Flink消费Rabbit数据,写入HDFS - 使用 BucketingSink
一、应用场景:
Flink 消费 Kafka 数据进行实时处理,并将结果写入 HDFS。
二、Bucketing File Sink
由于流数据本身是无界的,所以,流数据将数据写入到分桶(bucket)中。默认使用基于系统时间(yyyy-MM-dd--HH,0时区)的分桶策略。在分桶中,又根据滚动策略,将输出拆分为 part 文件。
1、Flink 提供了两个分桶策略,分桶策略实现了
org.apache.flink.streaming.connectors.fs.bucketing.Bucketer 接口:
- BasePathBucketer,不分桶,所有文件写到根目录;
- DateTimeBucketer,基于系统时间(yyyy-MM-dd--HH)分桶。
除此之外,还可以实现Bucketer接口,自定义分桶策略。
2、Flink 提供了两种writer方式,它们实现了
org.apache.flink.streaming.connectors.fs.Writer 接口:
- StringWriter 是系统默认的写入方式,调用toString()方法,同时换行写入;
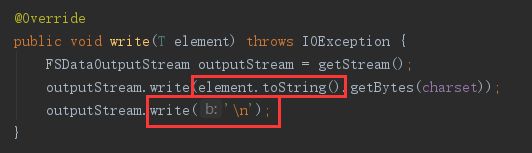
- SequenceFileWriter 是Hadoop序列文件写入方式,可配置压缩。
除此之外,还可以实现Writer接口,自定义Writer方式。
具体说明见Flink官网
三、编码。
1、pom添加依赖。
org.apache.flink
flink-connector-filesystem_${scala.binary.version}
${flink.version}
org.apache.flink
flink-connector-kafka_${scala.binary.version}
${flink.version}
2、添加Source。
// 源数据
val kafkaProps = new Properties()
kafkaProps.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, Constant.DATA_KAFKA_BROKER)
kafkaProps.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest")
kafkaProps.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "user-login-info")
val consumer010 = new FlinkKafkaConsumer010[String](Constant.DATA_KAFKA_TOPIC, new SimpleStringSchema(), kafkaProps)
val transaction = env.addSource(consumer010)
val sourceStream = transaction.map(s => MemberLogInfo.buildMemberLogInfo(s))
.uid("source-map")
.filter(s => s != null)
.uid("source-filter")3、添加Sink。
val sink = new BucketingSink[MemberLogInfo](Constant.HDFS_SAVE_PATH_LOGIN)
.setBucketer(new MemberBucket()) // 自定义桶名称
.setWriter(new MemberWriter()) // 自定义输出
.setBatchSize(120*1024*1024) // 设置每个文件的最大大小 ,默认是384M。这里设置为120M
.setBatchRolloverInterval(Long.MaxValue) // 滚动写入新文件的时间,默认无限大
.setInactiveBucketCheckInterval(60*1000) // 1分钟检查一次不写入的文件
.setInactiveBucketThreshold(5*60*1000) // 5min不写入,就滚动写入新的文件
.setPartSuffix(".log") // 文件后缀
loginStream.addSink(sink)4、自定义分桶名称
public class MemberBucket implements Bucketer {
private static final long serialVersionUID = 10000L;
@Override
public Path getBucketPath(Clock clock, Path path, MemberLogInfo memberLogInfo) {
String day = DateUtil.format(new Date(memberLogInfo.getTimestamp()), "yyyy-MM-dd");
return new Path(path + "/" + day);
}
} 5、自定义writer写入
@Override
public void write(MemberLogInfo element) throws IOException {
// 输出字符串内容
String content = element.getIggid() + "\t" + element.getType() + "\t" + element.getGameId() + "\t" +
element.getUrlDeviceName() + "\t" + element.getDeviceId() + "\t" + element.getTimestamp() + "\t" +
element.getSourceIp() + "\t" + element.getEventType();
byte[] s = content.getBytes(charsetName);
FSDataOutputStream outputStream = this.getStream();
outputStream.write(s);
outputStream.write(10); // 换行符
}四、总结。
截止目前,Flink 的 Bucketing File Sink 仍存在不少问题,如:
- 不支持写入到 Hive。
- 写入HDFS时,会产生大量的小文件。
- 当程序突然停止时,文件仍处于inprogress状态。
默认桶下的文件名是 part-{parallel-task}-{count}。当程序重启时,从上次编号值加1继续开始。前提是程序是正常停止- 除了使用BucketingSink外,还可以使用StreamingFileSink,见 这里。
- BucketingSink API 参见 这里。
- 间隔检查时间, 是以运行时间开始算的。如10:00:10运行程序,inactiveBucketThreshold=300s,inactiveBucketCheckInterval=60s,最后一次写入时间是10:05:30。则在10:11:10时,将inprocess文件转为正式文件。
如果有写的不对的地方,欢迎大家指正。有什么疑问,欢迎加QQ群:176098255
作者:magic_kid_2010,如果觉得笔者的博客对您有所帮助,欢迎【犒赏】