webpack与rollup背后的acorn
作者:Gloria 来源:知乎
原文:https://zhuanlan.zhihu.com/p/149323563
现如今webpack与rollup在整个前端工程化体系中扮演着极其重要的角色,许许多多的工程化解决方案都需要依托这两款模块打包器去实现。
社区中有大量的文章探索了这些打包器的内部原理,尤其是webpack,却很少有文章探究webpack是如何将代码转换成ast(抽象语法树)的,最多也只是提及acorn,至于acorn的内部实现,很少有人去探究。
如果点开acorn的贡献者列表,你会发现一些著名开源项目成员的身影,如:eslint、babel、vue.js。
ok,现在我们就揭开这层神秘的面纱,带你了解acorn内部的实现。
预热
在正式讲解acorn内部实现之前,我们首先得搞明白下面两个问题:
acorn能够干什么
怎么使用acorn
acorn能够干什么
先来看看acorn对自己的定义:
A tiny, fast JavaScript parser, written completely in JavaScript.
一个完全使用javascript实现的,小型且快速的javascript解析器
所以说,acorn可以完成 javascript 代码解析工作,这个代码解析工作的产出即ast(抽象语法树)。
怎么使用acorn
最基本的使用方法:
let acorn = require('acorn');
let code = "1 + 1";
console.log(acorn.parse(code));
将待解析的代码传给acorn.parse即可,输出遵循 Estree 规范的ast:
{
"type": "Program",
"start": 0,
"end": 11,
"body": [
{
"type": "ExpressionStatement",
"start": 5,
"end": 10,
"expression": {
"type": "BinaryExpression",
"start": 5,
"end": 10,
"left": {
"type": "Literal",
"start": 5,
"end": 6,
"value": 1,
"raw": "1"
},
"operator": "+",
"right": {
"type": "Literal",
"start": 9,
"end": 10,
"value": 1,
"raw": "1"
}
}
}
],
"sourceType": "script"
}
还可以在第二个参数的位置传入配置项,比如待解析的语法版本(ecmaVersion)、源代码类型(sourceType)等等。
如果需要解析esModule就要将sourceType置为module:
console.log(acorn.parse(`
import moduleA from "./moduleA.js";
import moduleB from "./moduleB.js";
function add(v1, v2) { return v1 + v2 }
add(moduleA.val, moduleB.val);
`, { sourceType: 'module' }));
如果想了解acorn的完整配置项列表,可以到这里瞅瞅 Acorn
接下来,进入到acorn内部实现。
内部实现
由于javascript的语法内容过多,为了更好地理解acorn的内部原理,避免纠结于过于细节的逻辑,这一部分会以解析下面代码中出现的语法为栗子,在必要的时候做适当的扩展,避免管中窥豹:
import moduleA from "./moduleA.js";
import moduleB from "./moduleB.js";
function add(v1, v2) { return v1 + v2 }
add(moduleA.val, moduleB.val);
这一部分的大纲:
大体的运行流程
分词
生成ast
大体的运行流程
典型的parser,都会经过下面的过程:
'import ...' -> 词法分析 -> [token, token, ...] -> 语法分析 -> ast
源代码经过词法分析,得到 token 序列
token 序列经过语法分析,得到最终的 ast
但是acorn稍有不同,它的词法分析和语法分析是交替进行的,只需要扫描一次源代码就能得到最终的ast树,看得出是出于对性能的考量。
接下来,看一看acorn大致的源码长啥样。
接下来,看一看acorn大致的源码长啥样。
代码
当调用acorn.parse(input)时,acorn 内部其实调用的是Parser.parse(input),Parser类大致长下面这样:
class Parser {
constructor(options, input, startPos) {
this.type = tt.eof;
this.pos = 0;
this.input = String(input);
...
}
parse() {
let node = this.options.program || this.startNode()
this.nextToken();
return this.parseTopLevel(node);
}
static parse(input, options) {
return new this(options, input).parse();
}
...
