都说金三银四是找工作的最佳时节,由于本人的个人职业规划跟目前工作内容不太相符(具体原因就不透露了,领导平时也要来这里逛,哈哈),四月份挑选了10多家公司投递简历(公司规模从几十人到上万人都有),参加了7家公司的电话面试,收获了5个offer,也还算不错。下面就分享一下面试过程中一些基础的,又最常见的问题。不啰嗦了,直接看题。
1、synchronized你用过吗?synchronized和Lock的区别?synchronized偏向锁的获取和撤销?
前2个问题,之前在多线程专题有详细的介绍,欢迎阅读《java线程间的共享》和《java之AQS和显式锁》。这里着重分析一下第三个问题。
对于synchronized这个关键字,鄙人刚实习还是一只菜鸡的时候,就听周围的大神说,synchronized是一个重量级锁,开销很大要少用,本菜只能一脸崇拜(一脸懵逼)的看着他们,不明觉厉。但是本菜也不能一直菜下去是不是,所以也打算对synchronized的原理进行学习,看下大神们为什么要这样说。其他的都不管,遇到问题先百度,查看了各种博客,各种资料,其实发现并不像大神们说的那样子,毕竟JDK团队也不能忍受世界各地的程序员对他们无休止的吐槽,所以在JDK1.6就对synchronized进行了大量的优化,在JDK1.6之前synchronized的实现统一采用重量级锁(线程阻塞)来实现的。本菜刚工作的时候就有JDK1.8了,所以周围的大神对synchronized的认识可能还停留在JDK1.6之前。
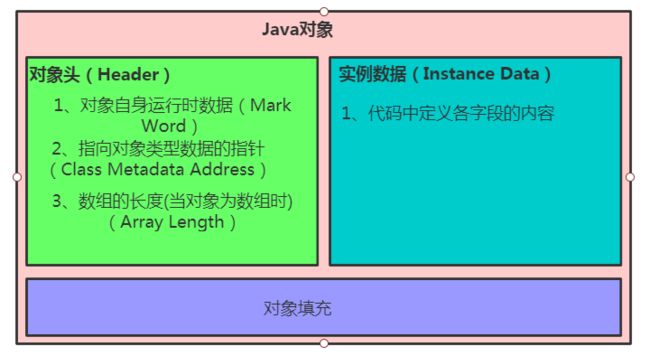
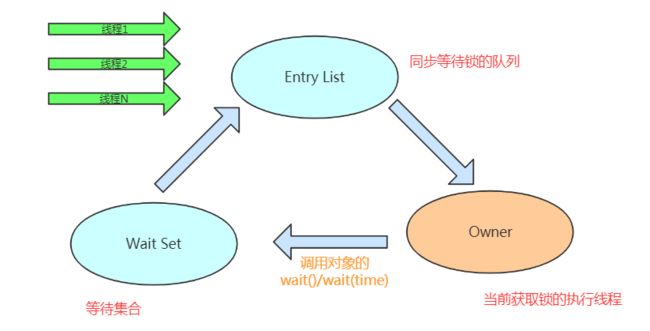
还是先补习一下synchronized的基本知识:锁实际上是加在对象上的,那么被加了锁的对象我们称之为锁对象,在Java中任何一个对象都能成为锁对象。很明显,这里的重点在于这个对象,先看一下对象在虚拟机中是如何保存的。Java对象在内存中的存储结构主要有三个部分:对象头、实例数据和填充部分,用一张图来说明。
跟锁相关的东西是存在Mark Word中,直接来看一下在32位虚拟中Mark Word的存储内容,看图。
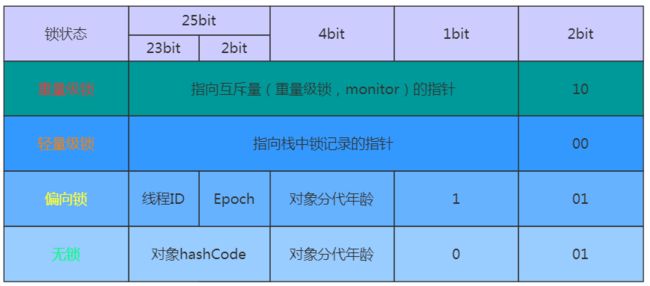
先看一下synchronized锁的几种状态:无锁状态、偏向锁状态、轻量级锁状态、重量级锁状态。它会随着线程竞争情况逐渐升级,但不能降级,目的是为了提高获得锁和释放锁的效率。
偏向锁
引入背景:大多数情况下锁不仅不存在多线程竞争,而且总是由同一线程多次获得,为了让线程获得锁的代价更低而引入了偏向锁,减少不必要的CAS 操作,对CAS操作不熟悉的同学欢迎阅读《java原子操作CAS》。偏向锁,顾名思义,这个锁会偏向于第一个获得它的线程,在接下来的执行过程中,假如该锁没有被其他线程所获取,没有其他线程来竞争该锁,那么持有偏向锁的线程将永远不需要进行同步操作。如果在运行过程中,遇到了其他线程抢占锁,则持有偏向锁的线程会被挂起,JVM 会撤销它身上的偏向锁,将锁升级到轻量级锁。
