SSD原理与代码实现
SSD原理与代码实现
- 基本思路
- 网络结构简介
- 默认框(default box)的生成
- 每层的feature map cell对应的anchor计算方法:
- 默认框大小论文由给出计算公式:
- 默认框宽高:
- 实际送入分类/回归器的样本匹配问题
- Training Loss
- Location loss :
- Lconf loss :
- 预处理数据
- data augmentation
- other trick
- atrous空洞卷积
- 代码详解
- SSD网络结构
- anchor box生成
- 图像预处理
- 默认框与GT的匹配以及偏差
- 损失函数

基本思路
- 基础VGG特征提取网络后接多层feature map分类网络
- 多层feature map分别对应不同尺度的固定anchor
- 回归所有anchor对应的class和bounding box
网络结构简介
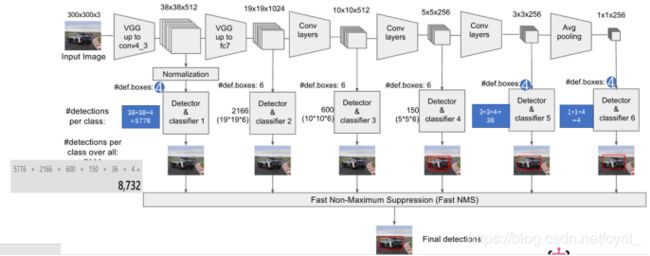
- 输入:300×300
- 经过VGG16(只到conv4_3层)
- 经过几层卷积,得到多层尺寸逐渐减小的feature map分别为:
feat_layers=['block4', 'block7', 'block8', 'block9', 'block10', 'block11']
对应上面层特征图的大小为:
feat_shapes=[(38, 38), (19, 19), (10, 10), (5, 5), (3, 3), (1, 1)] - 每层feature map分别做3×3卷积,每个feature map cell(又称slide
window)对应k个类别和4个bounding box offset(x, y, h, w) - 每层feature map的长宽比为论文里的ratios(2,1/2,3,1/3),其中第一层和最后一层对应4个anchor,其他feature map对应6个anchor:
anchor_ratios=[[2, .5],[2, .5, 3, 1./3], [2, .5, 3, 1./3],[2, .5, 3, 1./3], [2, .5],[2, .5]]
- 网络的训练目标就是,分类和回归各个anchor对应的类别和位置。
默认框(default box)的生成
对于每个用来预测的特征图,按照不同的大小(scale)和长宽比(ratio)生成k个默认框(default box),k的值由scale和ratio共同决定。
例如对于特征层’block4’,特征图尺寸feat_shapes为38x38,默认框大小anchor_sizes即Sk为(21., 45.)(这里参数二:45是下一特征层默认框的大小),默认框ratio为(2., 0.5),故k=4(尺寸21的有1:1, 1:2, 2:1三个默认框,以及论文中额外添加的一个尺寸为sqrt(21 * 45)的1:1一个默认框),该层总共会生成38x38x4个默认框。
代码中的默认参数:
# Smin = 0.15, Smax = 0.9
anchor_size_bounds=[0.15, 0.90]
# 当前层与下一层的预测默认矩形边框尺寸,即Sk的值
anchor_sizes=[(21., 45.),
(45., 99.),
(99., 153.),
(153., 207.),
(207., 261.),
(261., 315.)
# 特征图上一步对应在原图上的跨度 anchor_step * feat_shapes与等于300
anchor_steps=[8, 16, 32, 64, 100, 300]
# 偏移,计算中心点时用到
anchor_offset=0.5,
6层特征图的数据对照如下:
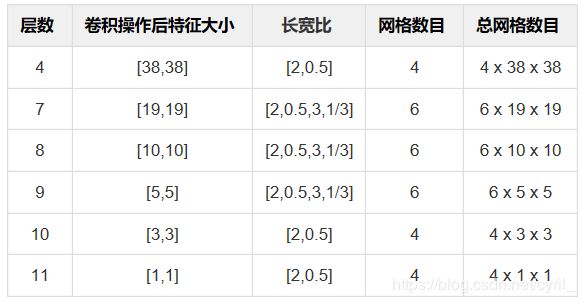
即共有 38 x 38 x 4 + 19 x 19 x 6 + 10 x 10 x 6 + 5 x 5 x 6 + 3 x 3 x 4 + 1 x 1 x 4 = 8732个anchor。
每层的feature map cell对应的anchor计算方法:
- 中心点和宽高都是放缩了的,乘300后才是对应于原图像的位置和宽高。这样层层下来,达到不同尺度不同位置的检测
- 位置:假设当前feature map cell是位于第i行,第j列,则anchor的中心为(i+0.5,j+0.5)
- 中心点公式:y = (y.astype(dtype) + offset) * step /
img_shape[0],实际上step*feat_shape约等于img_shape。
这使得网格点坐标介于0~1,放缩一下即可到图像大小,这也就是超参数anchor_steps的意义:用于辅助放缩搜索网格中心点的位置。
默认框大小论文由给出计算公式:

- 论文中Smin为0.2,代码中为0.15, Smax论文中代码中都为0.9。
- m是用于预测的特征图个数,k代表层数。(注意代码中每层默认框大小并不与计算公式对应)
默认框宽高:
![]()
![]()
可以理解为在缩放因子Sk选择好anchor尺寸后,用a_r来控制anchor形状,从而得到多尺度的各种anchor。
实际送入分类/回归器的样本匹配问题
