日均7亿交易量,如何设计高可用的MySQL架构?
点击上方SQL数据库开发,关注获取SQL视频教程
SQL专栏
SQL数据库基础知识汇总
SQL数据库高级知识汇总
本文作者将给大家分享工行基于 MySQL 构建分布式架构的转型之路!

将围绕如下几个方面展开:
工行 IT 架构转型中传统 OLTP 数据库架构面临的挑战和诉求。
构建基于 MySQL 分布式企业级解决方案实践历程,包括技术选择、高可用设计、两地三中心容灾、运维管理、资源使用效率等方面的思考和实践经验。
工行转型的成效以及对后续工作的一些思考。
数据库转型背景
传统 IT 架构的挑战
大型国有银行,整体核心的系统都是大机+DB2 这样的传统架构;针对现在的互联网金融业务快速扩张的需求,传统的架构面临着比较大的挑战。

主要集中在如下四个方面:
处理能力:因为工行这么大的体量,导致整体系统的规模比较庞大,这种垂直的单一的扩展模式,不具备横向处理能力,处理能力受到限制。
运行的风险:随着很多的业务从网点变成线上,新的业务提出了更高的业务连续性保障,包括 7×24 小时,传统的架构从架构设计上无法做到这样的支持。
快速交付:传统的开发模式应用内部模块、应用与应用之间的耦合度非常高,使得软件的开发和产品交付周期比较长。
成本控制:大型主机运营成本非常贵,买个机器帮你搞两下就几千万上亿的支出,再加上商业产品的 License 比较高,银行议价能力又比较低。
在这种情况下进行 IT 架构转型,整体的诉求是优化应用架构、数据架构、技术架构,建立灵活开放、高效协同、安全稳定的 IT 架构体系,强化对业务快速创新发展的科技支撑。
转型的核心诉求和策略
在上面的转型大背景下,数据作为核心,我们展开了对开放平台的数据库的架构转型,同时提出了几个核心的策略:

首先,在业务支撑方面,做到高并发、可扩展、支持海量数据存储及访问,以及两地三中心高可用容灾。工行在国有大型银行里应该是比较领先的实现了两地三中心容灾体系。
其次,降低使用成本,基于通用的廉价的硬件基础设施,希望提升自己的管理控制能力,进行行内适配和定制。降低对商业产品依赖,提升议价能力。
还有就是运维能力,提升数据库的运维自动化智能化,更加开放的技术体系以利于自主掌控。
主要采取三方面策略:
集中式向分布式的转型。
专有向通用的转型,也就是去 IOE。
限制商业产品,拥抱开源。
转型的发展经历
三年转型之路
整个转型历程,大概从 2015 年开始 IT 架构转型,但真正有进展应该是从 2016 年初到 2017 年这个时间。我们整个的发展历程大概可以分三个阶段:
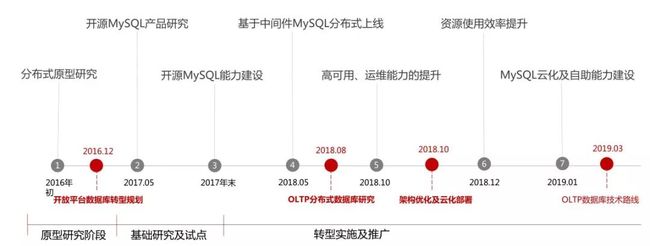
第一阶段:原型的研发和探索
2016 年初到 2017 年的过程,当时结合人民银行对于个人账户的管理要求,实行一类二类三类账户。
