前端高频面试题及答案汇总!


作者 | 木易杨
责编 | 伍杏玲
别惊讶!人工智能时代即将到来!
https://edu.csdn.net/topic/ai30?utm_source=cxrs_bw

第 1 题:简单讲解一下 HTTP2 的多路复用
在 HTTP/1 中,每次请求都会建立一次TCP连接,也就是我们常说的3次握手4次挥手,这在一次请求过程中占用了相当长的时间,即使开启了 Keep-Alive ,解决了多次连接的问题,但是依然有两个效率上的问题:
-
第一个:串行的文件传输。当请求a文件时,b文件只能等待,等待a连接到服务器、服务器处理文件、服务器返回文件,这三个步骤。我们假设这三步用时都是1秒,那么a文件用时为3秒,b文件传输完成用时为6秒,依此类推。(注:此项计算有一个前提条件,就是浏览器和服务器是单通道传输)
-
第二个:连接数过多。我们假设Apache设置了最大并发数为300,因为浏览器限制,浏览器发起的最大请求数为6(Chrome),也就是服务器能承载的最高并发为50,当第51个人访问时,就需要等待前面某个请求处理完成。
HTTP2采用二进制格式传输,取代了HTTP1.x的文本格式,二进制格式解析更高效。
多路复用代替了HTTP1.x的序列和阻塞机制,所有的相同域名请求都通过同一个TCP连接并发完成。在HTTP1.x中,并发多个请求需要多个TCP连接,浏览器为了控制资源会有6-8个TCP连接都限制。
HTTP2中
-
同域名下所有通信都在单个连接上完成,消除了因多个 TCP 连接而带来的延时和内存消耗。
-
单个连接上可以并行交错的请求和响应,之间互不干扰
详解:
https://github.com/Advanced-Frontend/Daily-Interview-Question/issues/14
第 2 题:谈谈你对 TCP 三次握手和四次挥手的理解
详解:
https://github.com/Advanced-Frontend/Daily-Interview-Question/issues/15

第 3 题:A、B 机器正常连接后,B 机器突然重启,问 A 此时处于 TCP 什么状态
如果A 与 B 建立了正常连接后,从未相互发过数据,这个时候 B 突然机器重启,问 A 此时处于 TCP 什么状态?如何消除服务器程序中的这个状态?(超纲题,了解即可)
因为B会在重启之后进入tcp状态机的listen状态,只要当a重新发送一个数据包(无论是syn包或者是应用数据),b端应该会主动发送一个带rst位的重置包来进行连接重置,所以a应该在syn_sent状态。

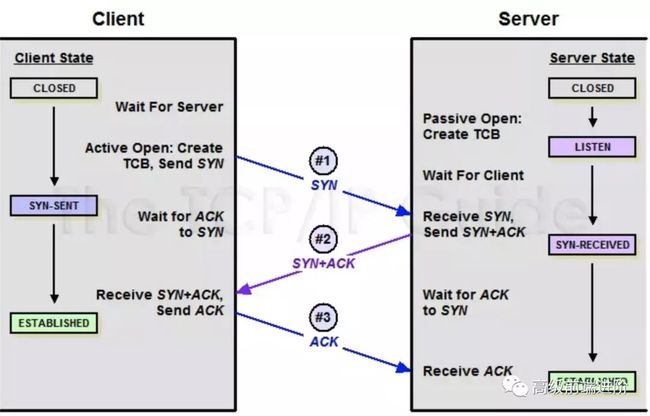
详解:
https://github.com/Advanced-Frontend/Daily-Interview-Question/issues/21
第 4 题:React 中 setState 什么时候是同步的,什么时候是异步的?