- 正样本:选择与bounding box jaccard overlap(两张图的交集/并集)大于0.5的anchor作为正样本
- Hard negative mining:由于负样本是远远大于正样本的,需要去掉一部分负样本。先整图经过网络,根据每个anchor的最高类置信度进行排序,选择不是前景又最不像背景的n_neg个样本,筛选后的负样本为class 0预测值最小的样本。这样筛选出来的负样本也会更难识别,正负样本比例大概是1:3。
源码中n_neg = 3 * n_pos + batch_size
Training Loss
= location loss + α * classification loss (实际上α = 1)

- N是匹配的default boxes的数量(包括正样本和负样本)
- Lconf为预测类别损失(softmax loss)
- Lloc为位置偏移量损失(Smooth L1 loss)
- x是判断第i个default box是否是第j个ground truth box上的p类样本的集和。
- c是第i个anchor预测为第p类的概率集合。
- l是预测的bounding box集合
- g是ground true bounding box集合
Location loss :

其中Smooth L1 loss:
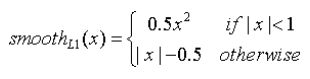
Llos损失函数主要有四部分:中心坐标cx的偏移量损失,中心点坐标cy的偏移损失,宽度w的缩放损失以及高度h的缩放损失。
式中的l表示的是预测的坐标偏移量,g表示的是默认框与之匹配的GTbox的坐标偏移量。k为类别,在式中表示不算背景0的意思,只算正样本的loc loss。
Lconf loss :
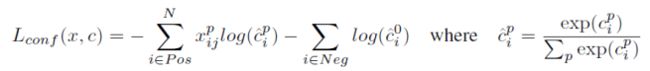
Lconf损失函数主要有两部分:正样本(Pos)交叉熵损失和负样本(Neg)交叉熵损失。

预处理数据
data augmentation
在训练中还用到了数据增强/扩充,每张图片多是由下列三种方法之一随机采样而来:
- 使用整图
- crop图片上的一部分,crop出来的min面积为0.1,0.3,0.5,0.7,0.9
- 完全随机地crop
源码中预处理函数preprocess_for_train大致流程为:
- 随机在原图上裁剪一个区域,计算裁剪后区域和各个标注框的重叠,视阈值保留bboxes和labels
- 裁剪出来的图片放大到输入图片大小(bbox都是归一化的,不需要放缩)
- 随机翻转flip(bbox要同步翻转)
- 其他预处理(随机扭曲颜色)(不涉及bbox)
- 返回image, labels, bboxes
源码中随机剪裁函数distorted_bounding_box_crop大致流程为:
- 调用内置函数保证裁剪的大小范围以及一定会包含一些关注目标,返回裁剪参数
- 裁剪图片(注意保留裁剪位置参数bbox_begin,bbox_size)
- 计算裁剪框和各个检测框的重叠,并设置阈值舍弃、调整保留框坐标
- 返回随机裁剪的图片,筛选调整后的labels(n,)、bboxes(n,4),裁剪图片对应原图坐标(4,)
other trick
atrous空洞卷积
(论文模型部分未提到,只在测试部分提到了一点)
介绍:https://blog.csdn.net/guyuealian/article/details/86239099
空洞卷积的作用:在不增加计算量的同时增大了感受野
源码中在block6中采用了空洞卷积,rate为使用atrous convolution的膨胀率
net = slim.conv2d(net, 1024, [3, 3], rate=6, scope='conv6')
论文中使用各个tricks带来的收益:

代码详解
重点在于为前向网络中挑选出的特征层分别添加两个卷积出口:分类和回归出口,用于对应后面的每个搜索框的各个类别得分、以及4个坐标值。接下来,通过5个方面(SSD网络结构、anchor box的生成、图像预处理、默认框与GT的匹配以及偏差、损失函数)来分析搭建SSD。
SSD网络结构
用VGG网络的前五层,并额外多加几层结构,提取需要用来回归分类的几层特征图进过卷积后的结果,进行网格搜索,找目标特征。对应到函数里,转化为三个大部分,原网络结构、添加网络结构、多尺度处理结构:
- ssd_net
# 建立SSD网络
def ssd_net(inputs,
num_classes=SSDNet.default_params.num_classes,
feat_layers=SSDNet.default_params.feat_layers,
anchor_sizes=SSDNet.default_params.anchor_sizes,
anchor_ratios=SSDNet.default_params.anchor_ratios,
normalizations=SSDNet.default_params.normalizations,
is_training=True,
dropout_keep_prob=0.5,
prediction_fn=slim.softmax,
reuse=None,
scope='ssd_300_vgg'):
"""SSD net definition.