结合这样的工作要求,把个人账户从主机下移到开放平台,基于开放平台的高性价比、可扩展进行了很多的探索,很多的技术验证。
当验证了技术可行性之后,我们提出了一个开放平台数据库转型的规划,这个规划对于我们行内后面几年的工作,对于数据库的方案选型是非常大的影响。
这个规划确定我们行里要建设基于开源的 MySQL OLTP 数据库解决方案。
第二阶段:基础研究和试点
2017 年整年,我们基于开源的 MySQL 数据库进行产品的研究和能力的建设,以及初步能力的建设,包括基础研究和应用的试点。
在此期间,前面提到的原型也是在 2017 年 5 月份上线的,在生产线上跑起来了,把整个技术体系都进行了验证。
第三阶段:转型实施及推广
2018 年开始大规模的实施和推广,在这个过程中基于开源的 MySQL 数据库,我们逐步建立起了一个企业级的数据库服务能力,包括引入了分布式的中间件,在高可用、运维能力的提升,资源使用率的提升,MySQL 的云化及自主服务的建设等等。
在整个过程中,同步对 OLTP 的分布式数据库进行了研究,也对后面的工作指导提供了依据。
选型阶段
①方案选型调研

在选型阶段,我们基于业务场景进行了大量的方案调研。坦率的说,工行软件开发中心在 2014-2016 年持续关注着行业内数据库的发展和生态的发展,在这个过程中我们对很多的产品进行了一些研究和摸底的测试。
NewSQL 数据库方案,是很多的互联网企业或者一些小型企业有所使用的,但是我行在选择技术的时候是非常谨慎的,以及要做非常多验证,在当时并不符合我们系统设计的考量点。
基于开源的分布式 OLTP 方案,业界有很多丰富的案例,而且在互联网企业里面得到了很好的实践,在业界资源案例都很丰富,是同时能应对我行的高并发、弹性扩展需求的。
所以我们最终确定从分布式架构的角度去解决整个架构的挑战,不仅仅只从单一的数据库的层面解决这个问题。
②分布式技术栈
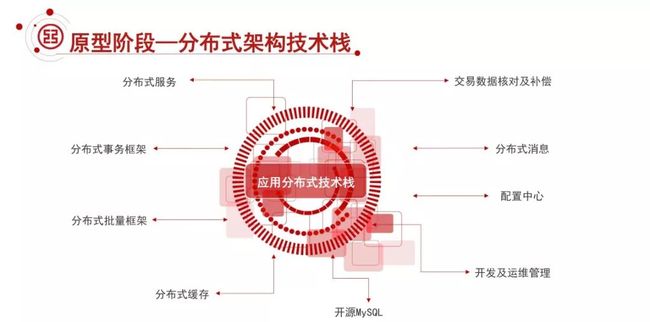
基于这样的一个原型探索,我们构建了一系列的分布式架构技术栈,包括分布式服务、分布式事务框架、分布式批量框架、分布式缓存、交易数据核对及补偿、分布式消息、配置中心、开发及运维管理。
这里简单说一下:
分布式服务改造,针对我们传统架构耦合比较紧密的特点,通过服务化的改造,降低耦合度。降低耦合度的同时,还可以尽最大可能的避免分布式事务的产生。
分布式事务的框架,我们结合两阶段提交和分布式的消息,支持强一致性和最终一致性多种模式的支持,通过分布式事务框架解决分布式事务的问题。
分布式批量框架,在大规模的数据结点上进行批量操作的一个整体的解决方案。
业务层面,在交易或者应用级层面进行数据核对及补偿,有些场景就是在传统的 OLTP 的情况下,也会对应用上下游进行核对和补偿。