在 React 中,如果是由 React 引发的事件处理(比如通过 onClick 引发的事件处理),调用 setState 不会同步更新 this.state,除此之外的 setState 调用会同步执行 this.state。所谓“除此之外”,指的是绕过 React 通过 addEventListener 直接添加的事件处理函数,还有通过 setTimeout/setInterval 产生的异步调用。
原因:在 React 的 setState 函数实现中,会根据一个变量 isBatchingUpdates 判断是直接更新 this.state 还是放到队列中回头再说,而 isBatchingUpdates 默认是 false,也就表示 setState 会同步更新 this.state,但是,有一个函数 batchedUpdates,这个函数会把 isBatchingUpdates 修改为t rue,而当 React 在调用事件处理函数之前就会调用这个 batchedUpdates,造成的后果就是由 React 控制的事件处理过程 setState 不会同步更新 this.state。
详解:
https://github.com/Advanced-Frontend/Daily-Interview-Question/issues/17

第 5 题:React setState 笔试题,下面的代码输出什么?
class Example extends React.Component {
constructor() {
super();
this.state = {
val: 0
};
}
componentDidMount() {
this.setState({val: this.state.val + 1});
console.log(this.state.val); // 第 1 次 log
this.setState({val: this.state.val + 1});
console.log(this.state.val); // 第 2 次 log
setTimeout(() => {
this.setState({val: this.state.val + 1});
console.log(this.state.val); // 第 3 次 log
this.setState({val: this.state.val + 1});
console.log(this.state.val); // 第 4 次 log
}, 0);
}
render() {
return null;
}
};
解析:
1、第一次和第二次都是在 react 自身生命周期内,触发时 isBatchingUpdates 为 true,所以并不会直接执行更新 state,而是加入了 dirtyComponents,所以打印时获取的都是更新前的状态 0。
2、两次 setState 时,获取到 this.state.val 都是 0,所以执行时都是将 0 设置成 1,在 react 内部会被合并掉,只执行一次。设置完成后 state.val 值为 1。
3、setTimeout 中的代码,触发时 isBatchingUpdates 为 false,所以能够直接进行更新,所以连着输出 2,3。
输出: 0 0 2 3
详解:
https://github.com/Advanced-Frontend/Daily-Interview-Question/issues/18
第 6 题:介绍下 NPM 模块安装机制,为什么输入 npm install 就可以自动安装对应的模块?
解析:
1. NPM 模块安装机制:
-
发出npm install命令
-
查询node_modules目录之中是否已经存在指定模块
-
若存在,不再重新安装
-
若不存在
-
npm 向 registry 查询模块压缩包的网址
-
下载压缩包,存放在根目录下的`.npm`目录里
-
解压压缩包到当前项目的`node_modules`目录
-
2. NPM 实现原理
输入 npm install 命令并敲下回车后,会经历如下几个阶段(以 npm 5.5.1 为例):
-
执行工程自身 preinstall
当前 npm 工程如果定义了 preinstall 钩子此时会被执行。
-
确定首层依赖模块
首先需要做的是确定工程中的首层依赖,也就是 dependencies 和 devDependencies 属性中直接指定的模块(假设此时没有添加 npm install 参数)。
工程本身是整棵依赖树的根节点,每个首层依赖模块都是根节点下面的一棵子树,npm 会开启多进程从每个首层依赖模块开始逐步寻找更深层级的节点。
-
获取模块
获取模块是一个递归的过程,分为以下几步:
-
获取模块信息。在下载一个模块之前,首先要确定其版本,这是因为 package.json 中往往是 semantic version(semver,语义化版本)。此时如果版本描述文件(npm-shrinkwrap.json 或 package-lock.json)中有该模块信息直接拿即可,如果没有则从仓库获取。如 packaeg.json 中某个包的版本是 ^1.1.0,npm 就会去仓库中获取符合 1.x.x 形式的最新版本。
-
获取模块实体。上一步会获取到模块的压缩包地址(resolved 字段),npm 会用此地址检查本地缓存,缓存中有就直接拿,如果没有则从仓库下载。
-
查找该模块依赖,如果有依赖则回到第1步,如果没有则停止。
-
模块扁平化(dedupe)
上一步获取到的是一棵完整的依赖树,其中可能包含大量重复模块。比如 A 模块依赖于 lodash,B 模块同样依赖于 lodash。在 npm3 以前会严格按照依赖树的结构进行安装,因此会造成模块冗余。
从 npm3 开始默认加入了一个 dedupe 的过程。它会遍历所有节点,逐个将模块放在根节点下面,也就是 node-modules 的第一层。当发现有重复模块时,则将其丢弃。
