结合Java详谈字符编码和字符集
字符编码和字符集是两个基础性的概念,很多开发人员对其都并不陌生,但是很少有人能将其讲得很准确。当应用出现乱码时,如何分析和定位原因,很多人仍是一头雾水。这篇文章,将从字符编码和字符集的相关概念开始讲解,然后结合Java进行实例分析。
字符编码和字符集的概念
字符集(character set)是一个系统支持的所有抽象字符的集合。字符(character)就是各种文字和符号,包括国家文字、标点符号、图形符号、数字等。
如果仅仅是抽象的字符集,其实是顾名思义的,但是我们常说的字符集,其实是指编码字符集(coded character set),比如: Unicode、ASCII、GB2312、GBK等等。什么是编码字符集呢?编码字符集是指,这个字符集里的每一个字符,都对应到唯一的一个代码值,这些代码值叫做代码点(code point),可以看做是这个字符在编码字符集里的序号,字符在给定的编码方式下的二进制比特序列称为代码单元(code unit)。在Unicode字符集中,字母A对应的数值是十六进制下的0041,书写时前面加U+,所以Unicode里A的代码点是U+0041。
常见的编码字符集有:
- Unicode:也叫统一字符集,它包含了几乎世界上所有的已经发现且需要使用的字符(如中文、日文、英文、德文等)。
- ASCII:早期的计算机系统只能处理英文,所以ASCII也就成为了计算机的缺省字符集,包含了英文所需要的所有字符。
- GB2312:中文字符集,包含ASCII字符集。ASCII部分用单字节表示,剩余部分用双字节表示。
- GBK:GB2312的扩展,完整包含了GB2312的所有内容。
- GB18030:GBK字符集的超集,常叫大汉字字符集,也叫CJK(Chinese,Japanese,Korea)字符集,包含了中、日、韩三国语言中的所有字符。
字符编码(character encoding),是编码字符集的字符和实际的存储值之间的转换关系。常见的编码方式有:UTF-8(Unicode字符集的编码方式)、UTF-16(Unicode字符集的编码方式)、UTF-32(Unicode字符集的编码方式)、ASCII(ASCII字符集的编码方式)等。
Java的字符编码和字符集
Java中char类型是16位无符号基本数据类型,用来存储Unicode字符。字符数据类型的范围为0到65535,可以存储65536个不同的Unicode字符,这在起初Unicode字符集不是很大的时候,是没问题的。然而随着Unicode字符集的增长,已经超过65536个了,根据Unicode标准,现在Unicode代码点的合法范围是U+0000到U+10FFFF,U+0000到U+FFFF称为Basic Multilingual Plane(BMP),代码点大于U+FFFF的字符称为增补字符。
Java如何解决这个问题的呢?
Java的char类型使用UTF-16编码描述一个代码单元。在这种表现形式下,增补字符用一对代码单元编码,即2个char,其中,第一个值取值自\uD800-\uDBFF(高代理项范围),第二个值取值自\uDC00-\uDFFF(低代理项范围)。Unicode规定,U+D800到U+DFFF的值不对应于任何字符,为代理区。因此,UTF-16利用保留下来的0xD800-0xDFFF区段的码位来对增补字符进行编码。具体的UTF-16编码格式,可见这篇文章:https://www.cnblogs.com/dragon2012/p/5020259.html。
所以,char值表示BMP代码点,包括代理项代码点和UTF-16编码的代码单元。而int值可以表示所有的Unicode代码点,包括增补代码点。int的21个低位表示Unicode代码点,且11个高位必须为0。
Java字符串由char序列组成,上面我们已经说过,char数据类型是一个采用UTF-16编码表示Unicode代码点的代码单元,大多数的常用Unicode字符使用一个代码单元就可以表示,而增补字符需要一对代码单元表示。我们所熟知的String类型的length方法,它返回的是UTF-16编码表示的给定字符串的代码单元的数量,如果想要得到代码点的数量,可以调用codePointCount()方法,charAt方法返回位于指定位置的代码单元,codePointAt方法则返回指定位置的代码点。详细可见这篇文章:https://www.cnblogs.com/vinozly/p/5155304.html。
Java代码需要编译成class文件后由JVM运行,在class文件里,字符串使用UTF-8编码,保存于常量池中。
Java里涉及到字符集和字符编码的一些接口
实例化String对象的时候,可以指定字符集解码指定的字节数组。

string.getBytes(Charset)方法,使用给定的charset将此String编码到byte序列,并将结果存储到新的byte数组。不带参数的getBytes()方法则使用平台默认的字符集将字符串编码成byte序列,并将结果存储到新的byte数组。
java.nio.charset.Charset类,定义了用于创建解码器和编码器以及获取与charset关联的各种名称的方法。其使用方式可见这篇文章:https://blog.csdn.net/zmken497300/article/details/51914875。
InputStreamReader和OutputStreamWriter的构造函数,均可以指定该InputStreamReader/OutputStreamWriter使用的字符集。