上面代码中有些东西需要稍微解释下:
type:当前token
pos:当前token所在input的位置
options为传入的配置项,input为源代码
startNode方法:返回一个空的ast节点
nextToken方法:从input中读取下一个token
parseTopLevel方法:递归下降地组装ast树
其实从这就能看出大体的流程了:
以
parseTopLevel为入口,递归下降地组装ast如需要下一个 token,则调用 nextToken 方法返回下一个token,赋值给this.type
虽然acorn的词法分析和语法分析是交替进行的,但是也不妨碍我们将它们独立出来,单独分析,就先来看看词法分析。
分词
整个acorn分词的过程,可以分为3部分来讲
都有哪些token类型
acorn是如何将源代码转换成token序列的
额外扩展的知识
token类型
看一看下面这段代码涵盖的 token 类型
import moduleA from "./moduleA.js";
import moduleB from "./moduleB.js";
function add(v1, v2) { return v1 + v2 }
add(moduleA.val, moduleB.val);
出现了下面几种token:
关键字(keyword),如:import、from、function、return
普通名称(name),如:moduleA、moduleB、add、v1、v2、val
一些符号,如:;(semi)、,(comma)、.(dot)、((parenL)、)(parenR)、{(braceL)、}(braceR)、+(plusMin)
结束符 eof
代码里是这样声明的:
const types = {
/* 关键字 */
_import: new TokenType("import"),
_from: new TokenType("from"),
_function: new TokenType("function"),
_return: new TokenType("return"),
/* 普通名称 */
name: new TokenType("name"),
/* 一些符号 */
semi: new TokenType(";"),
comma: new TokenType(","),
dot: new TokenType("."),
parenL: new TokenType("("),
parenR: new TokenType(")"),
braceL: new TokenType("{"),
braceR: new TokenType("}"),
plusMin: new TokenType("+/-"),
/* 结束符 */
eof: new TokenType("eof"),
};
状态机
确定了token种类之后,就要开始确定整个词法状态机了。
针对上述几种token,acorn大致的状态机长这样:
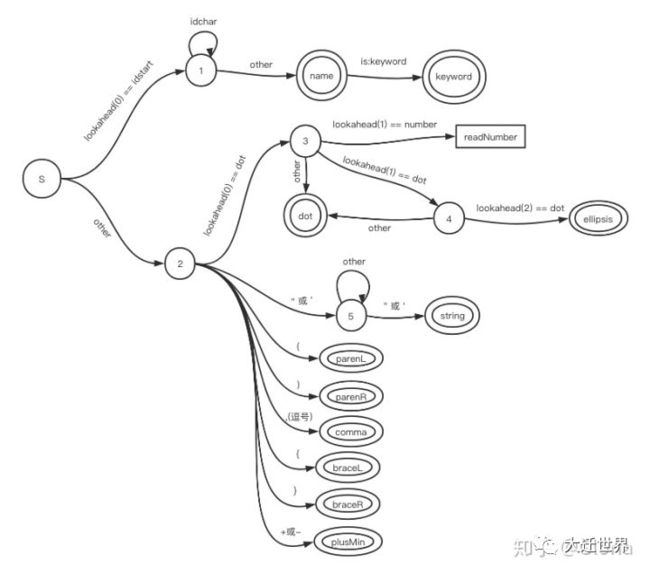
上面状态机中的大部分状态转换都会伴随着1个字符的消耗,但是有两种状态转换不消耗字符:
lookahead表示“向前查看”,不消耗字符,比如:lookahead(1)意为向前查看1个字符,lookahead(0)表示查看当前字符。is:keyword表示匹配到的内容是某个关键字。
确定了状态机之后,看一下核心代码是怎么写的。
核心代码
这一部分会有选择地忽略掉一些与上述例子语法无关的代码,保证尽量少的干扰。
接下来会按照调用顺序,依次说明在下面几个方法做的事情:
nextToken
readToken
readWord 和 getTokenFromCode
nextToken
nextToken方法负责更新当前token,下面是精简过后的代码:
pp.nextToken = function() {
...
if (this.pos >= this.input.length) return this.finishToken(tt.eof)
this.readToken(this.fullCharCodeAtPos())
}
当所有字符都被消耗完毕时,调用
finishToken(tt.eof)将当前 token 变为eof否则,调用
readToken(this.fullCharCodeAtPos())设置当前token
finishToken的相关实现:
pp.finishToken = function(type, val) {
...
this.type = type
this.value = val
...