这里需要对重复模块进行一个定义,它指的是模块名相同且 semver 兼容。每个 semver 都对应一段版本允许范围,如果两个模块的版本允许范围存在交集,那么就可以得到一个兼容版本,而不必版本号完全一致,这可以使更多冗余模块在 dedupe 过程中被去掉。
-
安装模块
这一步将会更新工程中的 node_modules,并执行模块中的生命周期函数(按照 preinstall、install、postinstall 的顺序)。
-
执行工程自身生命周期
当前 npm 工程如果定义了钩子此时会被执行(按照 install、postinstall、prepublish、prepare 的顺序)。
最后一步是生成或更新版本描述文件,npm install 过程完成。
详解:
https://github.com/Advanced-Frontend/Daily-Interview-Question/issues/22

第 7 题:有以下 3 个判断数组的方法,请分别介绍它们之间的区别和优劣
Object.prototype.toString.call() 、 instanceof 以及 Array.isArray()
解析:
1. Object.prototype.toString.call()
每一个继承 Object 的对象都有 toString 方法,如果 toString 方法没有重写的话,会返回 [Object type],其中 type 为对象的类型。但当除了 Object 类型的对象外,其他类型直接使用 toString 方法时,会直接返回都是内容的字符串,所以我们需要使用call或者apply方法来改变toString方法的执行上下文。
const an = ['Hello','An'];
an.toString(); // "Hello,An"
Object.prototype.toString.call(an); // "[object Array]"
这种方法对于所有基本的数据类型都能进行判断,即使是 null 和 undefined 。
Object.prototype.toString.call('An') // "[object String]"
Object.prototype.toString.call(1) // "[object Number]"
Object.prototype.toString.call(Symbol(1)) // "[object Symbol]"
Object.prototype.toString.call(null) // "[object Null]"
Object.prototype.toString.call(undefined) // "[object Undefined]"
Object.prototype.toString.call(function(){}) // "[object Function]"
Object.prototype.toString.call({name: 'An'}) // "[object Object]"
Object.prototype.toString.call() 常用于判断浏览器内置对象。
2. instanceof
instanceof 的内部机制是通过判断对象的原型链中是不是能找到类型的 prototype。
使用 instanceof判断一个对象是否为数组,instanceof 会判断这个对象的原型链上是否会找到对应的 Array 的原型,找到返回 true,否则返回 false。
[] instanceof Array; // true
但 instanceof 只能用来判断对象类型,原始类型不可以。并且所有对象类型 instanceof Object 都是 true。
[] instanceof Object; // true3. Array.isArray()
-
功能:用来判断对象是否为数组
-
instanceof 与 isArray
当检测Array实例时,Array.isArray 优于 instanceof ,因为 Array.isArray 可以检测出 iframes
var iframe = document.createElement('iframe'); document.body.appendChild(iframe); xArray = window.frames[window.frames.length-1].Array; var arr = new xArray(1,2,3); // [1,2,3] // Correctly checking for Array Array.isArray(arr); // true Object.prototype.toString.call(arr); // true // Considered harmful, because doesn't work though iframes arr instanceof Array; // false -
Array.isArray() 与 Object.prototype.toString.call()
Array.isArray()是ES5新增的方法,当不存在 Array.isArray() ,可以用 Object.prototype.toString.call() 实现。
if (!Array.isArray) {
Array.isArray = function(arg) {
return Object.prototype.toString.call(arg) === '[object Array]';
};
}
详解:
https://github.com/Advanced-Frontend/Daily-Interview-Question/issues/23
第 8 题:介绍下重绘和回流(Repaint & Reflow),以及如何进行优化
解析:
1. 浏览器渲染机制
-
浏览器采用流式布局模型(Flow Based Layout)
-
