2018年DevOps最新现状研究报告解读
2018年度的DevOps最新研究现状姗姗来迟,但最终还是来了,让我们来看一下这份报告今年会给我们带来那些启示。
研究人员
铁打的营盘,流水的Dora(DevOps Research and Assessment)。参与其中Jez Humble和Gene Kim一直是这份报告最大的看点,他们的离去虽然是一种遗憾,新的加入也会从其他角度带给我们不同的思考。2018年度的报告的作成主要由splunk和puppet引导给出。

内容概要
DevOps实践之路,成功的方法很多,但是失败的方式更多
DevOps实践对任意个一个组织来说,都不是一帆风顺的,会有很多起起落落,而这些会使得早期来之不易的上升势头受到打击。
而将DevOps的成功经验进行复制也是一个非常挑战的事情,如何才能顺利推进?一旦碰到挫折,如何才能重回正轨?
虽然DevOps实践是一个不会结束的长期过程,但是还是有方法可以帮助它,这份报告中整理出了其中的五个重要阶段和关键实践内容以帮助DevOps实践之旅的顺利展开。
企业最高管理层比团队成员对DevOps进展更加乐观
在很多DevOps的实践中,Job title以C打头的最高级别的管理层往往都会过于乐观,这是因为他们的消息来源是自下而上传递而来,这个过程中往往有过滤和"消毒",导致阻碍进程的问题以及瓶颈都无法被完整看到,由于他们对现状的认识是不完整的,所以在数据上显示出了和团队成员之间的gap。
比如在关于安全团队是否在设计和部署的过程中介入了的问题上,管理层有64%持肯定看法,而团队成员则只有39%持相同看法。
总结:
使得每个人对实践的状况有相同的认知这点非常重要,而实现的方法则可以强化自动化和衡量指标信息的共享上。
跨团队分享是DevOps成功经验能复制的重要因素
DevOps的关键要素C(文化)A(自动化)M(指标)S(分享),在研究中发现分享对于DevOps经验的扩展中具有最为重要的作用。很多DevOps实践取得了一些小范围的成功,但是无法更进一步,导致最终对于业务的正向影响也较为有限。为了使DevOps早期实践获得的成功更好地扩展,跨组织进行成功经验和失败教训的分享对于整个DevOps实践具有重要的作用。
自动化安全策略配置对更高成熟度的DevOps实践具有重要作用
成熟度高的组织相比于其他较低的组织,在自动化安全策略配置方面,效率是其24倍。安全策略已经是整个过程中的一部分,而不再是传统意义上在审查室的例行确认。这要求打破横亘在运维和信息安全团队之间的那堵“墙”,而最终随着信息安全团队的融入,安全配置能够进行自动化配置将会传统意义上的另外一块瓶颈予以打破。
概要解读
解读1:Five Stages
这份报告更多地聚焦于如何进行DevOps的落地实践,提出了五个阶段或者步骤来给予整个实践的旅程更好的引导。而整份报告几乎都是对这五个阶段的展开。无论是刚刚起步的阶段还是卡在某个阶段止步不前的企业,报告称这种方法能够帮助组织更快更好地走向成功。
解读2: DevOps实践成功的扩展
小规模的DevOps试行已经获得成功,但是成功地如何大规模的扩展开来是一个巨大的挑战。如何复制小规模的DevOps的成功,是当下实践的重点挑战之一。
解读3: 偏离方向的实践
有很多团队在九年之前就开始践行DevOps,但是至今似乎不得其门而入,或者卡在某个阶段无法继续。DevOps不是万应灵药,在一个一路高歌猛进的现状之下也需要给自己泼盆冷水了,应更多的聚焦于组织的目标,反向进行落地,DevOps到底能给我们带来什么,在每次实践的时候,功利性地明确到底能带来何种收益,落地之后像个商人一样去检查,而不是仅在文化上的诸如NoBlaming上反复畅谈。
解读4: 融入安全的DevOps
将安全融入DevOps,这从来都不是一个新的话题,甚至还是一个主题:DevSecOps。本年度的报告中将安全策略的自动化配置提到了一个重要的角度,除了其他的都谈过了之外,安全确实是不可获取的一块拼板。
传统意义上的安全,一般情况下在很多项目中本来就是形同虚设,在引入DevOps加快业务交付的同时,将这个问题变得更加尖锐,就像DevOps Hand Book中所提到的那样,开发人员:运维人员:信息安全人员,在实际的情况中往往这个比例是100:10:1,所以安全信息的自动化,不是一个锦上添花的事情,而是如果在实际项目中真正有所谓的信息安全的确认,这是一个必选项,没有信息安全策略的自动化,DevOps注定无法推广开来,除非投入大量的人力进行follow,基于成本的考量,这在现实的世界中不太可行,所以自动化提高效率在此处是一个必选项,除非此信息安全设定可有可无。
数据来源
区域
2018年的亚洲相关的数据上涨了80%,那是因为2017年的比例太低,上涨之后仍然只有可怜的18%。欧洲和美国的数据仍然占到了整体的68%。

加上台湾地区,在这份报告中中国的数据比例占到整体的亚洲部分的4%(大陆地区3%),日本和弹丸小国新加坡各占亚洲数据的37%,印度18%。

所以,整体来说,这份报告基本不能反映中国地区在全球的DevOps发展状况,但作为对标的资料都是有一定的参考意义。

作为欧洲经济三大强国的英/德/法,三家数据占到整个欧洲的3/4.

行业与规模
科技与金融仍然撑起半壁江山,而零售/通信/教育/医疗/政务/健康/保险/制造等主要行业也达到30%左右,整体行业均有涵括,非盈利的组织数据占比明显提高,这也间接印证了2017年的结论之一:DevOps在各个行业已全面展开。
相比较与2017年使用人数,今年对组织大小的判断定义在年度营业收入,使用annual revenue将组织进行划分,10亿美元以上的组织占到1/4,其余规模的组织比例也较为均衡。
角色

比较有趣的是参与调查的人员角色的构成比例,填写调查报告的有9%的C级别的企业最高层管理人员,普通的管理人员有39%,Team Leader和IC占到47%,真正的IC为26%。
DevOps团队
随着DevOps理念和实践的不断推广,与DevOps团队相关的工作人员也开始逐年递增。
| 年份 | 2014 | 2015 | 2016 | 2017 | 2018 |
|---|---|---|---|---|---|
| 占比 | 16% | 19% | 22% | 27% | 29 |

55%的受访者来自于IT部门,36%来自于开发部,相较于2017年的27%,2018年的29%,更加细致:14%(IT部门) + 15% (开发部)
在一个DevOps至今尚无统一定义的2018年,有29%的人在称为DevOps的组织中工作,这是每年都会看的一个有趣数据,而且这个比例还在不断上升。
组织结构
根据调查结果,在DevOps实践中被采用的方式:开发中心方式(58%),特定应用服务的跨职能团队方式(57%),而专职的DevOps团队只占到51%。
另外SRE团队方式是目前采用最少的方式,但是关于后续是否会尝试使用这种方式的调查上,意愿是最高的(28%)。
解读:
通过对受访数据的分析,这次调查报告认为C级别的最高管理人员在后续尝试没有使用过的组织结构方面明显比普通管理人员和团队成员要低得多这个结论非常有趣。
但是我个人认为这是一个非常正常的事情,作为组织变动被影响最大的C级别的最高管理人员,频繁地做影响自己position的变化应该并不算是好主意。
而且很多实践的经验也已经证明,很多项目的内在动力是在于这次调查报告中包含的较少的草根阶层,朴素的动力往往就只是来源于避免没有营养的重复性作业,增加一些自己生活和成长的时间而已,从数据上也可以看出他们根本没有那么多时间去填写调查问卷。

解读:
在看这个结果的时候,先预设一个问题:如果我所在的组织要推行DevOps,我们应该以什么样的组织结构去面对它?