分布式消息平台,实现这样一个应用级的数据交互。
同时我们也进行了运维的规划和总设计。这里引入了开源的 MySQL 数据库来解决数据最终落地的问题。
③MySQL 高可用方案
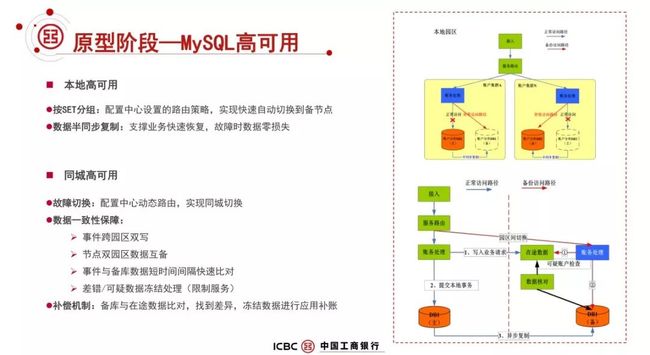
在原型阶段,当时主流是 MySQL 5.6、5.7 才刚出来;对于高可用要求,行里的应用是要做到同城切换,上海两个园区要做到 RPO 是 0,RTO 非常小,同时异地北京有一个灾备中心,就是两地三中心。
我们的 AB 类重点应用必须具备这样的同城两个园区同时对外服务的能力。
在原型设计阶段,我们基于 MySQL 的半同步复制,来做这样的一个切换,实现 RPO=0,解决主库故障自动切换到备库,同城为了保障 RPO=0,在原型阶段进行了应用的双写,来进行数据的核对和补充。
这里顺便提一下,MySQL 5.7 相对 5.6 的改进非常大的,这是一款真正可以适合金融行业的数据库产品,它在数据回放方面,在性能方面都有比较大的改进和提升。
实施推广阶段
①基础研究和应用试点
第二个阶段是开源 MySQL 基础研究和应用试点,就是 2017 年。对于这些元素研究以后,在行里要发布第一个产品;把这个产品推上线,要做很多的工作:
产品的基础研究,我需要验证功能、新特性和配置基线,数据备份恢复,还要结合它的特性来设计应用的高可用,提供开发的技术规范。
我们的角色既要考虑到运维,也要考虑到上游应用,做好上面的衔接、对接和支持。
包括应用的开发规范,它的性能能力评估,上线需要多少设备,容量是多大,还要对 Oracle 等老架构给予指引和帮助,代码写不好还要弄个检查工具等等。
运维方面就是要提供各种安装部署的便利化,然后行内和行内的监控系统进行对接,制定很多的指标和参数,如何和行里进行对接,然后新问题的分析等等一系列的问题。
在这个阶段我们实现了同城 RPO=0,RTO=分钟级目标,RPO 为 0 的切换,问题可监控,实现了人工或自动的一键式切换。

这个阶段,行里决策了之后,我们 2017 年一下子上了 21 个应用,211 个节点。
②分布式中间件应用
2018 年开始转型和实施,并且大量应用上线;之前的基于应用级的分布式解决方案,遇到了一些新的限制。
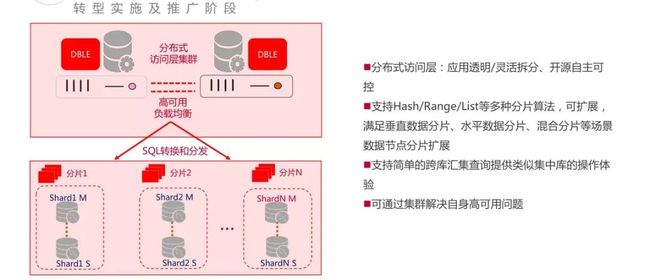
部分应用不想设计的过分复杂,这个时候引入了开源分布式中间件 DBLE,引入它的目的就是为了简化开发的工作量。
通过引入这样一个 DBLE 来支持垂直数据分片、水平数据分片、混合分片等场景的支持,还支持简单的跨库汇集查询提供类似集中库的操作体验,这个时候开发场景就简化了,给了应用更多的选择,简化了应用开发的复杂度。
③运维架构流程完善
解决了应用开发的复杂度,运维怎么办?高可用怎么办?
