CCNP路由实验之十三 Qos
CCNP路由实验之十三 Qos
QoS(Quality of Service,服务质量)指一个网络能够利用各种基础技术,为指定的网络通信提供更好的服务能力,是网络的一种安全机制, 是用来解决网络延迟和阻塞等问题的一种技术。同时它是一把双刃剑,因为网络资源总是有限的,只要存在抢夺网络资源的情况,就会出现服务质量的要求,务质量在保证某类业务服务质量的同时,可能就是在损害其它业务的服务质量。在正常情况下,如果网络只用于特定的无时间限制的应用系统,并不需要QoS,比如Web应用,或E-mail设置等。但是对关键应用和多媒体应用(语音或视频)就十分必要。当网络发生拥塞的时候,所有的数据流都有可能被丢弃;为满足用户对不同应用不同服务质量的要求,就需要网络能根据用户的要求分配和调度资源,对不同的数据流提供不同的服务质量:对实时性强且重要的数据报文优先处理;对于实时性不强的普通数据报文,提供较低的处理优先级,网络拥塞时甚至丢弃。QoS功能能够提供传输品质服务;针对某种类别的数据流,可以为它赋予某个级别的传输优先级,来标识它的相对重要性,并使用设备所提供的各种优先级转发策略、拥塞避免等机制为这些数据流提供特殊的传输服务。配置了QoS的网络环境,增加了网络性能的可预知性,并能够有效地分配网络带宽,更加合理地利用网络资源。
数据通过网络链路和交换机移动有两种基本方法:电路交换(circuit switching)和分组交换(packet switching)。区别其实就是电路交换不考虑需求而预先分配传输资源,使得有时候部分资源并不使用但还是被分配着,出现资源浪费;而分组交换就是按需分配,谁需要资源大,就多给谁资源。
电路交换网络有两种情况,要么频分多路复用(Frequency-DivisionMultiplexing, FDM)比如调频无线电台,要么时分多路复用(Time-Division Multiplexing, TDM)比如电话通信。频分多路复用在物理信道的可用带宽超过单个原始信号(如CH1、CH2)所需带宽情况下,可将该物理信道的总带宽分割成若干个与传输单个信号带宽相同(或略宽)的子信道;然后在每个子信道上传输一路信号,以实现在同一信道中同时传输多路信号。多路原始信号在频分复用前,先要通过频谱搬移技术将各路信号的频谱搬移到物理信道频谱的不同段上,使各信号的带宽不相互重叠(搬移后的信号如图中的中间3路信号波形);然后用不同的频率调制每一个信号,每个信号都在以它的载波频率为中心,一定带宽的通道上进行传输。为了防止互相干扰,需要使用抗干扰保护措施带来隔离每一个通道。时分多路复用(TDM)是按传输信号的时间进行分割的,它使不同的信号在不同的时间内传送,将整个传输时间分为许多时间间隔(Slot time,TS,又称为时隙),每个时间片被一路信号占用。TDM就是通过在时间上交叉发送每一路信号的一部分来实现一条电路传送多路信号的,电路上的每一短暂时刻只有一路信号存在。假设A要向B发信息,网络必须专门留一条线路给A和B,确保在连接时候能获得链路带宽的1/n,这个带宽是固定的不可能多也不会少。你用不了这么大带宽,别人也抢不走,你觉得带宽不够,也抢不了别人的
分组交换也称包交换,它是将用户传送的数据划分成多个更小的等长部分,每个部分叫做一个数据段。在每个数据段的前面加上一些必要的控制信息组成的首部,就构成了一个分组。首部用以指明该分组发往何地址,然后由交换机根据每个分组的地址标志,将他们转发至目的地,这一过程称为分组交换。进行分组交换的通信网称为分组交换网。分组交换网络采用了统计复用技术,即多个会话连接可以共享一条通信信道。分组交换实质上是在“存储—转发”基础上发展起来的。它兼有电路交换和报文交换的优点。在分组交换方式中,由于能够以分组方式进行数据的暂存交换,经交换机处理后,很容易地实现不同速率、不同规程的终端间通信。分组交换网络上交换的各种信息就是报文(message),比如一张图片,一个大文件什么的。报文一般都比较大,要划分为许多小分组,才能在网上发送。多数分组交换机在链路的输入端使用存储转发传输(store-and-forward transmission)机制。就是在这个分组交换机转发该分组的第一个bit前,必须接受到整个分组。注意这里等的是一个分组中的所有bit,不是说把一个报文中的分组都等到了,然后再慢慢把报文中的分组一个个发出去。所以这里就会引入存储转发延时。每个分组交换机都有多条链路与之相连。对于每条相连的链路,分组交换机内都要有个输出缓存(output buffer),也叫输出队列(output queue),与之对应,用于存储准备发往该链路的分组。除了存储转发延时外,分组还要承受输出缓存的排队延时(queue delay),即一个分组来到一个链路上了,然而这个链路暂时还未空闲,还在发送上一个分组,我这个分组就得先等着。如果输出缓存满了,又有个分组到达了,没地方存,就出现分组丢失或丢包(packet lost)。不一定是这个后来的分组被丢失,也有可能是前面正在等待的分组出现丢失。分组交换的缺点:端到端延时是变动的和不可预测的,因为排队延时的变动和不可预测所致,故不适合实时服务(如电话和视频会议)。
从上面两种数据传输技术上看其实我们现在的IP网络就是分组交换网络。既然是分组交换网络,那么就会有分组交换所带来的约束,即报文在每个节点都经受几种不同类型延时,
节点处理延时( processing delay): 指路由器收到报文后并查看信息,找到其目的地,然后把它调度到相应的链路上。这个过程的延时。通常在微妙或更低的数量级。
排队延时(queuing delay): 每个分组交换机都有多条链路与之相连。对于每条相连的链路,分组交换机内都要有个输出缓存(output buffer),也叫输出队列(output queue),用于存储准备发往该链路的分组。当一个分组来到一个链路上了,然而这个链路暂时还未空闲,还在发送上一个分组,我这个分组就得在output buffer中等待。如果输出缓存满了,又有个分组到达了,没地方存,就出现分组丢失或丢包(packet lost)。注意不一定是这个后来的分组被丢失,也有可能是前面正在等待的分组出现丢失。这个队列跟带宽有一定关系
串行延时(serialization delay):也叫传输延时(Transmission Delay),是将封装在数据帧中的数据包按比特(bit)放到物理介质上所需的时间,即一个报文如果有L个bit,那么路由不可能一下子把这L个bit一次性全放到下一段网络链路上,要有个传输时间,如果一秒钟R个bit,那么传输延时就是L / R秒。一般我们看到的说10Mbps以太,100Mbps以太网,就是说的它传输速度是一秒钟10Mb 或者100 Mb。一般在毫秒到微妙级别。
传播延时(propagation delay): 指信号在线缆中的传输速度。当一个bit被推向一个链路,该bit就开始按照路由方向出发,传播。从链路的起点到目的地所消耗的时间就是PropagationDelay,传播延时。传播速度主要取决于物理媒体(是双绞线 还是光纤)。速度非常快,延时一般在毫秒量级。光纤速度是网线的10倍
按照以上的述说,不难看出对于网络业务来说,服务质量无非就是传输的带宽、传送的时延、数据的丢包率等,而提高服务质量无非也就是保证传输的带宽,降低传送的时延,降低数据的丢包率以及时延抖动等。在上面的延时因素中,排队延时就是我们利用Qos调控的环节。根据网络对应用的控制能力的不同,可以把网络的QoS能力分为三种模型:
BestEffort(尽力而为)模型是最简单的服务模型,应用程序可以在任何时候,发出任意数量的报文,网络尽最大的可能性来发送报文,对带宽、时延、抖动和可靠性等不提供任何保证。Best Effort是Internet的缺省服务模型,通过FIFO(First In First Out,先进先出)队列来实现。尽力而为的服务实质上并不属于QoS的范畴,因为在转发尽力而为的通信时,并没有提供任何服务或转发保证。
IntServ(Integrated Service,综合服务)模型由RFC1633定义,在这种模型中,节点在发送报文前,需要向网络申请资源预留,确保网络能够满足数据流的特定服务要求。IntServ可以提供保证服务和负载控制服务两种服务,保证服务提供保证的延迟和带宽来满足应用程序的要求;负载控制服务保证即使在网络过载的情况下,也能对报文提供与网络未过载时类似的服务。在IntServ模型中,网络资源的申请是通过信令来完成的,应用程序首先通知网络它自己的流量参数和需要的特定服务质量请求,包括带宽、时延等,应用程序一般在收到网络的确认信息,即确认网络已经为这个应用程序的报文预留了资源后,才开始发送报文。同时应用程序发出的报文应该控制在流量参数描述的范围以内。负责完成保证服务的信令为RSVP(Resource Reservation Protocol,资源预留协议),它通知网络设备应用程序的QoS需求。RSVP是在应用程序开始发送报文之前来为该应用申请网络资源的,所以是带外信令。保证服务要求为单个流预先保留所有连接路径上的网络资源,而当前在Internet主干网络上有着成千上万条应用流,保证服务如果要为每一条流提供QoS服务就变得不可想象了。因此,IntServ模型很难独立应用于大规模的网络,目前主要与MPLS TE(Traffic Engineering,流量工程)结合使用。
DiffServ(Differentiated Service,区分服务)模型由RFC2475定义,在区分服务中,根据服务要求对不同业务的数据进行分类,对报文按类进行优先级标记,然后有差别地提供服务。区分服务一般用来为一些重要的应用提供端到端的QoS,它通过下列技术来实现:
流量标记与控制技术:它根据报文的CoS(Class of Service,服务等级)域、ToS域(对于IP报文是指IP优先级或者DSCP)、IP报文的五元组(协议、源地址、目的地址、源端口号、目的端口号)等信息进行报文分类,完成报文的标记和流量监管。目前实现流量监管技术多采用令牌桶机制。
拥塞管理与拥塞避免技术:在计算机数据通信中,通信信道是被多个计算机共享的,对于网络单元,当分组到达的速度大于该接口传送分组的速度时,在该接口处就会产生拥塞。如果没有足够的存储空间来保存这些分组,它们其中的一部分就会丢失。分组的丢失又可能会导致发送该分组的主机或路由器因超时而重传此分组,这将导致恶性循环。 造成拥塞的因素有很多。比如,当分组流从高速链路进入路由器,由低速链路传送出去时,就可能产生拥塞。分组流同时从多个接口进入路由器、由一个接口转发出去或处理器速度慢也可能会产生拥塞拥塞管理是指网络在发生拥塞时,如何进行管理和控制。处理的方法是使用队列技术。将所有要从一个接口发出的报文进入多个队列,按照各个队列的优先级进行处理。不同的队列算法用来解决不同的问题,并产生不同的效果,cisco常用的队列技术有FIFO、PQ、CQ、WFQ、CBWFQ、LLQ等队列技术对拥塞的报文进行缓存和调度实现拥塞管理;同时使用拥塞避免机制避免尾部丢弃,CISCO路由器接口上使用的常见拥塞避免技术RED及其变体WRED和CBWRED,但是尾部丢弃的限制和缺陷会导致TCP全局同步、TCP资源缺乏等;
TCP全局同步 : 传统的丢包策略采用尾部丢弃(Tail-Drop)的方法。当队列的长度达到某一最大值后,所有新到来的报文都将被丢弃。当出现尾部丢弃时,基于TCP的流量流通过减小TCP发送窗口尺寸而同时降低发送速度,使带宽使用率大幅降低,接口队列的拥塞得到缓解,进而TCP流又增大发送窗口尺寸,又重复导致拥塞,这个情况就是TCP全局同步
TCP资源缺乏:当发送TCP全局同步的时候,TCP流量流减少,其它类型流量不变,而且占满队列,留个TCP流量的队列资源非常少,导致TCP资源缺乏QOS技术简介:
在实施拥塞管理的机制中,会使用到各种各样的队列机制,分别为硬件队列和软件队列两种。只有当硬件队列满了,设备发生拥塞了,才会使用到软件队列,此时实施队列机制才有意义;如果硬件队列一直没有出现拥塞,就没有存在软件队列的排队。引入硬件队列的更能充分的使用带宽,在调度中可以直接将硬件队列的数据包放入出接口。解决如果只有软件队列存在的情况下出现的中断和软件队列附加的要调度到出接口的决策
| 硬件队列特点 |
| 硬件队列只有一种队列机制,为FIFO |
| 硬件队列的机制没法修改 |
| 硬件队列的长度可以进行修改,以防硬件队列过长而影响整体QOS实施的效率 |
| 如果接口实施了一些qos机制,比如说WFQ CBWFQ等,硬件队列长度会自动降低 |
FlFO(先进现出队列):不对报文进行分类,当报文进入接口的速度大于接口能发送的速度时,FIFO按报文到达接口的先后顺序让报文进入队列,同时,FIFO在队列的出口让报文按进队的顺序出队,先进的报文将先出队,后进的报文将后出队。Internet的默认服务模式是Best-Effort,采用FIFO队列策略。
如果软件队列满了,那就简单的进行尾丢弃。此外,硬件队列也使用的FIFO队列,并且只能用这种队列。在带宽大于E1(2.048M)的接口上FIFO是默认启用的。在小于E1的接口上默认队列机制是WFQ。若要在小于E1的接口上也启用FIFO,可在接口上输入no fair-queue命令,hold-queue用来设置FIF的队列缓存。
| FIFO优点 |
FIFO缺点 |
| 简单,而且处理速度最快。因为就使用了一个软件队列,不用分类,而且调度机制也很简单 |
在多个流之间分配的带宽不公平 |
| 所有平台上都支持这种队列 |
野蛮流量可能占满带宽,从而导致其他流量被没有带宽可用,被“饿死”。 |
| 支持所有的IOS版本 |
导致抖动(突发流量可能会临时性的填满队列) |
| 支持所有的交换路径(进程交换,快速交换,CEF等) |
对所有数据流进行尾丢弃,则可能造成TCP全局同步,以及TCP慢启动,降低链路使用效率,而且可能会造成TCP饥饿 |
PQ (PriorityQueueing)优先队列:PQ使用了4个子队列,优先级分别是high,medium,normal,low。默认的流量都是normal,PQ会先服务高优先级的子队列,若高优先级子队列里没有数据后,再服务中等优先级子队列,依次类推。如果PQ正在服务中等优先级子队列,但是高优先级里又来了数据包,则PQ会中断中等优先级子队列的服务,转而服务高优先级子队列。每一个子队列都有一个最大队列深度(queue-size),如果达到了最大队列深度,则进行尾丢弃。
| PQ优点: |
PQ缺点 |
| 对高优先级的数据流提供了低延迟的转发 |
对单一子队列而言,会继承FIFO队列的所有缺点 |
| 大多数平台上都支持该队列机制 |
对低优先级的数据流而言,可能会被“饿死”,因为只有高优先级队列里有数据,PQ就不会服务低优先级队列 |
| 支持所有的IOS版本 |
需要在每一跳上都手工的配置分类 |
CQ(CustomizedQueue,用户定制队列)CQ最多可包含16个组(即group-number的取值范围为1~16),在每个组中指明了什么样的数据包进入什么样的队列、各队列的长度和每次轮询各队列所能连续发送的字节数等信息。CQ对报文进行分类,将所有报文分成最多至17类,分别属于CQ的17个队列中的一个,然后,按报文的类别将报文进入相应的队列。CQ的17个队列中,0号队列是最高优先队列,路由器总是先把0号队列中的报文发送完,然后才处理1到16队列中的报文,所以0号队列一般作为系统队列把实时性要求高的交互式协议报文放到0号队列。1到16号队列可以按用户的定义分配它们能占用接口带宽的比例,在报文出队的时候,CQ按定义的带宽比例分别从1到16号队列中取一定量的报文在接口上发送出去。其中,按带宽比例分别发送的实现过程是这样的,16个普通队列采用轮询的方式进行调度,当调度到某一个队列时,从这个队列取出一定字节数的报文发送,用户通过指定这个字节数,就可以控制不同队列之间的带宽分配比例,如果不配置字节数,即平均分配带宽。用户在指定每个队列每次调度时发送的字节数时,需要把握所配数值的大小,因为这关系到轮询中配置增加的粒度。