前文中当前使用的结构就是现在的DevOps实践所给出的答案,除了DevOps团队之外,可以看出目前比例最高的仍然是现在的组织构成,开发中心方式明显就是各种GDC,特定应用服务的跨职能团队方式就是大型项目目前的现状,所以实践给出的答案就是:除了DevOps团队之外就是继续使用原有的结构。
为什么SRE方式是目前大家尝试意愿最多的一种呢,从另外一个角度来看,已经有人尝试的方案在备选答案中仅此一家别无分店,自然大家会希望使用google尝试过的方式。这样看来之后,SRE目前选择的最少但是后续希望尝试的最多这个结论也没有太多意外了。
希望后续的报告能够在使用什么样变革型的组织结构以及实践的效果方面有一些数据的支持,不然个人认为这份报告具有的导向性会越来越低。
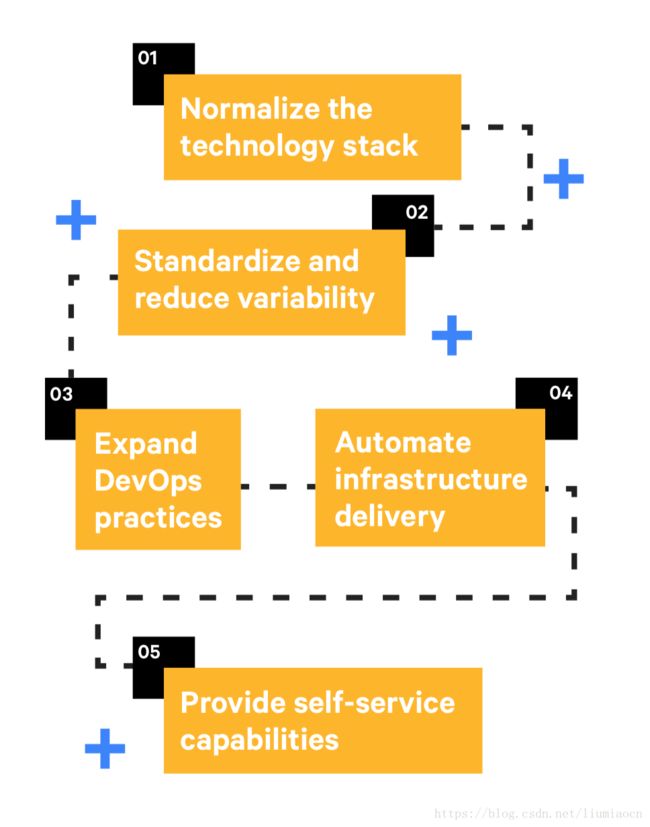
Five Stages
这是整份报告的重中之重,Five Stages,并给出了各个Stage建议做的事情。
四个关键要素:CAMS
调查的角度和方向,调查的方向聚焦于DevOps的四个重要支柱,CAMS这4个维度在分别有不同的侧重点,这也是在实施中所需要关注的。
关键要素细化
C:Culture:文化维度
在文化维度,重点确认DevOps文化在不同的组织结构中的实施状况
- 单一团队
- 单一部门的多个团队
- 单一部门
- 横跨多个部门
A: Automation: 自动化维度
自动化的维度,主要确认当前自动化推行的状况,团队自身是否提供相关服务,自服务所推行的程度:
- 团队自己控制自动化服务
- 使用其他团队提供的自动化服务
- 团队合作提供自动化服务
- 对关键业务功能提供自动化维度的自服务
- 对大多数业务提供自动化维度的自服务
M: Measurement:指标维度
指标维度从系统和业务两个方面进行确认,收集方式从手工和自动两种进行衡量:
- 诸如计算机性能和吞吐等系统指标通过手工方式收集和展示
- 自动收集和展示系统指标
- 业务指标通过手工方式进行收集和展示
- 业务指标通过自动方式进行收集和展示
S:Sharing:分享
分享是DevOps实践经验最快扩展的有效途径,分享的范围大小是衡量的一个重要标准
- 最佳实践和模式在团队内分享
- 最佳实践和模式跨团队分享
- 最佳实践和模式跨组织分享
- 最佳实践和模式在组织外部分享
调查结果
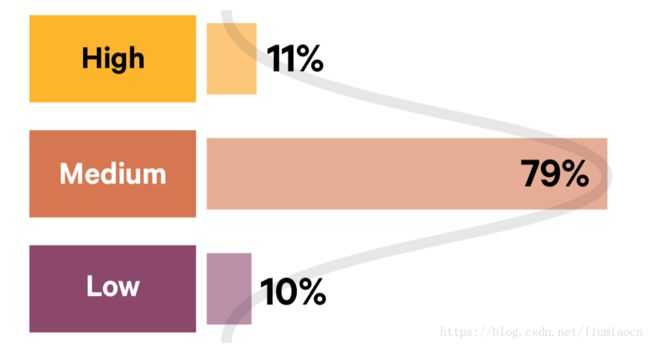
整体结果
整体来说,基本上一般程度和较好程度的已经占到了90%,尚未起步的已经很少。但是一般程度的仍然占据绝大部分,刚刚起步了一些,在一些方面取得了局部的收获但是离较好的程度还有一定的距离,这些占到整体的79%。
C:Culture:文化维度
单一部门的多个团队以及单一团队方式为目前主要的实施方式。

A: Automation: 自动化维度
提供自服务的方式推动自动化的进程仍然只是占到很小的一个比例,更多地还是通过团队以及团队之间的合作来实现自动化。

自动化一直被认为是一个非常容易被切入的维度,但随着实践经验的扩展,依赖逐渐增度,复杂性逐渐增大,自然自动化的成本也愈加的昂贵,相关的问题都逐渐出现。自动化很重要,但是DevOps并不只是简单地工具和自动化,这个结论再一次出现在报告之中。
(请注意本年度上面这张原图有些错误,Low evolution的比例加起来高达到101%,再次验证了小学数学成绩的好坏根本不重要,两位数的加减结果反正也没有人会在乎,这不重要,请忽略)
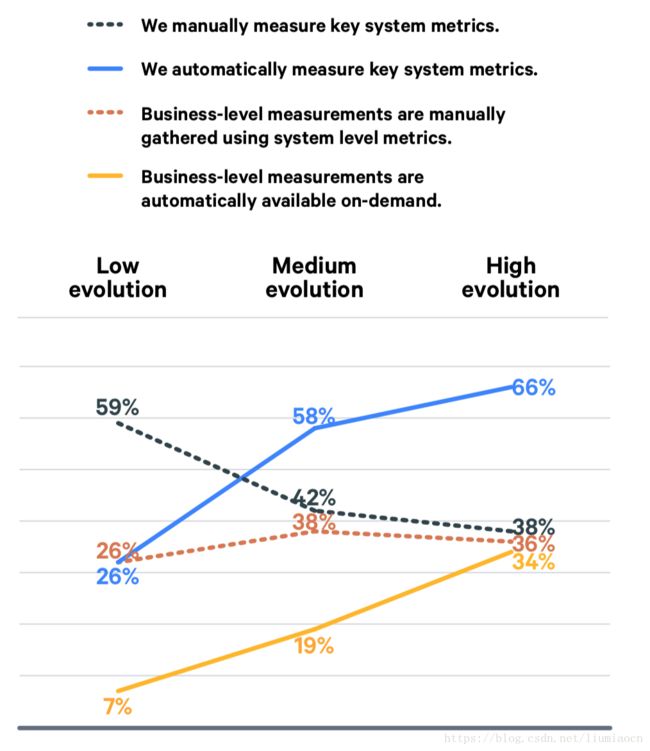
M: Measurement:指标维度
随着成熟度的提高,自动化程度会逐渐提高,手工方式会逐渐降低,这是一个整体的结论,系统级别的指标收集和展示在这个方面体现地非常清楚。
而业务指标数据的收集和展示自动化程度会逐渐提高,但和系统指标相比,复杂性和共通性较低,收集分析统计与展示也较为复杂,无论是自动化还是手工作业,相关的程度还有待于进一步地提升,是一个标准化仍在继续的过程。所以在业务指标的自动化程度会随着成熟度提高的时候明显提高,但是手工的收集和展示方面也呈整体上升的状态,随着标准化的完善和进一步的提升,整体下降的趋势应该会在后续出现,这一点可以在明年及以后的数据中可以进一步的确认。
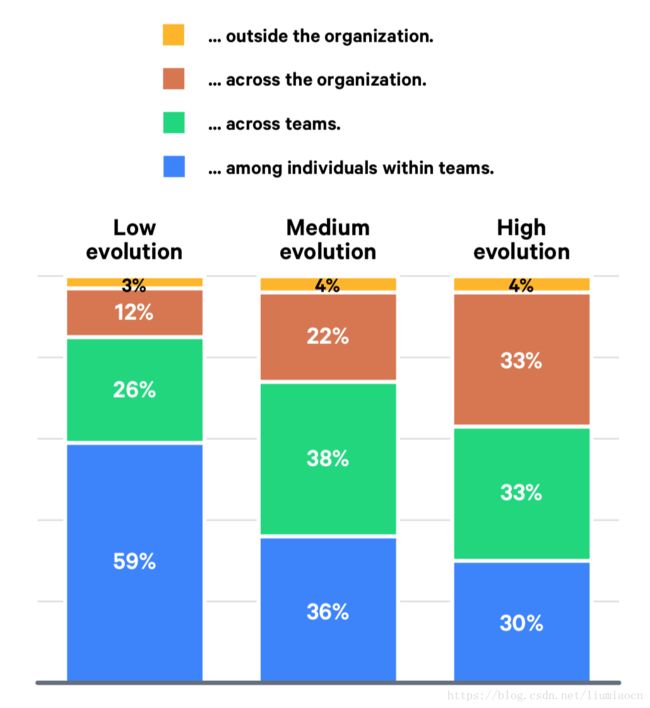
S:Sharing:分享
随着成熟度的提高,关于成功实践经验和模式的分享,在整个组织内部实施的比例越来越多,也体现了DevOps实践在组织内部不断复制和借鉴的过程。而对于组织外部的分享,目前各种成熟度都表现出的是比较冷淡,没有明显的利益推动,这样的结果并不意外。
不同角色的不同结论