浏览器会把HTML解析成DOM,把CSS解析成CSSOM,DOM和CSSOM合并就产生了渲染树(Render Tree)。
-
有了RenderTree,我们就知道了所有节点的样式,然后计算他们在页面上的大小和位置,最后把节点绘制到页面上。
-
由于浏览器使用流式布局,对Render Tree的计算通常只需要遍历一次就可以完成,但table及其内部元素除外,他们可能需要多次计算,通常要花3倍于同等元素的时间,这也是为什么要避免使用table布局的原因之一。
2. 重绘
由于节点的几何属性发生改变或者由于样式发生改变而不会影响布局的,称为重绘,例如outline, visibility, color、background-color等,重绘的代价是高昂的,因为浏览器必须验证DOM树上其他节点元素的可见性。
3. 回流
回流是布局或者几何属性需要改变就称为回流。回流是影响浏览器性能的关键因素,因为其变化涉及到部分页面(或是整个页面)的布局更新。一个元素的回流可能会导致了其所有子元素以及DOM中紧随其后的节点、祖先节点元素的随后的回流。
<body>
<div class="error">
<h4>我的组件h4>
<p><strong>错误:strong>错误的描述…p>
<h5>错误纠正h5>
<ol>
<li>第一步li>
<li>第二步li>
ol>
div>
body>
在上面的HTML片段中,对该段落(
标签)回流将会引发强烈的回流,因为它是一个子节点。这也导致了祖先的回流(div.error和body – 视浏览器而定)。此外,
和也会有简单的回流,因为这些节点在DOM中回流元素之后。大部分的回流将导致页面的重新渲染。
回流必定会发生重绘,重绘不一定会引发回流。
4. 浏览器优化
现代浏览器大多都是通过队列机制来批量更新布局,浏览器会把修改操作放在队列中,至少一个浏览器刷新(即16.6ms)才会清空队列,但当你获取布局信息的时候,队列中可能有会影响这些属性或方法返回值的操作,即使没有,浏览器也会强制清空队列,触发回流与重绘来确保返回正确的值。
主要包括以下属性或方法:
-
offsetTop、offsetLeft、offsetWidth、offsetHeight
-
scrollTop、scrollLeft、scrollWidth、scrollHeight
-
clientTop、clientLeft、clientWidth、clientHeight
-
width、height
-
getComputedStyle()
-
getBoundingClientRect()
所以,我们应该避免频繁的使用上述的属性,他们都会强制渲染刷新队列。
5. 减少重绘与回流
-
CSS
-
使用 transform 替代 top
-
使用 visibility 替换 display: none ,因为前者只会引起重绘,后者会引发回流
-
避免使用table布局,可能很小的一个小改动会造成整个 table 的重新布局。
-
尽可能在DOM树的最末端改变class,回流是不可避免的,但可以减少其影响。尽可能在DOM树的最末端改变class,可以限制了回流的范围,使其影响尽可能少的节点。
-
避免设置多层内联样式,CSS 选择符从右往左匹配查找,避免节点层级过多。
<div>
<a> <span>span> a>
div>
<style>
span {
color: red;
}
div > a > span {
color: red;
}
style>
对于第一种设置样式的方式来说,浏览器只需要找到页面中所有的 span 标签然后设置颜色,但是对于第二种设置样式的方式来说,浏览器首先需要找到所有的 span 标签,然后找到 span 标签上的 a 标签,最后再去找到 div 标签,然后给符合这种条件的 span 标签设置颜色,这样的递归过程就很复杂。所以我们应该尽可能的避免写过于具体的 CSS 选择器,然后对于 HTML 来说也尽量少的添加无意义标签,保证层级扁平。
-
将动画效果应用到position属性为absolute或fixed的元素上,避免影响其他元素的布局,这样只是一个重绘,而不是回流,同时,控制动画速度可以选择 requestAnimationFrame,详见探讨 requestAnimationFrame。
-
避免使用CSS表达式,可能会引发回流。
-
将频繁重绘或者回流的节点设置为图层,图层能够阻止该节点的渲染行为影响别的节点,例如will-change、video、iframe等标签,浏览器会自动将该节点变为图层。
-
CSS3 硬件加速(GPU加速),使用css3硬件加速,可以让transform、opacity、filters这些动画不会引起回流重绘 。但是对于动画的其它属性,比如background-color这些,还是会引起回流重绘的,不过它还是可以提升这些动画的性能。
-
JavaScript
-
避免频繁操作样式,最好一次性重写style属性,或者将样式列表定义为class并一次性更改class属性。
-
避免频繁操作DOM,创建一个documentFragment,在它上面应用所有DOM操作,最后再把它添加到文档中。
-
避免频繁读取会引发回流/重绘的属性,如果确实需要多次使用,就用一个变量缓存起来。
-
对具有复杂动画的元素使用绝对定位,使它脱离文档流,否则会引起父元素及后续元素频繁回流。
-
详解:
https://github.com/Advanced-Frontend/Daily-Interview-Question/issues/24

第 9 题:介绍下观察者模式和订阅-发布模式的区别,各自适用于什么场景
解析:

联系
发布-订阅模式是观察者模式的一种变体。发布-订阅只是把一部分功能抽象成一个独立的ChangeManager。
意图
都是某个对象(subject, publisher)改变,使依赖于它的多个对象(observers, subscribers)得到通知。
区别与适用场景
总的来说,发布-订阅模式适合更复杂的场景。
在「一对多」的场景下,发布者的某次更新只想通知它的部分订阅者?