PQ赋予较高优先级的报文绝对的优先权,这样虽然可以保证关键业务的优先,但在较高优先级的报文的速度总是大于接口的速度时,将会使较低优先级的报文始终得不到发送的机会。采用CQ,将可以避免这种情况的发生。CQ可以把报文分类,然后按类别将报文被分配到CQ的一个队列中去,对每个队列,可以规定队列中的报文应占接口带宽的比例,这样,就可以让不同业务的报文获得合理的带宽,从而既保证关键业务能获得较多的带宽,又不至于使非关键业务得不到带宽。当然CQ中的实时业务不能获得象PQ一样好的时延指标
WFQ(Weighted Fair Queueing,加权公平队列)WFQ是一个复杂的排队过程,可以保证相同优先级业务间公平,不同优先级业务间加权。队列的数目可预先配置,范围是(16-4096)。 WFQ,在保证公平(带宽、延迟)的基础上体现权值,权值大小依赖于IP报文头中携带的IP优先级(Precedence)。WFQ对报文按流进行分类(相同源IP地址,目的IP地址,源端口号,日的端口号,协议号,Precedence的报文属于同一个流),每一个流被分配到一个队列,该过程称为散列。WFQ入队过程采用HASH算法来自动完成,尽量将不同的流分入不同的队列。在出队的时候,WFQ按流的优先级(precedence)来分配每个流应占有出口的带宽。优先级的数值越小,所得的带宽越少。优先级的数值越大,所得的带宽越多。这样就保证了相同优先级业务之间的公平,体现了不同优先级业务之间的权值。如:接口中当前有8个流,它们的优先级分别为O,2,2,3,4,5,6,7。则带宽的总配额将是:所有(流的优先级+1)的和。即:1+3+3+4+5+6+7+8=37;每个流所占带宽比例为:(自己的优先级数+1)/带宽总配额。即每个流可得的带宽分别为:1/37,3/37,3/37,4/37,5/37,5/37,6/37,7/37,8/37。由此可见,WFQ在保证公平的基础上对不同优先级的业务体现权值,而权值依赖于IP报文头中所携带的IP优先级。
| WFQ优点: |
WFQ缺点 |
| 配置简单(不用手工分类) |
对单一子队列而言,会继承FIFO队列的所有缺点 |
| 保证所有的流都有一定的带宽 |
多个不同的流可能会被分入同一个队列(流的数量超过了配置的队列数) |
| 支持所有的IOS版本 |
不支持手工分类 |
| 丢弃野蛮流量,从最主动的流中丢弃数据包,可以为非主动流提供更快的服务 |
不能提供固定带宽保证 |
|
|
因为使用了复杂的分类和调度机制,会使用系统一部分资源 |
|
|
仅支持低速链路(2.048Mbit/s及以下的) |
目标:
为每个活动流提供公平的带宽分配机制
为少量交互流提供更快的调度机制
为高优先级流提供更多的带宽
CBWFQ(class-based weighted fairqueuing,基于类的加权公平队列) CBWFQ通常使用ACL定义数据流类别,并将注入宽带和队列限制等参数应用于这些类别。CBWFQ是网络中的一个队列配置方案,其允许通信基于标准分类,可以通过acl,入接口,优先级,DSCP值等等去分类,并且可以使用bandwidth参数实现在发生拥塞的情况下允许给每类分配拥塞时的最小保证带宽,明确了带宽保证。注意,CBWFQ的默认调度方法是FIFO,可以配置为FQ和早期丢弃。默认丢弃机制为尾丢弃。CBWFQ扩展了加权公平队列WFQ功能的标准来提供自定义通信类型支持。默认接口的可用的带宽为总参考带宽的75%(这个数值和IOS版本也有关系,有的可高达99%),如果CBWFQ策略超出了75%的带宽,可以采用max-reserved-bandwidth 100去修改最大保留可用的带宽;如果想用到100%,必须打上这一命令。CBWFQ特点:
能够给不同的类保障一定的带宽
当没有发生拥塞时此类可以超出最小带宽保证(原因是没有拥塞就不会有软件队列,没有软件队列CBWFQ没有效果)。意义在于在任何情况下都有最小带宽的保证
对传统的WFQ作了扩展支持用户自己定义流量的分类:
队列的个数和类别是一一对应,给每个class 保留带宽
当发生拥塞时出口带宽有多余的情况下各个类的class会按着最小带宽保证的比例来占用多余带宽。
LLQ(Low Latency Queueing,低延迟队列) LLQ(LowLatency Queuing)在WFQ的基础上增加了一个优先队列即CBWFQ+PQ,LLQ为基于类别的加权公平排队(CBWFQ)提供绝对优先排队功能,减少了语音会话的抖动。LLQ相当于CBWFQ加上一个严格优先级队列,该队列优先级高于其他所有队列,非常适合时延敏感性应用。LLQ的严格优先级队列是一个有最小保证带宽的优先级队列,出现拥塞时,该队列的数据量不能超过所允许的带宽,否则会被丢弃。LLQ具有CBWFQ的所有优点,包括自定义流量类别,为每种类别的流量提供带宽保证,并且可以在所有类别的队列上应用WRED。(严格优先级队列除外) 对于LLQ和CBWFQ来说,任何没有被显示分类的流量都被认为class-default流量,可以将class-default流量类别队列由FIFO改为WFQ,需要时也可以用WRED。 LLQ最大优势是可以为时延和抖动敏感型应用的流量提供一个或多个有带宽保证的严格优先级队列,LLQ并不局限于特定平台或传输介质。CBWFQ虽然能够为各种类别的流量提供带宽的保证,但却不能提供低延迟的传输保证,为此LLQ解决保证对延时敏感的数据流优先传输。比如VOICE流量。低延时队列,可以优先传送低延时队列里的数据,一般为语音流量。可以保证此流量的低延时通过保证此数据流量的最小带宽。在LLQ队列里总是优先传送PQ队列的数据流,当PQ队列的数据流量传送完毕后再依次传送其他数据。 默认可以将任何数据流放入LLQ队列保证优先的传送,但是一般情况下只将语音这些对延迟特别敏感的数据流放入此队列中。
iprtp priority:RTP优先队列是针对语音数据的严格优先队列使用的,对其他数据使用的是WFQ。RTP优先队列根据端口号识别语音数据,语音数据使用的是偶数端口号。RTP优先队列已经考虑了RTP报文头压缩(包括IP,UDP,RTP),但不包括二层帧的开销,因此,在为RTP优先队列分配带宽时,只需要使用标准的语音流所占用带宽即可。二层开销占用保留的25%带宽。它只能为UDP流量服务,这个队列在接口下直接配置,实际上就是在接口下划出一部分带宽给特定UDP流量来使用,实际上主要是为VOIP流量服务·RTP(Real-TimeProtocol):实时传输协议RTP传输多媒体应用的数据流,包括IP语音和视频(对延迟比较敏感的)
与LLQ比较:
LLQ无法识别偶数端口号,只能把一个端口号区间包含进去,這样也就把控制数据放入了LLQ中。如果在低速链路上,把语音数据和控制数据都放入LLQ有可能降低语音质量。
RTP优先队列不需要考虑哪些端口号是语音数据使用的,可以把整个端口号区间写进去。这是LLQ无法比拟的。
RTP和LLQ都可以同时应用在同一个接口上,但RTP优先队列优先于LLQ。
Random EarlyDetection(RED)早期检测随即丢弃 : 拥塞避免原理受限于设备的内存资源,按照传统的处理方法,当队列的长度达到规定的最大长度时,所有到来的报文都被丢弃。不过,如果您拥有多个TCP源,那么在所有源中统一进行数据包的丢弃将会导致所有这些源的退回,并随后同时开始重新发送。这 种情况将会导致波浪式的拥塞,也被称为"全局同步"。这种情况将会导致吞吐量的急剧下降。通过有选择地从特定的TCP流中丢弃数据包,RED解决了这一问题,只有很少的TCP发送方会出现退回和重发的现象。采用加权随机早期检测WRED(Weighted RandomEarly Detection)的报文丢弃策略(WRED与RED的区别在于前者引入IP优先权,DSCP值,和MPLS EXP来区别丢弃策略)。采用WRED时,用户可以设定队列的阈值(threshold)。当队列的长度小于低阈值时,不丢弃报文;当平均队列长度超过用户规定的"最小阈值"时,WRED 开始根据一定的概率丢弃数据包(包括TCP和UDP)。如果平均队列长度超过用户规定的"最大阈值",则WRED转为"后来(数据包)丢弃",即所有后面 到达的数据包都将被丢弃。WRED的意图就是使将队列长度维持在最小和最大阈值之间的某个水平。拥塞避免机制是一种主动的拥塞管理,而队列机制是一种被动的拥塞管理,。注意WRED不可以和接口队列合用,只能支持FIFO;可以和CBWFQ结合使用,可以给IP优先级或者DSCP设置不同的阀值和丢弃策略
流量监管之CAR(CommitAccess Rate)即承诺访问速率,是QoS技术当中的一种流量管制工具,一种基于传统命令行的QoS配置机制与以前的CB-Policing使用同样的令牌桶机制;原理是在令牌桶中,CBS(每次突发所允许的最大的流量尺寸,即令牌桶的最大容量)+EBS(超额突发尺寸Excess Burst Size )=令牌桶大小,默认情况下EBS为0,CBS采用默认值,CBS和EBS单位是Byte,CIR(承诺信息速率)为每秒往令牌桶添加令牌的速度,单位是kbps,注意是bit每秒,不是Byte每秒,如配置qos car outbound carl 1 cir 64,其含义就是对carl队列1在接口出方向配置CIR为64kbps,此时默认CBS为4000(Byte),即令牌桶大小为4000字节,每秒往桶 内注入令牌的速率是64kbps,令牌桶就和水桶一样,CIR最多把桶注满,并不会多出。假设一个包,大小是1500字节,如果此时桶内令牌数量是2000字节,那么该数据包通过,令牌数量变成2000-1500=500(称BE),如果此时再来一个1000字节的数据包,那么令牌就不够,这个数据包就有可能被丢弃或remark作用是限制进入某一网络的某一连接的流量与突发。在报文满足一定的条件时,如某个连接的报文流量过大,流量监管就可以对该报文采取不同的处理动作,例如丢弃报文,或重新设置报文的优先级等。通常的用法是使用CAR来限制某类报文的流量,例如限制HTTP报文不能占用超过50%的网络带宽。CAR利用令牌桶(Token Bucket,简称TB)进行流量控制。首先,根据预先设置的匹配规则来对报文进行分类,如果是没有规定流量特性的报文,就直接继续发送,并不需要经过令牌桶的处理;如果是需要进行流量控制的报文,则会进入令牌桶中进行处理。如果令牌桶中有足够的令牌可以用来发送报文,则允许报文通过,报文可以被继续发送下去。如果令牌桶中的令牌不满足报文的发送条件,则报文被丢弃。这样,就可以对某类报文的流量进行控制。在实际应用中,CAR不仅可以用来进行流量控制,还可以进行报文的标记(mark)或重新标记(re-mark)。具体来讲就是CAR可以设置IP报文的优先级或修改IP报文的优先级,达到标记报文的目的。
CAR不支持以太channel、tunnel或者PRI接口以及任何不支持CEF的接口。CEF必须在配置CAR的接口上使能。7600系列路由器不支持CAR特性
可以基于以下内容设置CAR的管制策略:所有的IP流量、IP优先级、MAC地址、IP ACL。最多可以在一个子接口上配置100个CAR,但是会随着CAR的增加而增加CPU的负载
有专门用于CAR的ACl为IP优先级或者MAC地址分类:access-list rate-limit <0-99> PrecedenceACL index <100-199> MAC address ACL index
CAR还有标记的功能,可以标记为DSCP、IP优先级或者MPLS的EXP位。CAR可以应用在入方向或者出方向
带宽是被共享的,因此当做QOS的CAR的时候如果某用户带宽没有被限制,则可能会由于此用户流量过大而抢占你所用CAR保证的用户带宽,此时需要结合队列技术使用
流量整型 (Traffic Shaping)流量整形分为四种分别为:通用流量整形(GTS)、基于类的流量整形、分布式流量整形(DTS)和帧中继流量整形。流量整形可以对不规则或不符合预定流量特性的流量进行整形,以利于网络上下游之间的带宽匹配。整形的目的(与速率限制/政策制订相对比)是永远不会发生丢弃数据包这样的事情,与CAR一样,均采用了令牌桶技术来控制流量。流量整形与CAR的主要区别在于:CAR在接口的出、入方向进行报文的流量控制,对不符合流量特性的报文进行丢弃;而流量整形只在接口的出方向对于不符合流量特性的报文进行缓冲,减少了报文的丢弃,同时满足报文的流量特性,但增加了报文的延迟。通过将特定通信流的速率限制为某一特定位速率,这一功能可以减少输出通信流以避免拥塞的发生 (这也被称为令牌存储桶方法),同时对猝发性的特定通信流进行排队处理。因此,对符合某一特征的通信流进行整形以后可以使其能够满足下游的要求,消除了因 数据传输速率不匹配而导致的拓扑结构上的瓶颈。流量整形可以每一接口(或每一子接口)为应用对象,能够通过访问列表来选择将被整形的通信流,并能够使用多种 Layer 2技术。换句话说,GTS可以不依赖于Layer 2接口或封装而对Layer 3通信流进行整形,例如以太网、ATM、HDLC、PPP(ISDN和拨号接口不支持)和帧中继
物理接口总速率限制(Line Rate,简称LR)可以在一个物理接口上,限制接口发送报文(包括紧急报文)的总速率。LR的处理过程仍然采用令牌桶进行流量控制。如果用户在路由器的某个接口上配置了LR,规定了流量特性,则所有经由该接口发送的报文首先要经过LR的令牌桶进行处理。如果令牌桶中有足够的令牌可以用来发送报文,则报文可以发送。如果令牌桶中的令牌不满足报文的发送条件,则报文入QoS队列进行拥塞管理。这样,就可以对通过该物理接口的报文流量进行控制。
资源保留协议(RSVP)为应用程序(或一个代表应用程序的路由器)提供了一种向网络发出信令以要求所需QoS级别的方法。RSVP是一种Layer 3信令协议,允许一个应用程序以每个流为单位请求QoS服务。RSVP依赖于在两个端点之间周期性地交换PATH/REVP消息;它被认为是一种"接收方发起"性质的协议,因为作为数据流的接收方,它为该特定 流发起并维护资源保留处理过程。由于RSVP要求每个中间路由器维护每个RSVP流的状态信息,所以当被用于消息需要通过大量路由器的基础设施(如 Internet)中时,可能会产生可扩展性和成本方面的问题。当必须实现清晰的QoS功能和粒度化时,RSVP是可以派上用场的,如一个低速WAN链路。
链路分片与交叉(Link Fragment & Interleave,LFI)对于低速链路,即使为语音等实时业务报文配置了高优先级队列(如RTP优先队列或LLQ),也不能够保证其时延与抖动,原因在于接口在发送其他数据报文的瞬间,语音业务报文只能等待,而对于低速接口发送较大的数据报文要花费相当长的时间。采用LFI以后,数据报文(非RTP实时队列和LLQ中的报文)在发送前被分片、逐一发送,而此时如果有语音报文到达则被优先发送,从而保证了语音等实时业务的时延与抖动。LFI主要用于低速链路。应用LFI技术,在大报文出队的时候,可以将其分为定制长度的小片报文,这就使RTP优先队列或LLQ中的报文不必等到大片报文发完后再得到调度,它等候的时间只是其中小片报文的发送时间,这样就很大程度的降低了低速链路因为发送大片报文造成的时延。