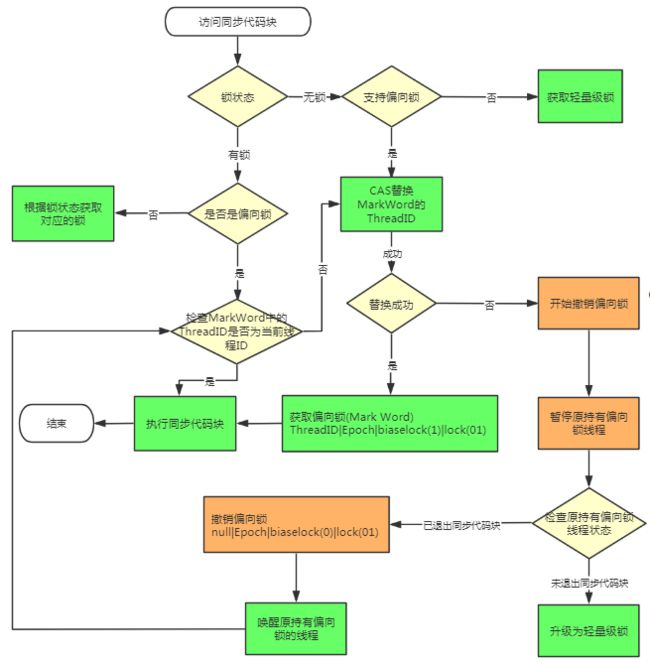
偏向锁的获取和撤销过程:
1)访问Mark Word 中偏向锁的标识是否设置成1,锁标志位是否为01,确认为可偏向状态。
2)如果为可偏向状态,则判断线程ID是否指向当前线程,如果是进入步骤5,否则进入步骤3。
3)如果线程ID并未指向当前线程,则通过CAS 操作竞争锁。如果竞争成功,则将Mark Word 中线程ID设置为当前线程ID,然后执行步骤5;如果竞争失败则执行步骤4。
4)如果CAS获取偏向锁失败,则表示有竞争。当到达全局安全点(safepoint)时获得偏向锁的线程被挂起,偏向锁升级为轻量级锁,然后被阻塞在安全点的线程继续往下执行同步代码。(撤销偏向锁的时候会导致stop the world)。
5)执行同步代码。
偏向锁是否开启可以使用JVM的参数来控制:
开启偏向锁:-XX:+UseBiasedLocking -XX:BiasedLockingStartupDelay=0
关闭偏向锁:-XX:-UseBiasedLocking
文字描述太过抽象,还是画一图个来理解。
轻量级锁
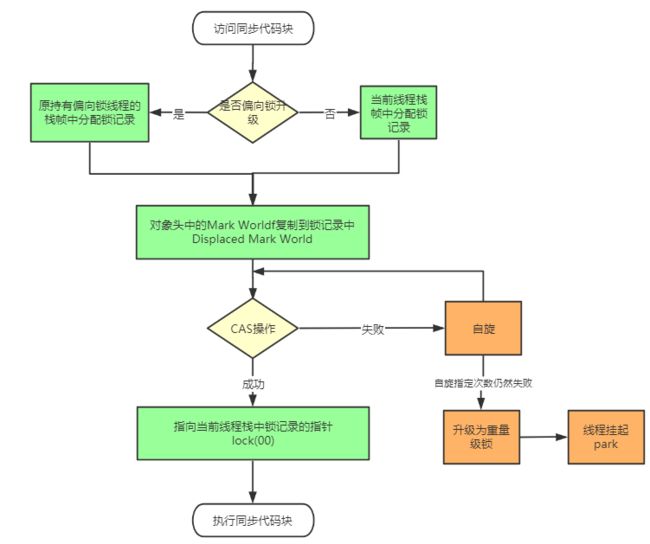
轻量级锁是由偏向锁升级来的,偏向锁运行在一个线程进入同步块的情况下,当第二个线程加入锁争用的时候,偏向锁就会升级为轻量级锁。
轻量级锁的加锁过程:在代码进入同步块的时候,如果同步对象锁状态为无锁状态且不允许进行偏向(锁标志位为“01”状态,是否为偏向锁为“0”),虚拟机首先将在当前线程的栈帧中建立一个名为锁记录(LockRecord)的空间,用于存储锁对象目前的Mark Word 的拷贝,官方称之为Displaced Mark Word。拷贝成功后,虚拟机将使用CAS 操作尝试将对象的Mark Word 更新为指向LockRecord 的指针,并将Lock Record里的owner 指针指向object mark word。如果这个更新动作成功了,那么这个线程就拥有了该对象的锁,并且对象Mark Word 的锁标志位设置为“00”,即表示此对象处于轻量级锁定状态。如果这个更新操作失败了,虚拟机首先会检查对象的Mark Word 是否指向当前线程的栈帧,如果是就说明当前线程已经拥有了这个对象的锁,那就可以直接进入同步块继续执行。否则说明多个线程竞争锁,当竞争线程尝试占用轻量级锁失败多次之后,轻量级锁就会膨胀为重量级锁,重量级线程指针指向竞争线程,竞争线程也会阻塞,等待轻量级线程释放锁后唤醒他。锁标志的状态值变为“10”,Mark Word中存储的就是指向重量级锁(互斥量)的指针,后面等待锁的线程也要进入阻塞状态。
自旋次数可以通过虚拟机参数-XX:PreBlockSpin来进行更改,默认为10。
上述流程还是画一个图来理解。
重量级锁
