tensorflow2 多项式拟合
参考博文
https://www.jianshu.com/p/37a7e9b51891
import os
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
os.environ['CUDA_VISIBLE_DEVICES'] = "0" # Specify visible gpus.
tf.debugging.set_log_device_placement(True) # Show the devices when calculating.
cont=1000
input_x = np.linspace(-3,3,cont) #创建等差数列
# input_y = 3*np.sin(input_x) + np.random.uniform(0,1,cont)
input_y =input_x * 1.0 + pow(input_x,2)*2.0+ pow(input_x,3)*1.5 + pow(input_x,4)*1.1 + 5.0 + np.random.uniform(-2,2,cont)
#绘制出原始数据
plt.scatter(input_x, input_y)
plt.show()
initializer = tf.initializers.GlorotUniform()
# W = tf.Variable(initializer(shape=(1, ), dtype=tf.float64), name="W")
# b = tf.Variable(initializer(shape=(1, ), dtype=tf.float64), name="b")
w1 = tf.Variable(0.0,dtype=tf.float64,name='w1')
w2 = tf.Variable(0.0,dtype=tf.float64,name='w2')
w3 = tf.Variable(0.0,dtype=tf.float64,name='w3')
w4 = tf.Variable(0.0,dtype=tf.float64,name='w4')
b = tf.Variable(0.0,dtype=tf.float64,name='b')
optimizer = tf.optimizers.Adam(0.01)
def train_step(x, y_batch, epoch, batch_i):
with tf.GradientTape() as tape:
y_predict = tf.multiply(w1, x) + tf.multiply(w2, tf.pow(x, 2)) + tf.multiply(w3, tf.pow(x, 3)) + tf.multiply(w4,tf.pow(x, 4)) + b
loss = tf.reduce_mean(tf.math.pow(y_predict - y_batch, 2))
# print("loss", loss)
train_variables = [w1,w2,w3,w4, b]
gradients = tape.gradient(loss, train_variables)
# print("grads", gradients)
optimizer.apply_gradients(zip(gradients, train_variables))
print(epoch, batch_i,loss.numpy())
return loss
def fit():
for epoch in range(100):
for i in range(0, cont, 10):
start = i
end = i + 10
x_batch = input_x[start:end]
y_batch = input_y[start:end]
loss=train_step(x_batch, y_batch, epoch, i)
# if(loss.numpy()< 1):
# return
fit()
print(w1)
print(w2)
print(w3)
print(w4)
print(b)
#作图,显示线性回归的结果
plt.plot(input_x, input_y, 'bo', label='real data')
# plt.plot(input_x, input_x * w1 + pow(input_x,2)*w2+ pow(input_x,3)*w3 + pow(input_x,4)*w4 + b, 'r', label='predicted data')
plt.plot(input_x, input_x * w1 + input_x**2*w2+ input_x**3*w3 + input_x**4*w4 + b, 'r', label='predicted data')
plt.legend()
plt.show()
拟合结果如下图所示:
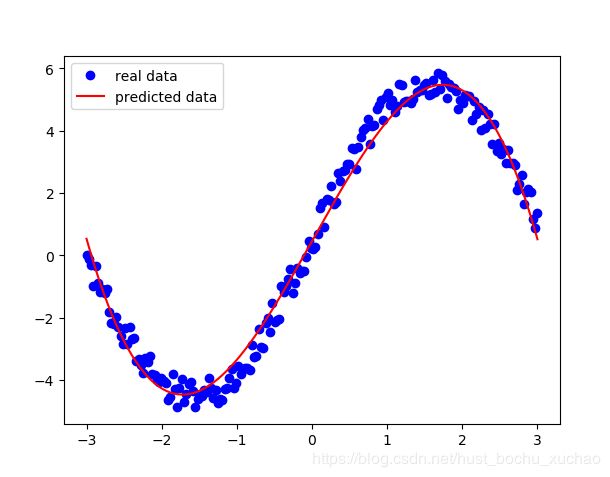
另外一种写法也可以
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
cont=200
input_x = np.linspace(-3,3,cont) #创建等差数列
input_y =5.0*np.sin(input_x) + np.random.uniform(0,1,cont)
# input_y =input_x * 1.0 + pow(input_x,2)*2.0+ pow(input_x,3)*1.5 + pow(input_x,4)*1.1 + 5.0 + np.random.uniform(-2,2,cont)
w1 = tf.Variable(0.0,dtype=tf.float64,name='w1')
w2 = tf.Variable(0.0,dtype=tf.float64,name='w2')
w3 = tf.Variable(0.0,dtype=tf.float64,name='w3')
w4 = tf.Variable(0.0,dtype=tf.float64,name='w4')
b = tf.Variable(0.0,dtype=tf.float64,name='b')
#绘制出原始数据
plt.scatter(input_x, input_y)
plt.show()
def model(x):
y = tf.multiply(w1, x) + tf.multiply(w2, tf.pow(x, 2)) + tf.multiply(w3, tf.pow(x, 3)) + tf.multiply(w4, tf.pow(x, 4)) + b
return y
opt = tf.optimizers.Adam(0.01)
# opt = tf.optimizers.Adadelta(0.01)
batchSize=20
for epoch in range(200):
for i in range(0, cont, batchSize):
start = i
end = i + batchSize
x_batch = input_x[start:end]
y_batch = input_y[start:end]
loss = lambda: tf.losses.MeanSquaredError()(model(x_batch), y_batch)
opt.minimize(loss, [w1, w2, w3, w4, b])
print(epoch,i, loss().numpy())
print(w1)
print(w2)
print(w3)
print(w4)
print(b)
#作图,显示线性回归的结果
plt.plot(input_x, input_y, 'bo', label='real data')
plt.plot(input_x, input_x * w1 + input_x**2*w2+ input_x**3*w3 + input_x**4*w4 + b, 'r', label='predicted data')
plt.legend()
plt.show()