RTP报文头压缩(RTP Header Compression,CRTP)用于RTP(Real-timeTransport Protocol)协议,对IP头、UDP头和RTP头进行压缩,通常在低速链路上使用。可将40字节的IP/UDP/RTP头压缩到2~4个字节(不使用UDP校验和可到2字节),提高链路带宽的利用率。CRTP主要得益于同一会话的语音分组头和语音分组头之间的差别往往是不变的,因此只需传递增量。RTP协议用于在IP网络上承载语音、视频等实时多媒体业务。RTP报文包括头部分和数据部分,RTP的头部分包括:12字节的RTP头,加上20字节的IP头和8字节的UDP头,就是40字节的IP/UDP/RTP头;RTP数据部分典型载荷是20字节到160字节。为了避免不必要的带宽消耗,可以使用CRTP特性对报文头进行压缩。CRTP可以将IP/UDP/RTP头从40字节压缩到2~4字节,对于40字节的载荷,头压缩到4字节,压缩比为(40+40)/(40+4),约为1.82,可见效果是相当可观的,可以有效的减少链路带宽的消耗,尤其是低速链路。
FR QoS FR(Frame Relay,帧中继)是一种统计复用的协议,它能够在单一物理传输线路上提供多条虚电路。每条虚电路用DLCI(Data Link Connection Identifier,数据链路连接标识)来标识。每条虚电路通过LMI(Local Management Interface,本地管理接口)协议检测和维护虚电路的状态。帧中继采用VC(Virtual Circuit)虚电路技术,即帧中继传送数据使用的传输链路是逻辑连接,而不是物理连接。虚电路是面向连接的,可以保证用户帧按顺序传送至目的地。根据虚电路建立方式的不同,将帧中继虚电路分为两种类型:永久虚电路(PVC,Permanent Virtual Circuit)和交换虚电路(SVC,Switched VirtualCircuit)。PVC是手工设置产生的虚电路,而SVC是通过协议协商自动创建和删除的虚电路。帧中继报头中的3个位提供了帧中继网络中的拥塞控制机制,这3个位分别叫做向前显式拥塞通知(FECN,Forward Explicit Congestion Notification)位、向后显式拥塞通知(BECN,Backward Explicit Congestion Notification)位和丢弃合格(DE,Discard Eligible)位。可以通过帧中继交换机将FECN位置1来告知诸如路由器等目标数据终端设备(DTE,Data Terminal Equipment),在帧从源传送到目的地的方向发生了拥塞。帧中继交换机将BECN位置1则告知目标路由器,在帧从源传送到目的地的反方向上发生了拥塞。DE位由路由器或其他DTE设备设置,指出被标记的帧没有传输的其他帧那么重要,它在帧中继网络中提供了一种基本的优先级机制,如果发生拥塞时,DE位置位的帧会被优先丢弃。帧中继流量整形(FRTS,Frame Relay Traffic Shaping)对从帧中继VC输出的通信进行整形,使之与配置速率一致,它将超出平均速率的分组放到缓冲区来使突发通信变得平滑。根据配置的排队机制,当有足够的可用资源时,这些缓冲的分组出队并等候被传输。排队算法是基于单个VC配置的,它只能针对接口的出站通信进行设置。FRTS可对每个VC的流量进行整形,将其峰值速率整形为承诺信息速率(CIR,Committed Information Rate)或其他定义的值,如超额信息速率(EIR,Excess Information Rate)。自适应模式的FRTS还能够根据收到的网络BECN拥塞指示符降低帧中继VC的输出量,将PVC的输出流量整形为与网络的可用带宽一致
ATM QoS ATM是异步传输模式(AsynchronousTransfer Mode)的简称,以信元为基本单位进行信息传输、复接和交换。ATM信元具有53字节的固定长度,其中5个字节构成信元头部,主要用来标识虚连接,另外也完成了一些功能有限的流量控制,拥塞控制,差错控制等功能,其余48个字节是有效载荷。ATM是面向连接的交换,其连接是逻辑连接,即虚电路。每条虚电路(Virtual Circuit,VC)用虚路径标识符(Virtual Path Identifier,VPI)和虚通道标识符(VirtualChannel Identifier,VCI)来标识。一个VPI/VCI值对只具有本地意义,不具有全局有效性。它在ATM节点上被翻译。当一个连接被释放时,与此相关的VPI/VCI值对也被释放,它被放回资源表,供其它连接使用。ATM中每一条VC都有一定的QoS保障,这是由ATM的连接管理来实现的。当用户与网络或网络与网络建立一个连接的时候,双方就确定了一份通信契约,契约中包括流量参数和QoS参数两部分。此通信契约为双方所共识,双方必须遵守。流量参数包括峰值信元速率(PCR,Peak Cell Rate)、持续信元速率(SCR,Sustained CellRate)、最小信元速率(MCR,Minimum Cell Rate)以及最大突发量(MBS,Maximum BurstSize),它们描述业务本身的流量特性,又称为源流量参数。QoS参数主要包括最大信元传递时延(MCTD,MeanCell Transfer Delay)、信元抖动容限(CDVT,CellDelayVariationTolerance)和信元丢失率(CLR,Cell Loss Ratio), MCTD是信元从一个端点到另一个端点所需要的时间, CDVT是信元间隔的上限, CLR是可以接受的因网络拥塞而导致信元丢失比例。ATM端系统负责确保传输的流量符合QoS合同。ATM端系统通过缓冲数据来对流量进行整形,并按约定的QoS参数传输通信。ATM交换机控制每个用户的通信指标,并将其与QoS合同进行比较。对于超过了QoS合同的通信,ATM节点可以设置信元的CLP(Cell Loss Priority,信元丢弃优先级)位。在网络拥塞时,CLP置位的信元被丢弃的可能性更大。ATM网络拥塞管理的基本思想在于:引入预防性控制措施,不再是出现拥塞之后再采取措施来消除拥塞,而是通过精心管理网络资源来避免拥塞的出现。
实验一、拥塞管理之认识硬件队列

R1配置:
R1#conft
R1(config)#intfastEthernet 0/0
R1(config-if)#ipadd 192.168.1.1 255.255.255.0
R1(config-if)#nosh
R1(config-if)#exit
R2配置:
R2#conft
R2(config)#intfa0/0
R2(config-if)#ipadd 192.168.1.2 255.255.255.0
R2(config-if)#tx-ring-limit256 //手动修改接口硬件队列长度。其实当接口设置了一些qos策略后,硬件队列长度会自动降低,为了就是提高QOS的效率
R2(config-if)#nosh
R2(config-if)#exit
R2(config)#
查看R1和R2的Fa0/0口的硬件队列。注意当硬件队列满了才会实行软件队列
R1#shcontrollers fastEthernet 0/0 | include tx_limited
tx_limited=0(128)
R2#shcontrollers fastEthernet 0/0 | include tx_limited
tx_limited=0(256)
实验二、拥塞管理之FIFO队列机制

R1配置:
R1#conft
R1(config)#intfa0/0
R1(config-if)#ipadd 192.168.12.1 255.255.255.0
R1(config-if)#nosh
R1(config-if)#exit
R1(config)#routerrip
R1(config-router)#version2
R1(config-router)#noauto-summary
R1(config-router)#network192.168.12.0
R1(config-router)#exit
R2配置:
R2#conft
R2(config)#intfa0/0
R2(config-if)#ipadd 192.168.12.2 255.255.255.0
R2(config-if)#hold-queue60 out //修改接口FIFO的输出队列长度
R2(config-if)#nosh
R2(config-if)#exit
R2(config)#ints1/0
R2(config-if)#clockrate 64000
R2(config-if)#ipadd 192.168.23.2 255.255.255.0
R2(config-if)#nosh
R2(config-if)#exit
R2(config)#routerrip
R2(config-router)#version2
R2(config-router)#noauto-summary
R2(config-router)#network192.168.12.0
R2(config-router)#network192.168.23.0
R2(config-router)#exit
R3配置:
R3#conft
R3(config)#ints1/0
R3(config-if)#clockrate 64000
R3(config-if)#ipadd 192.168.23.3 255.255.255.0
R3(config-if)#nofair-queue //强制启用FIFO
R3(config-if)#hold-queue100 out////修改接口FIFO的输出队列长度
R3(config-if)#nosh
R3(config-if)#exit
R3(config)#routerrip
R3(config-router)#version2
R3(config-router)#noauto-summary
R3(config-router)#net192.168.23.0
R3(config-router)#exit
查看R1、R2、R3的相关接口
R1#sh int fa0/0 //默认的队列FIFO,长度40
FastEthernet0/0is up, line protocol is up
Hardware is Gt96k FE, address isc403.27cc.0000 (bia c403.27cc.0000)
Internet address is 192.168.12.1/24
MTU 1500 bytes, BW 10000 Kbit, DLY 1000 usec,
reliability 255/255, txload 1/255, rxload1/255
Encapsulation ARPA, loopback not set
Keepalive set (10 sec)
Half-duplex, 10Mb/s, 100BaseTX/FX
ARP type: ARPA, ARP Timeout 04:00:00
Last input 00:00:01, output 00:00:07, outputhang never
Last clearing of "show interface"counters never
Input queue: 0/75/0/0(size/max/drops/flushes); Total output drops: 0
Queueing strategy: fifo
Output queue: 0/40 (size/max)
5 minute input rate 0 bits/sec, 0 packets/sec
5 minute output rate 0 bits/sec, 0packets/sec
15 packets input, 2973 bytes
Received 15 broadcasts, 0 runts, 0 giants,0 throttles
0 input errors, 0 CRC, 0 frame, 0 overrun,0 ignored
0 watchdog
0 input packets with dribble conditiondetected
50 packets output, 5625 bytes, 0 underruns
0 output errors, 0 collisions, 1 interfaceresets
0 babbles, 0 late collision, 0 deferred
0 lost carrier, 0 no carrier
0 output buffer failures, 0 output buffersswapped out
R2#sh interfacesfa0/0 //修改FIFO队列长度效果
FastEthernet0/0is up, line protocol is up
Hardware is Gt96k FE, address isc404.27cc.0000 (bia c404.27cc.0000)
Internet address is 192.168.12.2/24
MTU 1500 bytes, BW 10000 Kbit, DLY 1000 usec,
reliability 255/255, txload 1/255, rxload1/255
Encapsulation ARPA, loopback not set
Keepalive set (10 sec)
Half-duplex, 10Mb/s, 100BaseTX/FX
ARP type: ARPA, ARP Timeout 04:00:00
Last input 00:00:57, output 00:00:05, outputhang never
Last clearing of "show interface"counters never
Input queue: 0/75/0/0(size/max/drops/flushes); Total output drops: 0
Queueing strategy: fifo
Output queue: 0/60 (size/max)
5 minute input rate 0 bits/sec, 0 packets/sec
5 minute output rate 0 bits/sec, 0packets/sec
11 packets input, 3861 bytes
Received 11 broadcasts, 0 runts, 0 giants,0 throttles
0 input errors, 0 CRC, 0 frame, 0 overrun,0 ignored
0 watchdog
0 input packets with dribble conditiondetected
106 packets output, 10571 bytes, 0underruns
0 output errors, 0 collisions, 1 interfaceresets
0 babbles, 0 late collision, 0 deferred
0 lost carrier, 0 no carrier
0 output buffer failures, 0 output buffersswapped out
R2#sh interfacess1/0 //串口带宽小于2.048,所以默认不采用FIFO,而是WFC
Serial1/0 is up,line protocol is up
Hardware is M4T
Internet address is 192.168.23.2/24
MTU 1500 bytes, BW 1544 Kbit, DLY 20000 usec,
reliability 255/255, txload 1/255, rxload1/255