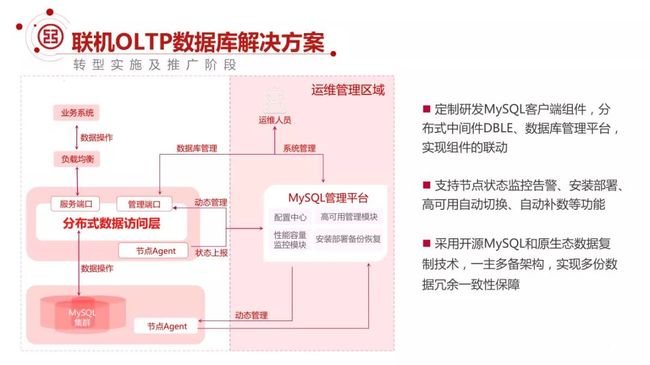
我们结合 DBLE 和运维管理平台,实现整平台联动,支持从高可用、监控告警、安装部署、自动化补数等等一系列的解决方案。
④运维管理能力沉淀
这时进行运维能力的提升,也迫在眉睫;因为分布式随着实施的运维节点的增加,运维是一个很大的挑战,那么多的节点,安装、监控、报警、故障、人工处理等非常麻烦。
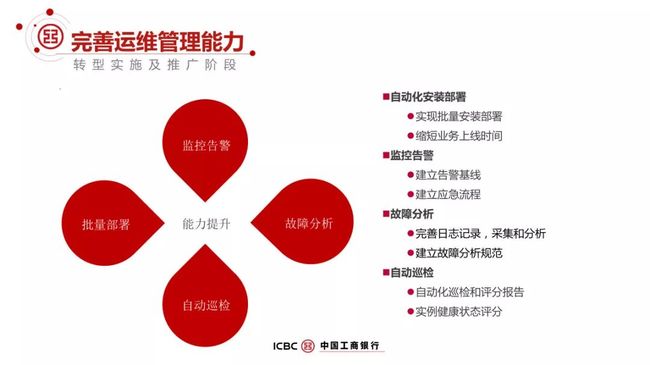
我们的做法:
先提供一个自动化的安装部署,实现批量安装部署,批量串行还不行,时间太长了,要并行,并行太高了,网络的流量会受到比较大的影响,所以这个方面有很多的场景都需要打磨。
监控告警,监控告警里有事件等级,分各种等级,这些需要灵活的定制,建立基线告警,建立应急流程。
故障的分析,完善日志记录、采集和分析,建立故障分析规范。
自动巡检,自动化的巡检和评分报告,对实例状态进行健康评分。
⑤统一运维平台建立
我们通过这样一个统一的运维管理平台,把所有的节点都纳入进来了,实现一键式的安装、版本的升级、参数的配置。并且实现了多种高可用策略配置,包括自动、人工一键式切换。
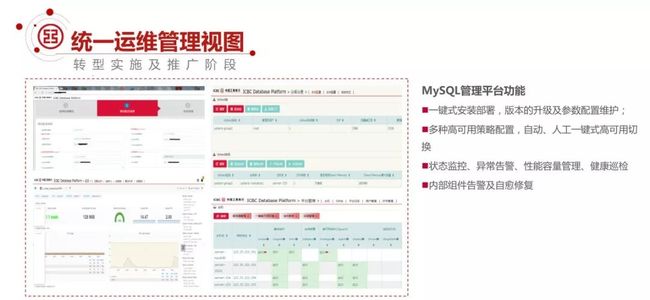
谈到为什么要有自动化和人工的两种切换方式?一种新的事务上线之前,都会面临一些挑战和怀疑的,都是一个循序渐进的过程,特别是是在金融行业,我们实现了多种高可用策略的灵活配置。
⑥故障自动切换上线
我们建立了一个自动化、高可用的决策系统。大家知道人工决策到自动切换,虽然只是迈出一步,但是面临着很大的挑战:
包括决策的因素和决策的模型,最难的是还要应对不同应用场景的需求,有的时候说 RPO 优先,有的 RTO 优先。
有的要求三分钟搞定,有的说 10 秒钟 5 秒钟我都难受。你要有这样的模型适配这样的场景,这是非常大的挑战。
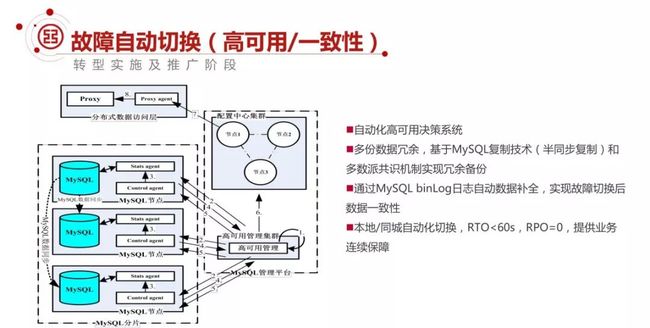
