CNN语义分割系列总结


一、研究背景
语义分割是计算机视觉方向的基础问题之一,如上图所示,该任务是将图片中的每一个目标逐像素分割出来,并且标明该目标是属于哪一类,比如人,车或者马等大类。
基本挑战:结合全局和局部信息的分割任务,在分割相应目标类的同时,如何确保每一个像素被准确分类,通常需要保证边界的精细度。
常用数据集:PASCAL VOC 2012,MS COCO, CityScapes等。
二、FCN
论文目的:基于经典CNN分类模型(AlexNet,VGG,GoogLeNet),探索端到端的全卷积语义分割网络。
论文主要贡献:
- 提出全卷积网络,将经典分类网络成功应用于密集语义分割任务;
- 跳跃连接结构,融合不同网络层的特征,保证分割精度;
- 卷积上采样(反卷积),保证高层次特征和低层次特征融合;
FCN的不足:(1)虽然使用FCN-8s得到比较好的结果,但是依然很粗糙;(2)忽略了像素之间的空间联系;
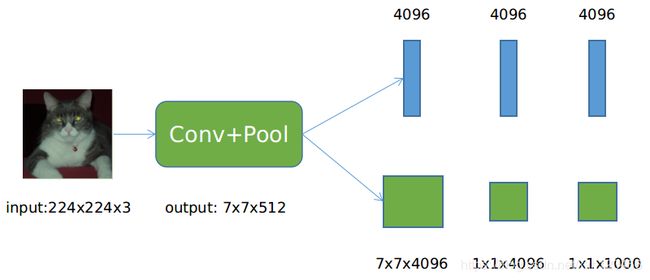
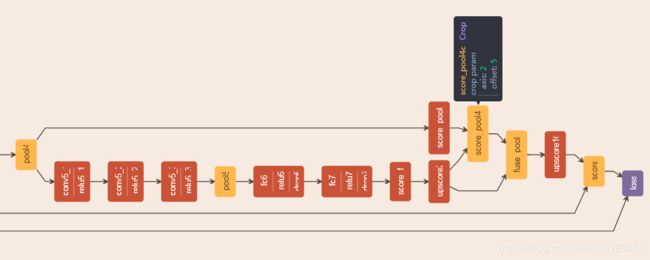
全卷积网络:在CNN图像分类网络中,通常的网络结构:Conv+Pool+3FC,最后一层全连接层输出每一类的概率。如下图所示,通过将全连接层改为全卷积层,可以高效地进行语义分割任务。最后3层FC的大小分别为(4096,4096,1000),那么可以使用三个卷积核(7x7x4096, 1x1x4096, 1x1x4096)将其转换为卷积层。结合反卷积和Crop层(Caffe,类似于裁剪),训练时可以输入任意尺寸的图像。具体转换方式如下图所示:
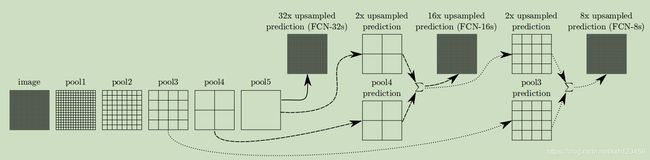
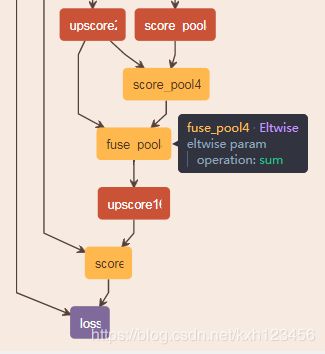
跳跃结构:将低层、精细的特征与高层、粗糙抽象的特征融合,进而获得更加精细、准确的分割结果。如下图所示,比如将pool5的结果与pool4融合,由于pool4的输出特征图是pool5的特征图尺寸的2倍,因此需要将pool5进行2x上采样,也即是本文提出的结构之一,FCN-16s:
上采样(反卷积):为了得到原图大小的输出heatmap,需要进行上采样。我们先回顾卷积的特征图尺寸计算方式。令输入:input,输出:output,kernel size:k,stride:s,pading:p,则经过卷积后的尺寸为:
output = (input - k + 2p)/s + 1 (1)
很显然,反卷积是卷积的逆过程,那么反卷积后的尺寸如何计算,只需将公式反算即可:
input = (output - 1)* s + k - 2p (2)
在作者提供的代码中,可以发现,第一层卷积的pad=100,为什么填充100个像素?以VGG-16为例,假如第一层卷积pad=1,那么可以推算每一层的特征图尺寸。参考公式(1),假设输入尺寸为 H x H x C,由于卷积层特征图尺寸不变,不列出具体计算:
- pool1:H1 = (H - 2)/2 + 1 = H/2
- pool2:H2 = (H1 - 2)/2 + 1 = H/4
- pool3:H3 = (H2 - 2)/2 + 1 = H/8
- pool4:H4 = (H3 - 2)/2 + 1 = H/16
- pool5:H5 = (H4 - 2)/2 + 1 = H/32
可见,经过卷积池化,输入图像的尺寸降低32倍,继续计算FC6的特征图尺寸:
FC6:H6 = (H5 - 7)/2 + 1 = (H - 192)/32
接下来是FC7,以及score_fr(输出21类),卷积核均为1x1,不改变特征图尺寸。因此,反卷积前的特征图尺寸为H6,从这里可以看出,如果不进行100像素填充,那么小于192像素的图片,将无法计算H6。填充100之后,再按照上述公式(1)计算,可以得到:
FC6:H6 = (H5 - 7)/2 + 1 = (H + 6)/32
反卷积核Crop层如何产生与原图尺寸相同的特征图?按照公式(2),计算反卷积Hdeconv后的尺寸:
Hdeconv = (H6 - 1)* 32 + 64 = H + 38
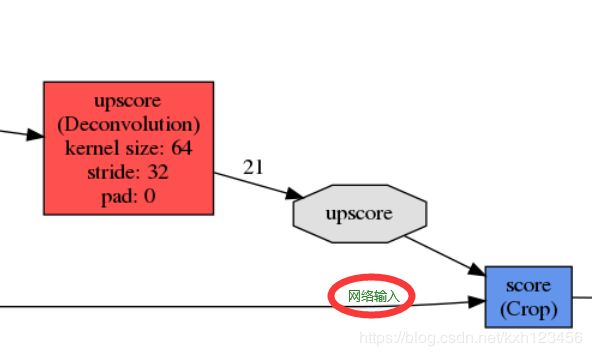
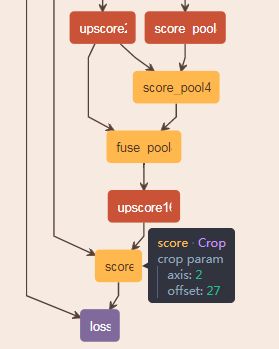
反卷积之后,输出尺寸比原图大38个像素单位,如何保证与输入的尺寸一致,Caffe中采用Crop层调整特征输出的尺寸与原图保持一致,如下图所示,Crop层的输入:上采样层的输出+输入图像,那么输入图像就是Crop层的参考值,决定网络如何对Hdecon进行裁剪,Crop层有个参数offset:

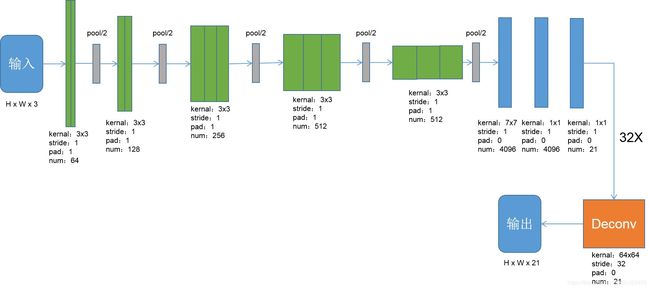
网络结构:以基础网络为VGG-16基本模型,论文提出3个模型,FCN-8s,FCN-16s,FCN-32s,下图是FCN-32s
训练细节:论文是采用分步训练,总共分为三步,
第一步:训练FCN-32s网络,在VGG预训练权重的基础上,修改全连接层为卷积层,微调网络,需要3天时间,见下图:

第二步:训练FCN-16s,使用训练好的FCN-32s权重参数初始化FCN-16s,同时使用跳跃结构融合pool4的输出特征图。然后进行上采样,使得输出特征图与原图尺寸保持一致,需要额外的一天时间,见下图所示:
第三步:训练FCN-8s,与FCN-16s的操作类似;
三、DeepLab系列
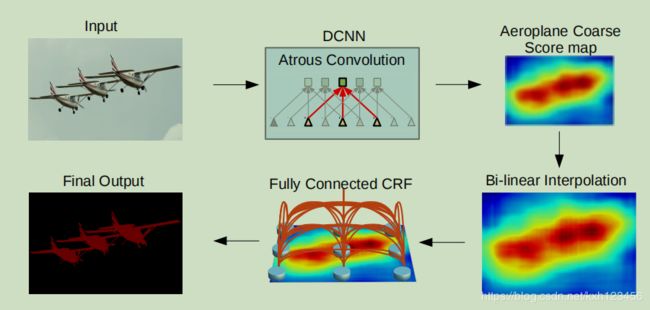
1、deeplab-v1(code:https://bitbucket.org/deeplab/deeplab-public/src/master/)
论文目的:获得更加精确的分割结果,并且兼顾速度的提升。
论文主要贡献:
- 添加空洞卷积,可以增加感受野和特征图的分辨率,并且明确控制感受野大小;