Encapsulation HDLC, crc 16, loopback not set
Keepalive set (10 sec)
Restart-Delay is 0 secs
CRC checking enabled
Last input 00:00:06, output 00:00:07, outputhang never
Last clearing of "show interface"counters never
Input queue: 0/75/0/0(size/max/drops/flushes); Total output drops: 0
Queueing strategy: weighted fair
Output queue: 0/1000/64/0 (size/maxtotal/threshold/drops)
Conversations 0/1/256 (active/max active/max total)
Reserved Conversations 0/0 (allocated/maxallocated)
Available Bandwidth 1158 kilobits/sec
5 minute input rate 0 bits/sec, 0 packets/sec
5 minute output rate 0 bits/sec, 0packets/sec
70 packets input, 5288 bytes, 0 no buffer
Received 69 broadcasts, 0 runts, 0 giants,0 throttles
0 input errors, 0 CRC, 0 frame, 0 overrun,0 ignored, 0 abort
107 packets output, 7759 bytes, 0underruns
0 output errors, 0 collisions, 3 interfaceresets
0 output buffer failures, 0 output buffersswapped out
3 carrier transitions DCD=up DSR=up DTR=up RTS=up CTS=up
R3#sh interfacess1/0 //强制在串口启用FIFO,并修改队列长度
Serial1/0 is up,line protocol is up
Hardware is M4T
Internet address is 192.168.23.3/24
MTU 1500 bytes, BW 1544 Kbit, DLY 20000 usec,
reliability 255/255, txload 1/255, rxload1/255
Encapsulation HDLC, crc 16, loopback not set
Keepalive set (10 sec)
Restart-Delay is 0 secs
CRC checking enabled
Last input 00:00:09, output 00:00:08, outputhang never
Last clearing of "show interface"counters never
Input queue: 0/75/0/0(size/max/drops/flushes); Total output drops: 0
Queueing strategy: fifo
Output queue: 0/100 (size/max)
5 minute input rate 0 bits/sec, 0 packets/sec
5 minute output rate 0 bits/sec, 0packets/sec
128 packets input, 8832 bytes, 0 no buffer
Received 97 broadcasts, 0 runts, 0 giants,0 throttles
0 input errors, 0 CRC, 0 frame, 0 overrun,0 ignored, 0 abort
98 packets output, 7152 bytes, 0 underruns
0 output errors, 0 collisions, 3 interfaceresets
0 output buffer failures, 0 output buffersswapped out
3 carrier transitions DCD=up DSR=up DTR=up RTS=up CTS=up
实验三、拥塞管理之PQ优先队列

R1配置:
R1#conft
R1(config)#intlo 1
R1(config-if)#ipadd 1.1.1.1 255.255.255.0
R1(config-if)#exit
R1(config)#intlo 2
R1(config-if)#ipadd 2.2.2.2 255.255.255.0
R1(config-if)#exit
R1(config)#intfa0/0
R1(config-if)#ipadd 192.168.12.1 255.255.255.0
R1(config-if)#nosh
R1(config-if)#exit
R1(config)#routerrip
R1(config-router)#version2
R1(config-router)#noauto-summary
R1(config-router)#net1.1.1.0
R1(config-router)#net2.2.2.0
R1(config-router)#net192.168.12.0
R1(config-router)#exit
R1(config)#access-list1 permit 1.1.1.0 0.0.0.255 //设置ACL 1抓取源的流
R1(config)#priority-list1 protocol ip high list 1//设置ACL 1的流量为最高优先级
R1(config)# #priority-list1 protocol http medium//设置所有http的流量为中优先级
R1(config)#priority-list1 default normal //其他流量默认为normal
R1(config)#priority-list1 queue-limit 40 50 60 70//设置高、中、普通、低队列长度
R1(config)#intfa0/0
R1(config-if)#priority-group1 //将队列优先级应用到接口
R1(config-if)#exit
R2配置:
R2#conft
R2(config)#intlo 1
R2(config-if)#ipadd 22.22.22.22 255.255.255.255
R2(config-if)#exit
R2(config)#intfa0/0
R2(config-if)#ipadd 192.168.12.2 255.255.255.0
R2(config-if)#nosh
R2(config-if)#exit
R2(config)#routerrip
R2(config-router)#version2
R2(config-router)#noauto-summary
R2(config-router)#net192.168.12.0
R2(config-router)#net22.22.22.22
R2(config-router)#exit
测试配置:
R1#debugpriority //开启调试模式
R1#ping22.22.22.22 source 1.1.1.1
Typeescape sequence to abort.
Sending5, 100-byte ICMP Echos to 22.22.22.22, timeout is 2 seconds:
Packetsent with a source address of 1.1.1.1
!!!!!
Successrate is 100 percent (5/5), round-trip min/avg/max = 12/85/188 ms
*Mar 1 00:27:07.151: PQ: FastEthernet0/0: ip(s=1.1.1.1, d=22.22.22.22) -> high
*Mar 1 00:27:07.155: PQ: FastEthernet0/0 output(Pk size/Q 114/0)
*Mar 1 00:27:07.343: PQ: FastEthernet0/0: ip(s=1.1.1.1, d=22.22.22.22) -> high
*Mar 1 00:27:07.343: PQ: FastEthernet0/0 output(Pk size/Q 114/0)
*Mar 1 00:27:07.403: PQ: FastEthernet0/0: ip(s=1.1.1.1, d=22.22.22.22) -> high
*Mar 1 00:27:07.407: PQ: FastEthernet0/0 output(Pk size/Q 114/0)
R1#ping22.22.22.22 source loopback 2
Typeescape sequence to abort.
Sending5, 100-byte ICMP Echos to 22.22.22.22, timeout is 2 seconds:
Packetsent with a source address of 2.2.2.2
!!!!!
Successrate is 100 percent (5/5), round-trip min/avg/max = 12/108/220 ms
*Mar 1 00:38:15.583: PQ: FastEthernet0/0: ip(defaulting) -> normal
*Mar 1 00:38:15.587: PQ: FastEthernet0/0 output(Pk size/Q 114/2)
*Mar 1 00:38:15.751: PQ: FastEthernet0/0: ip(defaulting) -> normal
*Mar 1 00:38:15.755: PQ: FastEthernet0/0 output(Pk size/Q 114/2)
*Mar 1 00:38:15.879: PQ: FastEthernet0/0: ip (defaulting)-> normal
*Mar 1 00:38:15.879: PQ: FastEthernet0/0 output(Pk size/Q 114/2)
*Mar 1 00:38:15.899: PQ: FastEthernet0/0: ip(defaulting) -> normal
*Mar 1 00:38:15.899: PQ: FastEthernet0/0 output(Pk size/Q 114/2)
*Mar 1 00:38:16.123: PQ: FastEthernet0/0: ip(defaulting) -> normal
*Mar 1 00:38:16.127: PQ: FastEthernet0/0 output(Pk size/Q 114/2)
R1#shqueueing interface fa0/0
InterfaceFastEthernet0/0 queueing strategy: priority
Outputqueue utilization (queue/count)
high/143 medium/0 normal/237 low/0
PQ优先队列分别有四个优先队列:高(high)、中(medium)、普通(normal)、低(low)优先。每个队列长度有限,超出队列长度的数据将采用队尾丢弃。PQ的调度机制首先要把高优先队列中的报文清空,然后才发送中优先队列,以此类推。在这种机制下被分配到高优先队列的重要数据被优先发送,尤其在容易发生拥塞的低速率接口上。
PQ支持以下数据分类条件:
协议及其子协议类型
数据入口
报文长度
访问列表
IP数据报片段
使用PQ注意以下几点
由于总是优先发送高优先队列中的数据,如果设置不当,有可能造成低优先队列中的数据永远不能被转发,所以 建议使用CAR或流量整形技术限制高优先队列的流量(长度)。
PQ要花费更长的时间转发数据,因为数据包是经由处理器分类的
PQ会引入额外接口开销,这种开销对高速接口来说是不可接受的,但低速接口可以接受
PQ是静态配置的,不能自动适应网络状况的变化
隧道接口不支持PQ
实验四、拥塞管理之CQ自定义队列
PC1配置
PC#conft
PC(config)#ipdefault-gateway 192.168.1.1
PC(config)#intfa0/0
PC(config-if)#ipadd 192.168.1.11 255.255.255.0
PC(config-if)#nosh
PC(config-if)#exit
R1配置:
R1#conft
R1(config)#intfa0/0
R1(config-if)#ipadd 192.168.1.1 255.255.255.0
R1(config-if)#nosh
R1(config-if)#exit
R1(config)#intfa0/1
R1(config-if)#ipadd 192.168.12.1 255.255.255.0
R1(config-if)#nosh
R1(config-if)#exit
R1(config)#routerrip
R1(config-router)#noauto-summary
R1(config-router)#version2
R1(config-router)#net192.168.1.0
R1(config-router)#net192.168.12.0
R1(config-router)#exit
R1(config)#access-list10 permit 192.168.1.0 0.0.0.255
R1(config)#queue-list1 protocol ip 1 tcp www
R1(config)#queue-list1 protocol ip 2 list 10
R1(config)#queue-list1 default 3
R1(config)#queue-list1 queue 1 limit 100
R1(config)#queue-list1 queue 2 limit 100
R1(config)#queue-list1 queue 2 limit 100
R1(config)#intfa0/0
R1(config-if)#custom-queue-list1
R1(config-if)#exit
R2配置:
R2#conft
R2(config)#intfa0/1
R2(config-if)#ipadd 192.168.12.2 255.255.255.0
R2(config-if)#nosh
R2(config-if)#exit
R2(config)#routerrip
R2(config-router)#version2
R2(config-router)#noauto-summary
R2(config-router)#net192.168.12.0
R2(config-router)#exit
测试配置:
PC#ping192.168.12.2
Typeescape sequence to abort.