}
然后,fullCharCodeAtPos是干啥的?
说白了,就是返回当前位置字符的unicode码点。
而es5在里面charCodeAt()方法返回的是当前字符的 utf-16 编码,而有的字符超过了单个 utf-16 字符所能表示的范围,utf-16 使用两个字符来表示它,所以需要特殊处理,像下面这样:
pp.fullCharCodeAtPos = function() {
let code = this.input.charCodeAt(this.pos)
if (code <= 0xd7ff || code >= 0xe000) return code
let next = this.input.charCodeAt(this.pos + 1)
return (code << 10) + next - 0x35fdc00
}
当然,在es6中现在我们可以直接使用codePointAt()实现。
下面进入到的状态机实现。
readToken
直接看代码:
pp.readToken = function(code) {
if (isIdentifierStart(code))
return this.readWord()
return this.getTokenFromCode(code)
}
如果当前code可以作为一个标识符开头,则调用readWord(),否则调用getTokenFromCode(code)。对应这部分状态机:
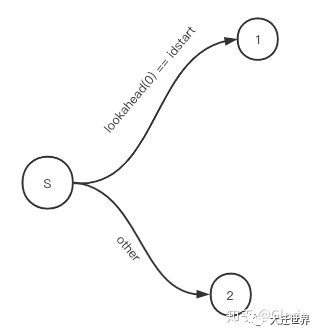
接下来,分别看1和2这两个状态后续部分的实现。
readWord 和 getTokenFromCode
readWord
先瞅一瞅,状态1后面这部分:
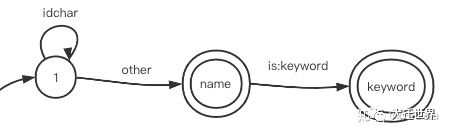
代码实现:
pp.readWord = function() {
let word = this.readWord1()
let type = tt.name
if (this.keywords.test(word)) {
type = keywordTypes[word]
}
return this.finishToken(type, word)
}
调用this.readWord1()方法读取完整的标识符,然后检测该标识符是否是关键字,最后调用this.finishToken(type, word)设置当前token,比如:
word是import,则设置当前token类型为tt._import
word是moduleA,则设置当前token类型为tt.name
其中readWord1方法,精简后的实现如下:
pp.readWord1 = function() {
let chunkStart = this.pos
while (this.pos < this.input.length) {
let ch = this.fullCharCodeAtPos()
if (isIdentifierChar(ch)) {
this.pos += ch <= 0xffff ? 1 : 2
} else {
break
}
}
return this.input.slice(chunkStart, this.pos)
}
做的事情也是比较容易理解,当字符不能出现在标识符中时,将之前的所有字符拼接起来,作为标识符返回。
getTokenFromCode
getTokenFromCode负责的是状态2后面的这部分:
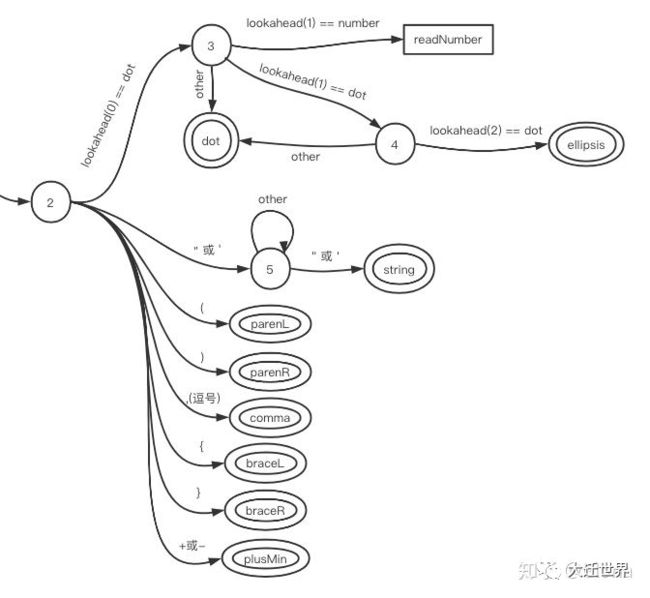
代码实现:
pp.getTokenFromCode = function(code) {
switch (code) {
case 46: return this.readToken_dot()
case 40: ++this.pos; return this.finishToken(tt.parenL)
case 41: ++this.pos; return this.finishToken(tt.parenR)
case 59: ++this.pos; return this.finishToken(tt.semi)