在整体上面基于 MySQL 的复制技术,我们有半同步复制和多数派共识机制实现冗余备份。基于 MySQL binlog 日志实现自动数据补全,保障数据的一致性。
实践中的改善优化
①高可用方案改进
同时实施过程中我们走的比较快了,一年几百个节点,几十个应用。
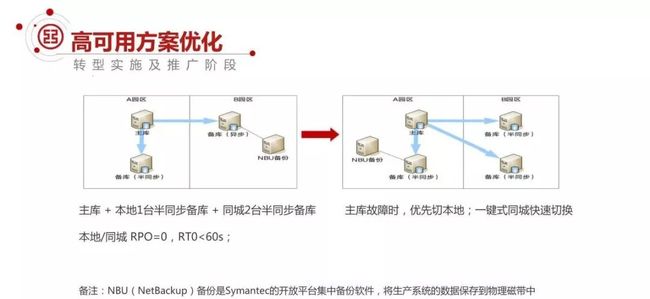
在这个过程中,我们又对高可用方案进行了持续的优化,同时学习和借鉴互联网包括分布式数据库的一些方案。
我们把 1 主 2 备,本地 1 备和同城 1 备,扩展成 1 主 3 备,通过半同步的机制,做到真正的在系统级去保证 RPO=0。
②异地灾备和存储优化
异地灾备和存储方面,当初跑的太快,方方面面有些没有考虑那么完备。
刚才说了,我们在上海到北京有一个灾备。数据灾备刚开始,方案采用磁盘复制实现灾备,这个也是要支出软件费用,也比较耗钱。
还有就是冷备,无法热切换,RTO 至少半个小时以上。这个方面我们改进了,用了 MySQL 异步复制。
另外存储方面沿用的集中存储,一套集中存储上面同时支撑六七十上百个 MySQL 实例,IO 的性能非常容易成为瓶颈。
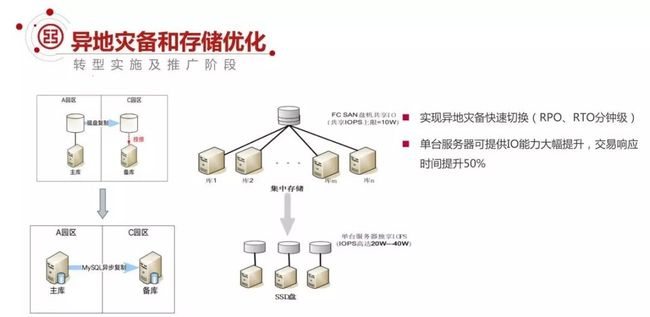
在应对一些高并发场景的时候,因为 IO 性能不足,这方面我们就改进了,直接引入了 SSD 盘,基本上把 MySQL、IO 的瓶颈给解决了。
在现在的场景下,IO 一般不会成为瓶颈了。同时通过 SSD 的引入,交易的响应时间在相同条件下降低 50%。
③MySQL 容器化探索
MySQL 的上容器,首先说一下为什么要搞这个事情?
因为工行一两年转型过来,大规模的上 MySQL 数据库,节点非常多,机房和设备成为一个瓶颈,再这么玩儿下去机房容量不足了。这个时候需要提升资源的使用效率。
在很多应用里,因为它的超前规划,一般为了稳定运行,基本上都提出资源申请的时候,都是物理机,为了满足后面几年的业务需求,大规模的申请物理机,但当前应用的交易量又不是那么大,浪费是比较严重的。
这个时候我们提升资源的使用成为紧迫的问题。这个过程中为什么选择 MySQL 的容器呢?