重量级锁大家都比较了解,重量级锁是依赖对象内部的monitor锁来实现的,而monitor又依赖操作系统的MutexLock(互斥锁)来实现的,所以重量级锁也被成为互斥锁。所以大神们说synchronized开销大,针对的是重量级锁而言。主要原因是升级到重量级锁之后,会把等待想要获得锁的线程进行阻塞,被阻塞的线程不会消耗cup。但是阻塞或者唤醒一个线程时,都需要操作系统来帮忙,进行状态转换。状态转换是需要消耗很多时间的,有可能比用户执行代码的时间还要长。还是画一个经典的图来理解。
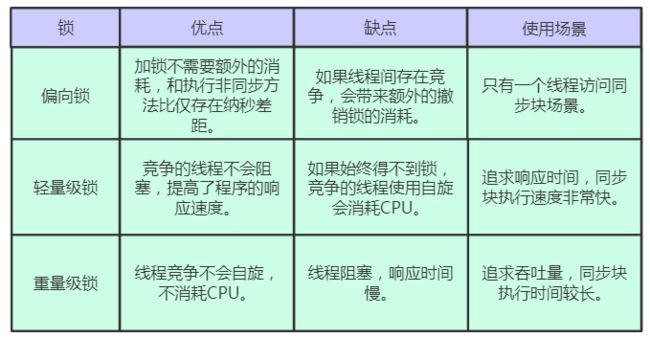
我们把几种锁进行一个比较,直接上图。
当然面试时候还有一些其他的问题也非常常见,比如说synchronized是乐观锁还是悲观锁?乐观锁一定比悲观锁好吗?使用CAS机制的3大问题?请谈谈AQS是怎么回事儿?ReentrantLock是如何实现可重入性的?如何让Java的线程彼此同步?你了解过哪些同步器?用过线程池吗,介绍一下线程池的各个构造参数以及线程池的运行原理?请谈谈 volatile 有什么作用,以及volatile和synchronized的区别?你用过ThreadlLocal吗,请谈谈你的使用场景以及原理?什么是不可变对象,它对写并发有什么帮助?除了第一个问题留给大家思考,其余问题相关的答案都可以在我之前写的《Java并发编程》专题可以找到答案,掌握了这些,面试时候再也不怕多线程相关的问题,也可以实际运用到我们的项目中。
2、Redis的持久化
Redis的数据全部在内存中,如果突然宕机,数据就会全部丢失,因此必须有一种机制来保证Redis的数据在遇到突发状况的时候不会丢失,或者只丢失少量,于是必须根据一些策略来把Redis内存中的数据写到磁盘中,这样当Redis服务重启中,就可以根据磁盘中的数据来恢复数据到内存中。
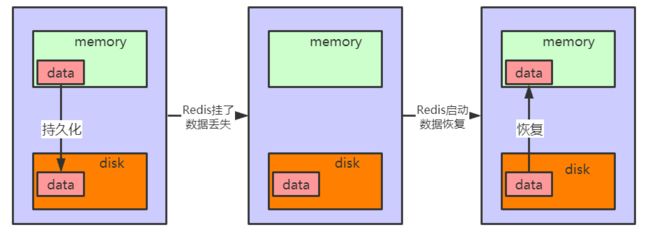
Redis的持久化机制:AOF、RDB以及混合持久化(4.0版本以后支持,后续的Redis专题详细介绍)。
1)RDB
RDB(快照)持久化:保存某个时间点的全量数据快照。
RDB是一次的全量备份,即周期性的把Redis当前内存中的全量数据写入到一个快照文件中。Redis是单线程程序,这个线程要同时负责多个客户端的读写请求,还要负责周期性的把当前内存中的数据写到快照文件中RDB中,数据写到RDB文件是IO操作,IO操作会严重影响Redis的性能,甚至在持久化的过程中,读写请求会阻塞,为了解决这些问题,Redis需要同时进行读写请求和持久化操作,这样又会导致另外的问题,持久化的过程中,内存中的数据还在改变,假如Redis正在进行持久化一个大的数据结构,在这个过程中客户端发送一个删除请求,把这个大的数据结构删掉了,这时候持久化的动作还没有完成,那么Redis该怎么办呢?
