统计推断——假设检验——两变量关联性分析
一、线性相关描述
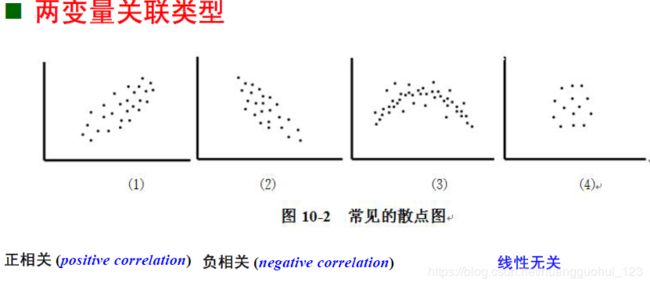
问题:两变量间是否存在相关或关联?
身高与体重
尿铅排出量与血铅含量
凝血时间与凝血酶浓度
血压与年龄
1、线性相关
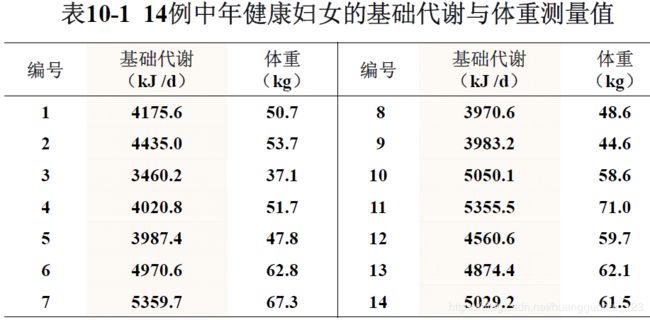
例 在某地一项膳食调查中,随机抽取了14名40~60岁的健康妇女,测得每人的基础代谢(kJ /d)与体重(kg)数据,见表。据此数据如何判断这两变量间有无关联?

变量X和Y相关系数的详细公式如下:
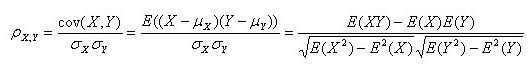
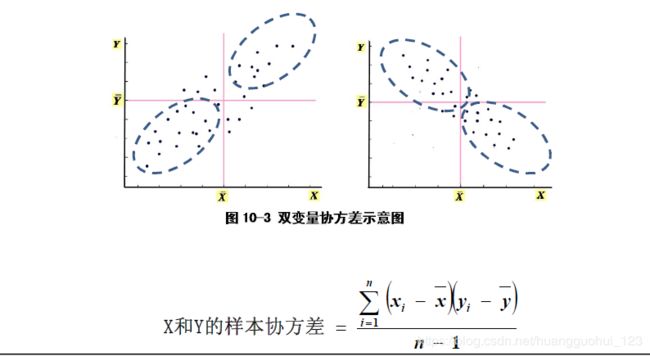

例 计算上个例子中基础代谢Y与体重X之间的样本相关系数。
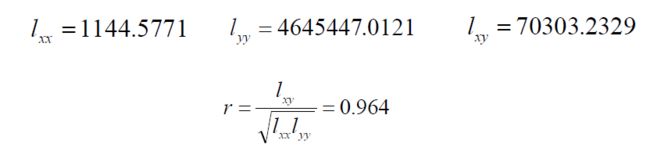
说明该14名40~60岁健康妇女的基础代谢和体重之间呈正相关,相关程度较大。
2、相关系数的种类
2.1、Pearson(皮尔逊)线性相关系数
 被称为随机变量X和Y的Pearson线性相关系数。
被称为随机变量X和Y的Pearson线性相关系数。
当两个变量的标准差都不为零时,相关系数才有定义,皮尔逊相关系数适用于:两个变量之间是线性关系,都是连续数据,可以使用散点图查看;两个变量的总体是正态分布,或接近正态的单峰分布;两个变量的观测值是成对的,每对观测值之间相互独立。
皮尔逊相关系数的经验解释如下。
①当![]() 时,可视为两个变量之间高度相关。
时,可视为两个变量之间高度相关。
②当![]() 时,可视为两个变量之间中度相关。
时,可视为两个变量之间中度相关。
③当![]() 时,可视为两个变量之间低度相关。
时,可视为两个变量之间低度相关。
④当![]() 时,说明两个变量之间的相关程度极弱,可视为不相关。
时,说明两个变量之间的相关程度极弱,可视为不相关。
2.2、Spearman(斯皮尔曼)等级相关系数