在这次的报告列出了一个角度,就是项目的不同角色对同一问题的看法,整体来说管理层级别越高,对问题的看法愈加乐观。
比如对待在新的特性开发的时候保持较低的技术债务的这个问题的看法上,团队成员有33%的比例,也就是说只有1/3的人有信心能够平衡新的业务开发在一个比较低的技术债务基础上,而C级别的最高管理层对此项的看法接近底层人员的一倍,有2/3的最高层管理人员对此有信心(真不知道这个信心是哪里来的,开发的人自己都没有,大概体现了一种真正的信任)。
报告认为,这种认识的落差来源于信息的有意或者无意的过滤,所以增强沟通,提高自动化和指标展示,使得不同角色对相同问题有大体一致的看法这个也非常之重要。

Stage 0: 整体基础的五个实践
作为整体的基础,如下五个基础的实践被认为是非常重要的基石:
- 监控和警告是可以配置使用的
- 部署模式是可重用的
- 构建应用和服务的测试是可以重用的
- 工具链可用并且团队持续进行改进
- 配置使用配置管理工具进行管理
基础实践&分享
从某种角度来说,这些基础实践是跟CAMS模型中的S(分享)密切相关:
| 基础实践 | 说明 |
|---|---|
| 监控和警告是可以配置使用的 | 对系统和引用的运行状况进行监控和告警,使得所有人能对其有相同层次的认识本身就是一种重要的信息分享方式,有助于整个团队更好地进行改进。 |
| 部署模式是可重用的 | 成功经验的分享往往意味着不同团队之间对于这些模式会有一些共同的认可,而这些将会是后续改进的基石 |
| 工具链可用并且团队可以继续改进 | 这些改进会推动团队之间围绕在工具/流程/指标等进行进一步的改进,并对于优先度和计划进行更多的讨论 |
| 配置使用配置管理工具进行管理 | 配置管理工具将开发/信息安全/运维等团队凝聚在一起对于系统和应用的配置变化一同作出反映,最重要的是使得整个团队在业务层面上共享共同的目标和责任。 |
监控和警告是可以配置使用的:24x
在这一点的实践上,成熟度高的组织达到了47%的比例,对比与低的2%,达到了近24倍的差距。
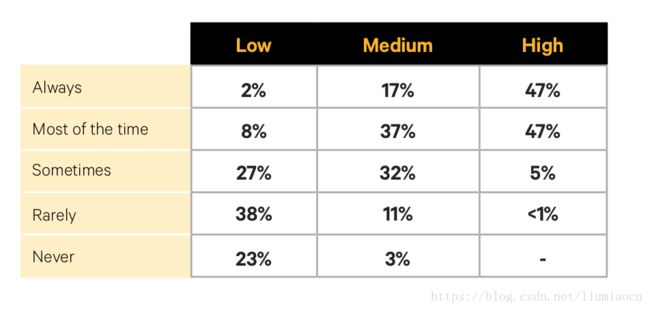
在具体实践的细节上,有很多方式比如:
- 开发者自己对自己的代码部署和运行负责
- 开发者和运维人员一起提供相关的非功能性要素保证部署和交付
- DevOps团队作为一个紧密结合的整体定义监控细节
- 由运维专家组成的团队监控开发人员所交付的应用
- …
部署模式是可重用的: 23x
可重用的部署模式对于打破开发和运维之间的那堵墙(wall of confusion)非常重要,High级别和Low级别之间有高达23倍的差距。
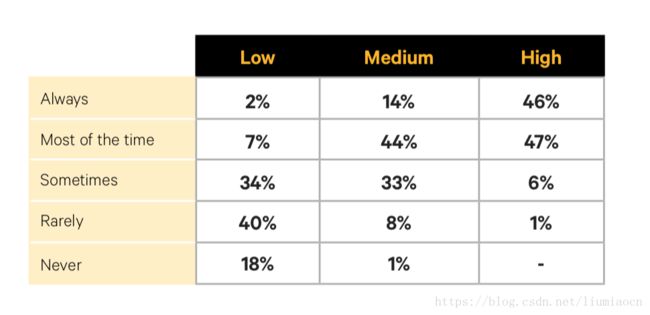
构建应用和服务的测试是可以重用的 :44x
同样测试的可重用方面也是有着很大差距的,最重要的是Low级别的基本没有相关的实践,所以有高达44倍的差距。

解读:不得不说这是一个去年没有确认的重要部分,持续测试是DevOps中的一个重要环节,但是目前整体的状况推广的并不是很好,占到整体大多数的Medium级别的组织只有10%左右的比例,Low级别更是几乎没有实践,这将是接下来一个重要的实践要点。
工具链可用并且团队持续进行改进:44x
保持工具链可用并且持续进行改进,此项的差距也达到了44倍。
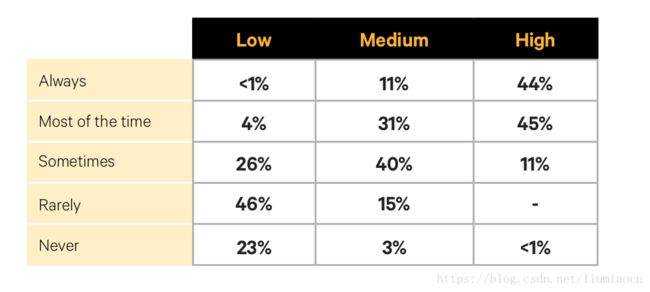
通过工具的使用,看起来似乎是自动化提高效率的一面,但实际影响更大的是通过工具的合理使用,使原本割裂开来的各个孤岛进行了协作和信息共享,这种改进更深层次的理解则是团队进一步融合的显现。
配置使用配置管理工具进行管理:
随着DevOps实践的深入,部署频度的加快增大了运维侧对于配置管理的自动化的压力和需求,生产环境的性能和可用性需求也浮出水面,同时需要考虑快速的频度下评审方式和数据提供的方式,一年一次部署的时候Audit的做法和一天十次部署的时候的做法自然不同,同时新的技术对于传统的Audit方式带来的挑战都需要进行考量。这些最终反映在实际数据上看到此项调查相关的差距达到了27倍。

总结:
作为五项基础的实践,在实施中如下三项应该作为重点内容:
- 监控和警告是可以配置使用的
- 部署模式是可重用的
- 配置使用配置管理工具进行管理
而在此基础之上,余下的两项建议推行,则是这份报告对于基础实践的五项所给予的结论
- 构建应用和服务的测试是可以重用的
- 工具链可用并且团队持续进行改进
Stage 1: 规范化技术栈
很多组织都使用了很多技术,而且引入了很多的依赖,使得复杂性大为增加,而这些往往会拖慢整体的步伐。在这个阶段,降低复杂性则是当务之急。
解读:
就像报告所指出的那样,很多人认为自动化应该是最初的切入点。而实际上如果事前的准备工作没有做好,直接切入进行自动化,很多时候这种急功近利的朴实的需求并不一定能够收到很好的效果。
在一个技术栈非常复杂的情况下,自动化本身就将会变成一个不可控的需求,而如果不对这种复杂性进行控制,后续的投入很有可能会大幅增加。所以规范化整体的技术栈更多的是为了简化,降低过多的依赖,所谓磨刀不误砍柴工。
我们做很多DevOps落地的项目中也是如此,虽然会讲自动化作为一个很重要的点进行推行,但是在此之前对整体的流程/可改善的环节/改善的计划和重点/技术架构进行讨论,目的就是为了明确和降低整体的复杂性,以期能够持续稳定的投入收到持续稳定的回报。
实践内容
此阶段主要从如下两点来进行推进:
- 应用开发团队使用版本管理
解读:
版本管理是整体实践的基础,这一点应该不会有所异议。在实际的项目中,目前的阶段没有使用版本管理的项目可能更为罕见。但是是否所需要进行管理的内容纳入了管理,管理是否规范,是否高效,这些问题实际上才是版本管理在实践中不断进行改善的细节。
- 团队在标准的操作系统上进行部署
解读:
应用和服务在复杂的操作系统中才得以运行这是非常普遍的一个现状,在报告中所举例的那样,可能有在Windows 2012/Windows 2012RT/Windows 2016上运行的不同应用,而这些应用一起提供最终的服务,简化这些能使得整体的复杂性大幅的降低。
在实际的项目中,往往比报告中所提到的例子更加复杂,你有可能还在使用一些大型机,使用已经不再更新版本了的Unix系统,使用Motif来画页面,使用CGI来写网页,因为大型的项目不是那么理想可以一步替换的。但是简化整体的技术栈确实是一个重要方向,哪怕技术本身不是一个问题,在DevOps Handbook 中就举过一些公司在此方面的实践,因为技术本身就非常复杂,每个人都很难在所有的方面做到全部精通,简化技术栈可以使得在整体之间的沟通更为的高效和快速。
关键因素
为了保证此阶段获得成功,有四项对于结果影响最为重要的关键因素如下所示:
- 构建标准的技术栈
- 应用配置纳入配置管理
- 在部署至生产环境之前测试基础框架变更
- 源码对其他团队可见
构建标准的技术栈
构建标准的技术栈非常重要,它是Stage 1的关键因素,同时是Stage 2中的实践内容,也是Stage 3的关键因素,可以看出这是一项需要持续实施的实践要素。标准化技术栈对简化依赖和降低复杂度有很好的效果,而在业务层面也会在诸如license的成本上有所降低。
解读:
对技术栈进行规范和标准化,从长远来看会收到很好的效果。但是对于拥有复杂度很好的老旧系统,如何进行实施才是关键所在,影响太大,改动成本过高往往是现实世界中的阻碍所在。构建标准化的技术栈,势在必行,但是如何推动,以什么样的规划进行才是更应该考虑的。
另外,构建规范的技术栈,不应该局限于某一个应用或者服务,应该着眼全局,从整体角度进行考虑,也是这份报告所给出的一个建议。
应用配置纳入配置管理
应用开发应该进行版本管理,这包括代码的版本管理以及应用配置信息的版本管理。
解读:
应用配置进行版本管理,可以从如下几个方面进行理解:
- 应用部署的环境不同并且复杂,导致应用配置可能会有所不同
- 不同的应用配置,相同的应用代码,代码和配置数据进行分离是一种常见的对应方式
- 应用配置不仅仅着眼于快速的部署和灵活应对各种环境,可回滚也是进行版本管理的一个主要着眼点
在部署至生产环境之前测试基础框架变更
这项实践内容在这个阶段和Stage 3均有出现,不同的是实施的程度有所不同。在此阶段对于测试基础框架变更所涉及到的内容仅仅为不需要手工的批准,主要目标在于团队的自制,获得权限和责任是这个阶段需要注意的。
这些实践往往都是贯穿于各个阶段的,不同的阶段所侧重的角度不同,这也是在实践的不断深入所应该考虑的问题。
源码对其他团队可见
源码对于其他团队可以见,可以使得不同团队更好的进行参考和借鉴,也是分享文化的一种具体体现,在这个阶段中这是一种将局部的成功经验进行复制扩展的有效方法。
Stage 2: 推进标准化&降低不一致性因素
标准化的推进是一个持续的过程,而那些不同的特性或者说不一致的因素往往会成为实践过程中的阻碍,而这些不一致的要素往往是由于多种原因导致的,比如:
- 新的技术不断实践,但是旧有的技术栈也不进行移除,导致很多非标准的不一致因素的存在
- 土生土长的架构没有考虑到行业共同的标准和规范,自成一派
- 企业合并与收购导致的不一致性
- …
实践内容
此阶段主要从如下两点来进行推进:
- 构建标准的技术栈
团队需要使用可重用的部署模式,标准的技术栈所解决的问题就是降低依赖行和复杂度。可以简单地使用诸如如下的问题进行自检:
- 是否所有的服务都是在相同的架构上进行构建?
- 是否这些服务使用相同的消息队列?
- 他们是否使用相同的组建和模式?
当你的答案中出现No的时候,这些非标准化的不一致性会给系统带来更高的复杂度和更多的维护成本负担。
解读:团队对技术栈进行标准化和简化意味着很多,而且能够带来很多收益比如:
- 更快的交付速度
- 降低安全脆弱性的简单的共通性问题
- 学习曲线更加平滑,维护和升级更加容易…
- 在标准的单一操作系统上进行部署
操作系统及其版本的不同往往对运行于其上的应用程序有较大的影响,这里的影响并不是业务层次上的影响,而是在NFR角度的考量,而当组织使用单一操作系统或者范围可控的操作系统级是,部署的效率更得到很好的提升。同时能够降低在系统安全补丁/调优/升级/故障排查等方面所消耗的时间。
整体来说,在操作系统的规范层面相关建议如下:
- 即使无法保证在单一操作系统上运行服务,减少到最低限度总是好的
- 在单一的操作系统上也尽可能地降低不一致性的存在
解读:
活用目前所拥有的技术栈是一个很好的建议。技术本身往往没有好坏之分,只有合适和不合适,即使是那些看起来很合适的技术,也需要考虑到引入之后带来的成本考量,比如根据数据库特性不同导入了MongoDB/Mysql/Oracle/Postgresql同时在一个系统之中明显不是一个好主意,这极大地增加了运维的复杂度,同时使得系统正常运行起来说需要的基础知识范围大幅度的扩宽,沟通的成本和时间也往往会大幅提升,而简化往往能够使得这些都不在是问题。
放弃的技术并不一定是不好的技术,规范和简化技术栈以提高效率是非常重要的一环。
关键因素
为了保证此阶段获得成功,对于结果影响最为重要的关键因素如下所示:
- 重用构建和部署应用和服务的模式
- 基于业务需求对应用进行架构重构
- 将系统配置纳入版本管理之中
重用构建和部署应用和服务的模式
在这个阶段的重用其实还是非常的简单的,而没有考虑到过过多复杂的因素,简单程度上的重用是这个阶段的。而关于详细的展开,在Stage 3中还会有进一步的陈述。
基于业务需求对应用进行架构重构
标注化技术栈带来的结果往往是需要对既有的应用进行重构,在这个过程中可能是使用开源的组件或者商业的产品来代替以往项目中愈加难以维护和更新的自由行开发的旧有组件。
解读:这是一个说起来更加容易的实践,目的是希望有更快的速度和更好的可维护性。技术债务需要不断偿还,而且好的状态需要不断的维护。
将系统配置纳入版本管理之中
在这个阶段中,对系统级别的配置管理进行版本管理会给基础框架的开发和维护提供一个非常良好的基础,这也是“基础框架即代码”的基础实践所要求的范畴。
系统配置纳入版本管理会带来很多好处,比如:
- 可以变更相关的详细信息,不同时间的变更和发起者等都能够被追踪
- 任何具有对版本控制系统具有权限的人员都能对变更进行确认
- 关键的备至管理文件能够得到备份,从而具有可回滚的基础
Stage 3: 扩展DevOps实践
在前面的两个Stage的基础之上,整体程度上技术栈的复杂度和不一致性得到了有效的降低,为这个阶段的DevOps实践提供了很好的前提条件。
随着各个团队合作的深入,聚焦于各个部分的改进使得团队开始在技术应用之外进行了更深入的协作,分享工具的改进,应用/服务/以及知识等等,这些推动了DevOps实践在组织中的扩展。
实践内容
此阶段主要从如下三点来进行推进:
- 团队成员工作无需团队外部的人工批准
解读:
这点主要的目的是为了赋能团队,降低组织官僚化的冗长流程对效率造成重大损害。在实际实施的过程中达到目的即可,流程的审批需要的时候,可以考虑责任下放,使得团队中的Leader有审批有权利和责任即可。
另外根据前几年的调查报告显示:这些外部的人工审批对于系统的安定性有着几乎可以忽略的影响,换句话说,额外的人工审批不会使系统更加安全,可能只会使审批者心理上更加放心而已。
- 重用构建和部署应用和服务的模式
解读:
相比较于前一个阶段的同样的实践,这里的要求就严格的多。简单来说,哪怕你只有两个软件项目要进行发布,需要使用相同的方式,而不论是发不到开发/测试/准生产还是生产环境。
在这个阶段很多具体的实践都会根据组织技术栈和流程进行标准化的重用,比如:
- 使用标准的方式去指定所要部署的对象环境
- 与CI的持续集成进行结合
- 部署的步骤可以进行标准化或者定制化
- 部署的方式可能是蓝绿或者其他方式
- 可以重用一条流水线对不同的应用进行发布
- …
- 在部署至生产环境之前测试基础框架变更
解读:
在这个阶段,对于基础框架并不需要集成到CI中进行全自动,而是要把重点放到对基础框架功能的验证上,而手工完全可以保持。