- 提出CRF平滑模块,使得分割结果更加精细;
- 通过空洞卷积,重新设计部分网络,使得速度很快,达到8FPS;
论文不足:(1)略;
网络结构:以预训练网络VGG-16为基础,并对网络作相应的修改,以兼顾速度和精度的平衡,具体设置如下:
(1)全连接层改为卷积层(分割任务必备);
(2)最后两层Pool4和Pool5,滑动步长由2变为1,保证输出特征图不会太小;
(3)最后三层卷积(conv5_1, conv5_2, conv5_3)的空洞值设为2,全连接第一层的空洞值设为4;



2、deeplab-v2(code:https://bitbucket.org/aquariusjay/deeplab-public-ver2/src/master/)
分割问题面临的挑战:
挑战一:为分类任务设计的DCNN需要多次Max-Pooling和卷积层的连续滑动,导致空间信息的丢失。在DeepLabV1中引入了空洞卷积来增加输出的分辨率,以保留更多的空间细节信息。
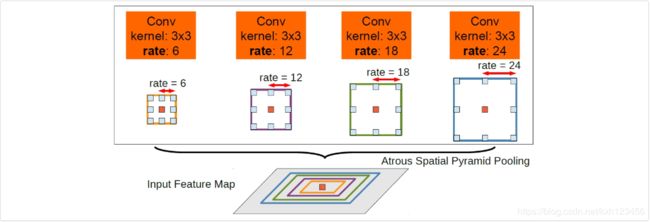
挑战二:图像目标存在多尺度问题。DeepLab v2为了解决这一问题,引入了ASPP(atrous spatial pyramid pooling)模块,即是通过并联不同膨胀速率的空洞卷积层来处理特征图,并将输出特征图融合。
挑战三:分割结果不够精细的问题。这个和DeepLabV1的处理方式一样,在后处理过程使用全连接CRF精细化分割结果。
在deeplab-v1的基础上:(a)增加ASPP模块,解决目标多尺度问题;(b)基础模块由VGG变为ResNet。
ASPP模块如下:采用不同rate的空洞卷积,使得模型可以提取多尺度目标,同时保证网络的效率。
网络结构:
基础结构为ResNet-101,每个模块结构见图1,然后在最上层添加上面的ASPP模块,见图2。
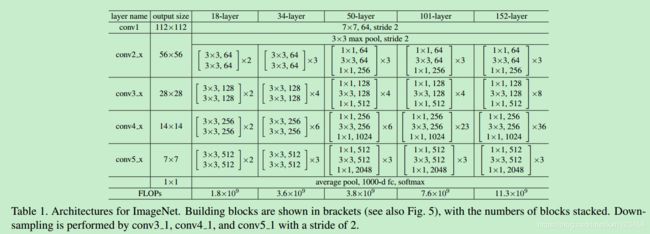 、
、
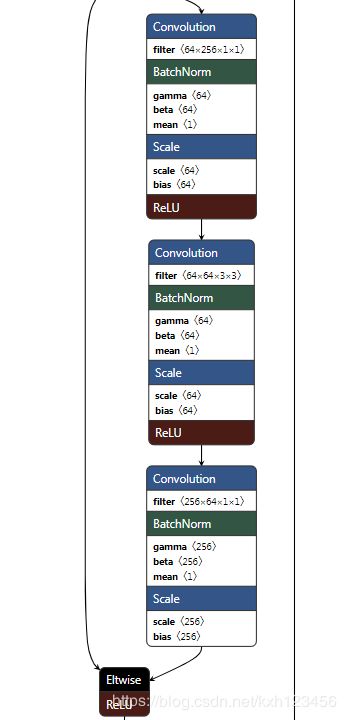 图1
图1
 图2
图2
基本流程:Deeplab-v1和deeplab-v2的基本流程一样,只是更换部分模块。
3、deeplab-v3
论文目的:分割精确度和速度的提升。
论文贡献:
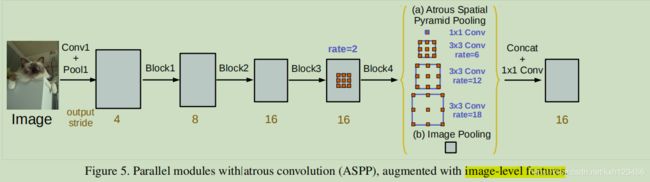
(a)修改ASPP模块(添加BN以及1x1卷积);
(b)添加 image pooling层, 编码全局信息(见图5)。
(c)mutil-grid 模块;
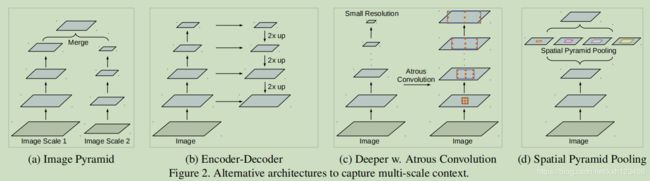
多尺度问题的解决方案如下:
(a)图像金字塔,将输入图片处理为不同的尺度,那么不同的目标就呈现出不同的尺度。
(b)Encoder-Decoder,先将图片不断降采样编码,然后逐渐上采样解码恢复原图大小。
(c)级联空洞卷积,获取更长空间距离的目标信息。
