串——KMP算法
串——KMP算法
如果我们要去找一个单词在一篇文章(相当于一个大字符串)中的定位,这种子串的定位操作通常称做串的模式匹配,是串中最重要的操作之一。
1、朴素模式匹配
按照通常的思路,要在一个长的字符串中找到指定的子串,比较简单的想法是:从左到右一个个匹配,如果这个过程中有某个字符不匹配,就跳回去,将主串开始比较的位置向右移动一位,直到结束。
演示如下:
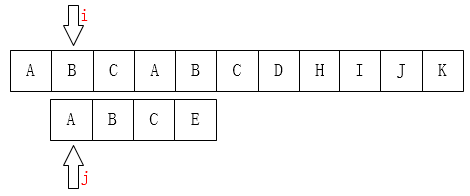
(1)从串的开头初始化比较:

(2)比较i指针指向的字符和j指针指向的字符是否一致。如果一致就都向后移动,如果不一致,如下图:

(3)A和E不相等,那就把i指针移回第1位(假设下标从0开始),j指针移动到模式串的第0位,然后又重新开始这个比较:
(4)程序第3部分算法实现:朴素模式匹配
2、KMP算法
KMP算法要解决的问题就是在字符串(也叫主串)中的模式(pattern)定位问题。说简单点就是我们平时常说的关键字搜索。
KMP算法的关键是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。具体实现就是实现一个next()函数,函数本身包含了模式串的局部匹配信息。时间复杂度O(m+n)。
(1)分析KMP算法的改进思路
分析朴素模式匹配中的例子:
如果我们人为来寻找的话,肯定不会再把i移动回第1位,因为主串匹配失败的位置前面除了第一个A之外再也没有A了,我们为什么能知道主串前面只有一个A?因为我们的子串中字符都不相同,而且我们已经知道前面三个字符都是匹配的!(这很重要)。移动过去肯定也是不匹配!因此,我们产生一个想法,可以保持i不动,只需要移动j即可,如下图:
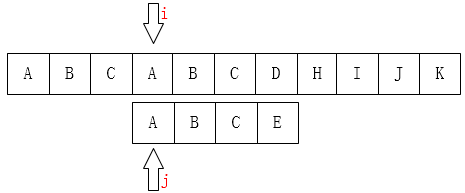
KMP的思想就是:利用已经部分匹配这个有效信息,保持i指针不回溯,通过修改j指针,让模式串尽量地移动到有效的位置。
但是上面这种情况比较理想,因为子串中的字符都不相同,处理起来较简单。如果字串中存在相同的字符,匹配时如何知道j的指针应该移动到哪里呢?
于是我们有个想法:利用一个数组next来保存每一个字符不相同时j应该移动到的位置。
KMP算法的核心就是找到数组next
可是问题来了,这个数组next应该如何确定,也就是说j移动的规律应该是什么样的?
(2)求跳转数组next的思路
现在我们通过例子来发现规律,从而得到求数组next的算法:
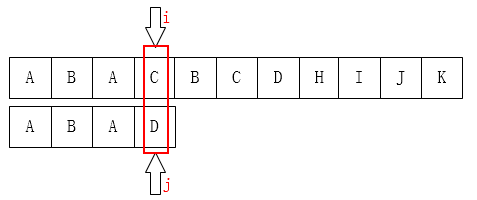
第一个例子如上图:C和D不匹配,我们要把j移动到哪?显然是第1位B。为什么?因为前面有一个A相同:

第二个例子如下图也是一样的情况:

可以把j指针移动到第2位,因为前面有两个字母是一样的:

当匹配失败时,j要移动的下一个位置k。存在着这样的性质:最前面的k个字符和j之前的最后k个字符是一样的。
该性质可以表示为:
S [ 0 ∼ k − 1 ] = = S [ j − k ∼ j − 1 ] S[0 \sim k-1] == S[j-k \sim j-1] S[0∼k−1]==S[j−k∼j−1]
图示如下:

因此,可以直接将j移动到k位置,因为k之前的字符与主串是一样的,从k位置开始比较即可。
于是,得到如下程序:
def get_next(T, next_list):
# next_list[0] = -1作为初始化位置
next_list[0] = -1
j = 0
k = -1
while j < len(T) - 1:
if k == -1 or T[j] == T[k]:
j = j + 1
k = k + 1
next_list[j] = k
else: # -1为k的初始化位置,只要是T[j] != T[k]则k回到初始化位置开始比较
k = next_list[k]
算法最核心的地方是:next_list[j]的值(也就是k)表示,当S[j] != T[i]时,j指针的下一步移动位置。
简单来说,next_list[j]中保存的是:最前面的k个字符和j之前的最后k个字符相同的个数。
KMP算法的改进:
上面的算法存在一点缺陷,
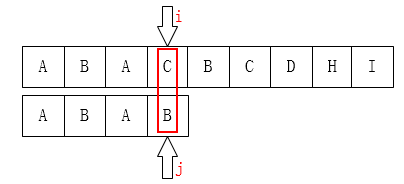
显然,当我们上边的算法得到的next数组应该是[ -1,0,0,1 ]
所以下一步我们应该是把j移动到第1个元素:
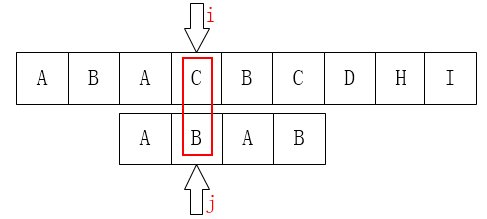
不难发现,这一步是完全没有意义的。因为后面的B已经不匹配了,那前面的B也一定是不匹配的,同样的情况其实还发生在第2个元素A上。
显然,发生问题的原因在于P[j] == P[next[j]]。
所以我们也只需要添加一个判断条件即可:
def get_next(T, next_list):
next_list[0] = -1
j = 0
k = -1
while j < len(T) - 1:
if k == -1 or T[j] == T[k]:
j = j + 1
k = k + 1
if T[j] != T[k]: # 跳过T[j] == T[k]的位置,因为T[j] != S[i],则T[k] != S[i],故无须比较
next_list[j] = k
else:
next_list[j] = next_list[k]
else:
k = next_list[k]
这样可以避免KMP算法中出现类似上面的无效比较。
到此为止,确定数组next_list的全部工作都已完成,KMP算法的完整实现见下面一部分。
KMP算法的时间复杂度:(m + n)
3、一个笔试题
例题:画出字串为ababcabcacbab,模式为abcac时的KMP算法匹配过程。
模式串T="abcac"匹配主串S="ababcabcacbab"的KMP过程如下图:

因此,得到最终的匹配结果需要3次。
其中:子串的next数组为:[-1, 0, 0, 0, 1],当然算法具体实现的差异,也有使用next = [0, 1, 1, 1, 2],只是起始点的比较不一样,没有差异。
4、算法实现(python3)
import time
"""
朴素模式匹配:暴力匹配
直接逐个向下比较,子串和主串字符存在很多重复部分时时间复杂度较高,有些比较没有必要。
"""
def index(S, T, pos):
i = pos
j = 0
while i < len(S) and j < len(T):
if S[i] == T[j]:
i += 1
j += 1
else:
i = i - j + 1
j = 0
if (j >= len(T)):
return i - len(T)
else:
return 0
"""
KMP模式匹配算法:
基本思想:
利用已经部分匹配的有效信息,保持i指针不回溯,通过修改j指针,让模式串尽量地移动到有效的位置。
参数:
S:主串(长度为n)
T:子串(长度为m)
时间复杂度:(m + n)
"""
def get_next(T, next_list):
next_list[0] = -1
j = 0
k = -1
while j < len(T) - 1: # O(m)
if k == -1 or T[j] == T[k]:
j = j + 1
k = k + 1
if T[j] != T[k]: # 跳过T[j] == T[k]的位置,因为T[j] != S[i],则T[k] != S[i],故无须比较
next_list[j] = k
else:
next_list[j] = next_list[k]
else:
k = next_list[k]
def index_KMP(S, T, pos):
i = pos
j = 0
next = [0] * (len(T))
get_next(T, next) # O(m)
print(next)
while i < len(S) and j < len(T): # O(n)
# j == -1:首字母不相等i持续后移,j保持在首地址;S[i] == T[j]:字母相等时i,j持续后移比较;
if j == -1 or S[i] == T[j]:
i += 1
j += 1
else:
j = next[j]
if (j >= len(T)):
return i - len(T)
else:
return 0
if __name__ == '__main__':
S = "aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaabxde"
T = "aaaaaaaaaaab"
pos = 0
start1 = time.perf_counter()
pos = index(S, T, pos)
end1 = time.perf_counter()
print("子串在主串中的位置为:", pos, "; 花费时间:", end1 - start1)
start2 = time.perf_counter()
pos2= index_KMP(S, T, pos)
end2 = time.perf_counter()
print("子串在主串中的位置为:", pos2, "; 花费时间:", end2 - start2)
运行结果:
子串在主串中的位置为: 20 ; 花费时间: 0.00011166400000006682
[-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 10]
子串在主串中的位置为: 20 ; 花费时间: 3.1609999999959726e-05
由运行结果可知,使用KMP算法(3.16e-05),比朴素模型匹配(11.16e-05)时间效率提升很大,原因就在于next数组使得算法避免了很多无效的比较,就好像动态规划使用缓存使得递归避免了很多无效运算一样。
参考:
https://www.cnblogs.com/yjiyjige/p/3263858.html