因为基础框架的变更范围非常广泛,对其进行自动化,引入infrastructure-as-code的方式进行管理也是需要成本的,而在很多时候,对绝大多数情况来说,这些并没有那么的频繁(当然对于那些云服务器的服务商来说完全不同了),所以结合手动作业,主要对基础框架的变更进行验证的方式是这个阶段推行的重要方式。
关键因素
为了保证此阶段获得成功,对于结果影响最为重要的关键因素如下所示:
- 团队成员可以进行变更对应而不会有过多的等待时间
- 服务变更可以在业务时间内对应
- 进行事后检查和评审并分享相关结果
- 团队在标准的技术栈上进行构建
- 团队进行持续集成实践
- 基础框架团队使用版本管理
团队成员可以进行变更对应而不会有过多的等待时间
解读:
虽然这期所给出的CAMS模型里面没有L(Lean),但是这就是典型的精益实践之一,消除等待的浪费。是对整体过程的一个简化,当然实际实施时需要考虑到很多因素,比如:
- 在整体不会出现很多问题的情况下进行实践,比如部署成功率已经很高,很少出现问题和意外
- 消除等待时间应该与实际业务需求相结合,确认是必要还是可选
服务变更可以在业务时间内对应
解读:
在业务时间进行服务变更,保证服务不中断,建议从如下角度进行实践:
- 流程:等待时间大幅度降低情况下进行
- 架构:考虑蓝绿部署等方式降低影响
- 时机:定义出业务时间结合业务影响度,即使是24小时无终止的服务,业务影响度也会有所不同,选择影响程度最低的时间段
- 预演:在准生产环境上进行验证能力
- 回滚:事前准备回滚方案并进行验证
- 试点:先选择影响度小的项目作为试点
进行事后检查和评审并分享相关结果
解读:
时候检查仍然是CAMS中S(分享)相关的具体实践,实施时需要注意如下几个要点:
- 免责方式进行:去年的gitlab给出了一个很好的案例,看一下他们把关键数据丢失的员工的进行了什么样的惩罚就知道了。
其实也很好理解,出现的问题往往只是冰山的一角,对于可能出现的问题,大部分人在自身安全不能得到保证的情况下,免责还是不免责可能就是出现问题有可能会藏起来不说还是说的区别,这是人的本性,无可厚非。
有些组织在构建企业文化时,一边拿着鞭子抽打,另一方面期待员工能够为公司殚精竭虑,所有问题都能畅所欲言,不太现实。- 相关干系人参与并将结果进行公示,一方面可以增进信任,公开比隐藏个能获取相关干系人的信任。另外一方面,对于其他没有直接关联的成员,这些公布的内容也是值得学习和借鉴的内容。
团队在标准的技术栈上进行构建
解读:
构建标准的技术栈,这个实践要点也是一个持续性的行为,在不同阶段都需要进行考虑,自然在扩展的阶段也不能避免。好不容易打下的基础,简化的技术栈,在扩展的时候重新变成复杂度和不一致性都很高的高技术负债的状况,就说明扩展的方式出现了问题。
团队进行持续集成实践
解读:
持续集成已经成为版本管理之后,最需要进行实践的内容之一。但是需要注意的是,持续集成本身也需要维护和优化,也是一个长期的过程。
基础框架团队使用版本管理
基础框架团队使用版本管理在这个阶段和后续的阶段都是非常重要的,将基础框架的变更和管理也纳入版本管理的范畴也会对整体实践的推进有非常正向的影响,详细会在后续阶段进行说明。
Stage 4: 自动化基础框架交付
自动化基础框架的交付并非是到了这个阶段才能去实施的阶段,在经过前面阶段的规范化/标准化/简化以及扩展之后,这个阶段可以进行更为全面的基础框架相关的自动化了。
实践内容
此阶段主要从如下四点来进行推进:
- 自动化系统配置
- 自动化设定
- 应用配置纳入版本管理之中
- 基础框架团队使用版本管理
自动化系统配置
解读:
自动化系统配置一般意味着系统的构建不是通过手工,而是通过得到版本管理的设定文件和脚本,整体通过一个自动化的框架(比如Puppet/Ansible,虽然报告中没有写出来,但是已经非常明显了,有整整一个Stage来进行自动化基础框架,而前面几个Stage都是用来铺垫和准备)
整体来说,系统配置自动化能带来很多收益,比如:
- 更加快速应对变更
- 更快的整体交付速度
- 环境一致性得到保证
…
另外,关于对那些系统配置项进行自动化,自然需要考虑到ROI,使用频度高的并且实现简单的自然应该有限考虑,同时也需要可简化或优化流程结合起来以达到更好的效果。
自动化设定
解读:
与自动化系统配置相结合,自动化设定实践能够使得项目成员通过自服务功能来对基础框架进行操控。当然,使用频度最高的项目应该是优先考虑的,同时自动化设定在后续阶段中也是重要的实践内容。
应用配置纳入版本管理之中
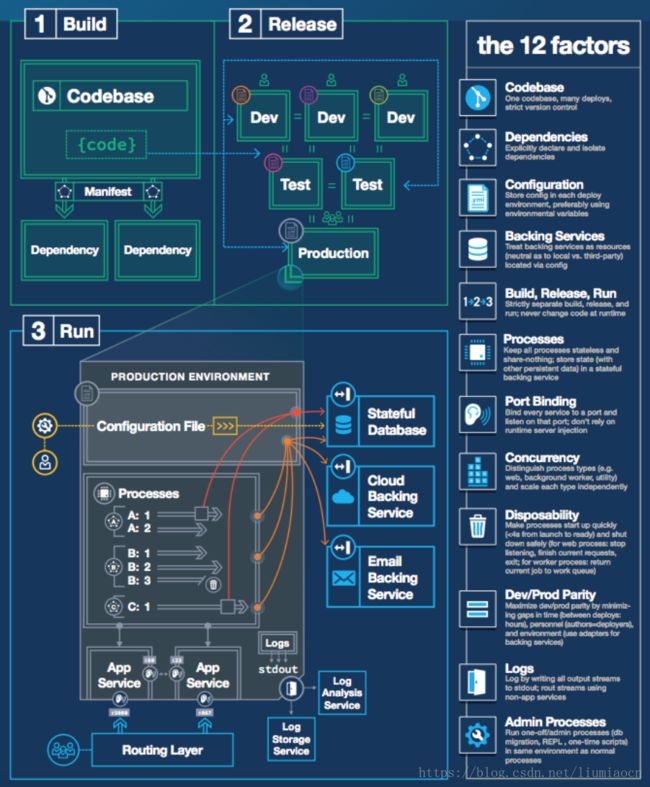
解读:
应用程序源码在版本管理控制之中,但是应用程序配置信息同样应该纳入管理,那些使用了诸如12-facotr的应用,相关的配置信息的管理也源码一样同等重要。