斯皮尔曼相关系数是根据等级资料研究两个变量之间相关关系的方法。它是依据两列成对等级的各对等级数之差来进行计算的,所以又被称为“等级差数法”。其计算公式为:
其中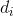 为等级差(秩次差
为等级差(秩次差![]() ,
, 和
和 为
为 和
和 编秩之后的结果),
编秩之后的结果), :[-1.1]
:[-1.1]
等级相关系数是建立在等级的基础上计算的,比较适用于反映序列变量的相关。等级相关系数和通常的相关系数一样,它与样本的容量有关,尤其是在样本容量比较小的情况下,其变异程度较大,等级相关系数的显著性检验与普通的相关系数的显著性检验相同。
斯皮尔曼相关系数对数据条件的要求没有皮尔逊相关系数严格,只要两个变量的观测值是成对的等级评定资料,或者是由连续变量观测资料转化得到的等级资料,不论两个变量的总体分布形态、样本容量的大小如何,都可以用斯皮尔曼等级相关系数来进行研究。
2.3、Kendall(肯德尔)等级相关系数
肯德尔相关系数用希腊字母 (
(![]() )是一个用来测量两个随机变量相关性的统计量。肯德尔检验是无参数假设检验,它使用计算而得的相关系数去检验两个随机变量的统计依赖性,肯德尔相关系数的计算公式有3种,这个仅介绍其中一个计算公式:
)是一个用来测量两个随机变量相关性的统计量。肯德尔检验是无参数假设检验,它使用计算而得的相关系数去检验两个随机变量的统计依赖性,肯德尔相关系数的计算公式有3种,这个仅介绍其中一个计算公式:
其中C表示X和Y种拥有一致性的元素对数(两个元素为一对)
D表示X和Y中拥有不一致性的元素对数。
需要注意的是,上述公式仅适用于集合X与Y中均不存在相同元素的情况(集合中各个元素唯一)。肯德尔相关系数与斯皮尔曼相关系数对数据条件的要求相同。肯德尔相关系数的取值范围在-1~1,当为1时,表示两个随机变量拥有一致的等级相关性;当为-1时,表示两个随机变量拥有完全相反的等级相关性;当为0时,表示两个随机变量是相互独立的。
二、假设检验与秩相关
1、假设检验
例 计算例1中基础代谢 与体重
与体重 之间的样本相关系数。
之间的样本相关系数。