"""
# if data_format == 'NCHW':
# inputs = tf.transpose(inputs, perm=(0, 3, 1, 2))
# End_points collect relevant activations for external use.
# 用于收集每一层的输出
end_points = {}
with tf.variable_scope(scope, 'ssd_300_vgg', [inputs], reuse=reuse):
# Original VGG-16 blocks.
net = slim.repeat(inputs, 2, slim.conv2d, 64, [3, 3], scope='conv1')
end_points['block1'] = net
net = slim.max_pool2d(net, [2, 2], scope='pool1')
# Block 2.
net = slim.repeat(net, 2, slim.conv2d, 128, [3, 3], scope='conv2')
end_points['block2'] = net
net = slim.max_pool2d(net, [2, 2], scope='pool2')
# Block 3.
net = slim.repeat(net, 3, slim.conv2d, 256, [3, 3], scope='conv3')
end_points['block3'] = net
net = slim.max_pool2d(net, [2, 2], scope='pool3')
# Block 4.
net = slim.repeat(net, 3, slim.conv2d, 512, [3, 3], scope='conv4')
end_points['block4'] = net
net = slim.max_pool2d(net, [2, 2], scope='pool4')
# Block 5.
net = slim.repeat(net, 3, slim.conv2d, 512, [3, 3], scope='conv5')
end_points['block5'] = net
net = slim.max_pool2d(net, [3, 3], stride=1, scope='pool5')
# Additional SSD blocks.
# Block 6: let's dilate the hell out of it!
net = slim.conv2d(net, 1024, [3, 3], rate=6, scope='conv6')
end_points['block6'] = net
net = tf.layers.dropout(net, rate=dropout_keep_prob, training=is_training)
# Block 7: 1x1 conv. Because the fuck.
net = slim.conv2d(net, 1024, [1, 1], scope='conv7')
end_points['block7'] = net
net = tf.layers.dropout(net, rate=dropout_keep_prob, training=is_training)
# Block 8/9/10/11: 1x1 and 3x3 convolutions stride 2 (except lasts).
end_point = 'block8'
with tf.variable_scope(end_point):
net = slim.conv2d(net, 256, [1, 1], scope='conv1x1')
net = custom_layers.pad2d(net, pad=(1, 1))
net = slim.conv2d(net, 512, [3, 3], stride=2, scope='conv3x3', padding='VALID')
end_points[end_point] = net
end_point = 'block9'
with tf.variable_scope(end_point):
net = slim.conv2d(net, 128, [1, 1], scope='conv1x1')
net = custom_layers.pad2d(net, pad=(1, 1))
net = slim.conv2d(net, 256, [3, 3], stride=2, scope='conv3x3', padding='VALID')
end_points[end_point] = net
end_point = 'block10'
with tf.variable_scope(end_point):
net = slim.conv2d(net, 128, [1, 1], scope='conv1x1')
net = slim.conv2d(net, 256, [3, 3], scope='conv3x3', padding='VALID')
end_points[end_point] = net
end_point = 'block11'
with tf.variable_scope(end_point):
net = slim.conv2d(net, 128, [1, 1], scope='conv1x1')
net = slim.conv2d(net, 256, [3, 3], scope='conv3x3', padding='VALID')
end_points[end_point] = net
print(end_points)