Redis使用操作系统的多进程写时复制机制(Copy On Write)机制来实现快照的持久化,在持久化过程中调用glibc(Linux下的C函数库)的函数fork()产生一个子进程,快照持久化完全交给子进程来处理,父进程继续处理客户端的读写请求。子进程刚刚产生时,和父进程共享内存里面的代码段和数据段,这是Linux操作系统的机制,为了节约内存资源,所以尽可能让父子进程共享内存,这样在进程分离的一瞬间,内存的增长几乎没有明显变化。
简单介绍一下写时复制和fork。
fork:fork()函数通过系统调用创建一个与原来进程几乎完全相同的进程,也就是两个进程可以做完全相同的事,但如果初始参数或者传入的变量不同,两个进程也可以做不同的事。一个进程调用fork()函数后,系统先给新的进程分配资源,例如存储数据和代码的空间。然后把原来的进程的所有值都复制到新的新进程中,只有少数值与原来的进程的值不同,相当于克隆了一个自己。
写时复制(Copy On Write):
资源的复制只有在需要写入的时候才进行,在此之前,只是以只读方式共享。这种技术使地址空间上的页的拷贝被推迟到实际发生写入的时候。在Linux程序中,fork()会产生一个和父进程完全相同的子进程,子进程在此后会调用exec()开始执行。
所以对于上面的那个问题,处理方式是子进程对当前内存中的数据进行持久化,并不会修改当前的数据结构,如果父进程收到了读写请求,那么会把处理的那一部分数据复制一份到内存,对复制后的数据进行修改,所以即使对某个数据进行了修改,Redis持久化到RDB中的数据也是未修改的数据,这也是把RDB文件称为"快照"文件的原因,子进程所看到的数据在它被创建的一瞬间就固定下来了,父进程修改的某个数据只是该数据的复制品。这里再深入一点,Redis内存中的全量数据由一个个的"数据段页面"组成,每个数据段页面的大小为4K,客户端要修改的数据在哪个页面中,就会复制一份这个页面到内存中,这个复制的过程称为"页面分离",在持久化过程中,随着分离出的页面越来越多,内存就会持续增长,但是不会超过原内存的2倍,因为在一次持久化的过程中,几乎不会出现所有的页面都会分离的情况,读写请求针对的只是原数据中的小部分,大部分Redis数据还是"冷数据"。用一个图来表示。
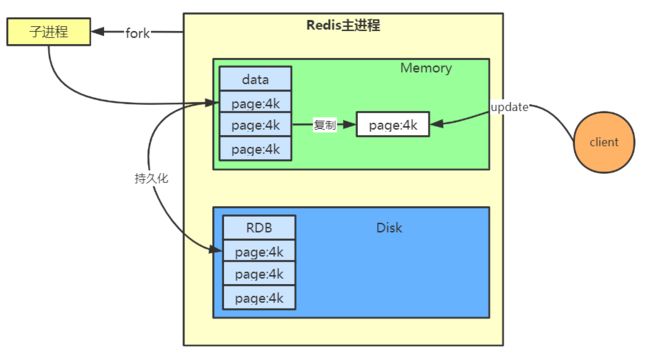
对RDB快照持久化过程做一个总结:
① Redis使用fork函数复制一份当前进程的副本(子进程)。
② 父进程继续接收并处理客户端发来的命令,而子进程开始将内存中的数据写入硬盘中的临时文件。
③ 当子进程写入完所有数据后会用该临时文件替换旧的RDB文件,至此,一次快照操作完成。
注意:Redis在进行快照的过程中不会修改RDB文件,只有快照结束后才会将旧的文件替换成新的,也就是说任何时候RDB文件都是完整的。 这就使得我们可以通过定时备份RDB文件来实现Redis数据库的
备份, RDB文件是经过压缩的二进制文件,占用的空间会小于内存中的数据,更加利于传输。
RDB快照产生方式:
手动触发
①SAVE:阻塞Redis的服务器进程,知道RDB文件被创建完毕。