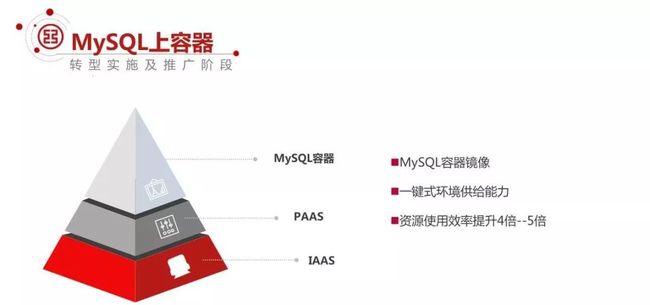
几点考量:
行业化里的商业软件都是用的 VMware。
VMware 在 IO 方面,在系统性能方面都有比较大的损耗。
行里在 Iaas、Paas 方面建设好多年了,我们无状态的应用服务其实全部上了 Paas,全部上了容器,在这方面有一些技术的积累,结合行内对于云战略的规划,所以我们 MySQL 选择了上容器。
上容器解决的两个技术要点:
容器对数据的持久化支持。
对服务的暴露。
整体我们 MySQL 上容器,在现阶段仅仅是把它作为一个虚拟化的技术,它的整个高可用,包括它的整个监控、整个的安装部署都是通过我们之前提到的管理平台来实施的。
通过上容器,我们提供了一键式的环境供给能力,通过上容器把 Iaas、Paas 全部打通过了,能很快的把基础环境,按照行内的标准和模式很快的供应出来。
资源的使用效率提升了 4 到 5 倍。截止当前我们行内在 MySQL 上容器这块,应该是有 400 多个节点。
转型成效
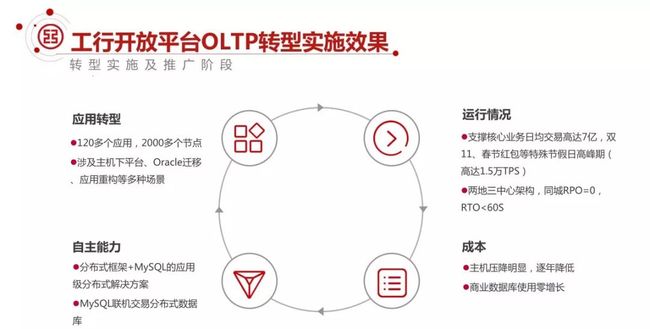
①转型实施成果
我们实施了至少 120 多个应用,2000 多个服务器节点,超过 2500 个 MySQL 节点。
实施的应用涉及很多核心业务,包括个人账户、对公账户、基金以及很多 A 类、B 类的应用,大多都是主机上迁移过来的。其中还有少量应用是从 Oracle 迁移过来的,应用层也因此需要重构。
我们通过 MySQL 支持的核心交易达到日均 7 亿的交易量,经历过双十一、2018 年的双十一和春节的高峰期的 1.5 万的 TPS。
我们的架构现在通过横向扩展可以达到几万的 TPS。我们就是基于 3 万 TPS 的设计目标进行了架构设计,理论上通过扩展设备还可以无限地增加。如果通过主机想达成这个目标,那么挑战就会比较大。
另外通过良好的架构设计,我们可以满足两地三中心的架构要求,做到同城 RPO=0,RTO<60s。
现在很多的“多活”,包括互联网公司的架构,都是最多能够做到分片双活的维度,两边同时提供对外服务,但是同时对于某一分片数据的写入只能是单活的。
通过架构转型,我们在自主能力方面,初步建立了企业级的基于 MySQL 的分布式解决的自主能力:
首先是分布式框架+MySQL 的应用级分布式解决方案,这个方案承载了我们很多的从主机下来的应用。
其次是基于分布式中间件构成了所谓联机交易的数据库,这样能应对一些不是很复杂的场景,通过良好设计的分库分表方案就可以满足需求。
在成本方面,我们在主机上的成本投入明显下降。这几年我们的业务交易量每年以 20% 的速度增长,但是主机并没有进行扩容,投入还逐年降低。
商业产品的数据库的使用不仅实现零增长,还有所下降。从整个经费上来说,应该有比较大的降幅。
②典型案例 1:个人账户平台
介绍一下作为我们架构设计原型的个人账户平台,这是从主机上迁移下来的应用。
当时的交易要求高并发、低延时,日均交易量 3 亿,这个应用的内部交易延时不能超过 100ms,要求 7×24 小时的联机服务。
我们实施的架构是高可用架构同城分片双活。实施效果是日均交易量超 1 亿以上,本地高可用做到自动化切换,RPO=0,RTO<30S。同城高可用切换也是 60 秒内切换。