在「多对一」或者「多对多」场景下。一个订阅者依赖于多个发布者,某个发布者更新后是否需要通知订阅者?还是等所有发布者都更新完毕再通知订阅者?
这些逻辑都可以放到ChangeManager里。
详解:
https://github.com/Advanced-Frontend/Daily-Interview-Question/issues/25
第 10 题:聊聊 Redux 和 Vuex 的设计思想
欢迎在 Issue 区留下你的答案。
作者简介:木易杨,网易高级前端工程师,跟着我每周重点攻克一个前端面试重难点。让我带你走进高级前端的世界,在进阶的路上,共勉!
进阶系列文章汇总如下,内有优质前端资料:
https://github.com/yygmind/blog
牛了,这几个案例让你迅速掌握AI技术!
https://edu.csdn.net/topic/ai30?utm_source=cxrs_bw



热 文 推 荐
☞这个 17 岁少年凭什么成为“顶级大师”?
☞杨超越杯编程大赛上热搜:不懂技术真不敢追星
☞程序员撒狗粮!3 天开发自己的婚礼小程序!
☞“我才是世界上最好的编程语言!”
☞腾讯变革 150 天全记录
☞让数百万台手机训练同一个模型?Google把这套框架开源了
☞剧情反转! 创始人去世事件再爆新料, 1.8亿美元难道去了天堂?
☞云漫圈 | 如何给女朋友解释什么是HTTP
☞没有一个人,能躲过程序员的诱惑!
System.out.println("点个好看吧!");
console.log("点个好看吧!");
print("点个好看吧!");
printf("点个好看吧!\n");
cout << "点个好看吧!" << endl;
Console.WriteLine("点个好看吧!");
Response.Write("点个好看吧!");
alert("点个好看吧!")
echo "点个好看吧!"
 喜欢就点击“好看”吧!
喜欢就点击“好看”吧!
回流必定会发生重绘,重绘不一定会引发回流。
4. 浏览器优化
现代浏览器大多都是通过队列机制来批量更新布局,浏览器会把修改操作放在队列中,至少一个浏览器刷新(即16.6ms)才会清空队列,但当你获取布局信息的时候,队列中可能有会影响这些属性或方法返回值的操作,即使没有,浏览器也会强制清空队列,触发回流与重绘来确保返回正确的值。
主要包括以下属性或方法:
-
offsetTop、offsetLeft、offsetWidth、offsetHeight
-
scrollTop、scrollLeft、scrollWidth、scrollHeight
-
clientTop、clientLeft、clientWidth、clientHeight
-
width、height
-
getComputedStyle()
-
getBoundingClientRect()
所以,我们应该避免频繁的使用上述的属性,他们都会强制渲染刷新队列。
5. 减少重绘与回流
-
CSS
-
使用 transform 替代 top
-
使用 visibility 替换 display: none ,因为前者只会引起重绘,后者会引发回流
-
避免使用table布局,可能很小的一个小改动会造成整个 table 的重新布局。
-
尽可能在DOM树的最末端改变class,回流是不可避免的,但可以减少其影响。尽可能在DOM树的最末端改变class,可以限制了回流的范围,使其影响尽可能少的节点。
-
避免设置多层内联样式,CSS 选择符从右往左匹配查找,避免节点层级过多。
<div>
<a> <span>span> a>
div>
<style>
span {
color: red;
}
div > a > span {
color: red;
}
style>
对于第一种设置样式的方式来说,浏览器只需要找到页面中所有的 span 标签然后设置颜色,但是对于第二种设置样式的方式来说,浏览器首先需要找到所有的 span 标签,然后找到 span 标签上的 a 标签,最后再去找到 div 标签,然后给符合这种条件的 span 标签设置颜色,这样的递归过程就很复杂。所以我们应该尽可能的避免写过于具体的 CSS 选择器,然后对于 HTML 来说也尽量少的添加无意义标签,保证层级扁平。