②BGSAVE:fork出一个子进程来创建RDB文件,不阻塞服务器进程。lastsave指令可以查看最近的备份时间。
自动触发
①根据Redis.conf配置里的save m n定时触发(用的是BGSAVE)

②主从复制时,主节点自动触发
③执行Debug Relaod
④执行Shutdown且没有开启AOF持久化
了解了以上内容,我们可以画一个图来表示RDB快照持久化的流程。
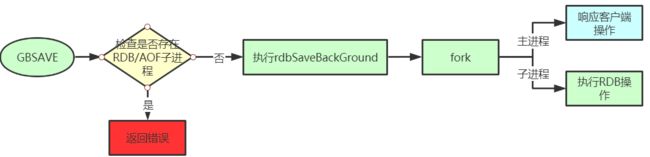
2)AOF
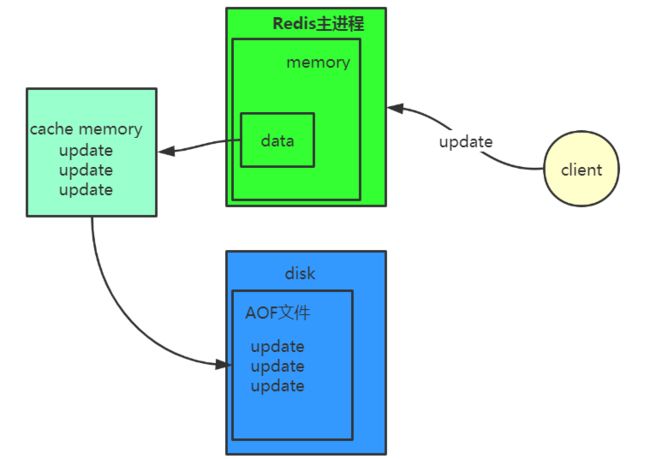
AOF日志存储的是Redis服务器的顺序指令序列,即对内存中数据进行修改的指令记录。当Redis收到客户端修改指令后,先进行参数校验,如果校验通过,先把该指令存储到AOF日志文件中,也就是先存到磁盘,然后再执行该修改指令。当Redis宕机后重启后,可以读取该AOF文件中的指令,进行数据恢复,恢复的过程就是把记录的指令再顺序执行一次,这样就可以恢复到宕机之前的状态。用一个图来表示AOF的过程。
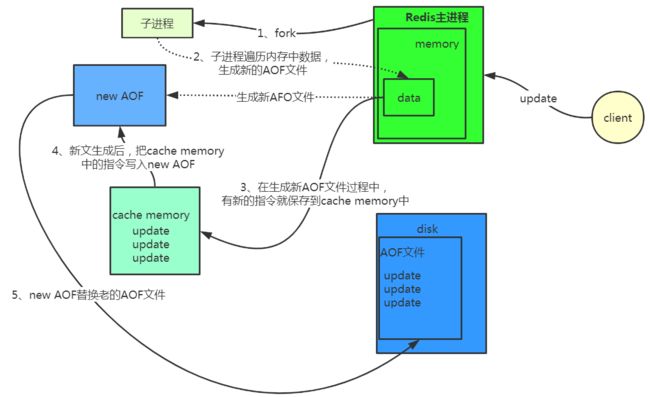
Redis在长期运行过程中,AOF日志会越来越大,如果Redis服务重启后根据很大的AOF文件来顺序执行指令,将会非常耗时,导致Redis服务长时间无法对外提供服务,所以需要对AOF文件进行"减肥"。"减肥"的过程称作AOF重写(rewrite)。AOF Rewrite 的原理是,主进程fork一个子进程,对当前内存中的数据进行遍历,转换成一系列的Redis操作指令,并序列化到一个新的AOF日志中,然后把序列化操作期间新收到的操作指令追加到新的AOF文件中,追加完毕后就立即替换旧的AOF文件,这样就完成了"减肥"工作。Redis把操作指令追加到AOF文件这个过程,并不是直接写到AOF文件中,而是先写到操作系统的内存缓存中,这个内存缓存是由操作系统内核分配的,然后操作系统内核会异步地把内存缓存中的Redis操作指令刷写到AOF文件中。用一个图来表示。
AOF相关参数配置:

简单对重写的几个参数做一个说明:比如说上一次AOF rewrite之后,是128mb然后就会接着128mb继续写AOF的日志,如果发现增长的比例,超过了之前的100%,256mb,就可能会去触发一次rewrite
但是此时还要去跟min-size,64mb去比较,256mb > 64mb,才会去触发rewrite。
我们对Redis持久化机制做一个对比:
RDB的优缺点:
优点:
① RDB会生成多个数据文件,每个数据文件都代表了某一个时刻中Redis的数据,这种多个数据文件的方式,非常适合做冷备,可以将这种完整的数据文件发送到一些远程的安全存储上去。