同时结合 MySQL 的管理平台,对自动化的切换能力进行了包装,同城的切换会面临着比较大的挑战:
本地的高可用切换是基于 SIP 的,它是对应用透明的。
同城切换是对应用不透明的。
于是我们设计了从服务器到数据库的整体切换流程,数据库要和应用服务器进行一些联动来实现同城自动化切换。
③典型案例 2:信息辅助服务
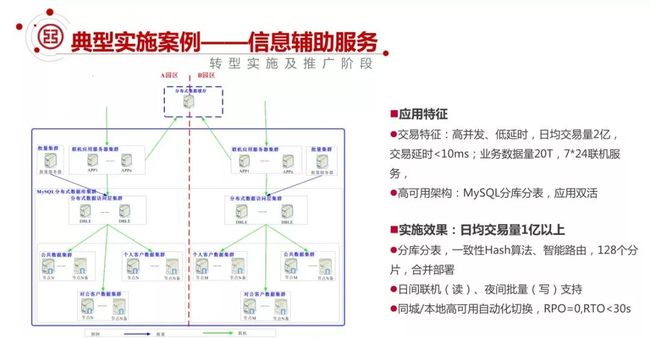
另外一个案例就是通过 DBLE 实现分布式数据库。
这是第一个数据量比较大的系统,它要求高并发、低延时,日均交易量 2 亿,交易响应延时要求 10ms 以内,当时的业务数据量大概 20T 左右,还要求 7×24 小时的联机服务。
我们的架构是通过分布式中间件做 MySQL 的分库分表,一共 128 个分片。我们对分片进行了合并部署,这看上去像是过度分片,但是资源使用上就收益很大。
DBLE 中间件在日间进行联机服务,夜间进行批量变更,把主机上的一些数据同步下来。
这个架构整体上实现了本地和同城完全自动化切换,RPO=0,RTO<30S。
后期工作思路

结合我们行的 OLTP 的数据转型,后续几个方向是我们行要做大量工作的。
云化服务
现在 SaaS 云也好还是什么云也好,工行对于一些新的技术是保持跟踪,当它有普遍性,很好的落地以后,可以使我们不会比互联网慢一拍,在技术经过更多的打磨,我们认为它成熟以后再引用。
在云化服务方面,我们这边结合像 MySQL,像其它的一些数据库,我们要加强云化服务的建设。
通过我们刚才的一些平台也好,一些自主服务的建设也好,加强后面云化服务能力的建设。
数据统一交换
我们刚才提到消息平台,它实现了应用和应用之间的数据交换,这个是业务级的。
那么我们现在除了这样的一个业务级的,我们还需要一个系统级的来实现不同数据库和数据库系统级的准实时的数据的交换和复制。
只有把数据流转,把它活动起来了,那么数据才能更好的发挥它的业务价值,我们行目前也在建设这一块的数据复制平台。
Oracle 的转型
工行应该把 Oracle 这样的一些特性用的非常极致;基本上都是存储过程,当开发框架一确定,大家存储过程都是用笔勾几下或者拉几下就可以产生很多的流程,但它同时和具体的数据库绑定了,后面的维护、扩展都面临比较大的挑战。
比如说如何用相对可以接受,相对较低的代价进行 Oracle 的转型,因为整个数据库、整个应用重构开发的代价还是非常非常大的,这个也是我们的后面需要探索和思考的事情。
对分布式的数据库
对分布式数据库来说,我们从 2015 年以来,就一直跟踪着业界很多的分布式数据库的产品。
我们应用级的分布式解决方案也好,包括我们的分布式访问层的解决方案也好,可能有些场景还真的是无法应对的。
我们也在探索,随着生态圈和国内技术的逐步成熟,我们也在考虑分布式数据库技术的探索和引入的事情,同时从另外一个角度来说,在现在这种国际的关系形势下,需要做一些技术的储备,有自主支撑下来的能力。
作者:林承军
出处:转载自微信公众号大数据技术标准推进委员会,本文根据 DTCC 数据库大会分享内容整理而成。
如果你想支持我们的公众号,可购买下方推荐的商品,我将获得10%的佣金。
公众号内回复1,拉你进微信交流群
长按下方二维码加入我们的SQL训练营
点击"阅读原文",了解SQL训练营