-
将动画效果应用到position属性为absolute或fixed的元素上,避免影响其他元素的布局,这样只是一个重绘,而不是回流,同时,控制动画速度可以选择 requestAnimationFrame,详见探讨 requestAnimationFrame。
-
避免使用CSS表达式,可能会引发回流。
-
将频繁重绘或者回流的节点设置为图层,图层能够阻止该节点的渲染行为影响别的节点,例如will-change、video、iframe等标签,浏览器会自动将该节点变为图层。
-
CSS3 硬件加速(GPU加速),使用css3硬件加速,可以让transform、opacity、filters这些动画不会引起回流重绘 。但是对于动画的其它属性,比如background-color这些,还是会引起回流重绘的,不过它还是可以提升这些动画的性能。
-
JavaScript
-
避免频繁操作样式,最好一次性重写style属性,或者将样式列表定义为class并一次性更改class属性。
-
避免频繁操作DOM,创建一个documentFragment,在它上面应用所有DOM操作,最后再把它添加到文档中。
-
避免频繁读取会引发回流/重绘的属性,如果确实需要多次使用,就用一个变量缓存起来。
-
对具有复杂动画的元素使用绝对定位,使它脱离文档流,否则会引起父元素及后续元素频繁回流。
-
详解:
https://github.com/Advanced-Frontend/Daily-Interview-Question/issues/24
第 9 题:介绍下观察者模式和订阅-发布模式的区别,各自适用于什么场景
解析:
联系
发布-订阅模式是观察者模式的一种变体。发布-订阅只是把一部分功能抽象成一个独立的ChangeManager。
意图
都是某个对象(subject, publisher)改变,使依赖于它的多个对象(observers, subscribers)得到通知。
区别与适用场景
总的来说,发布-订阅模式适合更复杂的场景。
在「一对多」的场景下,发布者的某次更新只想通知它的部分订阅者?
在「多对一」或者「多对多」场景下。一个订阅者依赖于多个发布者,某个发布者更新后是否需要通知订阅者?还是等所有发布者都更新完毕再通知订阅者?
这些逻辑都可以放到ChangeManager里。
详解:
https://github.com/Advanced-Frontend/Daily-Interview-Question/issues/25
第 10 题:聊聊 Redux 和 Vuex 的设计思想
欢迎在 Issue 区留下你的答案。
作者简介:木易杨,网易高级前端工程师,跟着我每周重点攻克一个前端面试重难点。让我带你走进高级前端的世界,在进阶的路上,共勉!
进阶系列文章汇总如下,内有优质前端资料:
https://github.com/yygmind/blog
牛了,这几个案例让你迅速掌握AI技术!
https://edu.csdn.net/topic/ai30?utm_source=cxrs_bw
热 文 推 荐
☞这个 17 岁少年凭什么成为“顶级大师”?
☞杨超越杯编程大赛上热搜:不懂技术真不敢追星
☞程序员撒狗粮!3 天开发自己的婚礼小程序!
☞“我才是世界上最好的编程语言!”
☞腾讯变革 150 天全记录
☞让数百万台手机训练同一个模型?Google把这套框架开源了
☞剧情反转! 创始人去世事件再爆新料, 1.8亿美元难道去了天堂?
☞云漫圈 | 如何给女朋友解释什么是HTTP
☞没有一个人,能躲过程序员的诱惑!
System.out.println("点个好看吧!");
console.log("点个好看吧!");
print("点个好看吧!");
printf("点个好看吧!\n");
cout << "点个好看吧!" << endl;
Console.WriteLine("点个好看吧!");
Response.Write("点个好看吧!");
alert("点个好看吧!")
echo "点个好看吧!"
喜欢就点击“好看”吧!