深度好文:最详细的卷积神经网络入门教程
卷积神经网络
简介
卷积网络 (convolutional network)(LeCun, 1989),也叫做卷积神经网络 (convolutional neural network, CNN),是一种专门用来处理具有类似网格结构的数据的神经网络。卷积神经网络主要包括:输入层(Input layer)、卷积层(convolution layer)、激活层(activation layer)、池化层(poling layer)、全连接层(full-connected layer)、输出层(output layer)。
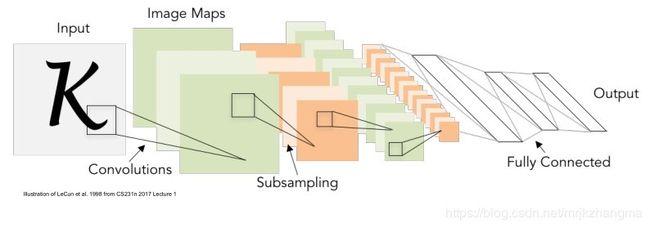
本篇博文我们主要描述卷积神经网络中卷积层和池化层的工作原理,并解释填充、步幅、输入通道和输出通道的含义和卷积过程中的的参数计算公式。
卷积层
卷积层的组成:
一个卷积层的配置通常由以下四个参数确定。
- 滤波器(filter)个数。卷积层中的权值通常会被称为滤波器(filter)或卷积核。使用一个滤波器对输入进行卷积会得到一个二维的特征图(feature map)。使用多个滤波器同时对输入进行卷积,便可以得到多个特征图。
- 感受野(receptive field) F,即滤波器空间局部连接大小,比如3 * 3,5 * 5,7 * 7。
- 零填补(zero-padding) P。随着卷积的进行,图像大小将缩小,图像边缘的信息将逐渐丢失。因此,在卷积前,我们在图像上下左右填补一些0,使得我们可以控制输出特征图的大小。
- 步长(stride) S。滤波器在输入每移动S个位置计算一个输出神经元。
卷积的特点:
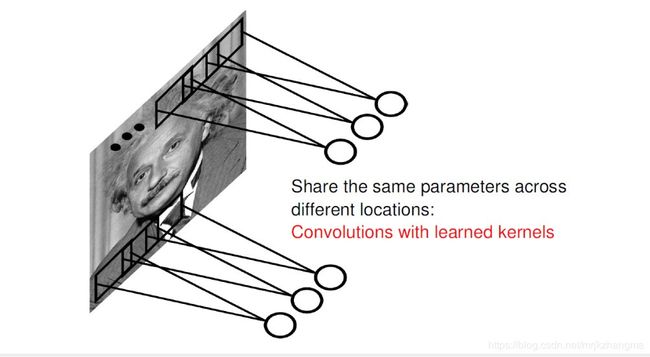
卷积具有局部连接、参数共享这两大特征。
-
局部连接便是指每个输出通过权值(weight)和所有输入相连。在卷积层中,每个输出神经元在通道方向保持全连接,而在空间方向上只和一小部分输入神经元相连。
-
参数共享(parameter sharing)是指在一个模型的多个函数中使用相同的参数。
如果一组权值可以在图像中某个区域提取出有效的表示,那么它们也能在图像的另外区域中提取出有效的表示。也就是说,如果一个模式(pattern)出现在图像中的某个区域,那么它们也可以出现在图像中的其他任何区域。因此,卷积层不同空间位置的神经元共享权值,用于发现图像中不同空间位置的模式。共享参数是深度学习一个重要的思想,其在减少网络参数的同时仍然能保持很高的网络容量(capacity)。卷积层在空间方向共享参数,而循环神经网络(recurrent neural networks)在时间方向共享参数。
卷积过程实质上就是卷积核中的所有权重与其在输入图像上对应元素数值之和。
卷积过程实例展示:
-
首先我们介绍一下最常见的二维卷积层。它有高和宽两个空间维度,常用来处理图像数据。
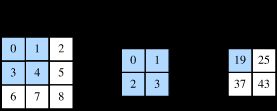
在二维卷积层中,一个二维输入数组和一个二维核(kernel)数组通过互相关运算输出一个二维数组。 我们用一个具体例子来解释二维互相关运算的含义。如图1所示,输入是一个高和宽均为3的二维数组。我们将该数组的形状记为 3×3 或(3,3)。核数组的高和宽分别为2。该数组在卷积计算中又称卷积核或过滤器(filter)。卷积核窗口(又称卷积窗口)的形状取决于卷积核的高和宽,即 2×2 。图1中的阴影部分为第一个输出元素及其计算所使用的输入和核数组元素: 0×0+1×1+3×2+4×3=19 。