即使没有使用12-factor,应用配置信息需要进行规范化和标准化,至少避免以硬编码的方式存在与应用程序之中,这种最基本的程度是需要做到的。系统运维人员登录到生产环境之中,手工修改设定文件或者数据库然后重启系统等这种手法在目前的阶段已经不再是一个备选项了。应用程序的配置应该得到管理,能够进行审计,包含前因后果,像代码一样进行严格管理
基础框架团队使用版本管理
解读:
基础框架团队使用版本管理是对包含基础框架在内的整体进行持续交付的基础。纳入版本管理之后后很多的收益,比如
- 更加容易创建开发或者测试环境
- 更加容易重建测试环境用于问题定位
- 缩短生产环境的故障恢复时间
- 更好地提供Audit所需数据和功能
…
关键因素
为了保证此阶段获得成功,对于结果影响最为重要的关键因素如下所示:
- 自动化安全策略配置
- 资源可以通过自服务获取
自动化安全策略配置
解读
除了普通的安全策略之外,组织往往需要强制性的满足一些外部的Audit规范诸如:
- Sarbanes-Oxley
- Payment Card Industry Standards (PCI)
- NIST
- General Data Protection Guidelines (GDPR)
- …
在实际推行的时候需要注意:
- 这些安全策略在团队层面意味着什么和如何遵从和检测
- 逐步推行循序渐进地完成安全策略检测的方式,可以是从最简单的一个脚本开始和完善
- 可以通过一些外部的工具对安全性和脆弱性进行扫描和分析
脆弱性实例:OWASP Top 10(2017)
- A1:2017-Injection
- A2:2017-Broken Authentication
- A3:2017-Sensitive Data Exposure
- A4:2017-XML External Entities (XXE)
- A5:2017-Broken Access Control
- A6:2017-Security Misconfiguration
- A7:2017-Cross-Site Scripting (XSS)
- A8:2017-Insecure Deserialization
- A9:2017-Using Components with Known Vulnerabilities
- A10:2017-Insufficient Logging&Monitoring
资源可以通过自服务获取
通过自服务获取资源能更好地提高效率,在后续的Stage中对相关的实践有更多的阐述。
Stage 5: 提供自服务能力
这个阶段的实践需要对IT能力进行重新的理解,需要不同团队(开发/运维/信息安全/ITSM和其他职能团队)共同协作来提供IT能力,整体的方式是将这种能力进行服务化以提供给业务层面,而不再是将IT作为一个对应工单的成本中心。
而通过这个阶段的实践,一些新的收获将会显现,比如:
- 应用架构开始在标准化的技术栈上慢慢融入Cloud/容器化/微服务等
- 安全策略的自动化从满足团队需要到变成组织级别可衡量的基线
- …
实践内容
此阶段主要从如下四点来进行推进:
- 自动进行事件响应
- 资源可以通过自服务获取
- 根据业务需要进行应用架构重构
- 安全团队融入技术设计和部署阶段
自动进行事件响应
解读:
事件的响应是人工还是自动在效率上差别很大,比如以ALIEN VAULT所举的例子进行说明:
- 对于可疑的IP的自动检测和封IP自动响应:有些组织需要先发起工单,进行审批与核准,然后才能进行事件响应,缺乏实效性
- 被感染了病毒的服务器的隔离:如果无法自动隔离,则很容易丧失最佳对应时间点
风险:
自动事件响应是好的,但是误响应的风险也是巨大的,比如可疑IP的自动检测,将新的大客户的IP自动封起来之后影响也是巨大的,平衡与折衷,循序渐进的推进都是这个过程中需要考虑的。
资源可以通过自服务获取
自服务带来的好处不言而喻,就像这份报告所提到的那样:
This is exactly what the data shows successful teams do.
Comparing our Low and High evolutionary cohorts, we see this exact shift from a high proportion of self-service systems for internal team usage towards multiple teams collaborating to deliver systems that will be broadly consumed across the organization.