Sending5, 100-byte ICMP Echos to 192.168.12.2, timeout is 2 seconds:
!!!!!
Successrate is 100 percent (5/5), round-trip min/avg/max = 40/115/316 ms
R1#debugcustom-queue
Customoutput queueing debugging is on
*Mar 1 00:23:02.199: CQ: FastEthernet0/0 output(Pk size/Q: 66/2) Q # was 2 now 2
*Mar 1 00:23:11.275: CQ: FastEthernet0/0 output(Pk size/Q: 351/3) Q # was 2 now 3
实验五、拥塞管理之WFQ队列机制

R1配置:
R1#conft
R1(config)#int lo 1
R1(config-if)#ipadd 1.1.1.1 255.255.255.255
R1(config-if)#exit
R1(config)#ints1/0
R1(config-if)#clockrate 64000
R1(config-if)#ipadd 192.168.12.1 255.255.255.0
R1(config-if)#fair-queue100 512 100//定义每个队列的长度,可以容乃多少个队列,保留队列即为RSVP预留队列数
R1(config-if)#hold-queue2000 out//所有队列报文总和不能大于2000,否则掉弃
R1(config-if)#nosh
R2配置:
R2#conft
R2(config)#ints1/0
R2(config-if)#clockrate 64000
R2(config-if)#ipadd 192.168.12.2 255.255.255.0
R2(config-if)#nosh
R2(config-if)#exit
R2(config)#iproute 0.0.0.0 0.0.0.0 192.168.12.1
检查配置:
R1#showqueue s1/0
Input queue: 0/75/0/0(size/max/drops/flushes); Total output drops: 0
Queueing strategy: weighted fair
Output queue:0/2000/100/0 (size/max total/threshold/drops)
Conversations 0/1/512 (active/max active/max total)
Reserved Conversations 0/0 (allocated/maxallocated)
Available Bandwidth 1158 kilobits/sec
R1#shqueueing fair
Currentfair queue configuration:
Interface Discard Dynamic Reserved Link Priority
threshold queues queues queues queues
Serial1/0 100 512 100 8 1
Serial1/1 64 256 0 8 1
Serial1/2 64 256 0 8 1
Serial1/3 64 256 0 8 1
WFQ是加权公平排队(Weighted Fair Queuing)。它是一种拥塞管理算法,该算法识别对话(以数据流的形式)、分开属于各个对话的分组,并确保传输容量被这些独立的对话公平地分享。WFQ是在发生拥塞时稳定网络运行的一种自动的方法,它能提高处理性能并减少分组的重发。
WFQ是根据流对报文进行动态分类,对于IP网络,五元组(源IP地址、目的IP地址、源端口号、目的端口号、协议号)和IP优先级或者DSCP相同的报文属于同一个流。在接入层的网络中,通常使用IP优先级和五元组配合进行流分类;在汇聚层网络中通常使用DSCP值和五元组配合进行流分类,具有相同特性的报文属于同一个流,使用Hash算法映射到不同的队列中;另外的一个区别就是如果使用WFQ,那么low-volume(字节数小的报文)、higher-precedence(优先级高的报文)的流会比large-volume、lower-precedence的流更先处理。因为WFQ是基于流的,每个流使用不同的队列,这就要求WFQ能够支持很大数目的队列——WFQ最大可以在每个接口支持到4096个队列。WFQ调度主要是为了一个是在各个流之间提供公平的调度即WFQ名字中的F(fairness)的含义,另外一个就是保证高IP precedence的流能够得到更多带宽即WFQ名字中的W(weighted)的含义。为了提供各个流之间的公平调度,WFQ给每个流分配的带宽是相同的。例如一个接口有10条流,该接口带宽为128Kbps,那么每个流得到的带宽为128/10=12.8Kbps。从某种意义上讲,有些类似于时分复用机制(TDM)。WFQ允许其它流使用某条流的剩余带宽,例如接口带宽为128kbps,共10条流,则每条流分配的带宽为12.8kbps,可能实际上某条流例如流1只有5kbps,而流2有20kbps,那么其它的流就可以分配流1所剩余下的12.8-5=7.8kbps的带宽。WFQ的加权是根据流中的IP precedence进行的,保证高IP precedence的流分配到更多的带宽。算法为(IP precedence+1)/Sum(IP precedence+1),例如有四个流,其IP precedence分别为1、2、3、4,那么每个流占用的带宽分别为2/14、3/14、4/14、5/14。
WFQ使用WFQ丢弃机制,该机制是对TailDrop的一种改进,WFQ还使用HQL和CDT来决定如何对报文进行丢弃。如果一个新的报文达到时HQL(限制了所有队列报文总数之和)已经到达最大值,该报文直接被丢弃;如果此时HQL没有到达最大值,WFQ将该报文根据WFQ的分类原则进行分类决定进入到哪个队列并计算出SN,剩下的丢弃机制还会由CDT(限制了每个队列中能够存放的报文数目决定),CDT是每个队列自己的丢弃阀值,如果此时CDT没有到达最大值报文直接进入该队列,如果CDT已经达到阀值,则判断其它队列是否有SN比新进入的报文SN大,如果没有直接丢弃新进入的报文,如果其他队列有SN大于当前入队列的报文,WFQ会选择丢弃SN大最大的报文。简单的说就是当某个队列的报文数目已经超过该队列CDT,WFQ可以选择丢弃其它队列中SN最大的报文。
WFQ的特点:
WFQ:是一种基于流的排队算法,到达的数据包被分成多个流,每个流都被分配给一个FIFO队列。
可以基于IP和TCP或UDP头中以下字段标识流:源IP地址 目的IP地址 协议号 TOS 源TCP/UDP端口号目的TCP/UDP端口号
WFQ插入和丢弃策略
WFQ有一个保持队列(hold queue)=WFQ系统中数据包占用的所有内存之和,数据包到达时,保持队列已满,那就丢弃数据包(WFQ主动丢弃WFQ aggressive dropping)
WFQ与CQ主要区别如下:
CQ可以自定义ACL规则来对报文进行分类,而WFQ只能根据元组对报文进行动态分类;
WFQ和CQ的队列调度方式不一样,CQ的调度方式是RR,而WFQ的调度机制是WFQ调度机制;
WFQ和CQ的报文丢弃机制不一样:CQ使用Tail Drop机制,WFQ使用WFQ丢弃机制,该机制是对Tail Drop的一种改进。
实验六、拥塞管理之CBWFQ队列机制

R1配置:
R1#conf t
R1(config)#int lo1
R1(config-if)#ipadd 1.1.1.1 255.255.255.0
R1(config-if)#exit
R1(config)#int lo2
R1(config-if)#ipadd 2.2.2.2 255.255.255.0
R1(config-if)#exit
R1(config)#intfa0/0
R1(config-if)#ipadd 192.168.12.1 255.255.255.0
R1(config-if)#nosh
R1(config-if)#exit
R1(config)#access-list1 permit 2.2.2.0 0.0.0.255
R1(config)#class-mapRTP //定义一个匹配RTP的类
R1(config-cmap)#matchprotocol rtp
R1(config-cmap)#exit
R1(config)#class-mapFTP //定义一个匹配FTP的类
R1(config-cmap)#matchprotocol ftp
R1(config-cmap)#exit
R1(config)#class-mapHTTP //定义一个匹配HTTP类
R1(config-cmap)#matchprotocol http
R1(config-cmap)#exit
R1(config)#class-mapBT //定义一个匹配BT类
R1(config-cmap)#matchprotocol bittorrent
R1(config-cmap)#exit
R1(config)#class-mapnetwork2 //定义一个匹配2.2.2.0网络的类
R1(config-cmap)#matchaccess-group 1
R1(config-cmap)#exit
R1(config)#policy-mapCBWFQ //创建一个策略,调用以上创建的类
R1(config-pmap)#classRTP //设置RTP类的带宽为3 Mbps
R1(config-pmap-c)#bandwidth3000
R1(config-pmap-c)#classHTTP//设置HTTP类的带宽为2Mbps
R1(config-pmap-c)#bandwidth2000
R1(config-pmap-c)#classFTP//设置FTP类的带宽为512kbps
R1(config-pmap-c)#bandwidth512
R1(config-pmap)#classnetwork2//设置2.2.2.0网段的带宽为1Mbps
R1(config-pmap-c)#bandwidth1000
R1(config-pmap-c)#exit
R1(config-pmap-c)#classBT //BT流量全部掉弃
R1(config-pmap-c)#drop
R1(config-pmap-c)#exit
R1(config-pmap)#classclass-default //网络中剩下的流量除了HTTP,FTP之使用WFQ放到fair-queue中了
R1(config-pmap-c)#fair-queue
R1(config-pmap-c)#exit
R1(config-pmap)#exit
R1(config)#intfa0/0
R1(config-if)#service-policyoutput CBWFQ //策略应用到接口
R1(config-if)#max-reserved-bandwidth 90 //修改可用的最大带宽为90%
R1(config-if)#exit
R2配置:
R2#conf t
R2(config)#int fa0/0
R2(config-if)#ipadd 192.168.12.2 255.255.255.0
R2(config-if)#nosh
R2(config-if)#exit
R2(config)#iproute 0.0.0.0 0.0.0.0 192.168.12.1
R2(config)#exit
实验七、拥塞管理之LLQ队列机制

R1配置:
R1#conf t
R1(config)#int lo 1
R1(config-if)#ip add 1.1.1.1 255.255.255.0
R1(config-if)#exit
R1(config-if)#exit
R1(config)#int s1/0
R1(config-if)#clock rate 64000
R1(config-if)#ip add 192.168.12.1255.255.255.0
R1(config-if)#no sh
R1(config-if)#exit
R1(config)#class-map VOIP //定义一个匹配VOIP的类
R1(config-cmap)#match ip precedence 5
R1(config-cmap)#exit
R1(config)#class-map rtp //定义一个匹配RTP的类
R1(config-cmap)#match protocol rtp
R1(config-cmap)#exit
R1(config)#class-map http //定义一个匹配http的类
R1(config-cmap)#match protocol http
R1(config-cmap)#exit
R1(config)#class-map bt
R1(config-cmap)#match protocol bittorrent//定义一个匹配BT的类
R1(config-cmap)#exit
R1(config)#policy-map LLQ
R1(config-pmap)#cla
R1(config-pmap)#class VOIP //VOIP类流量使用PQ,任何情况下都优先发送,同时最大带宽可以为接口带宽的20%
R1(config-pmap-c)#priority percent 20
R1(config-pmap-c)#exit
R1(config-pmap)#class rtp
R1(config-pmap-c)#priority percent 20
R1(config-pmap-c)#exit
R1(config-pmap)#class
R1(config-pmap)#class http
R1(config-pmap-c)#bandwidth percent 15
R1(config-pmap-c)#exit
R1(config-pmap)#class bt
R1(config-pmap-c)#drop
R1(config-pmap-c)#exit
R1(config-pmap)#class class-default
R1(config-pmap-c)#fair-queue
R1(config-pmap-c)#exit
R1(config-pmap)#exit
R1(config)#int s1/0
R1(config-if)#service-policy output LLQ
R1(config-if)#exit
R2配置:
R2#conf t
R2(config)#int s1/0
R2(config-if)#clock rate 64000
R2(config-if)#ip add 192.168.12.2255.255.255.0
R2(config-if)#no sh
R2(config-if)#exit
R2(config)#ip route 0.0.0.0 0.0.0.0192.168.12.1
实验八、拥塞管理之IP RTP priority优先队列

R1配置:
R1#conf t
R1(config)#int lo 1
R1(config-if)#ip add 1.1.1.1 255.255.255.0
R1(config-if)#exit
R1(config)#class-map http
R1(config-cmap)#match protocol http
R1(config-cmap)#exit
R1(config)#class-map ftp
R1(config-cmap)#match protocol ftp
R1(config-cmap)#exit
R1(config)#class-map bt
R1(config-cmap)#match protocol bittorrent
R1(config-cmap)#exit
R1(config)#class-map rtp
R1(config-cmap)#match protocol rtp
R1(config-cmap)#exit
R1(config)#policy-map LLQ-RTP
R1(config-pmap)#class http
R1(config-pmap-c)#bandwidth percent 15
R1(config-pmap-c)#exit
R1(config-pmap)#class ftp
R1(config-pmap-c)#bandwidth percent 15
R1(config-pmap-c)#exit
R1(config-pmap)#class rtp
R1(config-pmap-c)#bandwidth percent 30
R1(config-pmap-c)#exit
R1(config-pmap)#class bt
R1(config-pmap-c)#drop
R1(config-pmap-c)#exit
R1(config-pmap)#class class-default
R1(config-pmap-c)#fair-queue
R1(config-pmap-c)#exit
R1(config-pmap)#exit
R1(config)#int fa0/0
R1(config-if)#ip add 192.168.12.1255.255.255.0
