KMP算法详解
KMP算法是求解主串(以下简称为s)和模式串(以下简称为p)匹配问题的O(n)算法。
其核心思想就是,当s[i]和p[j]发生不匹配现象时,i指针不需要回溯,只需j指针回溯。
例如:
当s[i]和p[j]发生失配,一种暴力的方法就是i回溯到上一次起始位置的下一个位置,j移动到0,然后重新进行比较。
但是实际上,从我们人的角度来看,solution1一定是进行了一次无用的匹配,因为这次匹配一定是无法匹配上的。
而按照solution2的方式,i不回溯,j回溯,那么这次再次进行s[i]和p[j]的匹配,可以省下很多操作的时间。为什么可以这样移?因为前面有且只有一个A是相同的呀,所以j应该移动到B的位置。
那么问题来了,如果发生失配时,j进行回溯,j应该回溯到什么位置呢?
如果说,j不是回溯到0,而是回溯到模式串中间的某一个位置,那么,为了不漏掉任何一种可能的情况,j需要回溯的位置k应具有以下特性:
- 找到最大的k,使得
- P[0 ~ k-1] == P[j-k ~ j-1]
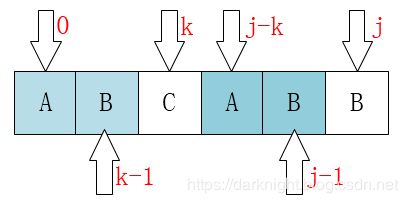
用通俗易懂的话来说,就是:j要移动的下一个位置k。存在着这样的性质:最前面的k个字符和j之前的最后k个字符是一样的,且k != j。
用官方的话来说,就是:对于串p[0 ~ j-1],它最长相同的真前缀和真后缀的长度即为k。
在上图中,如果j这个位置发生了失配,则应该移动到k的位置,因为虽然在j这个位置发生了失配,但是 j-k ~ j-1的位置肯定是和主串的 i-k ~ i-1匹配上的,那么j的下一个位置也应该保证新的j前面的字符能和主串匹配上。即:
- s[ i-k ~ i-1 ] == p[ j-k ~ j-1] == p[ 0 ~ k-1 ]
当你明白以上这些的时候,你就可以往下走了。
明白了k所需要的性质,那么怎么求每个j对应的k呢?
以下是一些串的术语,摘自《编译原理》第二版
串s的前缀(prefix)是从s的尾部删除0个或多个符号后得到的串。例如ban, banana和空串是banana的前缀
串s的后缀(suffix)是从s的开始处删除0个或多个符号后得到的串。例如nana, banana和空串是banana的后缀
串s的子串(substring)是删除s的某个前缀和某个后缀之后得到的串。例如anana,nan和空串是banan的子串
串s的真前缀、真后缀、真子串分别是s的既不等于空串,也不等于s本身的前缀、后缀和子串
串s的子序列(subsequence)是从s中删除0个或多个符号后得到的串,这些被删除的符号可能不相邻。例如,baan是banana的一个子序列。
求每个j对应的k,即求next[j],则是寻找一个p串最长相等的真前缀和真后缀的过程。例如串"abcab",它的最长相等的真前缀和真后缀即为"ab"。但是要找到它,可不是一件容易的事。因为我们不可能一个个去尝试它的所有真前缀和所有真后缀是否相同,如果去尝试所有的情况,我们求next数组的时间复杂度则为O(n^3),因为j有n个位置,每个位置对应的真前缀和真后缀串平均有O(n)个,比较每对真前缀和真后缀串需要对比O(n)次。
最高效的方式是使用递推。首先我们来回顾一下next数组。next[j]的值(也就是k)表示,当s[i] != t[j]时,j指针的下一步移动位置。根据定义,next[0] = -1,因为此时j已经在p串的最左边了,不可能再移动了,这时候要应该是i指针后移。而next[1] = 0,因为当j在位置1发生失配时,j应该移动到位置0进行下一次匹配。
在普通情况下(next[j]就是k):如果p[j] == p[next[j]],那么next[j+1] = next[j]+1。原因很简单,此时因为p[0 ~ next[j]-1]已经和p[j-k ~ j-1]相等了,如果p[j]也等于p[next[j]]的话,那么对于j+1这个位置来说,它的next值不就是next[j]+1嘛?
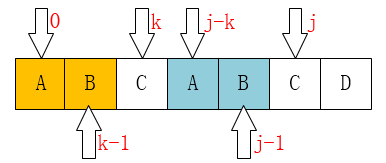
如上图,next[j] = k = 2,并且p[j] = p[next[j]] = ‘C’,那么对于j+1,也就是D这个位置来说,它的最长相等真前缀和真后缀的长度,就是C这个位置最长相等真前缀和真后缀的长度+1。
那如果p[j] != p[next[j]]又该怎么办呢?