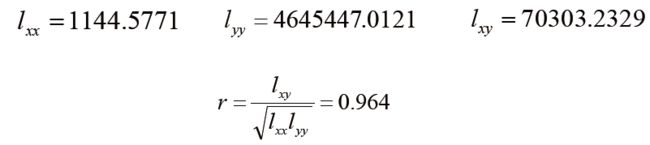
说明该14名40~60岁健康妇女的基础代谢和体重之间呈正相关,相关程度较大。
注意:以上=0.964仅仅是样本的相关系数,而我们关心的是在整体当中健康妇女的基础代谢和体重之间是否呈正相关?由于存在抽样误差,有时总体相关系数为0,得到的样本相关系数却不为0。所以要做线性相关系数的假设检验。
1.1、线性相关系数的统计推断
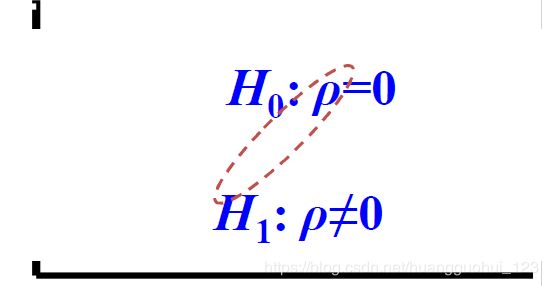
表示总体的相关系数。
1.2、常用的检验方法:
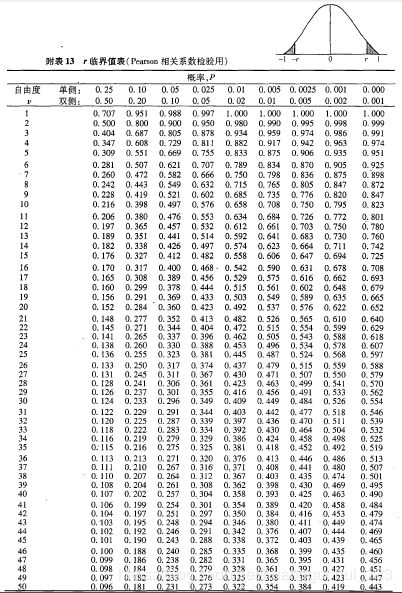
1. 查相关系数临界值表(样本量![]() ),自由度
),自由度![]()
2. 检验(样本量
检验(样本量![]() )
)
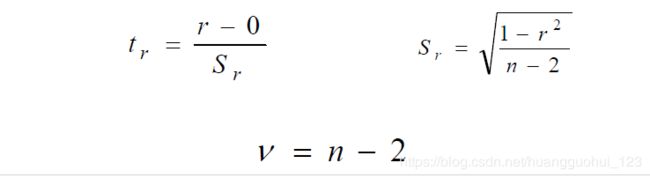
例 =0.964, 检验相关是否具有统计学意义。
检验:
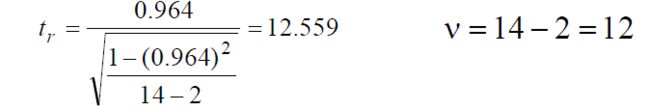
 <0.001。可认为40~60岁健康妇女的基础代谢与体重之间存在正相关。
<0.001。可认为40~60岁健康妇女的基础代谢与体重之间存在正相关。
1.3、总体相关系数的区间估计:

步骤:
1、对样本系数r做正曲正切变换,得到的z服从正态分布。
2、算出小z上下的95%置信区间。
3、对区间的上限、下限做反双曲正切变换。
例:=0.964, 试估计总体相关系数的95%置信区间。
![]()
(1.4086,2.5906)————>Z的上下限
(0.8872,0.9888)————>反双曲正切变换
【总结】两变量相关分析的步骤:
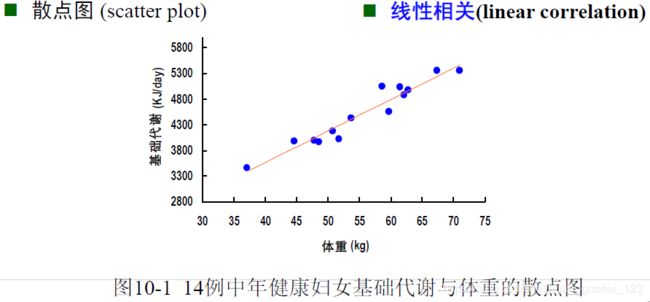
1、对随机变量x和y的相关关系利用散点图进行考察,是否有线性的趋势。
2、计算样本相关系数r。
3、假设检验:推断总体的相关系数是否为0。
4、计算总体相关系数的95%置信区间。
5、下结论:两变量(总体)是否有相关关系?相关密切程度如何?