case 44: ++this.pos; return this.finishToken(tt.comma)
case 91: ++this.pos; return this.finishToken(tt.bracketL)
case 93: ++this.pos; return this.finishToken(tt.bracketR)
case 123: ++this.pos; return this.finishToken(tt.braceL)
case 125: ++this.pos; return this.finishToken(tt.braceR)
case 34: case 39: // '"', "'"
return this.readString(code)
}
this.raise(this.pos, "Unexpected character '" + codePointToString(code) + "'")
}
如果都不匹配,则调用this.raise抛出Unexpected character错误。
扩展知识
在acorn词法分析过程中,还有个东西叫做context。
javascript的词法分析任务远比上面例子中情况要复杂很多。
思考一个问题:当解析器遇到/时,如何判断它应该是除法运算符,还是正则表达式的起始字符?
可以结合上下文判断,比如:如果出现在2/这种情况,它就是一个运算符,如果是a = /,那它就是正则表达式的起始字符。
context表达的就是这样一个上下文,它是一个栈,每次解析器设置当前token后,都会根据当前token+上一个token+上一个上下文,操作context栈,生成新的上下文。
再比如:大部分情况我们都可以按照上文出现的既定的词法状态机来提取token,每次提取token之前,都可以跳过连续的空格或者注释,但是当进入到模板字符串的时候情况就变得特殊了,我们需要知道此时词法解析器是否可以跳过空格或者注释。
这个context在很大程度上降低了词法状态机的复杂度,让词法分析相关的代码更加易于维护。
生成ast
import moduleA from "./moduleA.js";
import moduleB from "./moduleB.js";
function add(v1, v2) { return v1 + v2 }
add(moduleA.val, moduleB.val);
上面这段代码,由下面这三种东西构成,从上到下是包含与被包含的关系:
Program:整个程序
Statement:语句
Expression:表达式
Program 包含多个 Statement ,Statement 又包含多个 Expression 或者 Statement,其中 Statement 和 Expression 又会有很多种。比如上面代码存在下面这种结构(遵循estree规范):
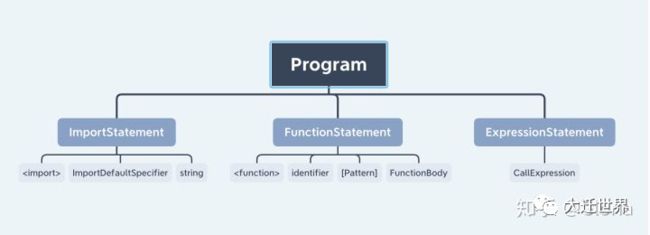
接下来详细介绍上面代码中涉及到语法结构,及其代码实现。
提前说明一点,后面的篇幅我们统一使用EBNF表达式来描述语法结构。
Program
Program在整个程序的AST树结构中作为根节点存在,它的定义如下:
Program -> { Statement }
{...} 表示忽略或者重复,上述表示 Program 由零个或者多个 Statment 组成。
对应acorn精简后的实现:
pp.parseTopLevel = function(node) {
while (this.type !== tt.eof) {
let stmt = this.parseStatement();
node.body.push(stmt);
}
this.next();
return this.finishNode(node, "Program");
}
this.next()的作用等同于this.nextToken()``,读取下一个token`,并赋值给this.type。
其中 finishNode 方法负责返回一个ast节点,大致长这样:
pp.finishNode = function(node, type) {
node.type = type;
...