② 当进行RDB持久化时,对Redis服务处理读写请求的影响非常小,可以让Redis保持高性能,因为Redis主进程只需要fork一个子进程,让子进程执行磁盘IO操作来进行RDB持久化即可。生成一次RDB文件的过程就是把当前时刻内存中的数据一次性写入文件中,而AOF则需要先把当前内存中的小量数据转换为操作指令,然后把指令写到内存缓存中,然后再刷写入磁盘。
③ 相对于AOF持久化机制来说,直接基于RDB数据文件来重启和恢复Redis的数据会更加快速。AOF,存放的是指令日志,做数据恢复的时候,要回放和执行所有的指令日志,从而恢复内存中的
所有数据。而RDB,就是一份数据文件,恢复的时候,直接加载到内存中即可。
缺点:
① 如果想要在Redis故障时,尽可能少的丢失数据,那么RDB没有AOF好。一般来说,RDB数据快照文件,都是每隔5分钟,或者更长时间生成一次,这个时候就得接受一旦Redis进程宕机,那么会
丢失最近5分钟的数据。这个问题,也是RDB最大的缺点,就是不适合做第一优先的恢复方案,如果你依赖RDB做第一优先恢复方案,会导致数据丢失的比较多。
② RDB每次在fork子进程来执行RDB快照数据文件生成的时候,如果数据文件特别大,可能会导致对客户端提供的服务暂停数毫秒,甚至数秒。所以一般不要让生成RDB文件的间隔太长,否则每次生成的RDB文件太大了,对Redis本身的性能会有影响。
AOF的优缺点:
优点:
① AOF可以更好的保护数据不丢失,一般AOF会每隔1秒,通过一个后台线程执行一次fsync操作,最多丢失1秒钟的数据。
② AOF日志文件以append-only模式写入,所以没有任何磁盘寻址的开销,写入性能非常高,而且文件不容易破损,即使文件尾部破损,也很容易修复。
③ AOF日志文件即使过大的时候,出现后台重写操作,也不会影响客户端的读写。因为在rewrite的时候,会对其中的指令进行压缩,会创建出一份需要恢复数据的最小日志出来。
④ AOF日志文件的命令通过非常可读的方式进行记录,这个特性非常适合做灾难性的误删除的紧急恢复。比如某人不小心用flushall命令清空了所有数据,只要这个时候后台rewrite还没有发生,那么就可以立即拷贝AOF文件,将最后一条flushall命令给删了,然后再将该AOF文件放回去,就可以通过恢复机制,自动恢复所有数据。
缺点:
① 对于同一份数据来说,AOF日志文件通常比RDB数据快照文件更大。
② AOF的写性能比RDB的写性能低,因为AOF一般会配置成每秒fsync一次日志文件,当然,每秒一次fsync,性能也还是很高的,只不过比起RDB来说性能低,如果要保证一条数据都不丢,也是可以的,AOF的fsync设置成每写入一条数据,fsync一次,但是这样,Redis的性能会大大下降。
③ 基于AOF文件做恢复的速度不如基于RDB文件做恢复的速度。
那么我们在实际项目中该怎么选择Redis的持久化方案呢?这里简单的给出我个人的建议:
① 不要仅仅使用RDB,因为那样会导致你丢失很多数据
② 也不要仅仅使用AOF,一是数据恢复慢,二是可靠性也不如RDB,毕竟RDB文件中存储的就是某一时刻实实在在的数据,而AOF只是操作指令,把数据转换为操作指令不一定是百分百没问题的。