# Prediction and localisations layers.
# 预测类别和位置调整
predictions = []
logits = []
localisations = []
for i, layer in enumerate(feat_layers):
with tf.variable_scope(layer + '_box'):
# 接受特征层的输出,生成类别和位置预测
p, l = ssd_multibox_layer(end_points[layer],# <-----SSD处理
num_classes,
anchor_sizes[i],
anchor_ratios[i],
normalizations[i])
# 收集每一层的预测结果
# prediction_fn=slim.softmax 预测类别
predictions.append(prediction_fn(p))
# 概率
logits.append(p)
# 位置偏移
localisations.append(l)
return predictions, localisations, logits, end_points
a. 超参数设定
- default_params
# 默认参数
default_params = SSDParams(
img_shape=(300, 300), # 输入size
num_classes=23, # 类别
no_annotation_label=23,
# 需要抽取做目标检测的卷积层
feat_layers=['block4', 'block7', 'block8', 'block9', 'block10', 'block11'],
# 对应上面层特征图的大小
feat_shapes=[(38, 38), (19, 19), (10, 10), (5, 5), (3, 3), (1, 1)],
# Smin = 0.15, Smax = 0.9
anchor_size_bounds=[0.15, 0.90],
# anchor_size_bounds=[0.20, 0.90],
# 对应检测层定义default box里的size,之后在计算anchor的时候用到
# 当前层与下一层的预测默认矩形边框尺寸,即Sk的值,与论文中的计算公式并不对应
anchor_sizes=[(21., 45.),
(45., 99.),
(99., 153.),
(153., 207.),
(207., 261.),
(261., 315.)],
# anchor_sizes=[(30., 60.),
# (60., 111.),
# (111., 162.),
# (162., 213.),
# (213., 264.),
# (264., 315.)],
# 对应检测层的长宽比,即论文里的ratios(2,1/2,3,1/3)
# 不包含1:1
anchor_ratios=[[2, .5],
[2, .5, 3, 1./3],
[2, .5, 3, 1./3],
[2, .5, 3, 1./3],
[2, .5],
[2, .5]],
# caffe实现的时候使用的初始化anchor方法,后面会讲到
# 特征图上一步对应在原图上的跨度 anchor_step*feat_shapey与等于300
anchor_steps=[8, 16, 32, 64, 100, 300],
# 偏移,计算中心点时用到
anchor_offset=0.5,
# 特征层是否正则处理
normalizations=[20, -1, -1, -1, -1, -1],
# 默认框与真实框的差异缩放比例 x y w h
prior_scaling=[0.1, 0.1, 0.2, 0.2]
)
b. 多尺度处理结构
multibox_layer输出cls_pred loc_pred
- ssd_multibox_layer
# 多尺度预测loc_pred位置 和cls_pred类别
def ssd_multibox_layer(inputs, # 输入特征层
num_classes,# 类别
sizes, # 当前层与下一层的预测默认矩形边框尺寸,即Sk的值
ratios=[1], # 矩形框长宽比
normalization=-1,# 是否正则化
bn_normalization=False):
"""Construct a multibox layer, return a class and localization predictions.
"""
net = inputs
# 对特征层做L2正则化
if normalization > 0:
net = custom_layers.l2_normalization(net, scaling=True)
# Number of anchors.
# 计算default box的数量,分别为 4 6 6 6 4
num_anchors = len(sizes) + len(ratios)
# Location.默认框位置偏移量预测 即 ymin,xmin,ymax,xmax
num_loc_pred = num_anchors * 4
# 对特征层做卷积,输出channels为4*num_anchors
loc_pred = slim.conv2d(net, num_loc_pred, [3, 3], activation_fn=None,
scope='conv_loc')
# ensure data format be "NWHC"
# # 强制转换为NHWC
loc_pred = custom_layers.channel_to_last(loc_pred)
# 将得到的feature maps reshape为[N,H,W,num_anchors,4]
loc_pred = tf.reshape(loc_pred,
tensor_shape(loc_pred, 4)[:-1]+[num_anchors, 4])
# Class prediction.默认框内目标类别预测
# 每个框都要计算所有的类别
num_cls_pred = num_anchors * num_classes
cls_pred = slim.conv2d(net, num_cls_pred, [3, 3], activation_fn=None,
scope='conv_cls')
# 强制转化为‘NHWC’
cls_pred = custom_layers.channel_to_last(cls_pred)
# NHW(num_anchors+类别)->NHW,num_anchors,类别
cls_pred = tf.reshape(cls_pred,
tensor_shape(cls_pred, 4)[:-1]+[num_anchors, num_classes])
return cls_pred, loc_pred
anchor box生成
- ssd_anchors_all_layers
def ssd_anchors_all_layers(img_shape,
layers_shape,
anchor_sizes,
anchor_ratios,
anchor_steps, # [8, 16, 32, 64, 100, 300]
offset=0.5,
dtype=np.float32):
"""Compute anchor boxes for all feature layers.
"""
layers_anchors = []
for i, s in enumerate(layers_shape):
anchor_bboxes = ssd_anchor_one_layer(img_shape, s,
anchor_sizes[i],
anchor_ratios[i],
anchor_steps[i],
offset=offset, dtype=dtype)
layers_anchors.append(anchor_bboxes)
return layers_anchors
def ssd_anchor_one_layer(img_shape,
feat_shape,
sizes,
ratios,
step,
offset=0.5,
dtype=np.float32):