return node;
}
接下来看看 Statement 的定义。
Statement
这里只给出示例代码中出现的Statement的语法结构:
Statement -> FunctionStatement | ImportStatement | ExpressionStatement
| 表示选择,意思是 Statement 可以是函数语句,模块引入语句或者表达式语句。
对应acorn精简后的实现:
pp.parseStatement = function() {
// 生成一个空ast节点
let node = this.startNode();
let starttype = this.type;
switch(starttype) {
...
case tt._function: return this.parseFunctionStatement(node)
case tt._import: return this.parseImport(node)
...
default: return this.parseExpressionStatement(node)
}
}
FunctionStatment
一个正常的函数声明语句的语法(不包含匿名函数或者箭头函数的语法)
FunctionStatment ->Identity FunctionParams FunctionBody
由function(关键字),Identity(标识符),FunctionParams(函数参数),FunctionBody(函数体)组成。
精简后的acorn实现:
pp.parseFunctionStatement = function(node) {
this.next()
return this.parseFunction(node);
}
pp.parseFunction = function(node) {
node.id = this.type === tt.name ? this.parseIdent() : null;
this.parseFunctionParams(node);
this.parseFunctionBody(node)
return this.finishNode(node, "FunctionDeclaration")
}
ImportStatement
模块引入语句语法:
ImportStatement -> ImportSpecifiers ExpAtom
ImportSpecifiers -> DefaultSpecifier
DefaultSpecifier -> Identity
上述只包含import a from 'b'这种语句的语法结构。
精简后的acorn实现:
/* ImportStatement */
pp.parseImport = function(node) {
this.next()
node.specifiers = this.parseImportSpecifiers()
this.expectContextual("from")
node.source = this.parseExprAtom();
this.semicolon()
return this.finishNode(node, "ImportDeclaration")
}
/* ImportSpecifiers */
pp.parseImportSpecifiers = function() {
let nodes = [];
let node = this.startNode()
node.local = this.parseIdent()
nodes.push(this.finishNode(node, "ImportDefaultSpecifier"))
return nodes
}
其中有两个方法需要解释一下:
this.expectContextual():先检验当前token是否匹配传入的上下文关键字,如匹配则消耗当前token,否则报错。this.semicolon():消耗一个分号,如果当前token不是分号,则尝试插入一个分号,如果当前位置不允许插入分号,则报错。
ExpressionStatement
示例代码中很多地方都是 ExpressionStatement,比如v1 + v2,add(moduleA.val, moduleB.val)。
自顶向下的语法结构:
ExpressionStatement -> MaybeAssign {,MaybeAssign}
MaybeAssign -> MaybeConditional [assign MaybeAssign]
MaybeConditional -> ExprOps [?MaybeAssign:MaybeAssign]
ExprOps -> MaybeUnary ExprOp
ExprOp -> binOp MaybeUnary ExprOp | ε
MaybeUnary -> prefix MaybeUnary | ExprSubscripts postfix
ExprSubscripts -> ExprAtom Subscripts
ExprAtom -> identity
Subscripts -> {Subscript}
Subscript -> [Expr] | .id | (...)