R1(config-if)#ip rtp priority 16384 16383 60 //设置UDP端口号在16348 16383区间的语音数据放在优先队列里面,并为此队列保留60kpbs带宽
R1(config-if)#service-policy output LLQ-RTP
R1(config-if)#no sh
R1(config-if)#exit
R2配置:
R2#conf t
R2(config)#int fa0/0
R2(config-if)#ip add 192.168.12.2255.255.255.0
R2(config-if)#no sh
R2(config-if)#exit
R2(config)#ip route 0.0.0.0 0.0.0.0192.168.12.1
实验九、拥塞避免之WRED

R1配置:
R1#conf t
R1(config)#ip access-list extended UDP //创建标记VOIP的UDP流量
R1(config-ext-nacl)#permit ip any anyprecedence 5
R1(config-ext-nacl)#exit
R1(config)#class-map UDP //创建一个类匹配UDP
R1(config-cmap)#match access-group name UDP
R1(config-cmap)#exit
R1(config)#policy-map WRED //对这个类创建一个策略,设置它的保留带宽为20%,并启用WRED
R1(config-pmap)#class UDP
R1(config-pmap-c)#bandwidth percent 20
R1(config-pmap-c)#random-detect
R1(config-pmap-c)#exit
R1(config-pmap)#exit
R1(config)#int lo 1
R1(config-if)#ip add 1.1.1.1 255.255.255.0
R1(config-if)#exit
R1(config)#int s1/0
R1(config-if)#clock rate 64000
R1(config-if)#no fair-queue //接口要使用FIFO队列机制才能配置WRED
R1(config-if)#random-detect prec-based //配置WRED基于IP优先级
R1(config-if)#random precedence 5 10 40 10//把IP优先级为5的流量的最小掉弃阈值改为10,最大为40,掉弃可能性为十分之一
R1(config-if)#ip add 192.168.12.1255.255.255.0
R1(config-if)#no sh
R1(config-if)#exit
R1(config)#int s1/1
R1(config-if)#clock rate 64000
R1(config-if)#service-policy out WRED
R1(config-if)#ip add 192.168.13.1 255.255.255.0
R1(config-if)#no sh
R1(config-if)#exit
R2配置:
R2#conf t
R2(config)#int s1/0
R2(config-if)#ip add 192.168.12.2255.255.255.0
R2(config-if)#clock rate 64000
R2(config-if)#no sh
R2(config-if)#exit
R2(config)#ip route 0.0.0.0 0.0.0.0192.168.12.1
R3配置:
R3#conf t
R3(config)#int s1/0
R3(config-if)#clock rate 64000
R3(config-if)#ip add 192.168.13.3255.255.255.0
R3(config-if)#no sh
R3(config-if)#exit
R3(config)#ip route 0.0.0.0 0.0.0.0192.168.13.1
检查配置
R1#sh queueing int s1/1
Interface Serial1/1 queueing strategy: fair
Inputqueue: 0/75/0/0 (size/max/drops/flushes); Total output drops: 0
Queueing strategy: Class-based queueing
Output queue: 0/1000/64/0 (size/max total/threshold/drops)
Conversations 0/1/256 (active/maxactive/max total)
Reserved Conversations 1/1 (allocated/max allocated)
Available Bandwidth 850 kilobits/sec
R1#sh queueing int s1/0
Interface Serial1/0 queueing strategy: randomearly detection (WRED)
Random-detect not active on the dialer
Exp-weight-constant: 9 (1/512)
Mean queue depth: 0
class Random drop Tail drop Minimum Maximum Mark
pkts/bytes pkts/bytes thresh thresh prob
0 0/0 0/0 20 40 1/10
1 0/0 0/0 22 40 1/10
2 0/0 0/0 24 40 1/10
3 0/0 0/0 26 40 1/10
4 0/0 0/0 28 40 1/10
5 0/0 0/0 10 40 1/10
6 0/0 0/0 33 40 1/10
7 0/0 0/0 35 40 1/10
rsvp 0/0 0/0 37 40 1/10
RED random early detection 随机早期检测机制:在队列溢出前就开始随机丢弃数据包,随着队列内数据量的增加,丢包速率也随着增大,但是不能差异化对待各个流,也不能基于流进行丢包操作 主动流的数据包丢弃量会大于非主动流的数据包。RED的配置参数:最小门限最大门限 MPD(mark probability denominator标记概率分母)最小门限以内不丢弃;在最小门限和最大门限之间随机丢弃;超过最大门限全部丢弃(即尾部丢弃)。
WRED(weighted random early detection加权随机早期检测)的出现,增加了针对高.低优先级流量的差异化处理能力,针对不同流量的优先级建立不同的流量简档(包含最小门限,最大门限和MPD)流量优先级基于IP优先级或DSCP值WRED认为RSVP流量属于丢包敏感型流量,因而丢弃RSVP流的流量之前会首先丢弃非RSVP流量;非IP流量是最不重要的流量,最先丢弃。接口下的WRED针对TCP的流量是有效的,但对于UDP等其他流量没有效果,如果需要对UDP流量进行处理就要结合CBWFQ。注意
建议WRED用在核心层网络设备上,不应用在语音队列
根据当前队列和最后的平均队列计算当前的平均队列长度。
CBWFQ(基于类别的加权随机早期检测)在CBWFQ中使用WRED就能得到CBWRED.
不能在同一个分类映射上同时应用WRED和WFQ机制。
WRED不能与PQ,CQ,WFQ同时应用于同一个接口
实验十、拥塞避免之CAR(承诺访问速率)
R1配置:
R1#conf t
R1(config)#access-list100 permit tcp any any eq 23
R1(config)#intlo 1
R1(config-if)#ip add 1.1.1.1 255.255.255.0
R1(config-if)#exit
R1(config)#int fa0/0
R1(config-if)#ip add 192.168.12.1 255.255.255.0
R1(config-if)#rate-limit output 1000000 2000 5000conform-action transmit exceed-action drop//这条命令的意思是出方向上对所有的流量限制速率为1Mbps,流的平均速率(CIR)为2000byte,流的突发所允许的最大的流量尺寸为5000byte,如果没有超出速率则传输,超过则丢弃包
R1(config-if)#no sh
R1(config-if)#exit
R1(config)#int fa0/1
R1(config-if)#ip add 192.168.13.1 255.255.255.0
R1(config-if)#rate-limit output access-group 100 10000003000 5000 conform-action set-prec-transmit 0 exceed-action continue //在出方向上对telnet的流量限制CIR为1Mbps,平均流量为2000字节,突发的流量最大为5000字节,在接入速率内的流量被设置为IP优先级0传输,超出的流量继续下一条CAR策略
R1(config-if)#rate-limit output 2000000 3000 3500conform-action set-prec-transmit 1 exceed-action drop//其他流量传输速率CIR为2M,平均流量为3000字节,突发的流量最大5000字节,在速率内的流量没有优先级传输,超出速率则丢弃
R1(config-if)#no sh
R1(config-if)#exit
R2配置:
R2#conf t
R2(config)#int fa0/0
R2(config-if)#ip add 192.168.12.2 255.255.255.0
R2(config-if)#no sh
R2(config-if)#exit
R2(config)#ip route 0.0.0.0 0.0.0.0 192.168.12.1
R3配置:
R3#conf t
R3(config)#int fa0/0
R3(config-if)#ip add 192.168.13.3 255.255.255.0
R3(config-if)#no sh
R3(config-if)#exit
R3(config)#ip route 0.0.0.0 0.0.0.0 192.168.13.1
R3(config)#line vty 0
R3(config-line)#login local
R3(config-line)#exit
检查配置
R1#ping 192.168.12.2 source 1.1.1.1 size 3000 repeat 50//用小于最大速率ping正常
Type escape sequence to abort.
Sending 50, 3000-byte ICMP Echos to 192.168.12.2, timeoutis 2 seconds:
Packet sent with a source address of 1.1.1.1
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
Success rate is 100 percent (50/50), round-tripmin/avg/max = 12/122/376 ms
R1#ping 192.168.12.2 source 1.1.1.1 size 5000 repeat 50//用等于最大速率ping会掉包
Type escape sequence to abort.
Sending 50, 5000-byte ICMP Echos to 192.168.12.2, timeoutis 2 seconds:
Packet sent with a source address of 1.1.1.1
!.!.!.!.!.!.!.!.!.!.!.!.!.!.!.!.!.!.!.!.!.!.!.!.!.
Success rate is 50 percent (25/50), round-tripmin/avg/max = 160/197/276 ms
R1#telnet 192.168.13.3
Trying 192.168.13.3 ... Open
User Access Verification
Username:
Password:
Username:
[Connection to 192.168.13.3 closed by foreign host]
R1#sh int fa0/1 rate-limit
FastEthernet0/1
Output
matches:access-group 100
params: 1000000 bps, 3000 limit, 5000 extended limit
conformed 20packets, 1206 bytes; action: set-prec-transmit 0
exceeded 0packets, 0 bytes; action: continue
last packet:23048ms ago, current burst: 0 bytes
last cleared00:16:07 ago, conformed 0 bps, exceeded 0 bps
实验十一、拥塞避免之通用流量整形(GTS)
R1配置:
R1#conf t
R1(config)#$ 100 permit icmp 1.1.1.00.0.0.255 192.168.13.0 0.0.0.255
R1(config)#int lo 1
R1(config-if)#ip add 1.1.1.1 255.255.255.0
R1(config-if)#exit
R1(config)#int s1/0
R1(config-if)#clock rate 64000
R1(config-if)#ip add 192.168.12.1255.255.255.0
R1(config-if)#traffic-shape rate 256000 4000050000 //CIR承诺信息速率256000byte,BC持续突发速率40000 byte,BE突发速率50000 byte
R1(config-if)#no sh
R1(config-if)#exit
R1(config)#int s1/1
R1(config-if)#clock rate 64000
R1(config-if)#ip add 192.168.13.1255.255.255.0
R1(config-if)#traffic-shape group 100 8000
R1(config-if)#no sh
R1(config-if)#exit
R2配置:
R2#conf t
R2(config)#int s1/0
R2(config-if)#clock rate 64000
R2(config-if)#ip add 192.168.12.2255.255.255.0
R2(config-if)#no sh
R2(config-if)#exit
R2(config)#ip route 0.0.0.0 0.0.0.0192.168.12.1
R3配置:
R3#conf t
R3(config)#int s1/0
R3(config-if)#clock rate 64000
R3(config-if)#ip add 192.168.13.3255.255.255.0
R3(config-if)#no sh
R3(config-if)#exit
R3(config)#ip route 0.0.0.0 0.0.0.0192.168.13.1
测试检查
R1#ping 192.168.13.3 source 1.1.1.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to192.168.13.3, timeout is 2 seconds:
Packet sent with a source address of 1.1.1.1
!!!!!
Success rate is 100 percent (5/5), round-tripmin/avg/max = 1/163/252 ms
R1#ping 192.168.13.3 source 1.1.1.1 size 5000//大包不通
Type escape sequence to abort.
Sending 5, 5000-byte ICMP Echos to192.168.13.3, timeout is 2 seconds:
Packet sent with a source address of 1.1.1.1
.....
Success rate is 0 percent (0/5)
R1#ping 192.168.12.2 source 1.1.1.1 size 5000//好慢
Type escape sequence to abort.
Sending 5, 5000-byte ICMP Echos to 192.168.12.2,timeout is 2 seconds:
Packet sent with a source address of 1.1.1.1
!!!!!