# y, x = np.mgrid[0:feat_shape[0], 0:feat_shape[1]]
# y = (y.astype(dtype) + offset) / feat_shape[0]
# x = (x.astype(dtype) + offset) / feat_shape[1]
# Weird SSD-Caffe computation using steps values...
# 计算中心点的归一化距离
# 生成feat_shape中HW对应的网格坐标
# 生成一个网格矩阵 y,x均为[38,38],其中y为从上到下从0到37。y为从左到右0到37
y, x = np.mgrid[0:feat_shape[0], 0:feat_shape[1]]
# 以第一个元素为例,简单方法为:(0+0.5)/38即为相对距离,
# 而SSD-Caffe使用的是(0+0.5)*step/img_shape
# step*feat_shape 约等于img_shape,这使得网格点坐标介于0~1,放缩一下即可到图像大小
# 超参数anchor_steps的意义:用于辅助放缩搜索网格中心点的位置
y = (y.astype(dtype) + offset) * step / img_shape[0]
x = (x.astype(dtype) + offset) * step / img_shape[1]
# Expand dims to support easy broadcasting.
# [38,38,1]
y = np.expand_dims(y, axis=-1)
x = np.expand_dims(x, axis=-1)
# Compute relative height and width.
# Tries to follow the original implementation of SSD for the order.
num_anchors = len(sizes) + len(ratios)
h = np.zeros((num_anchors, ), dtype=dtype)
w = np.zeros((num_anchors, ), dtype=dtype)
# Add first anchor boxes with ratio=1.
h[0] = sizes[0] / img_shape[0]
w[0] = sizes[0] / img_shape[1]
di = 1
if len(sizes) > 1:
h[1] = math.sqrt(sizes[0] * sizes[1]) / img_shape[0]
w[1] = math.sqrt(sizes[0] * sizes[1]) / img_shape[1]
di += 1
for i, r in enumerate(ratios):
h[i+di] = sizes[0] / img_shape[0] / math.sqrt(r)
w[i+di] = sizes[0] / img_shape[1] * math.sqrt(r)
# 返回y,x,h,w的数值信息
return y, x, h, w
图像预处理
a. 图像预处理:
随机剪裁 -> resize -> 随机flip -> 扭曲颜色 -> 返回image, labels, bboxes
- preprocess_image
def preprocess_image(image, labels, bboxes, out_shape,
scope='ssd_preprocessing_train'):
with tf.name_scope(scope, 'ssd_preprocessing_train', [image, labels, bboxes]):
if image.get_shape().ndims != 3:
raise ValueError('Input must be of size [height, width, C>0]')
# Convert to float scaled [0, 1].
# 并不单单是float化,而是将255像素表示放缩为[0 1]表示
if image.dtype != tf.float32:
image = tf.image.convert_image_dtype(image, dtype=tf.float32)
# (有条件的)随机裁剪,筛选调整后的labels(n,)、bboxes(n, 4),裁剪图片对应原图坐标(4,)
dst_image, labels, bboxes, distort_bbox = \
distorted_bounding_box_crop(image, labels, bboxes,
min_object_covered=0.25,
aspect_ratio_range=(0.6, 1.67))
# Resize image to output size.
dst_image = util_tf.resize_image(dst_image, out_shape,
method=tf.image.ResizeMethod.BILINEAR,
align_corners=False)
# Randomly flip the image horizontally.
dst_image, bboxes = util_tf.random_flip_left_right(dst_image, bboxes)
# Randomly distort the colors. There are 4 ways to do it.
dst_image = util_tf.apply_with_random_selector(
dst_image,
lambda x, ordering: util_tf.distort_color(x, ordering, False),
num_cases=4)
# Rescale to VGG input scale.
image = dst_image * 255.
image = util_tf.tf_image_whitened(image)
# mean = tf.constant(means, dtype=image.dtype)
# image = image - mean
# 'NHWC' (n,) (n, 4)
return image, labels, bboxes
b. 随机剪裁
- distorted_bounding_box_crop
def distorted_bounding_box_crop(image,
labels,
bboxes,
min_object_covered=0.3,
aspect_ratio_range=(0.9, 1.1),
area_range=(0.1, 1.0),
max_attempts=200,
scope=None):
with tf.name_scope(scope, 'distorted_bounding_box_crop', [image, bboxes]):
# 高级的随机裁剪
# The bounding box coordinates are floats in `[0.0, 1.0]` relative to the width
# and height of the underlying image.
# 1-D, 1-D, [1, 1, 4]
bbox_begin, bbox_size, distort_bbox = tf.image.sample_distorted_bounding_box(
tf.shape(image),
bounding_boxes=tf.expand_dims(bboxes, 0), # [1, n, 4]
min_object_covered=min_object_covered,
aspect_ratio_range=aspect_ratio_range,
area_range=area_range,
max_attempts=max_attempts, # 最大尝试裁剪次数,失败则返回原图
use_image_if_no_bounding_boxes=True)
[4],裁剪结果相对原图的(y, x, h, w)
distort_bbox = distort_bbox[0, 0]
# Crop the image to the specified bounding box.
cropped_image = tf.slice(image, bbox_begin, bbox_size)