先解释一下一些奇怪的东西:
ε代表空字符
binOp代表二元运算符,比如:逻辑运算符、位运算符、关系运算符等等
prefix和postfix代表能够作为前缀和后缀的符号,比如:前缀:++、--、!、~、+、-、typeof、void、delete 后缀:++、--
assign代表能够作为赋值作用的符号,比如:=、+=、-= 3. id代表标识符
着重说说下面几件事情:
总体上分为几类(优先级从高到低):MaybeAssign(赋值表达式)、MaybeConditional(条件表达式)、ExprOps(二元表达式)、MaybeUnary(一元表达式)。
ExprSubscripts 是在多元表达式层面,不可再拆分的语法单元,比如在++a.b中,ExprSubscripts 代表着a.b
ExprSubscripts 由 ExprAtom 和 Subscripts 组成,比如在a.b中,ExprAtom 是a,Subscripts 是.b
ExprOps(二元表达式)语法结构没有明确运算符的优先级关系,所以需要在解析算法中针对优先级做特殊处理,可详见下面parseExprOp方法的实现
精简过后的acorn实现:
/* ExpressionStatement */
pp.parseExpression = function() {
let expr = this.parseMaybeAssign()
if (this.type === tt.comma) {
let node = this.startNodeAt()
node.expressions = [expr]
while (this.eat(tt.comma)) node.expressions.push(this.parseMaybeAssign())
return this.finishNode(node, "SequenceExpression")
}
return expr
}
/* MaybeAssign */
pp.parseMaybeAssign = function() {
let left = this.parseMaybeConditional();
if (this.type.isAssign) {
let node = this.startNodeAt()
node.operator = this.value
node.left = this.type === tt.eq ? this.toAssignable(left, false) : left
this.next()
node.right = this.parseMaybeAssign()
return this.finishNode(node, "AssignmentExpression")
}
return left
}
/* MaybeConditional */
pp.parseMaybeConditional = function() {
let expr = this.parseExprOps()
if (this.eat(tt.question)) {
let node = this.startNodeAt()
node.test = expr
node.consequent = this.parseMaybeAssign()
this.expect(tt.colon)
node.alternate = this.parseMaybeAssign()
return this.finishNode(node, "ConditionalExpression")
}
return expr
}
/* ExprOps */
pp.parseExprOps = function() {
let expr = this.parseMaybeUnary()
return this.parseExprOp(expr)
}
/*
* ExprOp
* 接受两个参数 left、minPrec
* left 为运算符左边的表达式
* minPrec 表示当前运算的最小优先级
* 如果当前运算符的优先级不大于 minPrec ,则停止解析,否则解析右边的表达式
* 保证了解析出来的ast结构满足真实的运算符优先级关系
*/
pp.parseExprOp = function(left, minPrec) {
let prec = this.type.binop
if (prec > minPrec) {
let logical = this.type === tt.logicalOR || this.type === tt.logicalAND
let op = this.value
this.next()
let right = this.parseExprOp(this.parseMaybeUnary(null, false), prec)
let node = this.buildBinary(left, right, op, logical)
return this.parseExprOp(node, minPrec)
}
return left
}
/* MaybeUnary */
pp.parseMaybeUnary = function() {
let expr
if (this.type.prefix) {
let node = this.startNode()
node.operator = this.value
node.prefix = true
this.next()
node.argument = this.parseMaybeUnary()
expr = this.finishNode(node, "UnaryExpression")
} else {
expr = this.parseExprSubscripts(refDestructuringErrors)
while (this.type.postfix && !this.canInsertSemicolon()) {
let node = this.startNodeAt(startPos, startLoc)
node.operator = this.value
node.prefix = false
node.argument = expr
this.next()
expr = this.finishNode(node, "UpdateExpression")
}
}
return expr
}
/* ExprSubscripts */
pp.parseExprSubscripts = function() {
let expr = this.parseExprAtom()
return this.parseSubscripts(expr);
}
/* ExprAtom */
pp.parseExprAtom = function() {
return this.parseIdent();
}
/* Subscripts */
pp.parseSubscripts = function(base) {
while (true) {
let element = this.parseSubscript(base)
if (element === base) return element
base = element
}
}
/* Subscript */
pp.parseSubscript = function(base) {
let computed = this.eat(tt.bracketL)
if (computed || this.eat(tt.dot)) {
let node = this.startNodeAt()
node.object = base
node.property = computed ? this.parseExpression() : this.parseIdent()
node.computed = !!computed
if (computed) this.expect(tt.bracketR)
base = this.finishNode(node, "MemberExpression")
} else if (this.eat(tt.parenL)) {
let exprList = this.parseExprList(tt.parenR)
let node = this.startNodeAt()
node.callee = base
node.arguments = exprList
base = this.finishNode(node, "CallExpression")
}
return base
}
额外再说明一点,关于运算符的优先级,在定义token的时候已经确定好了,像下面这样,里面出现的数字代表优先级:
export const types = {
logicalOR: binop("||", 1),
logicalAND: binop("&&", 2),
bitwiseOR: binop("|", 3),
bitwiseXOR: binop("^", 4),
bitwiseAND: binop("&", 5),
equality: binop("==/!=/===/!==", 6),
relational: binop("/<=/>=", 7),
bitShift: binop("<>/>>>", 8),
plusMin: new TokenType("+/-", {binop: 9}),
modulo: binop("%", 10),
star: binop("*", 10),
slash: binop("/", 10),
}
到目前为止,我们已经把示例代码中涉及到语法的语法表示和解析器的具体实现大致上过了一遍。
js语法还有很多犄角旮旯的东西,上面的语法表示和实现也只是冰山一角。
除了构建AST外,acorn在语法解析阶段还做了什么事情呢?
