’,2001,3000);
查看员工所属薪资水平及部门名称
select s.last_name,d.name,s.salary,r.name
from s_emp s,rank r,s_dept d
where s.salary between r.minsal and r.maxsal
and s.dept_id=d.id
自连接:想象自身作为另一张表,使用方法普通查询一样。
eg:查询员工名字及其对应的经理名字。(员工表中有员工id和manager_id)
select e.id,e.last_name,m.last_name
from s_emp e,s_emp m
where e.manager_id=m.id;
外连接:左外连接(可理解为把左表中未匹配的数据也展示出来,加号在右)和右外连接(相反),初学时这里不是很好理解,尤其是+号放的位置。总结了一下
看英文的描述貌似更准确直观
use an outer join to see rows that do not normally meet the hion condition
outer jion operator is the plus sign (+)
place the operator on the side of the join where there is no value to join to
也就是说,+号放在的表是没有数据与另一个表相应位置数据对应的表。即,哪边数据少,放哪边。
eg:
左外连接:
select s.id,s.last_name,d.id
from s_emp s,s_dept d;
where s.dept_id=d.id(+)
结果
id last_name dept_id(fk) id name
2 Jake 3 3 kk
1 tom 2 2 yy
3 test
等价
select s.id,s.last_name,d.id
from s_emp s left outer join s_dept d;
on s.dept_id=d.id
注意:left前面的是主表
outer可以省略
右外连接:
select s.id,s.last_name,d.id
from s_emp s,s_dept d;
where s.dept_id(+)=d.id
结果
id last_name dept_id(fk) id name
2 Jake 3 3 kk
1 tom 2 2 yy
5 test_r
等价
select s.id,s.last_name,d.id
from s_emp s right outer join s_dept d;
on s.dept_id=d.id
全链接:在等值链接的基础之上,展示主表和从表没有匹配的数据
select s.id,s.last_name,d.id
from s_emp s full outer join s_dept d;
on s.dept_id=d.id
等价写法:
select s.id,s.last_name,d.id
from s_emp s,s_dept d;
where s.dept_id(+)=d.id
union
select s.id,s.last_name,d.id
from s_emp s,s_dept d;
where s.dept_id=d.id(+)
id last_name dept_id(fk) id name
2 Jake 3 3 kk
1 tom 2 2 yy
3 test
5 test_r
组函数
组函数:对数据库中的表进行分组,分完组之后,每组给出一个结果(一行)
group by 基于某列或某几列对表进行分组,分完组之后给出一行结果,分组的标准该列值相同的
归位一组
having 对group by 分组之后的结果一行一行的过滤用的,having可以不出现,一旦出现只能在group by的后面
语法:
select
from table_name…
where 条件语句(对from查询的结果处理)
group by column_name…
having 条件语句(对group by 分组的结果处理)
order by column_name [asc|desc]...
执行的流程: from->where->group by->having->select->order by
注意:group by在where后面执行,所有分组
函数不能出现where中
group by 后面出现的列可以出现在select
后面,也可以不出现,但是select后面出现的列
一定要出现在group by后面
分组函数 select having order by
子查询:思想——一张表的结果作为另一张表查询的条件(心中有表)
这里结合案例练习巩固:
嵌套查询(一个查询的结果是另外一个查询的条件...)
查询工资比Simth工资高的员工信息
1.查询Simth的工资
select salary
from s_emp
where last_name=‘Simth’;
2.工资比Simth工资高的员工信息
select last_name,salary
from s_emp
where salary>()
3组装
select last_name,salary
from s_emp
where salary>(select salary
from s_emp
where last_name=‘Simth’);
查询平均工资比 41号部门的平均工资高
的部门中员工的信息
1.查询41号部门的平均工资
select avg(salary)
from s_emp
where dept_id=41;
2.平均工资比 41号部门的平均工资高
的部门
select dept_id
from s_emp
group by dept_id
having avg(salary)>()
3.查询各个部门的员工信息
select last_name,salary
from s_emp
where dept_id in()
4整合:
select last_name,salary
from s_emp
where dept_id in(select dept_id
from s_emp
group by dept_id
having avg(salary)>(select avg(salary)
from s_emp
where dept_id=41))
查询平均工资比1247.5高的部门中员工信息
1.平均工资比 41号部门的平均工资高
的部门
select dept_id
from s_emp
group by dept_id
having avg(salary)>1247.5
2.查询各个部门的员工信息
select last_name,salary
from s_emp
where dept_id in()
3整合
select last_name,salary
from s_emp
where dept_id in(select dept_id
from s_emp
group by dept_id
having avg(salary)>1247.5)
案列(查询得到结果可以看作一张表)
查询平均工资比 41号部门的平均工资
高的部门中员工的信息,并且显示出当
前部门的平均工资
1.41号部门的平均工资
select avg(salary)
from s_emp
where dept_id=41;
2.平均工资比 41号部门的平均工资高