# Restore the shape since the dynamic slice loses 3rd dimension.
cropped_image.set_shape([None, None, 3]) # <-----设置了尺寸了哈
# Update bounding boxes: resize and filter out.
# 以裁剪子图为参考,将bboxes更换参考点和基长度
bboxes = bboxes_resize(distort_bbox, bboxes) # [4], [n, 4]
# 筛选变换后的bboxes和裁剪子图交集大于阈值的图bboxes
labels, bboxes = bboxes_filter_overlap(labels, bboxes,
threshold=0.5,
assign_negative=False)
# 返回随机裁剪的图片,筛选调整后的labels(n,)、bboxes(n, 4),裁剪图片对应原图坐标(4,)
return cropped_image, labels, bboxes, distort_bbox
默认框与GT的匹配以及偏差
在数据预处理之后,图片、类别、真实框格式较为原始,不能够直接作为损失函数的输入标签(ssd向前网络只需要图像就行,这里的处理主要需要满足loss的计算),对于一张图片(三维CHW)我们需要如下格式的数据作为损失函数标签:
gclasse: 搜索框对应的真实类别
长度为ssd特征层f的list,每一个元素是一个Tensor,shape为:该层中心点行数×列数×每个中心点包含搜索框数目
gscores: 搜索框和真实框的IOU,gclasses中记录的就是该真实框的类别
长度为ssd特征层f的list,每一个元素是一个Tensor,shape为:该层中心点行数×列数×每个中心点包含搜索框数目
glocalisations: 搜索框相较于真实框位置修正,由于有4个坐标,所以维度多了一维
长度为ssd特征层f的list,每一个元素是一个Tensor,shape为:该层中心点行数×列数×每个中心点包含搜索框数目×4
按照ssd特征层进行划分,首先建立三个list,然后对于每一个特征层计算该层的三个Tensor,最后分别添加进list中:
- tf_ssd_bboxes_encode
def tf_ssd_bboxes_encode(labels,
bboxes,
anchors,
num_classes,
no_annotation_label,
ignore_threshold=0.5,
prior_scaling=(0.1, 0.1, 0.2, 0.2),
dtype=tf.float32,
scope='ssd_bboxes_encode'):
with tf.name_scope(scope):
target_labels = []
target_localizations = []
target_scores = []
# anchors_layer: (y, x, h, w)
# 为了有助理解,m表示该层中心点行列数,k为每个中心点对应的框数,n为图像上的目标数
for i, anchors_layer in enumerate(anchors):
with tf.name_scope('bboxes_encode_block_%i' % i):
# (m,m,k),xywh(m,m,4k),(m,m,k)
t_labels, t_loc, t_scores = \
tf_ssd_bboxes_encode_layer(labels, bboxes, anchors_layer,
num_classes, no_annotation_label,
ignore_threshold,
prior_scaling, dtype)
target_labels.append(t_labels)
target_localizations.append(t_loc)
target_scores.append(t_scores)
return target_labels, target_localizations, target_scores
def tf_ssd_bboxes_encode_layer(labels, # (n,)
bboxes, # (n, 4)
anchors_layer, # y(m, m, 1), x(m, m, 1), h(k,), w(k,)
num_classes,
no_annotation_label,
ignore_threshold=0.5,
prior_scaling=(0.1, 0.1, 0.2, 0.2),
dtype=tf.float32):
yref, xref, href, wref = anchors_layer # y(m, m, 1), x(m, m, 1), h(k,), w(k,)
ymin = yref - href / 2. # (m, m, k)
xmin = xref - wref / 2.
ymax = yref + href / 2.
xmax = xref + wref / 2.
vol_anchors = (xmax - xmin) * (ymax - ymin) # 搜索框面积(m, m, k)
# Initialize tensors...
# 下面各个Tensor矩阵的shape等于中心点坐标矩阵的shape
shape = (yref.shape[0], yref.shape[1], href.size) # (m, m, k)
feat_labels = tf.zeros(shape, dtype=tf.int64) # (m, m, k)
feat_scores = tf.zeros(shape, dtype=dtype)
feat_ymin = tf.zeros(shape, dtype=dtype)
feat_xmin = tf.zeros(shape, dtype=dtype)
feat_ymax = tf.ones(shape, dtype=dtype)
feat_xmax = tf.ones(shape, dtype=dtype)
# 计算IOU
def jaccard_with_anchors(bbox):
"""Compute jaccard score between a box and the anchors.
"""
# 计算两个box的交集:交集左上角的点取两个box的max,交集右下角的点取两个box的min
int_ymin = tf.maximum(ymin, bbox[0]) # (m, m, k)
int_xmin = tf.maximum(xmin, bbox[1])
int_ymax = tf.minimum(ymax, bbox[2])
int_xmax = tf.minimum(xmax, bbox[3])
h = tf.maximum(int_ymax - int_ymin, 0.)
w = tf.maximum(int_xmax - int_xmin, 0.)