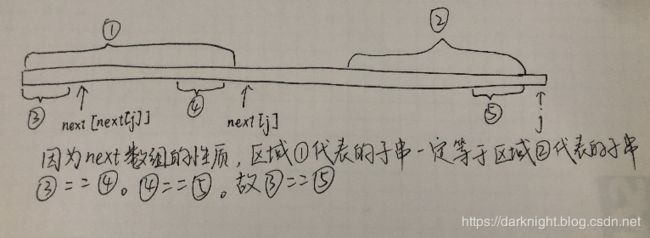
这时我们要做的事情就是再去找到next[j]的next值,即next[next[j]],比较p[j] == p[next[next[j]]]是否成立。上图为此条件成立时的情况,在图中我们可以看到,区域1 = 区域2,所以区域4 = 区域5,并且区域3 = 区域4。所以区域3等于区域5。所以如果在j+1这个位置p串和s串匹配不上的话,下一次j需要移动到的位置则是next[next[j]]+1, 即则next[j+1] = next[next[j]]+1。
如果p[j] == p[next[next[j]]]还不成立,那么再套一层next继续查询,一直等到套完一层next后的值为我们之前定义的-1,说明j已经到头了,该移动i了。
代码如下,当i为x的时候,实际上求的是x+1位置的next值:
void getnext()
{
int i = 0, j = -1;
next[0] = -1;
int len = strlen(p);
while (i < len)
{
if (j == -1 || p[i] == p[j])
{
next[++i] = ++j;
}
else
{
j = next[j];
}
}
}
求完next数组,再结合上面的过程,很容易写出完整的代码。
时间复杂度:O(len( s )+len( p ))
版本1:使用KMP算法找到第一个主串和模式串匹配的下标:
char s[N], p[N];/*主串和模式串*/
int next[N];
void getnext()
{
int i = 0, j = -1;
next[0] = -1;
int len = strlen(p);
while (i < len)
{
if (j == -1 || p[i] == p[j])
{
next[++i] = ++j;
}
else
{
j = next[j];
}
}
}
int strstr()
{
int len1 = strlen(s), len2 = strlen(p);
int i = 0, j = 0;
while (i < len1)
{
if (j == -1 || s[i] == p[j])
{
i++, j++;
if (j == len2)
{
return i - len2;
}
}
else
{
j = next[j];
}
}
return ret;
}
int main(void)
{
scanf("%s%s", s, p);
getnext();
int res = strstr();
}
版本2:使用KMP算法查询p在s中出现了多少次:
char s[N], p[N];/*主串和模式串*/
int next[N];
void getnext()
{
int i = 0, j = -1;
next[0] = -1;
int len = strlen(p);
while (i < len)
{
if (j == -1 || p[i] == p[j])
{
next[++i] = ++j;
}
else
{
j = next[j];
}
}
}
int cal()
{
int ret = 0;
int len1 = strlen(s), len2 = strlen(p);
int i = 0, j = 0;
while (i < len1)
{
if (j == -1 || s[i] == p[j])
{
i++, j++;
if (j == len2)
{
ret++;
j = next[j];
}
}
else
{
j = next[j];
}
}
return ret;
}
int main(void)
{
scanf("%s%s", s, p);
getnext();
int res = cal();
}
扩展KMP算法
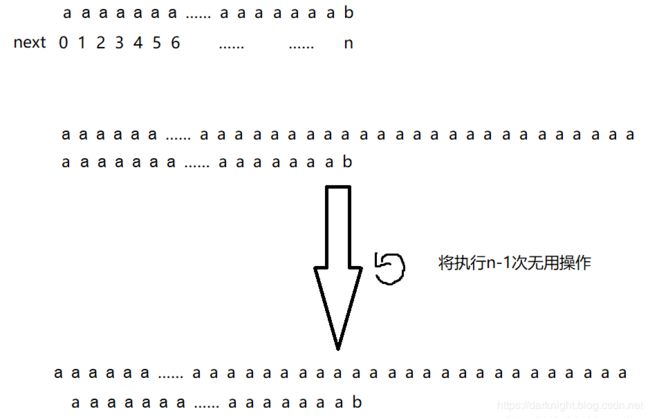
如上图所示,在这种情况下,由于next数组的特殊性,j一共会回溯n-1次,实际上,在我们人看来,这是很显然不可能匹配成功的,应该让j一下子直接回溯到0才对,那么,应该如何优化呢?
造成上述情况的根本原因在于:明明s[i] != p[j]了,但是p[j] == p[next[j]],导致下一轮match时,也就是将next[j]赋给j后,依然是一次无效匹配。
发现了问题的关键,那么优化就是:如果p[j] == p[next[j]],那么让next[j] = next[next[j]],如果还相等,再继续套一层next。当然,这是用递归的角度去看。实际上,在写代码的时候,我们是使用递推求next数组的,在递推中,只要加上一行代码即可:
if (p[i] == p[next[i]]) next[i] = next[next[i]];
因为i是从0到p.size(),所以递推到i的时候,i之前的那些位置的next值都已经是最优化的了,所以这里只要套一层next就行了,而不用担心p[next[i]] == p[next[next[i]]],这是不可能发生的。
完整求扩展KMP算法next数组的方法:
void getnext()
{
int i = 0, j = -1;
next[0] = -1;
int len = strlen(p);
while (i < len)
{
if (j == -1 || p[i] == p[j])
{
next[++i] = ++j;
if (p[i] == p[next[i]]) next[i] = next[next[i]];
}
else
j = next[j];
}
}
扩展之后的KMP算法,时间复杂度依然是O(len( s )+O(len( p )),它唯一的优点仅仅在于上述所讲述的最坏情况下,常数缩小了约两倍。
推荐 && 参考
https://www.cnblogs.com/yjiyjige/p/3263858.html
https://www.icourse163.org/course/XIYOU-1002578005