初次使用datax,发现datax不支持mysql8.x
一:下载安装
wget http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
tar -zxvf datax.tar.gz -C /usr/local/
二:
官方文档https://github.com/alibaba/DataX/blob/master/dataxPluginDev.md
三:简单案例
(1)stream—>stream
[root@hadoop01 home]# cd /usr/local/datax/
[root@hadoop01 datax]# vi ./job/first.json
内容如下:
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"sliceRecordCount": 10,
"column": [
{
"type": "long",
"value": "10"
},
{
"type": "string",
"value": "hello,你好,世界-DataX"
}
]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "UTF-8",
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": 5
}
}
}
}
运行job:
[root@hadoop01 datax]# python ./bin/datax.py ./job/first.json
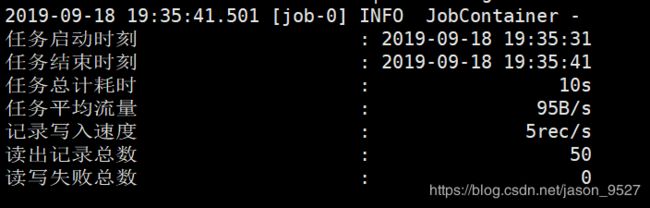
(2)mysql—>hdfs
[root@hadoop01 datax]# vi ./job/mysql2hdfs.json
内容如下:
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"id",
"name"
],
"connection": [
{
"jdbcUrl": ["jdbc:mysql://hadoop01:3306/test"],
"table": ["stu"]
}
],
"username": "root",
"password": "root"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://hadoop01:9000",
"fileType": "orc",
"path": "/datax/mysql2hdfs/orcfull",
"fileName": "m2h01",
"column": [
{
"name": "col1",
"type": "INT"
},
{
"name": "col2",
"type": "STRING"
}
],
"writeMode": "append",
"fieldDelimiter": "\t",
"compress":"NONE"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
注:
运行前,需提前创建好输出目录:
[root@hadoop01 datax]# hdfs dfs -mkdir -p /datax/mysql2hdfs/orcfull
运行job:
[root@hadoop01 datax]# python ./bin/datax.py ./job/mysql2hdfs.json
报错:
ERROR RetryUtil - Exception when calling callable, 即将尝试执行第1次重试.本次重试计划等待[1000]ms,实际等待[1000]ms, 异常Msg:[DataX无法连接对应的数据库,可能原因是:1) 配置的ip/port/database/jdbc错误,无法连接。2) 配置的username/password错误,鉴权失败。请和DBA确认该数据库的连接信息是否正确。]
datax里面的mysql驱动更换成合适的8.x的版本就好了

因为我的hdfs是ha的,所有尝试配置了
“hadoopConfig”:{
“dfs.nameservices”: “hdfs://testDfs”,
“dfs.ha.namenodes.testDfs”:“namenode1,namenode2”,
“dfs.namenode.rpc-address.aliDfs.namenode1”: “hadoop01:9000”,
“dfs.namenode.rpc-address.aliDfs.namenode2”: “hadoop02:9000”,
“dfs.client.failover.proxy.provider.testDfs”: “org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider”
}
但是会报java.io.IOException: Couldn’t create proxy provider class org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
解决方法:用winrar把hdfs-site.xml,core-site.xml,hive-site.xml三个文件压缩到datax/plugin/reader/hdfsreader/hdfsreader-0.0.1-SNAPSHOT.jar里面
但我还没尝试