自然,从数据上来看,对于自服务(self-service)的践行,Low/Medium/High分别的比例是3%/5%/8%,确实是非常明显地是随着成熟度的增高自服务程度在逐渐提升的一个结果
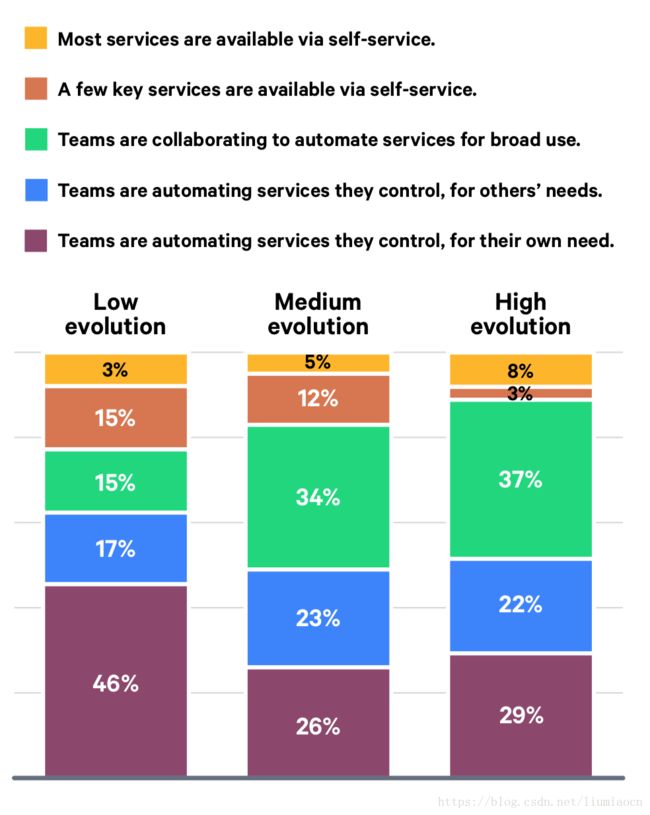
注:看原文的话,会发现这份数据在Page 28已经使用了,但是跟这里的区别是Low evolution的比例是8%,如果是这个数据的话,这里的结论就很难找到数据的支撑。而且简单地进行分析,本身Low evolution的数据相比与其他两种,总和就不是100%,这个数据本身就存在问题,所以个人认为这个值的真实数据应该是7%。
但是无论什么样的数据,是什么就应该展现什么,准备发信问一下DORA。但是无论是什么样的数据,自服务的趋势是整体的方向这个应该是没有问题的,只是可能在大家都在起步的阶段的时候,数据不足以对其提供支持而已,可以从后续的报告中进行进一步的确认,而不是修改数据去契合结论。
根据业务需要进行应用架构重构
解读:
在Stage 2的时候此项实践同样出现,不同的是前面的阶段中架构的重构所引起的原因是因为标准化技术栈所引起的,往往是很大程度的对应,比如数据库种类的变化以及操作系统有多个变成了一个。
而这个阶段则是整体的改善,比如12-factor规范的实践等等,不同的阶段考量的因素不同,架构的改善应该贯穿与整个过程。
安全团队融入技术设计和部署阶段
早在2016年的报告中,就发现了高效的组织在安全相关的问题上所花的时间只有抵消组织的50%,这是因为安全相关的因素已经在交付的过程中被考虑进去了。整体来说,安全需要更早的被引入到交付的流程之中,包括:
- 在保证不会拖慢开发进度的情况之下,对所有主要特性都进行安全评审的流程
- 集成信息安全机制到每日的工作之中
- 将对安全需求的检证作为自动测试过程的一部分
- …
组织不同角色对自动化的认识一致性较高
不同的角色在DevOps实践中对同一问题的看法往往存在gap,而对于自动化相关的看法,调查的结果显示,分歧非常之小。

关键因素
为了保证此阶段获得成功,对于结果影响最为重要的关键因素如下所示:
- 安全策略配置是自动化的
- 应用开发者自己部署应用到测试环境
- 项目的成功指标是可视化的
- 自动化设定
安全策略配置是自动化的
解读:
安全策略的自动化自所以在比较靠后的Stage进行,主要的原因是这是一块难啃的骨头,相比较于安全问题一旦出现所需要的成本,这一切都是值得。在如下的文章中对可以看到安全问题所需要付出的成本:(https://blog.csdn.net/liumiaocn/article/details/77646024)
应用开发者自己部署应用到测试环境
开发团队成员能够按需将开发的应用部署到测试环境时,由于无需进行环境的等待等,应用交付的流程将会更快,而运维团队由于从大量的环境配置的重复性劳动中解放出来了,则可将精力投入到系统性能的优化上。但是前提是需要这种自服务的功能的提供不是从天而降的,需要投入一定的人力和成本的。
项目的成功指标是可视化的
关心什么,你就会得到什么。KPI指标的可视化非常重要,但是更加重要的是明确地定义以及对参与者可以随时获得信息分享的途径。
总结
今年的报告给出的最为重要的内容就是5-stages的推进方式,对于那些初步进行了一些实践但是仍然觉得在扩展方面有问题的组织来说应该有一定的借鉴意义。
附录1: 2017年DevOps报告解读
https://blog.csdn.net/liumiaocn/article/details/72899528
附录2:Take Away:5 Stages具体内容
| 阶段 | 实践内容 | 关键因素 |
|---|---|---|
| Stage 0 | 监控和警告是可以配置使用的(重点) | - |
| 部署模式是可重用的(重点) | - | |
| 构建应用和服务的测试是可以重用的 | - | |
| 工具链可用并且团队持续进行改进 | - | |
| 配置使用配置管理工具进行管理(重点) | - | |
| Stage 1 | 应用开发团队使用版本管理(重点) | 构建标准的技术栈 |
| 团队在标准的操作系统上进行部署(重点) | 应用配置纳入配置管理 | |
| 在部署至生产环境之前测试基础框架变更 | ||
| 源码对其他团队可见 | ||
| Stage 2 | 构建标准的技术栈(重点) | 重用构建和部署应用和服务的模式 |
| 在标准的单一操作系统上进行部署(重点) | 基于业务需求对应用进行架构重构 | |
| 将系统配置纳入版本管理之中 | ||
| Stage 3 | 团队成员工作无需团队外部的手工批准(重点) | 团队成员可以进行变更对应而不会有过多的等待时间 |
| 重用构建和部署应用和服务的模式(重点) | 服务变更可以在业务时间内对应 | |
| 在部署至生产环境之前测试基础框架变更 | 进行事后检查和评审并分享相关结果 | |
| 团队在一套标准的技术栈上进行构建 | ||
| 团队进行持续集成实践 | ||
| 基础框架团队使用版本管理 | ||
| Stage 4 | 自动化系统配置 | 自动化安全策略配置 |
| 自动化设定 | 资源可以通过自服务获取 | |
| 应用配置纳入版本管理之中 | ||
| 基础框架团队使用版本管理 | ||
| Stage 5 | 自动进行事件响应 | 安全策略配置是自动化的 |
| 资源可以通过自服务获取 | 应用开发者自己部署应用到测试环境 | |
| 根据业务需要进行应用架构重构 | 项目的成功指标是可视化的 | |
| 安全团队融入技术设计和部署阶段 | 自动化设定 |
参考内容
https://puppet.com/company/press-room/releases/puppet-delivers-2018-state-devops-report-reveals-stages-devops
https://www.alienvault.com/blogs/security-essentials/automated-incident-response-in-action-7-killer-use-cases