那当然是:抛出错误。
接下来就简单说说acorn是如何做这件事的。
抛出错误
当目标代码中包含一些非法字符,或者不符合语法规则的情况,acorn会抛出一些可读的错误信息。
acorn中所有的错误都是通过raise方法抛出:
pp.raise = function(pos, message) {
let loc = getLineInfo(this.input, pos)
message += " (" + loc.line + ":" + loc.column + ")"
let err = new SyntaxError(message)
err.pos = pos; err.loc = loc; err.raisedAt = this.pos
throw err
}
pos代码位置 从0 开始,message是需要抛出的异常文本,除了传入的主体的异常信息,raise方法还会根据传入的pos在异常信息后面追加行、列信息。
下面根据抛出错误的阶段,分别讨论词法错误和语法错误。
词法错误
词法错误,即在词法分析阶段抛出的错误,当词法状态机接收到不被期望的字符时,会在此时抛出一个错误。
在acorn中,比如getTokenFromCode方法中的最后一行
pp.getTokenFromCode = function(code) {
switch (code) {
case 46: return this.readToken_dot()
...
}
this.raise(this.pos, "Unexpected character '" + codePointToString(code) + "'")
}
当 code 在switch所枚举的范围之外时,就会抛出一个错误Unexpected character XXX。
语法错误
在语法解析阶段,acorn会有针对性地对一些语法错误做检测,并给出友好的错误提示,在这里有几种典型的错误类型:
特定的语法错误
Unexpected token
左值错误
特定的语法错误
指在特定语句中的特殊语法错误,比如,import语句只能出现在程序的顶部,在parseStatement方法里就有这么一段:
pp.parseStatement = function(..., topLevel, ...) {
switch (starttype) {
...
case tt._import:
...
if (!this.options.allowImportExportEverywhere) {
if (!topLevel)
this.raise(this.start, "'import' and 'export' may only appear at the top level")
if (!this.inModule)
this.raise(this.start, "'import' and 'export' may appear only with 'sourceType: module'")
}
}
}
如果没有设置allowImportExportEverywhere为true,import和export必须在顶层出现,顶层即来自parseTopLevel的调用,如果在非顶层starttype命中了tt._import,则抛出错误。
Unexpected token
Unexpected token 算是最常见的语法错误,当目前token不满足语法结构时就会抛出Unexpected token,比如上面讲到过的三目条件表达式的语法结构:
MaybeConditional -> ExprOps [?MaybeAssign:MaybeAssign]
第一个MaybeAssign后面必须跟着一个:(冒号):
pp.parseMaybeConditional = function() {
let expr = this.parseExprOps()
if (this.eat(tt.question)) {
let node = this.startNodeAt()
node.test = expr
node.consequent = this.parseMaybeAssign()
this.expect(tt.colon)
node.alternate = this.parseMaybeAssign()
return this.finishNode(node, "ConditionalExpression")
}
return expr
其中this.expect(tt.colon)会消耗一个冒号,如果当前token不是冒号,则抛出错误:
pp.expect = function(type) {
this.eat(type) || this.unexpected()
}
pp.unexpected = function(pos) {
this.raise(pos != null ? pos : this.start, "Unexpected token")
}
左值错误
左值即赋值语句左边的部分,比如a = 2,其中a就是左值。
那啥是左值错误呢?简单说就是当一个语法单元不能作为左值时抛出的错误。
acorn按照下面的思路检测一个语法单元是否能够作为左值:
1.枚举所有可能作为左值的语法类型,如果不存在其中,则报错,acorn对应的实现则是switch:
pp.checkLVal = function(expr, bindingType = BIND_NONE) {
switch(expr.type) {
case "identifier":
...