- 对于多通道数据输入和多通道数据输出时:
相对于简单的二维卷积,此时增加了通道维的信息,为了与下文中的卷积计算公式保持一致,我们记为D1。
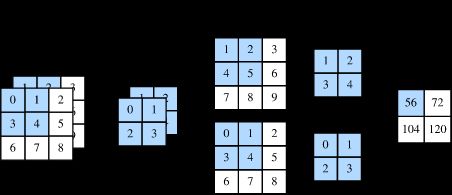
图2展示了含2个输入通道的二维互相关计算的例子。在每个通道上,二维输入数组与二维核数组做互相关运算,再按通道相加即得到输出。图2中阴影部分为第一个输出元素及其计算所使用的输入和核数组元素: (1×1+2×2+4×3+5×4)+(0×0+1×1+3×2+4×3)=56 。
对于多通道输入和经过多个卷积核操作之后,输出特征图的过程如下所示:

卷积中的填充与步幅
假设输入形状是 nh×nw ,卷积核窗口形状是 kh×kw ,那么输出形状将会是(nh−kh+1)×(nw−kw+1).
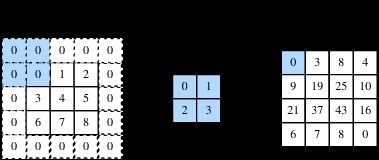
- 填充(padding) 是指在输入高和宽的两侧填充元素(通常是0元素)。图3里我们在原输入高和宽的两侧分别添加了值为0的元素,使得输入高和宽从3变成了5,并导致输出高和宽由2增加到4。图3中的阴影部分为第一个输出元素及其计算所使用的输入和核数组元素: 0×0+0×1+0×2+0×3=0 。
一般来说,如果在高的两侧一共填充 ph行,在宽的两侧一共填充 pw 列,那么输出形状将会是
(nh−kh+ph+1)×(nw−kw+pw+1).
也就是说,输出的高和宽会分别增加 ph 和 pw 。
在很多情况下,我们会设置 ph=kh−1 和 pw=kw−1 来使输入和输出具有相同的高和宽。这样会方便在构造网络时推测每个层的输出形状。假设这里 kh 是奇数,我们会在高的两侧分别填充 ph/2 行。如果 kh 是偶数,一种可能是在输入的顶端一侧填充 ⌈ph/2⌉ 行,而在底端一侧填充 ⌊ph/2⌋ 行。在宽的两侧填充同理。
卷积神经网络经常使用奇数高和宽的卷积核,如1、3、5和7,所以两端上的填充个数相等。对任意的二维数组X,设它的第i行第j列的元素为X[i,j]。当两端上的填充个数相等,并使输入和输出具有相同的高和宽时,我们就知道输出Y[i,j]是由输入以X[i,j]为中心的窗口同卷积核进行互相关计算得到的。
步幅(stride):卷积窗口从输入数组的最左上方开始,按从左往右、从上往下的顺序,依次在输入数组上滑动。我们将每次滑动的行数和列数称为步幅(stride)。
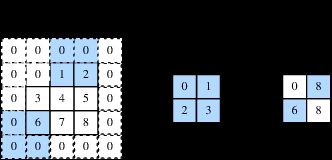
图4展示了在高上步幅为3、在宽上步幅为2的二维互相关运算。可以看到,输出第一列第二个元素时,卷积窗口向下滑动了3行,而在输出第一行第二个元素时卷积窗口向右滑动了2列。当卷积窗口在输入上再向右滑动2列时,由于输入元素无法填满窗口,无结果输出。图4中的阴影部分为输出元素及其计算所使用的输入和核数组元素: 0×0+0×1+1×2+2×3=8 、 0×0+6×1+0×2+0×3=6 。
一般来说,当高上步幅为 sh ,宽上步幅为 sw 时,输出形状为⌊(nh−kh+ph+sh)/sh⌋×⌊(nw−kw+pw+sw)/sw⌋.