# Volumes.
# 处理搜索框和bbox之间的联系
inter_vol = h * w # 交集面积
union_vol = vol_anchors - inter_vol \
+ (bbox[2] - bbox[0]) * (bbox[3] - bbox[1]) # 并集面积
jaccard = tf.div(inter_vol, union_vol) # 交集/并集,即IOU
return jaccard # (m, m, k)
def condition(i, feat_labels, feat_scores,
feat_ymin, feat_xmin, feat_ymax, feat_xmax):
"""Condition: check label index.
"""
r = tf.less(i, tf.shape(labels))
return r[0] # tf.shape(labels)有维度,所以r有维度
# 有点模糊 不太懂
def body(i, feat_labels, feat_scores,
feat_ymin, feat_xmin, feat_ymax, feat_xmax):
"""Body: update feature labels, scores and bboxes.
Follow the original SSD paper for that purpose:
- assign values when jaccard > 0.5;
- only update if beat the score of other bboxes.
"""
# Jaccard score.
label = labels[i] # 当前图片上第i个对象的标签
bbox = bboxes[i] # 当前图片上第i个对象的真实框bbox
jaccard = jaccard_with_anchors(bbox) # 当前对象的bbox和当前层的搜索网格IOU,(m, m, k)
# Mask: check threshold + scores + no annotations + num_classes.
# tf.greater 参数1>参数2返回True 否则False
mask = tf.greater(jaccard, feat_scores) # 掩码矩阵,IOU大于历史得分的为True,(m, m, k)
# mask = tf.logical_and(mask, tf.greater(jaccard, matching_threshold))
mask = tf.logical_and(mask, feat_scores > -0.5)
mask = tf.logical_and(mask, label < num_classes) # 不太懂,label应该必定小于类别数
imask = tf.cast(mask, tf.int64) # 整形mask
fmask = tf.cast(mask, dtype) # 浮点型mask
# Update values using mask.
# 保证feat_labels存储对应位置得分最大对象标签,feat_scores存储那个得分
# (m, m, k) × 当前类别scalar + (1 - (m, m, k)) × (m, m, k)
# 更新label记录,此时的imask已经保证了True位置当前对像得分高于之前的对象得分,其他位置值不变
feat_labels = imask * label + (1 - imask) * feat_labels
# 更新score记录,mask为True使用本类别IOU,否则不变
feat_scores = tf.where(mask, jaccard, feat_scores)
# 下面四个矩阵存储对应label的真实框坐标
# (m, m, k) × 当前框坐标scalar + (1 - (m, m, k)) × (m, m, k)
feat_ymin = fmask * bbox[0] + (1 - fmask) * feat_ymin
feat_xmin = fmask * bbox[1] + (1 - fmask) * feat_xmin
feat_ymax = fmask * bbox[2] + (1 - fmask) * feat_ymax
feat_xmax = fmask * bbox[3] + (1 - fmask) * feat_xmax
return [i + 1, feat_labels, feat_scores,
feat_ymin, feat_xmin, feat_ymax, feat_xmax]
# Main loop definition.
# 对当前图像上每一个目标进行循环
i = 0
(i,
feat_labels, feat_scores,
feat_ymin, feat_xmin,
feat_ymax, feat_xmax) = tf.while_loop(condition, body,
[i,
feat_labels, feat_scores,
feat_ymin, feat_xmin,
feat_ymax, feat_xmax])
# Transform to center / size.
# 这里的y、x、h、w指的是对应位置所属真实框的相关属性
feat_cy = (feat_ymax + feat_ymin) / 2.
feat_cx = (feat_xmax + feat_xmin) / 2.
feat_h = feat_ymax - feat_ymin
feat_w = feat_xmax - feat_xmin
# Encode features.
# prior_scaling: [0.1, 0.1, 0.2, 0.2],放缩意义不明
# ((m, m, k) - (m, m, 1)) / (k,) * 10
# 以搜索网格中心点为参考,真实框中心的偏移,单位长度为网格hw
feat_cy = (feat_cy - yref) / href / prior_scaling[0]
feat_cx = (feat_cx - xref) / wref / prior_scaling[1]
# log((m, m, k) / (m, m, 1)) * 5
# 真实框宽高/搜索网格宽高,取对
feat_h = tf.log(feat_h / href) / prior_scaling[2]
feat_w = tf.log(feat_w / wref) / prior_scaling[3]
# Use SSD ordering: x / y / w / h instead of ours.(m, m, k, 4)
feat_localizations = tf.stack([feat_cx, feat_cy, feat_w, feat_h], axis=-1) # -1会扩维,故有4