case "MemberExpression":
...
...
default:
this.raise(expr.start, (bindingType ? "Binding" : "Assigning to") + " rvalue")
}
}
如果不存在其中,则流到default分支中,抛出一个错误。
2.针对当前语法类型,结合左值可能出现的上下文语境,判断其能否作为左值
你肯定已经发现代码中有个bindingType,这个东西就是上下文语境,一共有6种语境:
BIND_NONE = 0, // 不是 变量绑定
BIND_VAR = 1, // Var 变量绑定
BIND_LEXICAL = 2, // Let 或者 const变量绑定
BIND_FUNCTION = 3, // 函数声明
BIND_SIMPLE_CATCH = 4, // catch 参数绑定
BIND_OUTSIDE = 5 // 在函数名称绑定在函数内部
这样,上面最后一行代码就很好理解了。
完整看一看Identifier中的逻辑:
pp.checkLVal = function(expr, bindingType = BIND_NONE) {
switch(expr.type) {
case "Identifier":
if (bindingType === BIND_LEXICAL && expr.name === "let")
this.raise(expr.start, "let is disallowed as a lexically bound name")
if (bindingType !== BIND_NONE && bindingType !== BIND_OUTSIDE) this.declareName(expr.name, bindingType, expr.start)
break
...
}
}
第一个判断:当当前上下文语境是,let和const变量绑定时,变量名不能是let。
第二个判断,当当前语境是声明类型语境时,调用this.declareName方法,该方法会在当前作用域内,在对应语境中搜索是否有重复声明,如果没有重复,则将标识符保存在作用域中,否则报错。
this.raise(pos, `Identifier '${name}' has already been declared`)
你可能有些疑惑,作用域持有哪些信息?直接看代码吧:
class Scope {
constructor(flags) {
this.flags = flags
this.var = []
this.lexical = []
this.functions = []
}
}
flags:作用域类型
this.var、this.lexical、this.functions对应着上面3种语境,根据不同的语境在不同的数组中找
那作用域是如何保存的?
答案是,acorn维护了一个栈,这个栈叫做scopeStack,每当解析器进入函数或块级语法时,都会创建一个新作用域推进栈中,离开时则在栈顶弹出一个作用域:
pp.enterScope = function(flags) {
this.scopeStack.push(new Scope(flags))
}
pp.exitScope = function() {
this.scopeStack.pop()
}
结尾
看acorn源码的过程还是比较痛苦的,还好坚持下来了,收获颇丰,但是由于篇幅限制不能把所有东西全部涵盖,这篇文章前前后后也拖了很久了,就此结束吧。
反正你要是能看到这,我敬你是条汉子!!
后续,大概率还会继续探索跟编译相关的主题,但是谁知道呢。
相关热门推荐
小智最近在学习正则,学习过程中发现这 6 个方便的正则表达式
详解 ES10 中 Object.fromEntries() 的缘起
有哪些被低估未被广泛使用的有用的 HTML标签?
【干货】工业软件为什么这么难?
JS执行上下文的两个阶段做了些啥?
为了反对种族歧视,代码托管平台GitHub可能要改术语了
【第 244 期】小智周末学习发现了 10 个好用JavaScript图像处理库
【第 243 期】前端!7个快速发现 bug 神仙调试工具