(d)SPP结构,不同空洞率的卷积层并行处理。
网络结构:
训练细节:
Data:PASCAL VOC 2012, 1464(train), 1449(val), and 1456(test),以及增强数据集10582 (trainaug)。
学习率:“poly” learning rate policy
,power为0.9。
优化器:momentum.
输入图像:统一裁剪为 513x513。
BN:ASPP添加BN层,batch_size最好大于或等于16,bn decay=0.9997。在trainaug上训练30k,初始学习率为0.007,output_stride=16。然后在 官方 PASCAL VOC 2012 trainval 上训练30K iterations,学习率为0.001,output_stride=8。
Upsampling Logits:对网络输出进行插值上采样,使其与标签大小一致。
Data Augmentation:随机缩放图片,缩放因子[0.5, 2],随机左右翻转图片。
4、deeplab-v3+
论文贡献:
- 提出新的 encode-decoder结构,encoder为deeplab-v3,新设计decoder;
- 借助空洞卷积,可以任意控制encoder模块特征图的分辨率;
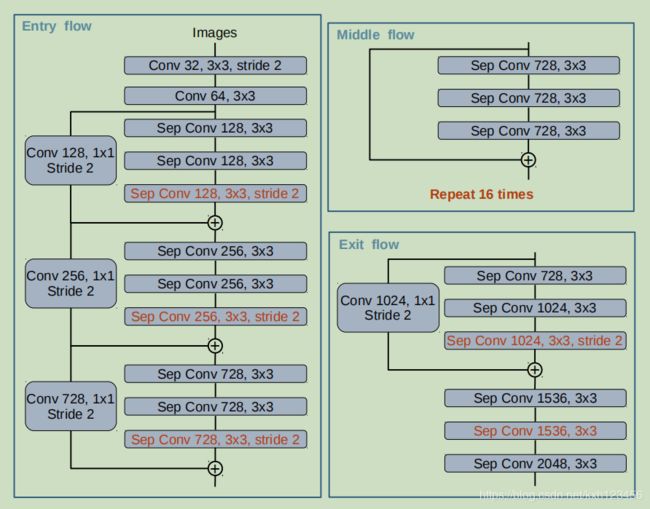
- 采用Xception网络,ASPP和Decoder模块添加空洞深度可分离卷积(depthwise separable convolution)
- https: //github.com/tensorflow/models/tree/master/research/deeplab
网络结构:总共三部分,基础模块(ResNet/Xception)+ASPP+Decoder,其中基础模块的低层特征需要和decoder融合,然后逐渐恢复到output_stride=4。

Xception修改:(a)不修改 entry flow network;(b)所有的max-pooling替换为带孔的深度可分离卷积;(c)每个3x3 深度可分离卷积后添加 BN和ReLU。
Decoder结构:
(a)1x1卷积用于降低encoder模块中低层(low-level)特征的通道数量(256->48),降低网络的复杂度。
(b)两个3x3卷积用于获取尖锐的目标边界。
(c)使用encoder中的Conv2的特征图。
训练细节:
ResNet-101的训练设置与DeepLab-V3一致。
Xception为主干网络时,需修改优化器和学习率,优化器为Nesterov momentum optimizer with momentum = 0.9,学习率为initial learning rate = 0.05, rate decay = 0.94 every 2 epochs, and weight decay 4e-5.