Success rate is 100 percent (5/5), round-tripmin/avg/max = 648/716/764 ms
R1#sh traffic-shape
Interface Se1/0
Access Target Byte Sustain Excess Interval Increment Adapt
VC List Rate Limit bits/int bits/int (ms) (bytes) Active
- 256000 11250 40000 50000 156 5000 -
Interface Se1/1
Access Target Byte Sustain Excess Interval Increment Adapt
VC List Rate Limit bits/int bits/int (ms) (bytes) Active
- 100 8000 2000 8000 8000 1000 1000 -
R1#sh traffic-shape queue
Traffic queued in shaping queue on Serial1/0
Queueing strategy: weighted fair
Queueing Stats: 0/1000/64/0 (size/max total/threshold/drops)
Conversations 0/0/32 (active/maxactive/max total)
Reserved Conversations 0/0 (allocated/max allocated)
Available Bandwidth 256 kilobits/sec
Traffic queued in shaping queue on Serial1/1
Traffic shape group: 100
Queueing strategy: weighted fair
Queueing Stats: 0/1000/64/0 (size/max total/threshold/drops)
Conversations 0/1/16 (active/maxactive/max total)
Reserved Conversations 0/0 (allocated/max allocated)
Available Bandwidth 8 kilobits/sec
CIR:承诺信息速率,这个速率指的是流量在正常情况下发送的速率。
Bc:持续突发速率,指的是在每个时间间隔内流量被允许突发超出正常流量速率的速率,以比特表示。
Be:过量突发速率,是指在第一个时间间隔内,流量被允许突发超出持续突发速率的速率。
Tc:时间间隔,每隔一个Tc,流量会被填充到流量整形的令牌桶中。为了正确配置流量整形,首先必须知道流量整形用于填充令牌桶的时间间隔,通过使用下面的公式:Tc=Bc/CIR。
流量整形的时间间隔不能小于10ms或者大于125ms。路由器基于Tc=Bc/CIR的公式发现最好的时间间隔。默认的时间间隔是125ms。这个时间间隔是CIR和Bc配置的结果,用户不可配置。思科建议BC应当是CIR的1/8,他将会在每秒钟内产生8个125ms的时间间隔。
实验十二、拥塞避免之基于类的流量整形(Class-based Shaping)

R1配置:
R1#conf t
R1(config)#class-map icmp
R1(config-cmap)#match protocol icmp
R1(config-cmap)#exit
R1(config)#class-map telnet
R1(config-cmap)#match protocol telnet
R1(config-cmap)#exit
R1(config)#policy-map
R1(config)#policy-map CBS
R1(config-pmap)#class icmp
R1(config-pmap-c)#shape peak 64000 8000 8000 //符合http流量的平均速率为64kbps,BC为8kbps,BE为8kbps
R1(config-pmap-c)#exit
R1(config-pmap)#class telnet
R1(config-pmap-c)#shape average 8000//符合telnet流量的平均速率为8Kbps,BC、BE默认
R1(config-pmap-c)#shape max-buffers 100//调整队列长度
R1(config-pmap-c)#exit
R1(config-pmap)#exit
R1(config)#int lo 1
R1(config-if)#ip add 1.1.1.1 255.255.255.0
R1(config-if)#exit
R1(config)#int s1/0
R1(config-if)#clock rate 64000
R1(config-if)#ip add 192.168.12.1255.255.255.0
R1(config-if)#service-policy output CBS
R1(config-if)#no sh
R1(config-if)#exit
R2配置:
R2#conf t
R2(config)#int s1/0
R2(config-if)#clock rate 64000
R2(config-if)#ip add 192.168.12.2255.255.255.0
R2(config-if)#no sh
R2(config-if)#exit
R2(config)#line vty 0
R2(config-line)#login local
R2(config-line)#exit
R2(config)#ip route 0.0.0.0 0.0.0.0192.168.12.1
检查配置:
R1# ping 192.168.12.2 size 7000 //有掉包
Type escape sequence to abort.
Sending 5, 7000-byte ICMP Echos to192.168.12.2, timeout is 2 seconds:
!!..!
Success rate is 60 percent (3/5), round-tripmin/avg/max = 1916/1968/2000 ms
R1#telnet 192.168.12.2
Trying 192.168.12.2 ... Open
User Access Verification
Username:
R1#sh traffic-shape queue
Trafficqueued in shaping queue on Serial1/0
Traffic shape class: http
Queueing strategy: weighted fair
Queueing Stats: 0/100/64/0 (size/maxtotal/threshold/drops)
Conversations 0/0/16 (active/max active/max total)
Reserved Conversations 0/0 (allocated/maxallocated)
Available Bandwidth 64 kilobits/sec
Traffic shape class: telnet
Queueing strategy: weighted fair
Queueing Stats: 0/1000/64/0 (size/maxtotal/threshold/drops)
Conversations 0/0/16 (active/max active/max total)
Reserved Conversations 0/0 (allocated/maxallocated)
Available Bandwidth 8 kilobits/sec
Class-based Shaping,和CB-policing类似用于限制速率,并且如果应用了CB-shaping,该接口的调度为只能是WFQ,和GTS一样,也没有marking的能力。也采用令牌桶算法,如果令牌桶足够,那么直接转发,如果不够会放到shaping queue中等待令牌填充,这点也和GTS相同CIR=Bc/Tc,现在引出另一个参数PIR(峰值速率)=CIR(1+Be/Bc),即等于令牌桶大小=BC+BE。配置BE后,没有增加CIR速率,是在链路空闲时,在令牌桶中存储下更多令牌,使其容忍burst能力更强
实验十三、拥塞避免之分布式的流量整形(DTS)
R1配置:
R1#conf t
R1(config)#class-map all
R1(config-cmap)#match any
R1(config-cmap)#exit
R1(config)#policy-map DTS1
R1(config-pmap)#class all
R1(config-pmap-c)#shape average 10000000
R1(config-pmap-c)#exit
R1(config-pmap)#exit
R1(config)#access-list 1 permit 1.1.1.00.0.0.255
R1(config)#access-list 2 permit 2.2.2.00.0.0.255
R1(config)#class-map c1
R1(config-cmap)#match access-group 1
R1(config-cmap)#exit
R1(config)#class-map c2
R1(config-cmap)#match access-group 2
R1(config-cmap)#exit
R1(config)#policy-map DTS2
R1(config-pmap)#class c1
R1(config-pmap-c)#shape average 5000000
R1(config-pmap-c)#exit
R1(config-pmap)#class c2
R1(config-pmap-c)#shape average 5000000
R1(config-pmap-c)#exit
R1(config-pmap)#exit
R1(config)#int lo 1
R1(config-if)#ip add 1.1.1.1 255.255.255.0
R1(config-if)#exit
R1(config)#int lo 2
R1(config-if)#ip add 2.2.2.2 255.255.255.0
R1(config-if)#exit
R1(config)#int fa0/0
R1(config-if)#ip add 192.168.12.1255.255.255.0
R1(config-if)#service-policy output DTS1
R1(config-if)#no sh
R1(config-if)#exit
R1(config)#int fa0/1
R1(config-if)#ip add 192.168.13.1255.255.255.0
R1(config-if)#service-policy output DTS2
R1(config-if)#no sh
R1(config-if)#exit
R2配置:
R2#conf t
R2(config)#int fa0/0
R2(config-if)#ip add 192.168.12.2255.255.255.0
R2(config-if)#no sh
R2(config-if)#exit
R2(config)#ip route 0.0.0.0 0.0.0.0192.168.12.1
R3配置:
R3#conf t
R3(config)#int fa0/0
R3(config-if)#ip add 192.168.13.3255.255.255.0
R3(config-if)#no sh
R3(config-if)#exit
R3(config)#ip route 0.0.0.0 0.0.0.0192.168.13.1
检查配置:
R1#sh traffic-shape queue
Traffic queued in shaping queue onFastEthernet0/0
Traffic shape class: all
Queueing strategy: weighted fair
Queueing Stats: 0/1000/64/0 (size/max total/threshold/drops)
Conversations 0/0/256 (active/maxactive/max total)
Reserved Conversations 0/0 (allocated/max allocated)
Available Bandwidth 10000 kilobits/sec
Traffic queued in shaping queue onFastEthernet0/1
Trafficshape class: c1
Queueing strategy: weighted fair
Queueing Stats: 0/1000/64/0 (size/max total/threshold/drops)
Conversations 0/0/128 (active/maxactive/max total)
Reserved Conversations 0/0 (allocated/max allocated)
Available Bandwidth 5000 kilobits/sec
Traffic shape class: c2
Queueing strategy: weighted fair
Queueing Stats: 0/1000/64/0 (size/max total/threshold/drops)
Conversations 0/0/128 (active/maxactive/max total)
Reserved Conversations 0/0 (allocated/max allocated)
Available Bandwidth 5000 kilobits/sec
DTS有很多好处。包括服务质量(QoS)功能相关的质量的分类,和干劲,尽可能有效地使用过不同的类型的流量带宽。 DTS的配置流量整形在接口级,子级或逻辑接口电平ATM或帧中继永久虚电路(PVC)。 整形可以实现网络的目标数组,并根据以下标准:
物理或逻辑接口上的所有流量
流量通过简单的和扩展的IP访问控制列表(ACL),分类(IP地址,TCP / UDP端口,IP优先级)
业务分类的QoS组(内部数据包的标签应用于上游由承诺访问速率 - 汽车,或QoS策略传播 - QPPB)
最多支持DTS200元的VIP形状队列,支持高达OC-3速率时的平均数据包大小为250字节或更大,并使用VIP2-50或8M静态RAM(SRAM),更好的时候。
不同于一般流量整形(GTS),DTS不需要加权公平队列(WFQ)启用。相反,DTS使用的字形队列公平队列或分布式先入先出(FIFO)。
实验十四、帧中继的流量整形
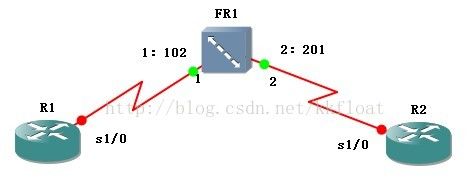
R1配置:
R1#conf t
R1(config)#int s1/0
R1(config-if)#clock rate 64000
R1(config-if)#ip add 192.168.12.1255.255.255.0
R1(config-if)#encapsulation frame-relay
R1(config-if)#frame-relay map ip 192.168.12.2102
R1(config-if)#frame-relay interface-dlci 102
R1(config-fr-dlci)#class DLCI102
R1(config-fr-dlci)#exit
R1(config-if)#no sh
R1(config-if)#exit
R1(config)#policy-map SHAPE
R1(config-pmap)#class class-default
R1(config-pmap-c)#shape average 64000
R1(config-pmap-c)#exit
R1(config-pmap)#exit
R1(config)#map-class frame-relay DLCI102
R1(config-map-class)#service-policy outputSHAPE
R1(config-map-class)#exit
R2配置:
R2#conf t
R2(config)#int s1/0
R2(config-if)#clock rate 64000
R2(config-if)#encapsulation frame-relay
R2(config-if)#frame-relay map ip 192.168.12.1201
R2(config-if)#ip add 192.168.12.2255.255.255.0
R2(config-if)#no sh
R2(config-if)#exit
检查测试配置
R1# ping 192.168.12.2 rep 20 size 2000
Type escape sequence to abort.
Sending 20, 2000-byte ICMP Echos to 192.168.12.2, timeoutis 2 seconds:
!!!!!!!!!!!!!!!!!!!!
Success rate is 100 percent (20/20), round-tripmin/avg/max = 188/358/496 ms
R1# ping 192.168.12.2 rep 20 size 6000
Type escape sequence to abort.
Sending 20, 6000-byte ICMP Echos to 192.168.12.2, timeoutis 2 seconds:
!....!..!.!!!!!..!!!
Success rate is 55 percent (11/20), round-tripmin/avg/max = 1304/1771/1996 ms
R1#sh policy-map int s1/0
Serial1/0: DLCI102 -
Service-policyoutput: SHAPE
Class-map:class-default (match-any)
110 packets,123040 bytes
5 minute offered rate 8000 bps, drop rate 0bps
Match: any
TrafficShaping
Target/Average Byte Sustain Excess Interval Increment
Rate Limit bits/int bits/int (ms) (bytes)
64000/64000 2000 8000 8000 125 1000
Adapt Queue Packets Bytes Packets Bytes Shaping
ActiveDepth Delayed Delayed Active
- 0 110 123040 60 61840 no
实验十五、拥塞避免之RSVP(资源保留协议)
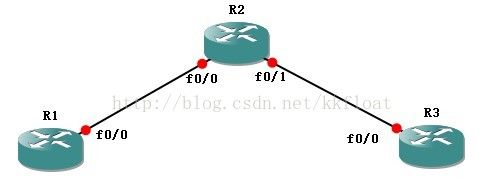
R1配置:
R1#conf t
Enter configuration commands, one per line. End with CNTL/Z.