如果设置 ph=kh−1 和 pw=kw−1 ,那么输出形状将简化为 ⌊(nh+sh−1)/sh⌋×⌊(nw+sw−1)/sw⌋ 。更进一步,如果输入的高和宽能分别被高和宽上的步幅整除,那么输出形状将是 (nh/sh)×(nw/sw) 。
卷积中的计算公式
卷积过程中多通道输入与输出的大小关系
其中W1代表输入图片宽度,H1代表输入图片高度,D1代表输入通道维数,K代表滤波器的个数,F代表感受野的大小(滤波器的大小,这里默认滤波器的高和宽都是一样的),S代表步幅,P代表填充,W2代表输出图片宽度,H2代表输出图片高度,D2代表输出通道维数·

池化层
池化层的提出主要是为了缓解卷积层对位置的过度敏感性。池化层中的池化函数通过使用某一位置的相邻输出的总体统计特征来代替网络在该位置的输出。
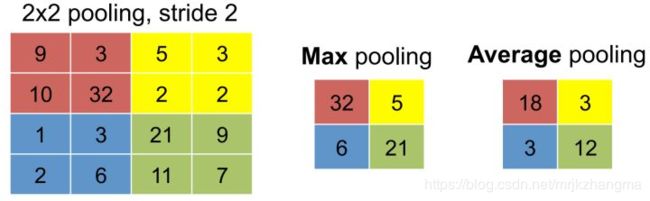
根据特征图上的局部统计信息进行下采样,在保留有用信息的同时减少特征图的大小。和卷积层不同的是,汇合层不包含需要学习的参数。即在池化层中参数不发生变化。最大池化(max pooling)函数给出相邻矩形区域内的最大值作为输出,平均池化(average pooling)函数给出相邻矩形区域内的均值作为输出。
池化层主要有以下三点作用:
- 增加特征平移不变性。汇合可以提高网络对微小位移的容忍能力。
- 减小特征图大小。汇合层对空间局部区域进行下采样,使下一层需要的参数量和计算量减少,并降低过拟合风险。
- 最大汇合可以带来非线性。这是目前最大汇合更常用的原因之一。
池化层中的填充和步幅机制与卷积层一致,值得注意的是:在处理多通道输入数据时,池化层对每个输入通道分别池化,而不是像卷积层那样将各通道的输入按通道相加。这意味着池化层的输出通道数与输入通道数相等。
池化层中的计算公式
池化过程中多通道输入与输出的大小关系
其中W1代表输入图片宽度,H1代表输入图片高度,D1代表输入通道维数,F代表感受野的大小(池化滤波器的大小,这里默认滤波器的高和宽都是一样的),S代表步幅,W2代表输出图片宽度,H2代表输出图片高度,D2代表输出通道维数·

参考链接
- http://zh.d2l.ai/chapter_convolutional-neural-networks
- https://zhuanlan.zhihu.com/p/31727402
- 卷积神经网络中特征图的可视化
更多优质原创文章,请关注我们的公众号:深度学习技术前沿