常用的一个InputStreamReader和OutputStreamWriter就是FileReader和FileWriter,可以看到这两个类的构造函数,均没有表示Charset的入参,即FileReader和FileWriter,只能以平台默认的字符集来解码和编码。
这里提到了平台默认的字符集。什么是Java的默认字符集呢?在Java里,如果没有指定Charset的时候,比如new String(byte[] bytes),都会调用Charset.defaultCharset()的方法,该字符集默认跟操作系统字符集一致,也可以通过-Dfile.encoding=叉叉叉来手动设定,这个方法的具体实现如下:
public static Charset defaultCharset() {
if (defaultCharset == null) {
synchronized (Charset.class) {
java.security.PrivilegedAction pa =
new GetPropertyAction("file.encoding");
String csn = (String)AccessController.doPrivileged(pa);
Charset cs = lookup(csn);
if (cs != null)
defaultCharset = cs;
else
defaultCharset = forName("UTF-8");
}
}
return defaultCharset;
}可以看到,defaultCharset只能被赋值一次,所以System.setProperty("file.encoding", "叉叉叉")并不能改变默认编码。
来看一个具体的例子,在Windows下,打印System.getProperty("file.encoding")结果是GBK,现在创建一个文本文件,使用UTF-8编码,内容如下:
测试文本。接下来创建Java文件,代码如下:
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
public class EncodingTest {
public static void main(String[] args) {
// TODO Auto-generated method stub
try {
System.out.println(System.getProperty("file.encoding"));
FileReader fr = new FileReader(new File("test.txt"));
System.out.println((char) fr.read());
fr.close();
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}命令行执行javac EncodingTest.java和java EncodingTest,打印出如下结果:
GBK
娴通过java -Dfile.encoding=UTF-8 EncodingTest,我们就打印出了正确的文本:
UTF-8
测Java Web项目中的乱码问题,可参考:https://blog.csdn.net/u013905744/article/details/52456417。
指定编码下字符串所占的字节数
在业务开发中一个常见的需求是计算字符串在指定编码方式下所占用的字节数,如上面所看到的,Java中可以使用string.getBytes(charsetName).length来实现。在前面的知识的基础上,我们来看下面的几个例子:
import java.io.UnsupportedEncodingException;
public class MyTest {
public static void main(String[] args) throws UnsupportedEncodingException {
String str = "a";
System.out.println(str.getBytes("UTF-8").length);
String str2 = "中";
System.out.println(str2.getBytes("UTF-8").length);
}
}该例输出如下:
1
3
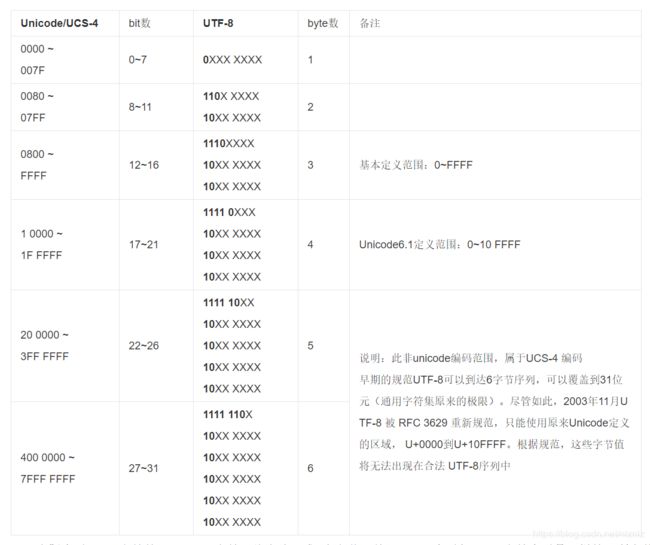
Process finished with exit code 0这个例子中分别输出了只包含一个英文字符的字符串和只包含一个汉字的字符串在UTF-8编码下所占的字节数,可以看到一个英文占用1个字节,一个汉字占用了3个字节。这个例子非常简单。具体的UTF-8编码的字节数和Unicode代码点的对应关系可见下表:
现在,我们把UTF-8编码换成UTF-16编码看看会输出什么:
import java.io.UnsupportedEncodingException;
public class MyTest {
public static void main(String[] args) throws UnsupportedEncodingException {
String str = "a";
System.out.println(str.getBytes("UTF-16").length);
String str2 = "中";
System.out.println(str2.getBytes("UTF-16").length);
}
}输出:
4
4
Process finished with exit code 0可以看到,输出都是4字节,这似乎和前面讲的不一致,因为不管是'a'还是'中',它们都是Unicode基本多语言平面内的字符,应该占用2字节才对,为什么会是4呢?