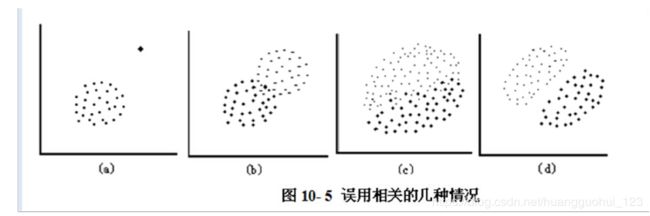
1.4、应注意的问题
1). 散点图显示变量间有线性趋势时,才进行相关分析
2). 线性相关适用于双变量正态分布资料
3). 正确理解相关关系,“相关不等于因果”
4). 出现异常值时慎用相关
5). 分层资料盲目合并易出假象。
2、秩相关
线性相关系数(Pearson correlation coefficient)
适用于:服从双变量正态分布;连续型定量资料。
秩相关(rank correlation, Spearman coefficient),或称等级相关。
适用于:不服从双变量正态分布;总体分布类型未知;数据本身有不确定值;等级资料。
例 某研究者研究10 例6 个月~7 岁的贫血患儿的血红蛋白含量与贫血体征之间的相关性,结果见表,试作秩相关分析。
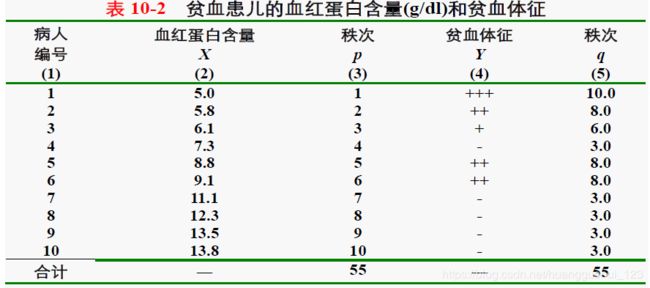
1、分别对、的观察值从小到大排序编秩,相同值取平均秩次。
2、以秩次代入公式计算
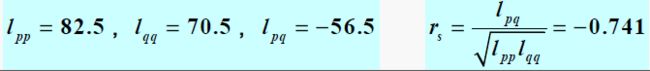
秩相关系数的假设检验
类似于积矩相关系数,关于秩相关系数的检验假设为
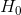 :
:![]() ,
, 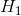 :
:![]() ,
, = 0.05
= 0.05
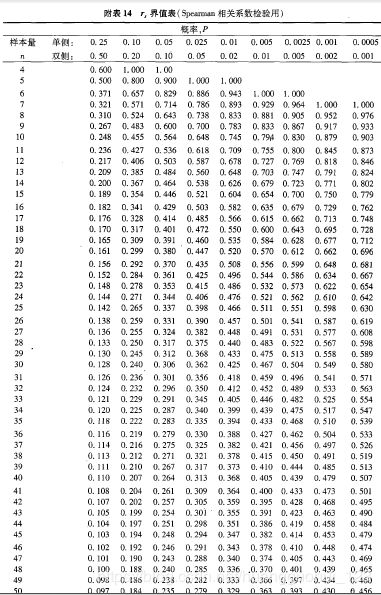
当 ≤50时,可 查书后关于秩相关系数的Spearman临界值表,若
≤50时,可 查书后关于秩相关系数的Spearman临界值表,若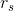 超过临界值,则拒绝 ;>50 时,也可采用式(10-5)和式(10-6)作检验。
超过临界值,则拒绝 ;>50 时,也可采用式(10-5)和式(10-6)作检验。
例 对以下例子的秩相关系数作假设检验。
例中算得=-0.741,= 10,查秩相关系数临界值表,![]() ,<0.05,按= 0.05 的水准,拒绝。可以认为
,<0.05,按= 0.05 的水准,拒绝。可以认为
贫血患儿的血红蛋白含量与贫血体征之间有负相关关系。
三、两个分类变量的关联分析
对分类变量间的联系,可作关联(association)分析
对两个分类变量交叉分类计数所得的频数资料(列联表)作关于两种属性独立性的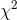 检验
检验
1、交叉分类2×2列联表
对样本量为的一份随机样本同时按照两个二项分类的特征(属性)进行交叉分类形成一个2×2交叉分类资料表,也称为2×2列联表(contingency table)。