的部门
select dept_id,avg(salary) avg
from s_emp
group by dept_id
having avg(salary)>()
3,员工信息及平均工资
select s.last_name,s.salary,m.avg
from s_emp s,() m
where s.dept_id=m.dept_id
4整合
select s.last_name,s.salary,m.avg
from s_emp s,(select dept_id,avg(salary) avg
from s_emp
group by dept_id
having avg(salary)>(select avg(salary)
from s_emp
where dept_id=41)) m
where s.dept_id=m.dept_id
查询平均工资比 41号部门的平均工资 高的
部门中员工的信息,并且显示出当前部门的平
均工资,同时显示出部门的名字
1.41号部门的平均工资
select avg(salary)
from s_emp
where dept_id=41;
2.平均工资比 41号部门的平均工资高
的部门
select dept_id,avg(salary) avg
from s_emp
group by dept_id
having avg(salary)>()
3,员工信息及平均工资,部门名字
select s.last_name,s.salary,m.avg,d.name
from s_emp s,() m,s_dept d
where s.dept_id=m.dept_id
and d.id=s.dept_id
4,整合
查询员工信息,这些员工的工资要比自己
所在部门的平均工资高
1.查询所有部门的平均工资
select avg(salary) avg,dept_id
from s_emp
group by dept_id
2.查询比自己部门工资高的员工
(如何确定是某一组)
select s.last_name,s.salary,m.avg
from s_emp s,() m
where s.dept_id=m.dept_id
s.salary>m.avg
整合
查询员工信息,这些员工的工资要比自己
所在部门的平均工资高,同时显示部门的
名称以及所在地区
1.查询所有部门的平均工资
select avg(salary) avg,dept_id
from s_emp
group by dept_id
2.查询比自己部门工资高的员工
(如何确定是某一组)
select s.last_name,s.salary,m.avg
from s_emp s,() m
where s.dept_id=m.dept_id
s.salary>m.avg
3.部门名字及区域
select s.last_name,s.salary,m.avg,d.name,r.name
from s_emp s,() m,s_dept d,s_region r
where s.dept_id=m.dept_id
s.salary>m.avg
s.dept_id=d.id and d.region_id=r.id
查询工资比 Ngao所在部门平均工资 要高的
员工信息,同时这个员工所在部门的平均工资
也要比Ngao所在部门的平均工资要高,
显示当前部门的平均工资以及部门的名字和
所在地区
1.查询Ngao所在部门
select dept_id
from s_emp
where last_name=’Ngao’;
2.查Ngao所在部门的平均工资
select avg(salary)
from s_emp
where dept_id=(); g
3.也要比Ngao所在部门的平均工资要高部门有哪些
select avg(salary) avg,dept_id
from s_emp
group by dept_id
having avg(salary)>(g);m
4.比Ngao所在部门的平均工资要高部门中的员工,
在这些部门中员工比Ngao所在部门的平均工资要高
select s.last_name,m.avg,d.name,r.name
from s_emp s,() m,s_dept d,s_region r
where s.dept_id=m.dept_id
s.salary>(g)
and s.dept_id=d.id
and d.region_id=r.id
组装:
select s.last_name,m.avg,d.name,r.name
from s_emp s,(select avg(salary) avg,dept_id
from s_emp
group by dept_id
having avg(salary)>(select avg(salary)
from s_emp
where dept_id=(select dept_id
from s_emp
where last_name=’Ngao’))) m,s_dept d,s_region r
where s.dept_id=m.dept_id
s.salary>(select avg(salary)
from s_emp
where dept_id=(select dept_id
from s_emp
where last_name=’Ngao’))
and s.dept_id=d.id
and d.region_id=r.id
查询s_emp表中最大的工资数,并且显示出这个最大工资
的员工的名字
select max(salary) max
from s_emp;
select s.last_name,s.salary
from s_emp s,() m
where s.salary=m.max
查询s_emp表每个部门的最大工资数,并且显示出这个
最大工资的员工名字以及该部门
的名字和该部门所属区域,并且使
用部门编号进行排序
1.查询每个部门的最大工资数
select max(salary) max,dept_id
from s_emp
group dept_id
2用每组中的员工和最大工资数比较
select s.last_name,s.salary,d.name,r.name
from s_emp s,() m,s_dept d,s_region r
where s.dept_id=m.dep_id
and s.salary=m.max
and s.dept_id=d.id
and d.region_id=r.id
数据库中的范式——理解
参考知乎“如何解释关系数据库的范式”
特殊建表
1.把其他的表结构(列的名字和约束)
和内容作为一张新表
create table table_name
as select…
e.g.:
create table stu
as
select id,last_name
from s_emp;
//把s_emp中的查新的列名做为stu的列名
//把s_emp中查询的列的约束也复制到stu中的
新列里
//把查询到的数据也复制到stu中
如果不想新表和查询结果的列名一致
可以起别名
create table stu
as
select id ids,last_name name
from s_emp
只想要表结构,不想要数据
create table stu
as
select id ids,last_name name
from s_emp
where 1=2