我们继续增加几个字符看下字节数:
import java.io.UnsupportedEncodingException;
public class MyTest {
public static void main(String[] args) throws UnsupportedEncodingException {
String str = "a";
System.out.println(str.getBytes("UTF-16").length);
str = "ab";
System.out.println(str.getBytes("UTF-16").length);
str = "abc";
System.out.println(str.getBytes("UTF-16").length);
String str2 = "中";
System.out.println(str2.getBytes("UTF-16").length);
str2 = "中华";
System.out.println(str2.getBytes("UTF-16").length);
str2 = "中华人";
System.out.println(str2.getBytes("UTF-16").length);
}
}输出:
4
6
8
4
6
8
Process finished with exit code 0可以看到,每加一个BMP平面内的字符,字符串占用的总字节数会多2,这说明确实每个BMP平面内的字符在UTF-16下占用了两个字节,但为什么一开始只有一个字符的时候,占用长度是4呢?我们打印几个只包含一个字符的字符串的UTF-16编码字节序列出来看看,看看里面除了字符本身的编码序列外还有些啥。
import java.io.UnsupportedEncodingException;
public class MyTest {
public static void main(String[] args) throws UnsupportedEncodingException {
String str = "a";
byte[] bytes = str.getBytes("UTF-16");
for(byte byt: bytes){
System.out.print(byt + " ");
}
System.out.println();
String str2 = "中";
byte[] bytes2 = str2.getBytes("UTF-16");
for(byte byt: bytes2){
System.out.print(byt + " ");
}
System.out.println();
String str3 = " ";
byte[] bytes3 = str3.getBytes("UTF-16");
for(byte byt: bytes3){
System.out.print(byt + " ");
}
System.out.println();
}
}输出如下:
-2 -1 0 97
-2 -1 78 45
-2 -1 0 32
Process finished with exit code 0这里分别输出了只包含一个英文字符'a'、一个汉字'中'、一个空格的字符串在UTF-16编码下的字节序列,显而易见的,它们的前两个字节是相同的----十六进制下的FEFF,第三个字节与第四个字节的组合正是字符本身在UTF-16下的代码单元。那这里为什么会冒出一个0xFEFF呢?原来这个0xFEFF叫做“零宽度非换行空格”(ZERO WIDTH NO-BREAK SPACE),它用来标识编码顺序是“大头方式”(Big endian)还是“小头方式”(Little endian)。以字符'中'为例,它的Unicode代码点是4E2D,存储时4E在前,2D在后,就是Big endian;2D在前,4E在后,就是Little endian。FEFF表示存储采用大头方式,FFFE表示使用小头方式。
最后我们再看看Unicode增补字符在UTF-16下所占的字节数:
import java.io.UnsupportedEncodingException;
public class MyTest {
public static void main(String[] args) throws UnsupportedEncodingException {
int ch = 0x2F81A;
System.out.println(new String(Character.toChars(ch)).getBytes("UTF-16").length);
}
}输出:
6
Process finished with exit code 0因为多了编码顺序标识,所以这里是2+4=6,与我们之前所说的增补字符集占用4个字节符合。这里需要注意的是增补字符的书写方式,Character.toChars(int codePoint)方法可以根据指定的Unicode代码点返回其在UTF-16表现形式下的char数组,我们可以用它来获得增补字符的UTF-16代码单元。