Codeforces #635题解
Codeforces round 635赛后解题报告
A. Ichihime and Triangle
首先这是一道几何题
那么我们知道,在此题中, x , y , z x,y,z x,y,z 满足 x ≤ y ≤ z , x + y > z x\leq y\leq z,x+y>z x≤y≤z,x+y>z。这是三角形三边的关系,很好理解。那么我们对这样一道构造题,又是在第一题,一定没什么难度。我们想是否能用 a , b , c , d a,b,c,d a,b,c,d 找出一组万能解。
我们再来看等腰三角形的性质,如果我们知道了两条腰的长:
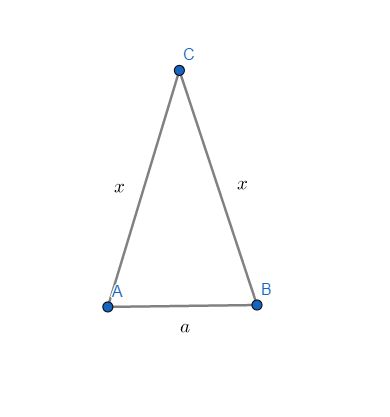
此时满足 a + x > x , x + x > a a+x>x,x+x>a a+x>x,x+x>a,所以 a < 2 x a<2x a<2x 即可。因此我们发现 a , c , c a,c,c a,c,c 是一组万能的解,满足所有条件。所以,直接输出即可,时间复杂度为 O ( 1 ) O(1) O(1)。
但为什么我在比赛里做了15min,错了三次qwq
#includeB. Kana and Dragon Quest game
那个switch好珂爱
首先,我们要考虑贪心,但有一个问题:因为一技能 ⌊ h 2 ⌋ + 10 \lfloor \frac{h}{2}\rfloor+10 ⌊2h⌋+10 有可能会使得龙的血量变大,那么什么时候采用第一种会使龙的血量增加呢?
Q:不就是不等式吗,小学三年级都会做,说的那么玄乎
A:你说的没错
我们来列个不等式看看:
⌊ h 2 ⌋ + 10 ≥ h \lfloor \frac{h}{2}\rfloor+10\geq h ⌊2h⌋+10≥h
⌈ h 2 ⌉ ≤ 10 \lceil \frac{h}{2}\rceil\leq 10 ⌈2h⌉≤10
h ≤ 20 h\leq 20 h≤20
所以我们就知道,如果 h ≤ 20 h\leq 20 h≤20,就只能用第二种技能,否则龙的血量会增加。一个贪心地思路就出现了:
1.我们先尽量使用一技能,直到 h ≤ 20 h\leq 20 h≤20 或一技能 n n n 次用完了,在等时间为 ∞ ∞ ∞ 的CD。
2.我们一直用二技能,直到 h ≤ 0 h\leq 0 h≤0 或二技能 m m m 次用完了,在等时间同样为 ∞ ∞ ∞ 的CD。
3.如果 h ≤ 0 h\leq 0 h≤0,输出 YES,否则 NO。(由于题目说 YES,NO 大小写随意,所以代码会有点不正常(滑稽))
总结这道题,是一个不等式的小应用,同时用贪心辅助即可,作为CF的div2 B还是很合适的~
还有注意:
多组数据!!!
#includeC. Linova and Kingdom
首先我们发现我们要找到深度尽可能大的节点,这样对答案的贡献较大,用堆维护,但是我们来看样例1:

如果我们找到了按顺序找到了 5 , 6 , 7 , 4 5,6,7,4 5,6,7,4 四个点,那么答案就是 6 6 6,与样例不符,没有体现样例的严密性,准确性,科学性。所以我们发现我们找到的点,尽量要分布在不同链上,这样对答案的减少最小。
我们下面来讨论如何解决这个问题:
这个题珂以用树剖做,但是我懒,还是用了贪心
树剖做法
先说树剖的做法,代码不给了。上面提到了,我们发现我们找到的点,尽量要分布在不同链上,这样对答案的减少最小。自然想到维护链的工具:树剖。我们找到一个点后,对其所在的重链或长链打上标记,下次优先找其他链上的点。代码可以自己写下。
贪心做法
我们再来看看贪心。我们发现,一个节点对于答案的贡献是它到根节点的深度减去以它为根的子树的工业城市与它的距离之和。但是由于我们贪心,所以我们肯定在选这个节点前,它的子树全被选过了(因为它的子树里每一个节点,深度都比它大,它们的贡献也比这个节点大),那么简而言之,一个节点的新贡献是这样的:
d e p u − s i z e u dep_u-size_u depu−sizeu
它的每一个子树成员都因为它的出现导致答案减去 1 1 1。所以我们在一遍 dfs 预处理完所有的基本信息后,用堆来维护即可。
这个可能太抽象,我们来模拟一下一组数据:
7 5
1 2
1 3
1 4
3 5
3 6
4 7
图和样例1一样:
我们前面的还是选择了 5 , 6 , 7 5,6,7 5,6,7。现在堆里有 3 3 3 个节点: 2 , 3 , 4 2,3,4 2,3,4 如果我们分别选择了它们,则对答案的新贡献分别是 1 , − 1 , 0 1,-1,0 1,−1,0 (因为其子树里的所有节点都会的答案值都要减 1 1 1),那么我们就选 2 2 2 号节点。然后把 1 1 1 放进去。最后不难发现我们改选择 4 4 4 作为下一个选择的节点,因为他的新贡献值最大(虽然是负的,但是不管如何,都要选满 k k k 个)。
是不是理解了呢,应该很清晰易懂了吧~~
#includeD. Xenia and Colorful Gems
这是一道有趣的题。
看到这个题,我们作为一种贪婪的生物,肯定会想到贪心,也就是找到尽量相近的 x , y , z x,y,z x,y,z。
