【论文笔记】Improving Machine Reading Comprehension with General Reading Strategies(2019,NAACL)
这篇论文在GPT模型的基础上,根据人类认知科学,提出了对非抽取式阅读理解任务的三个优化策略,分别被作者称为前后阅读(BACK AND FORTH READING,BF),高亮阅读(HIGHLIGHT, HL),自我评价(SELF-ASSESSMENT,SA),实际上分别对应输入策略,附加信息,数据增强的策略,对如何进行阅读理解的优化有启发作用。
1.介绍
作者认为,相对于抽取式阅读理解问题,非抽取式的任务由于其不限定于用原文回答,大部分问题不在原文出现,因此需要多样的阅读技巧才能回答,比抽取式的简单匹配更能体现阅读能力。

上图展示了几个非抽取式数据集的统计信息和非抽取问题的比例。
作者认为,预训练模型的提升要求的代价很大,从计算力方面和语料方面皆是如此。作者认为在fine-tuning阶段的训练策略也可以很大提升性能。
实际上,就是压榨模型的能力。当然,作者提出的策略也很有启发意义。
作者研究了人类认知学的几篇论文
Measuring esl students’ awareness of reading strategies
Assessing students’ metacognitive awareness of reading strategies.
iSTART: Interactive strategy training for active reading and thinking
提出了三个在实验中证明有效提升效果的策略:
-
前后阅读(BACK AND FORTH READING,BF):为了找到答案,常常反复按不同顺序进行阅读,在模型中,作者用颠倒问题、答案、文章的输入顺序来模拟这一点。
-
高亮阅读(HIGHLIGHT, HL):阅读时,高亮有用的信息常常有利于记忆,在模型中作者通过将文章的词嵌入附加问题、答案相关信息来模拟这一点。
-
自我评价(SELF-ASSESSMENT,SA)阅读时,人类通常会通过对自己提问题来确定自己对文章的理解。作者通过从文章中生成一些问题进行反复训练来模拟这点。
实际上SA策略只是通过数据增强来进行训练,而没有在实际预测时进行这一操作,从这一点说,这一策略并不能被称为“自我评价”,只是作者往概念上凑的。
2. 问题定义
作者简单地将阅读理解问题(主要是针对现有数据集)分为了两类:抽取式和非抽取式,抽取式是从文章中摘取一段作为回答,这点没有什么争议,但在本文中作者认为非抽取式都可以转化为多项选择,即我们平时英语考试的阅读理解问题,代表性的数据集是MCTest和RACE。
文章中,对这类问题的定义为,给定一个文章 d d d,一个问题 q q q,目标是从答案集合 { o 1 , o 2 , . . . , o n } \{o_1,o_2,...,o_n\} {o1,o2,...,on} 中选择出一个正确答案。
特别的,对于文中用的GPT模型,每次输入是 一组 ( d , q , o i ) (d,q,o_i) (d,q,oi),并在对所有 o i o_i oi计算出结果后使用softmax得到分类结果。
3. 方法和模型
作者使用了GPT作为基线模型,总体的模型架构如下图所示:

将在下文对上图进行解释。
3.1 Back and Forth Reading (BF)
如上文描述,GPT的单次输入可以描述为:[dq$o],其中,“[”、“]”分别表示开始符,“$"表示结束符。
作者应用这一策略的方式是,将它们的顺序变为: [o$qd],但其中token的顺序不变。单独训练一个模型,之后将这两个模型进行集成。集成的方式作者没有说,但可以尝试用boost,决策树之类的吧。
3.2 Highlighting (HL)
作者使用为文章的词嵌入附加问题、答案信息的方式实现“高亮”机制。
实现的方法比较有意思,首先,定义一个词性 (part of speech, POS) 标签集合:例如{名词,动词,数字,舶来词,等等}。
对于每一次前馈的 ( d , q , o i ) (d,q,o_i) (d,q,oi), 作者对 d d d中的每个token, d j d_j dj进行处理:
d j i = { d j + l + , P O S ( d j ) ∈ T 且 d j ∈ q 或 o i d j + l − , 其 他 d^i_j=\begin{cases}d_j + l^+ & ,POS(d_j)\in T 且d_j\in q 或o_i\\d_j + l^- & ,其他 \end{cases} dji={dj+l+dj+l−,POS(dj)∈T且dj∈q或oi,其他
其中 l + l^+ l+ 和 l − l^- l− 是可训练的向量,随机初始化。
区别于之前手工特征中为 d j d_j dj附加一位来标注是否出现的做法,作者加了一步判断词性,以此去除停用词等的影响。并且,使用可训练向量而不是标志位,更有利于模型的判断,是一个很好的做法。
3.3 Self-Assessment (SA)
作者提出了一种数据增强的方法:
首先选取一段终端任务(这里作者指RACE数据集)中的一篇文章,进行不超过 n q n_q nq次以下操作:
- 随机选取不超过 n s n_s ns个句子,并将它们组合。
- 随机从这些句子中选取不超过 n c n_c nc个片段,每个片段不超过 n t n_t nt个词(token)。将这些片段组合起来,作为正确答案,并从选取的句子中删除这些片段,将这些句子的拼接作为问题。
- 随机从文章中选取几个片段,替换正确答案中的一个或多个片段。
其中几个超参数用于控制数量和问题难度。
这样就生成了一些新的问题。
4. 实验
作者整体训练时,首先对RACE数据集运用SA策略,选取 n q = 10 , n s = 3 , n c = 4 , n t = 4 n_q=10,n_s=3,n_c=4,n_t=4 nq=10,ns=3,nc=4,nt=4,得到了119k个新的数据。首先用这些生成的数据训练一个epoch,然后在RACE数据集上训练5个epoch,之后,在具体的下游任务(指具体要测试的数据集)训练最多10个epoch。
在HL中的T定义为{NN, NNP, NNPS, NNS,VB, VBD, VBG, VBN, VBP, VBZ, JJ, JJR, JJS,RB, RBR, RBS, CD, FW}。
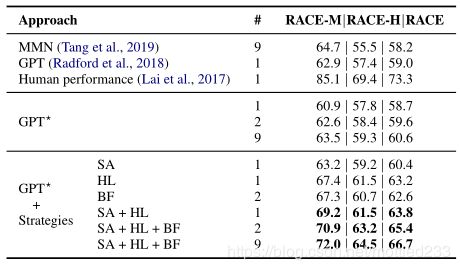
作者在RACE数据集上的结果以及消融分析如上图,其中RACE-M和RACE-H分别代表初中和高中级别的问题(RACE数据来自于中国英语考试)。
5. 分析
作者将RACE中的问题大致分为五类:details 事实细节,inference 推理,main 文章主题,attitude作者态度, vocabulary 词汇知识。
并得到下图分析:

可以看出,采用SA和HL对所有问题都有了一定提升,而BF对于主旨问题有更好的表现。
作者分析了一些错误样例,发现82%需要至少一个外部知识,而19.7%需要指代解析知识。
作者也尝试了一些其他的认知学的策略,例如总结(即附加抽取摘要信息),发现并没有提升。
对于BF策略,作者也尝试了其他的顺序,也都有少量提升。
对于HL策略,作者尝试加入指代信息,也没有得到很多提升
作者尝试使用Wiki进行SA操作,也稍微提高了一些,但比RACE少提升一个百分点。
我个人猜想,HL加入指代没有提升是由于作者简单地向量相加,这样才能不该变GPT的结构,而这并不适合添加指代信息。
作者使用了一些策略将其他数据集形式转变为问题定义中的形式,这里不细表。都取得了比基线更好的效果。