知识图谱里的知识表示:RDF
大部分知识图谱使用RDF描述世界上的各种资源,并以三元组的形式保存到知识库中。RDF( Resource Description Framework, 资源描述框架)是一种资源描述语言,它受到元数据标准、框架系统、面向对象语言等多方面的影响,被用来描述各种网络资源,其出现为人们在Web上发布结构化数据提供一个标准的数据描述框架。
使用RDF语言,有利于在网络上形成人机可读,并可由机器自动处理的文件。
1. 由来
RDF的出现最初来源于元数据的概念。所谓元数据,即“描述数据的数据”或者“描述信息的信息”。举个例子,电脑里保存的数码照片都包含一些关于尺寸、创建时间、感光度等额外属性信息,它们就是一种用来描述二进制图片数据的元数据。元数据是一种结构化形式的数据,机器处理起来十分方便。

EXIF_information
90年代有个叫Guha的人,在苹果公司研究各种各样的元数据格式来管理图片音频等数据,RSS就是他在那个时候发明的,随后在1997年他又发明了RDF。接着人们发现RDF这种形式非常适合用于在万维网上对知识的结构化表示,于是在1999年,RDF被W3C推为行业推荐标准。
2. 模型定义
RDF提出了一个简单的二元关系模型来表示事物之间的语义关系,即使用三元组集合的方式来描述事物和关系。三元组是知识图谱中知识表示的基本单位,简称SPO,三元组被用来表示实体与实体之间的关系,或者实体的某个属性的属性值是什么。
从内容上看三元组的结构为 “资源-属性-属性值” ,资源实体由URI表示,属性值可以是另一个资源实体的URI,也可以是某种数据类型的值,也称为literals(字面量)。
主语和宾语也可以由第三种结点类型空节点(blank nodes)表示。blank node简单来说就是没有IRI和literal的资源,或者说匿名资源。
由于RDF规定资源的命名必须使用URI,所以也直接解决了命名空间的问题。这里我们具体说一下IRI,URI,URL和URN这几个术语的区别:
-
URI:统一资源标识符,字符集被限制为US-ASCII(英文字符),通过指定唯一名称来标识资源;
-
IRI:国际化资源标识符(Internationalized Resource Identifier),定义与URI相同,URI,只是将字符集扩展到通用字符集(包含了非英文字符),所以它是URI的超集,同样唯一标识了一个资源;
-
URN: 统一资源名称(Uniform Resource Name),由命名空间标识符(NID)和命名空间特定字符串(NSS)组成;
-
URL:统一资源定位符,即我们通常提到的网址,通常指的是不包含URN的URI子集
以及它们的集合包涵关系:
-
IRI ⊃ URI
-
URI ⊃ URL
-
URI ⊃ URN
-
URL ∩ URN = ∅
3.RDF与XML的比较
RDF最初的灵感一部分也来源于xml,可以看成xml的扩展和简化。xml最初被设计用于网络之间数据的传输,语法类似于html,但是可以自行定义标签的名字。这个特点非常适合定义符合各自要求的数据格式,也使得xml具有更强大的表达能力,不过因此也导致XML数据的结构过于松散随意,其统一性和通用性受到了严重限制。读者通常需要对xml Schema文件(xmls)有足够的详细了解之后才可以完全理解xml文件背后的语义信息。
RDF和xml相比还是有很大的差别,下面通过两者比较来更好地了解RDF的优点。
-
模型更灵活。XML是被设定为固定的、树状的文本,其描述元数据的能力缺乏一定的灵活性。相比而言,RDF采用简单明了的三元组形式,以及互联形成的图结构,具备足够的灵活性来描述网络上许多主观的、分布式的、不同形式表达的资源对象。
-
RDF最初是被作为元数据语言设计的,其表达形式天然具备保存数据对象的描述型元数据的能力,自带语义解释。而XML最初的语义解释包含在另一个schema文件中,获取并解析相对麻烦很多,导致XML语言进行元数据建模,描述数据的灵活性非常差。
让我们看看下面这个RDF三元组的例子,比如“这个网页的作者是Ora”这句话,转化为三元组就是 (网页,作者,Ora),用图形表示就是:

Page_hasAuthor
但是如果用xml表示,形式就可能非常多样和复杂,导致语义不清的问题,比如下面这些结构的xml都可能出现:
在不了解xml文档的schema的前提下,除非标签的命名非常清晰易懂,否则你很难分辨推断出,到底哪个标签里的内容是另一个标签里内容的属性或者什么(语义不清)。
3.1 用xml格式表示RDF数据

Yangtze
不过w3c还是给出了一套如何用xml表示RDF数据的XML schema词汇,下图所示是 中国长江(Yangtze)作为一个RDF实体用xml表示的形式:
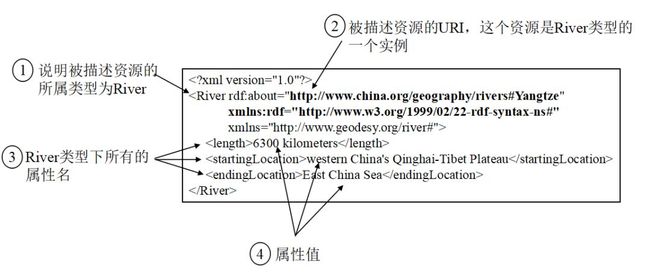
rdf xml
Description说明这是rdf里一条三元组陈述,about是主语资源的URI,s:Creator是属性名,后面跟着宾语属性值。
不过XML的形式太过冗长,且可读性差,后面会介绍更好的RDF序列化方式。
4. RDF解决的语义问题
RDF的最大意义在于,它不仅是字符串构成的符号,还包含了语义信息。
语义通常指的是符号与所指对象之间的关系。人可以根据自己的知识储备理解符号与符号之间的语义关系,比如你在新闻里读到“任正非”三个字,或者别人向你说起“任正非”,你都会将这些符号和你脑海中的一个对象或者影像联系,再综合过往收集到的和这个对象相关的信息,从而理解符号背后的含义。
那么计算机是否也可以为世界上的每一个实体,定义一个唯一的锚(也就是URI),所有与这个实体相关的信息(文字、图像等等),都会被这个锚钩住。
这正是RDF可以表达语义信息的一个原因。在三元组模型中,主体、客体可以是通过URI引用的资源,这些URI是独立于RDF文档中的符号存在的,唯一表示了存在于这个世界的某个资源,也即代表了对象本身而不仅仅是符号,如此RDF就表达出了符号和对象之间的关系,这是一种可以被计算机理解的语义。
比如还是上面那个中国长江的例子,我们有两份关于描述中国长江(Yangtze)的RDF文档,它们虽然分布在不同位置,但是却共用同一个URI,因此计算机可以把他们联系起一起处理。当用户搜索长江的时候,搜索引擎可以通过知识融合工具,把两份RDF描述整合一起返回。这也是RDF的分布式存储功能。

分布式rdf的聚合
5. 序列化方式
RDF是以一种建模的方式来描述数据语义,不受具体语法表示的限制,序列化的方式有多种。数据序列化就是将对象或者转化成特定的格式,使其可在网络中传输,或者存储在文件中。
序列化RDF数据的方法主要有这几种:RDF/XML,N-Triples,Turtle,RDFa,JSON-LD。
其中Turtle 是使用最广泛的RDF序列化方式,其格式紧凑,易于阅读。下面是w3c上RDF定义文档中的一部分内容,定义文档本身就采用了三元组来描述RDF中的专用词汇,因此可以用Turtle的形式展示出来:
上述片段是对RDF中的rdf:type这个词汇的描述。因为URI很长,一般我们都会使用缩写。Turtle使用 @prefix 对RDF的URI前缀进行缩写,rdf:表示URI前缀 http://www.w3.org/1999/02/22-rdf-syntax-ns#,因此rdf:type就是http://www.w3.org/1999/02/22-rdf-syntax-ns#type的简写。
文档中出现的谓词 a 是rdf:type的简写,这是Turtle语法中的一种常用简写,用于说明实体的类型是什么。
同一个subject实体拥有多种关系的时候,Turtle语法允许只出现一次subject来表示,通过分号分隔不同的关系,最后英文句号“.”说明与主语实体的所有关系已经说明完毕。这样就避免了subject主体像下面这样的重复出现。
关于RDF的介绍就先说到这里,后续会给大家在说一说一些关于RDFs和OWL的基本知识。
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
欢迎关注PyTorch官方中文教程站:
http://pytorch.panchuang.net/