R1(config)#int lo 1
R1(config-if)#ip add 1.1.1.1 255.255.255.0
R1(config-if)#exit
R1(config)#int fa0/0
R1(config-if)#ip add 192.168.12.1 255.255.255.0
R1(config-if)#ip rsvp bandwidth 20 8//配置总的保留带宽(total-BW)及per-flow的最大保留带宽(per-flow-BW).单位:kbps
R1(config-if)#no sh
R1(config-if)#exit
R1(config)#router rip
R1(config-router)#version 2
R1(config-router)#no auto-summary
R1(config-router)#net 1.1.1.0
R1(config-router)#net 192.168.12.0
R1(config-router)#exit
R2配置:
R2#conf t
R2(config)#int fa0/0
R2(config-if)#ip add 192.168.12.2 255.255.255.0
R2(config-if)#ip rsvp bandwidth 20 8
R2(config-if)#no sh
R2(config-if)#exit
R2(config)#int fa0/1
R2(config-if)#ip add 192.168.23.2 255.255.255.0
R2(config-if)#ip rsvp bandwidth 20 8
R2(config-if)#no sh
R2(config-if)#exit
R2(config)#router rip
R2(config-router)#version 2
R2(config-router)#no auto-summary
R2(config-router)#net 192.168.12.0
R2(config-router)#net 192.168.23.0
R2(config-router)#exit
R3配置:
R3#conf t
R3(config)#int lo 1
R3(config-if)#ip add 3.3.3.3 255.255.255.0
R3(config-if)#exit
R3(config)#int fa0/0
R3(config-if)#ip add 192.168.23.3 255.255.255.0
R3(config-if)#ip rsvp bandwidth 20 8
R3(config-if)#no sh
R3(config-if)#exit
R3(config)#router rip
R3(config-router)#version 2
R3(config-router)#no auto-summary
R3(config-router)#net 192.168.23.0
R3(config-router)#net 3.3.3.0
R3(config-router)#exit
RSVP(资源保留协议) 是 一 个 信 令 协 议, 它 提 供 建 立 连 接 的 资 源 预留, 控 制 综 合 业 务, 往 往 在 IP 网 络 上 提 供 仿 真 电 路。 RSVP 是 所 有 QoS 技 术 中 最 复 杂 的 一 种, 与 尽力 而 为 的 IP 服 务 标 准 差 别 最 大 , 它 能 提 供 最 高 的 QoS 等 级, 使 得 服 务 得 到 保 障、 资 源 分 配 量 化, 服 务 质 量 的 细 微 变 化 能 反馈 给 支 持 QoS 的 应 用 和 用 户。协 议 的 工 作 情 况 如 下:
发 送 端 依 据 高、 低 带 宽 的 范 围、 传 输 迟 延, 以 及 抖 动 来 表 征 发 送 业 务。 RSVP 从 含 有 '业 务 类 别(TSpec)' 信 息 的 发 送 端 发 送 一 个 路 径 信 息 给 目 的 地 址 (单点 广 播 或 多 点 广 播 的 接 收 端)。 每 一 个 支 持RSVP 的 路 由 器 沿 着 下 行 路 由 建 立 一 个 '路 径 状 态 表', 其 中 包 括 路 径 信 息 里 先 前 的 源 地 址 (例 如,朝 着 发 送 端 的 上 行 的 下 一 跳) 为 了 获 得 资 源 预 留, 接 收 端 发 送 一个 上 行 的 RESV (预 留 请 求) 消 息。 除 了 TSpec, RESV 消 息 里 有'请 求 类 别 (RSpec)', 表 明 所 要 求 的 综 合 服 务 类 型, 还 有 一个 '过 滤 器 类 别', 表 征 正 在 为 分 组 预 留资 源 (如 传 输 协 议 和 端 口 号)。 RSpec 和 过 滤 器 类 别 合 起 来 代 表 一 个 '流 的描 述 符', 路 由 器 就 是 靠 它 来 识 别 每 一 个 预 留 资 源 的。 当 每 个 支 持 RSVP 的 路 由 器 沿 着 上 行 路 径 接 收 RESV 的 消息 时, 它 采 用 输 入 控 制 过 程 证 实 请 求, 并 且 配 置 所 需 的 资 源。 如 果 这 个 请 求 得 不 到 满 足 (可 能 由 于 资 源 短 缺 或 未 通 过 认 证), 路 由 器向 接 收 端 返 回 一 个 错 误 消 息。 如 果 这 个 消 息 被 接 受, 路 由 器 就 发 送 上 行RESV 到 下 一 个 路 由 器 。当 最 后 一 个 路 由 器 接 收 RESV, 同 时接 受 请 求 的 时 候, 它 再 发 送 一 个 证 实 消 息 给 接 收 端 。 当 发 送 端 或 接 收 端 结 束 了 一 个 RSVP 会 话 时, 有 一 个 明 显 的 断 开 连 接 的 过 程。 RSVP支 持 的 综 合 业 务 有 以 下 两 种 基 本 类 型:
有 保 证 业 务: 这 种 业 务 是, 尽 可 能 地 仿 真 成 一 条 专 用 虚 电 路。 除 了 要 根 据 TSpec 参 数 的 要 求 确 保 带 宽 的 有 效 性 外, 它 还 可 以 用 把 一 条 路 径 里 的 不同 网 络 部 件 的 参 数 合 并 起 来 的 方 法 来 提 供 一 个 端 到 端 的 固 定 的 队 列 延 迟
受 控 负 载: 这 相 当 于 '无 负 载 条 件 下 尽 力 而 为 服 务'。 因 此, 它 比 '尽 力 而 为'服 务 更 好, 但 是 不 能 提 供 '有 保 证 业 务'所 承 诺 的, 具 有 严 格 固 定 队 列 延 迟 的 服 务。
对 于‘有 保 证 业 务’和 受 控 负 载,处 理 不 同 的 (与 类 别 无 关) 数 据 业 务 就象 处 理 没 有 QoS 的 尽 力 而 为 数 据 业 务 那 样。综 合 业 务 采 用 令 牌 筐 模式 来 表 征 输 入/输 出 排 序 算 法。 设 计 令 牌 筐 是 为 了 平 滑 输 出 的 业 务 流, 但 不 象 泄 露 筐 模 式 (也 可 以 平 滑 输 出 的 业 务 流), 令 牌 筐 模 式 允许 数 据 突 发、 在 短 时 间 内 维 持 更 高 的 发 送 速 率。 RSVP 协 议 机 制 要 点: 每个 路 由 器 的 预 留 资 源 是 '软' 的, 即 这 些资 源 需 要 由 接 收 端 定 期 地 刷 新,RSVP 不 是 传 输 协 议, 而 是 网 络 (控 制) 协 议。 作 为 这 样 的 协 议, 它 不 传 送 数 据,但 是 和 TCP 或 者 UDP 的 数 据 '流' 是 并 行 工 作 的 ,应 用 要 求 API 详 细 说 明 数 据 流 的 需 求, 初 始 化 预 留 资 源 请 求, 并 且 在 发 出 初 始 化 请求 后, 接 收 预 留 成 功 或 失 败 的 通 知 并 贯 穿 于 整 个 会 话 过 程。 为 了 更 好 地 利 用 API, API 也 要 包 含 那 些 描 述 在 整 个 预 留 时间 内 的 预 留 建 立 期 间 或 之 后, 当 条 件 发 生 变 化 时 出 现 问 题 的 RSVP 错误 信 息 根 据 接 收 端 的 情 况 来 预 留 资 源, 是 为 了 有 效 的 接 纳 相 当 复 杂 的 (组播) 接 收 端 组 在 上 行 方 向 的 业 务 复 制 点 处 组 播 预 留 资 源 混 合 在 一 起 (仍 然 有 不 易 理 解 的 复 杂 算 法 在 里 面) ,尽 管 RSVP 业 务 可 以 通 过 不 支 持 RSVP 的 路 由 器,但 是 这 会 在 QoS '链' 上 产 生 一 条实验十六、拥塞避免之链路分片和交叉离开(LFI)For Multilink PPP

R1配置:
R1#conf t
R1(config)#int s1/0
R1(config-if)#clock rate 64000
R1(config-if)#encapsulation ppp
R1(config-if)#ppp multilink group 1
R1(config-if)#no sh
R1(config-if)#exit
R1(config)#int s1/1
R1(config-if)#clock rate 64000
R1(config-if)#encapsulation ppp
R1(config-if)#ppp multilink group 1
R1(config-if)#no sh
R1(config-if)#exit
R1(config)#int s1/2
R1(config-if)#clock rate 64000
R1(config-if)#encapsulation ppp
R1(config-if)#ppp multilink group 1
R1(config-if)#no sh
R1(config-if)#exit
R1(config)#int multilink 1
R1(config-if)#fair-queue //必须开启WFQ队列机制
R1(config-if)#ppp multilink fragment delay 5
R1(config-if)#ppp multilink interleave
R1(config-if)#ip add 192.168.12.1255.255.255.0
R1(config-if)#exit
R2配置:
R2#conf t
R2(config)#int s1/0
R2(config-if)#clock rate 64000
R2(config-if)#encapsulation ppp
R2(config-if)#ppp multilink group 1
R2(config-if)#no sh
R2(config-if)#exit
R2(config)#int s1/1
R2(config-if)#clock rate 64000
R2(config-if)#encapsulation ppp
R2(config-if)#ppp multilink group 1
R2(config-if)#no sh
R2(config-if)#exit
R2(config)#int s1/2
R2(config-if)#clock rate 64000
R2(config-if)#encapsulation ppp
R2(config-if)#ppp multilink group 1
R2(config-if)#no sh
R2(config-if)#exit
R2(config)#int multilink 1
R2(config-if)#fair-queue
R2(config-if)#ppp multilink fragment delay 5
R2(config-if)#ppp multilink interleave
R2(config-if)#ip add 192.168.12.2255.255.255.0
R2(config-if)#exit
检查测试:
R1(config-if)#do sh ppp multi
Multilink1
Bundle name: R2
Remote Endpoint Discriminator: [1] R2
LocalEndpoint Discriminator: [1] R1
Bundle up for 00:04:51, total bandwidth 4632, load 1/255
Receive buffer limit 36000 bytes, frag timeout 1000 ms
Interleaving enabled
0/0fragments/bytes in reassembly list
0lost fragments, 82 reordered
0/0discarded fragments/bytes, 0 lost received
0xDE received sequence, 0xDD sent sequence
Member links: 3 active, 0 inactive (max not set, min not set)
Se1/0, since 00:04:51, 386 weight, 378 frag size
Se1/1, since 00:04:51, 386 weight, 378 frag size
Se1/2, since 00:04:50, 386 weight, 378 frag size
No inactive multilink interfaces
R2(config)#do sh ppp multi
Multilink1
Bundle name: R1
Remote Endpoint Discriminator: [1] R1
LocalEndpoint Discriminator: [1] R2
Bundle up for 00:03:17, total bandwidth 4632, load 1/255
Receive buffer limit 36000 bytes, frag timeout 1000 ms
Interleaving enabled
0/0fragments/bytes in reassembly list
0lost fragments, 77 reordered
0/0discarded fragments/bytes, 0 lost received
0xDC received sequence, 0xDD sent sequence
Member links: 3 active, 0 inactive (max not set, min not set)
Se1/0, since 00:03:17, 965 weight, 957 frag size
Se1/1, since 00:03:17, 965 weight, 957 frag size
Se1/2, since 00:03:17, 965 weight, 957 frag size
No inactive multilink interfaces
链路分片和交叉离开(LFI-Link Fragmentation and Interleaving):串行化时延是在物理链路上发送一个帧的时间。假设一个链路的物理clock rate为X bps,那么将花费1/X的时间来发送一个bit。如果合格帧有Y个bit,那将花费Y/X秒来串行化该帧。这意味着较快的链路会有较低的串行化时延。以56kbps的链路举例,发送一个bit的时间是1/56000秒,一个1500字节的帧(12.000bit)讲用12000/56000秒去串行化,即214毫秒 ,当路由器从接口发出去一个帧的时候是发送的一个完整的帧。如果一个小的包、同时对时延敏感的包需要发送出去的时候,恰巧这是路由器已经在开始发送一个比较大的帧,较小的帧不得不等较大的帧传递完毕才能传递,一个1500字节的包在56kbps的链路上串行化时延为214毫秒,这对语音包来说是一个太长的时间了。LFI工具使得大包不会过多的影响小包的串行化时延,它通过把大包分片然后让小包在大包的分片中交叉离开,这样对时延敏感的包就离开了该路由器。
实验十七、拥塞避免之链路分片和交叉离开(LFI)For 帧中继

R1#conf t
R1(config)#int s1/0
R1(config-if)#clock rate 64000
R1(config-if)#encapsulation frame-relay
R1(config-if)#frame-relay map ip 192.168.12.2 102
R1(config-if)#frame-relay interface-dlci 102 pppvirtual-Template 1
R1(config-if)#no sh
R1(config-fr-dlci)#exit
R1(config-if)#exit
R1(config)#int virtual-template 1
R1(config-if)#ip add 192.168.12.1 255.255.255.0
R1(config-if)#ppp multilink
R1(config-if)#ppp multilink fragment delay 4
R1(config-if)#ppp multilink interleave
R1(config-if)#exit
R1(config)#class-map telnet