Q:这不是废话吗。这是题意啊
A:这就是废话。
但是,这让我们知道我们直接去求这三个数,是不现实的。那么我们会想到一个算法:二分答案
通过缩小答案的范围来求出答案,是对于这种无法直接求解的题的一种好方法。但是,很可惜,我们无法想到一个 O ( n ) O(n) O(n) 的check。所以,报废。但是可以有 O ( n log n ) O(n \log n) O(nlogn) 的,大家可以来写一写。
那么真的不能直接做吗?其实可以,如果现在有一个数是确定下来的,另外两个数用贪心可以求出。我们设 x ≤ y ≤ z x\leq y\leq z x≤y≤z,那么我们枚举 y y y,用 STL 里的 lower_bound 和 upper_bound 就可以轻松找到最优的 x , z x,z x,z。但是, x , y , z x,y,z x,y,z 的关系不知这一种,有 P 3 3 = 6 P_3^3=6 P33=6 种,所以我们还需要枚举一下 x , y , z x,y,z x,y,z 的顺序。时间复杂度为 O ( 6 ⋅ n log n ) ≈ 6 × 100000 × 17 = 10200000 O(6\cdot n \log n)\approx 6\times100000\times 17 =10200000 O(6⋅nlogn)≈6×100000×17=10200000。给了 3 s 3s 3s 的时限,妥妥够了。POJ的老爷评测姬都够了(滑稽)。
Q1:为什么这样能找到最优解呢?
A1:我们想象一下这个过程,相当于我们对于每一个数,找了最优解,那么相当于一个枚举,只不过,有章法,有顺序,有道理。
Q2:为什么要枚举 y y y,然后找一个不严格小于 y y y 的数和不严格大于 y y y 的数,而不是都找不严格小于的数呢?
A2:我们再找 x , z x,z x,z 的过程,和枚举 x x x,找到 y , z y,z y,z 的过程是一样的。但是不能保证 y , z y,z y,z 之间的大小关系,所以枚举不完整,会错。
Q3:给个代码好吗?
A3:好的。
Q4:加个注释好吗?
A4:不了,原因:1.锻炼自我的代码能力,一下代码仅供参考。2.我懒
如果需要注释,可以私信我哟~~
#includeE. Kaavi and Magic Spell
首先这道题乍一看没有任何思路,本人想到的是“后缀自动机,后缀数组,后缀树”能不能做,答案是:我也不知道(因为我也不是对着三个算法和数据结构和熟悉,如果有人用这三种方法做出来了,私信我谢谢)。但是我可以告诉你,这道题可以用 DP 来解决。
定状态
我们定义 f i , j f_{i,j} fi,j 为用 s 1 s_1 s1 到 s j − i + 1 s_{j-i+1} sj−i+1 根据题目中的规则,填充 t i t_i ti 到 t j t_j tj 的方案数。
我们在定义 S , T S,T S,T 的长度为 n , m n,m n,m。
转移方程
很明显,这是一个区间DP的定义方式,所以转移方程很好想,应该是这样的:
f i , j = max { f i + 1 , j + f i , j − 1 ( i > m ∣ t i = s j − i ) & ( j > m ∣ t j = s j − i ) f i + 1 , j i > m ∣ t i = s j − i f i , j − 1 j > m ∣ t j = s j − i 0 f_{i,j}=\max \begin{cases} f_{i+1,j}+f_{i,j-1}&(i>m|t_i=s_{j-i})\&(j>m|t_j=s_{j-i})\\f_{i+1,j}&i>m|t_i=s_{j-i}\\f_{i,j-1}&j>m|t_j=s_{j-i}\\0 \end{cases} fi,j=max⎩⎪⎪⎪⎨⎪⎪⎪⎧fi+1,j+fi,j−1fi+1,jfi,j−10(i>m∣ti=sj−i)&(j>m∣tj=sj−i)i>m∣ti=sj−ij>m∣tj=sj−i
Q1:为什么 i i i 会大于 m m m?
A1:因为我们拼出的字符串 A A A 的长度不一定小于 T T T 的长度,所以在拼完前 m m m 个字符,后面可以随便拼,故 i > m i>m i>m 时,可以随便拼字符。
边界
我们在上面说过: i , j ⩾ m i,j\geqslant m i,j⩾m 是可以的,所以 i i i 要循环到 n n n。但是注意区间DP的常见错误!先枚举长度,再枚举起点!
初始化
很明显我们要初始化 f i , i f_{i,i} fi,i。
f i , i = max { 2 i > m ∣ t i = s 1 0 f_{i,i}=\max \begin{cases}2&i>m|t_i=s_1\\0\end{cases} fi,i=max{20i>m∣ti=s1
和上面的转移方程很类似。原因不再赘述。
写代码
注意我用的是 string,一定要注意下表从 0 0 0 开始。所以可能会和上面的转移方程有一些不同之处(主要是边界)。
#includeF. Yui and Mahjong Set