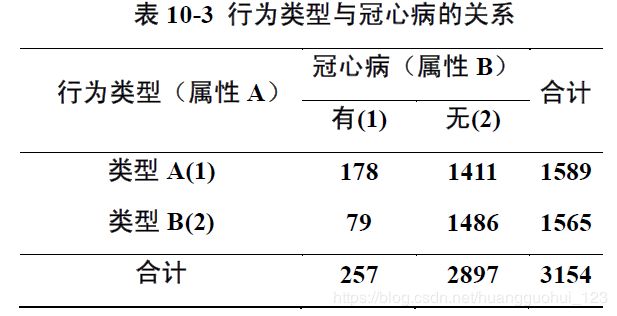
例:为观察行为类型与冠心病的关系,某研究组收集了一份包含3154个个体的样本,研究者将观察对象按行为类型分为A型(较具野心、进取心和有竞争性),B型(较沉着、轻松、和做事不慌忙)。对每个个体分别观察是否为冠心病患者和行为类型两种属性,2×2种结果
分类记数如下表所示。试分析两种属性的关联性。

注意:其中 表示实际频数,
表示实际频数,![]() 表示联合频率(概率),是联合属性A和B的概率,
表示联合频率(概率),是联合属性A和B的概率,![]() 和
和![]() 表示边缘频率(概率)。
表示边缘频率(概率)。
根据统计思想,如果A、B相互独立,则![]() (联合概率等于边缘概率的乘积)。
(联合概率等于边缘概率的乘积)。
:属性 A 与 B 互相独立, :属性 A 与 B 互相关联。
独立性检验就是考察![]() 成立与否。
成立与否。
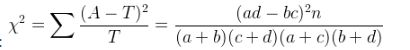
检验思想:其中![]() 表示理论频数,如果成立的条件下,则实际频数
表示理论频数,如果成立的条件下,则实际频数![]() 应该和理论频数
应该和理论频数![]() 很接近,我们就无法拒绝,如果差距很大,超过了偶然性的范畴,我们就可以拒绝,认为存在关联。和检验的思想完全一致。
很接近,我们就无法拒绝,如果差距很大,超过了偶然性的范畴,我们就可以拒绝,认为存在关联。和检验的思想完全一致。
:行为类型与冠心病之间互相独立
:行为类型与冠心病之间有关联
=0.05
将表中各数据代入公式(9-9),
![]() ,自由度为(r-1)(c-1)=1
,自由度为(r-1)(c-1)=1
![]() ,
,![]() , <0.05,说明行为类型与冠心病之间存在着关联性。
, <0.05,说明行为类型与冠心病之间存在着关联性。

从关联系数上看,虽然存在关联,但是关联的密切程度不大。
四、多分类资料的关联分析
1、两变量为无序分类
例 欲探讨职业类型与胃病类型是否有关联,某医生将收治的310名胃病患者按主要的职业类型与胃病类型两种属性交叉分类,结果见表。
问职业类型与胃病类型间有无关联?

:胃病类型与职业无关联
:胃病类型与职业有关联
=0.05
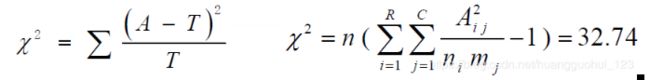
 表示行,
表示行, 表示列,
表示列,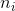 表示对应的列合计,
表示对应的列合计, 表示对应的行合计。
表示对应的行合计。
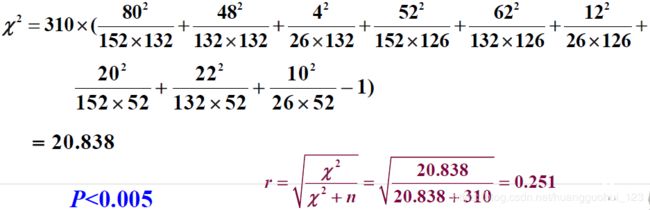
2、两变量为有序分类 (等级分类)
计算关系系数可采用Gamma系数进行计算。

【附表】