return feat_labels, feat_localizations, feat_scores
需要注意的是:在该函数中仅仅只是寻找与每个默认框最匹配的GTbox,并没有进行筛选正负样本,关于正负样本的选取会在下一部分losses计算中讲述
损失函数
先确定正样本,再确定负样本,经过筛选正负样本比例1:3,加入loss
- ssd_losses
# SSD loss function.
def ssd_losses(logits, localisations, # 预测类别,位置
gclasses, glocalisations, gscores, # ground truth类别,位置,得分
match_threshold=0.5,
negative_ratio=3.,
alpha=1.,
label_smoothing=0.,
scope=None):
with tf.name_scope(scope, 'ssd_losses'):
# 提取类别数和batch_size
lshape = tensor_shape(logits[0], 5) # tensor_shape函数可以取代
num_classes = lshape[-1]
batch_size = lshape[0]
# Flatten out all vectors!
flogits = []
fgclasses = []
fgscores = []
flocalisations = []
fglocalisations = []
for i in range(len(logits)): # 按照ssd特征层循环
flogits.append(tf.reshape(logits[i], [-1, num_classes]))
fgclasses.append(tf.reshape(gclasses[i], [-1]))
fgscores.append(tf.reshape(gscores[i], [-1]))
flocalisations.append(tf.reshape(localisations[i], [-1, 4]))
fglocalisations.append(tf.reshape(glocalisations[i], [-1, 4]))
# And concat the crap!
logits = tf.concat(flogits, axis=0) # 全部的搜索框,对应的21类别的输出
gclasses = tf.concat(fgclasses, axis=0) # 全部的搜索框,真实的类别数字
gscores = tf.concat(fgscores, axis=0) # 全部的搜索框,和真实框的IOU
localisations = tf.concat(flocalisations, axis=0) # 真实的位置
glocalisations = tf.concat(fglocalisations, axis=0) # 预测的位置
dtype = logits.dtype
pmask = gscores > match_threshold # 类别搜索框和真实框IOU大于阈值
fpmask = tf.cast(pmask, dtype) # 浮点型前景掩码(前景假定为含有对象的IOU足够的搜索框标号)
n_positives = tf.reduce_sum(fpmask) # 前景总数
# Hard negative mining...
no_classes = tf.cast(pmask, tf.int32)
predictions = slim.softmax(logits) # 转化为概率
nmask = tf.logical_and(tf.logical_not(pmask),
gscores > -0.5) # IOU达不到阈值的类别搜索框位置记1
fnmask = tf.cast(nmask, dtype)
# tf.where根据第一个条件是否成立,
# 当为True时选择第二个参数中的值,否则使用第三个参数的值
nvalues = tf.where(nmask,
predictions[:, 0], # 框内无物体标记为背景预测概率
1. - fnmask) # 框内有物体位置标记为1???
nvalues_flat = tf.reshape(nvalues, [-1])
# 此时的负样本(fnmask标记)同样的为{0,1},且和正样本互补,
# 但是这样会导致负样本过多,所以建立nvalue用于筛选负样本,
# nvalue中fnmask为1的位置记为对应搜索框的第0类(背景)预测概率,
# 否则记为1(fpmask标记位置),
# Number of negative entries to select.
# 在nmask中剔除n_neg个最不可能背景点(对应的class0概率最低)
max_neg_entries = tf.cast(tf.reduce_sum(fnmask), tf.int32)
# 3 × 前景掩码数量 + batch_size
n_neg = tf.cast(negative_ratio * n_positives, tf.int32) + batch_size
n_neg = tf.minimum(n_neg, max_neg_entries)
val, idxes = tf.nn.top_k(-nvalues_flat, k=n_neg) # 最不可能为背景的n_neg个点
max_hard_pred = -val[-1]
# Final negative mask.
nmask = tf.logical_and(nmask, nvalues < max_hard_pred) # 不是前景,又最不像背景的n_neg个点
fnmask = tf.cast(nmask, dtype)
# 由于知道这些负样本都属于背景(和真实框IOU不足),所以理论上其class 0预测值越大越好,
# 取class 0预测值最小的3倍正样本数目的负样本,最大化其class 0预测值,
# 达到最小化损失函数的目的。
# 筛选后的负样本(fnmask标记)为原负样本中class 0预测值最小的目标数目的点。
# Add cross-entropy loss.
with tf.name_scope('cross_entropy_pos'):
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits,
labels=gclasses) # 0-20
loss = tf.div(tf.reduce_sum(loss * fpmask), batch_size, name='value')
tf.losses.add_loss(loss)
with tf.name_scope('cross_entropy_neg'):
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits,
labels=no_classes) # {0,1}
loss = tf.div(tf.reduce_sum(loss * fnmask), batch_size, name='value')
tf.losses.add_loss(loss)
# Add localization loss: smooth L1, L2, ...
with tf.name_scope('localization'):
# Weights Tensor: positive mask + random negative.
weights = tf.expand_dims(alpha * fpmask, axis=-1)
loss = abs_smooth(localisations - glocalisations)
loss = tf.div(tf.reduce_sum(loss * weights), batch_size, name='value')
tf.losses.add_loss(loss)