③ 综合使用AOF和RDB两种持久化机制,用AOF来保证数据不丢失,作为数据恢复的第一选择; 用RDB来做不同程度的冷备,在AOF文件都丢失或损坏不可用的时候,还可以使用RDB来进行快速的
数据恢复。
关于Redis还有很多常见的面试题,比如说Redis单线程为什么还如此快?Redis的数据类型以及使用场景?Redis的高可用方案?你说你用了哨兵集群,那么谈谈脑裂场景怎么解决?Redis怎么实现分布式锁以及会遇到的问题,你这么解决这些问题?Redis的缓存击穿、缓存穿透、缓存雪崩是什么,怎么解决?Redis和DB数据一致性问题解决方案?Redis支持事务吗,具体是怎么样的?这些知识点会在后续的Redis专题中介绍。
最后再分享一下在面试中的一些心得体会。一般开场都会让自我介绍,自我介绍的时候一定要流畅,可以事先练习,千万不要结结巴巴。把最熟悉的知识点写在最前面,面试官一般会按照你简历上写的顺序去问。比如你把多线程写在最前面,一般都会聊到synchronized、Lock以及多线程在项目中实际的运用(这个一定要准备),既然都问到了锁,那么分布式锁肯定会引申出来。比如你回答了分布式锁是使用Redis实现的,既然扯到了Redis上面,上述我列出的这些问题大概率会出现。Redis都聊了,那么不聊一下关系型数据库好像不太好吧,如果你简历上写了熟悉MySQL,那么来聊聊MySQL。关于MySQL,肯定就会问到MySQL的存储引擎。嗯,你说你用的是InnoDB、MyISAM引擎,那么就聊聊这2个引擎区别。区别说完了,那你再说一下InnoDB引擎的索引以及聚集索引和非聚集索引,你把Hash、B+Tree的原理给说清楚,接下来肯定就是问你在项目中对MySQL的实际优化经验,那么慢查询、执行计划分析、表创建的技巧、索引的创建技巧、SQL编写的技巧肯定会随之而来。既然聊到了优化,那么接下来就再说说JVM相关的知识,从内存模型到垃圾回收算法、垃圾回收器、类加载机制、内存泄漏等,最后再到问你线上环境有过实际的调优经验吗,怎么实现的?这些都回答完了,可能还会来一个开放性的问题,比如说一个生产环境,上线半个小时,Full GC发生了上百次,而Minor GC只发生了几次,请你分析下可能是什么原因造成?再或者说,一个生产环境,没有报OOM,但是用户线程也没有执行了,直观现象就是应用没有日志输出,请你分析下可能是什么原因造成的?这些都是面试过程中Java基础部分最常见的问题,这些聊完了后面就会涉及到框架、项目相关的问题。在自己擅长的部分尽量多聊一会儿,不要被面试官牵着鼻子走,毕竟面试时间就那么长,这样就尽可能的扬长避短。在面试过程中,尽量把没有答上的问题记下来,面试完了做一个总结,看是因为什么原因没答上来,是的确不知道还是因为表达不清晰还是过于紧张。多参加几次面试后会发现,基础部分的问题其实都大同小异,情绪也不会那么紧张,此时收割offer的概率那就大大地提高咯。
参考资料:《Java并发编程的艺术》、《Redis实战》