R语言线性判别分析(LDA),二次判别分析(QDA)和正则判别分析(RDA)
- 大数据部落
- 数据分析
- 小波滤波器
- 算法
- 数据挖掘代写
- Computer
- science代写
- 代写Computer
- science
- assignment
- 数据分析报告代写
- CS作业代写
- C代写
- C++代写
- R语言代写
- python代写
- 数据库代写
- 数
原文链接:http://tecdat.cn/?p=5689
判别分析包括可用于分类和降维的方法。线性判别分析(LDA)特别受欢迎,因为它既是分类器又是降维技术。二次判别分析(QDA)是LDA的变体,允许数据的非线性分离。最后,正则化判别分析(RDA)是LDA和QDA之间的折衷。
本文主要关注LDA,并探讨其在理论和实践中作为分类和可视化技术的用途。由于QDA和RDA是相关技术,我不久将描述它们的主要属性以及如何在R中使用它们。
线性判别分析
LDA是一种分类和降维技术,可以从两个角度进行解释。第一个是解释是概率性的,第二个是更多的程序解释,归功于费舍尔。第一种解释对于理解LDA的假设是有用的。第二种解释可以更好地理解LDA如何降低维数。
Fisher的LDA优化标准
Fisher的LDA优化标准规定组的质心应尽可能分散。这相当于找到一个线性组合ž= aŤXZ=aTX,使得aTaT相对于类内方差的类间方差最大化。
LDA模型的复杂性
LDA的有效参数的数量可以通过以下方式导出。有KK手段μ^kμ^k被估计。协方差矩阵不需要额外的参数,因为它已经由质心定义。由于我们需要估计KK判别函数(以获得判定边界),这就产生了涉及p个元素的KK计算。另外,我们有ķ-1为自由参数ķ前科。因此,有效LDA参数的数量是Kp+(K-1)。
LDA摘要
在这里,我总结了LDA的两个观点,并总结了该模型的主要特性。
概率论
LDA使用贝叶斯规则来确定观察xx属于kk类的后验概率。由于LDA的正常假设,后验由多元高斯定义,其协方差矩阵假定对于所有类是相同的。新的点通过计算判别函数分类δkδk(后验概率的枚举器)并返回类kk具有最大δkδk。判别变量可以通过类内和类间方差的特征分解来获得。
费舍尔的观点
根据Fisher,LDA可以理解为降维技术,其中每个连续变换是正交的并且相对于类内方差最大化类间方差。此过程将特征空间转换为具有K−1K−1维度的仿射空间。在对输入数据进行扩展之后,可以通过在考虑类先验的情况下确定仿射空间中的最接近的质心来对新点进行分类。
LDA的特性
LDA具有以下属性:
- LDA假设数据是高斯数据。更具体地说,它假定所有类共享相同的协方差矩阵。
- LDA在K−1K−1维子空间中找到线性决策边界。因此,如果自变量之间存在高阶相互作用,则不适合。
- LDA非常适合于多类问题,但是当类分布不平衡时应该小心使用,因为根据观察到的计数来估计先验。因此,观察很少被分类为不常见的类别。
- 与PCA类似,LDA可用作降维技术。请注意,LDA的转换本质上与PCA不同,因为LDA是一种考虑结果的监督方法。
数据集
为了举例说明线性判别分析,我们将使用音素语音识别数据集。该数据集对于展示判别分析很有用,因为它涉及五种不同的结果。
library(RCurl)
f <- getURL('phoneme.csv')
df <- read.csv(textConnection(f), header=T)
print(dim(df))## [1] 4509 259
为了以后评估模型,我们将每个样本分配到培训或测试集中:
#logical vector: TRUE if entry belongs to train set, FALSE else
train <- grepl("^train", df$speaker)
# remove non-feature columns
to.exclude <- c("row.names", "speaker""g")
feature.df <- df[, !colnames(df) %in% to.exclude]
test.set <- subset(feature.df, !train)
train.set <- subset(feature.df, train)
train.responses <- subset(df, train)$g
test.responses <- subset(df, !train)$g在R中拟合LDA模型
我们可以通过以下方式拟合LDA模型:
library(MASS)
lda.model <- lda(train.set, grouping = train.responses)
LDA作为可视化技术
我们可以通过在缩放数据上应用变换矩阵将训练数据转换为规范坐标。要获得与predict.lda函数返回的结果相同的结果,我们需要首先围绕加权平均数据居中:
## [1] TRUE我们可以使用前两个判别变量来可视化数据: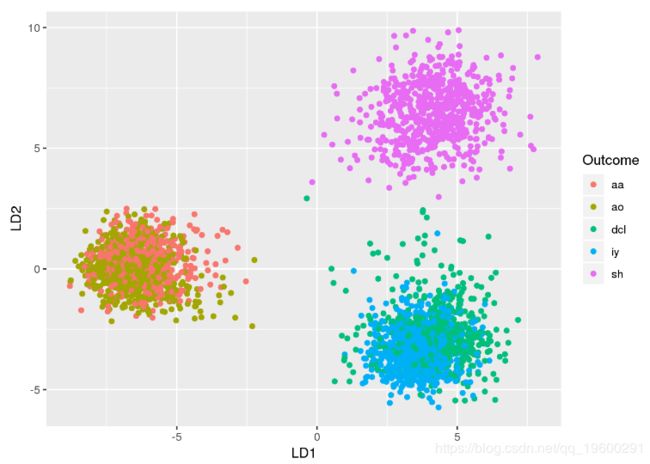
绘制两个LDA维度中的数据显示三个集群:
- 群集1(左)由aa和ao音素组成
- 群集2(右下角)由dcl和iy音素组成
- 群集3(右上角)由sh音素组成
这表明两个维度不足以区分所有5个类别。然而,聚类表明可以非常好地区分彼此充分不同的音素。
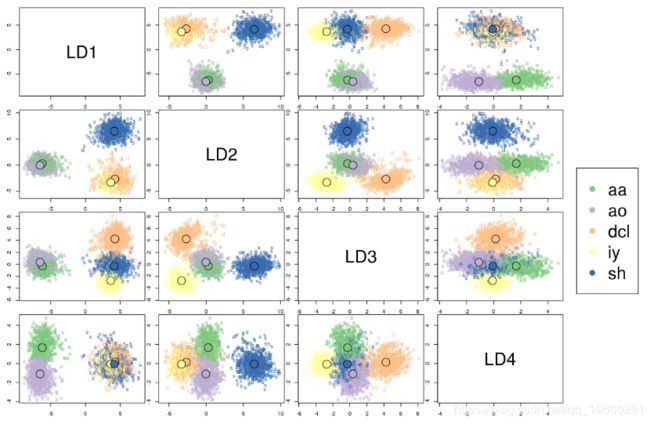
我们还可以使用plot.lda函数绘制训练数据到所有判别变量对的映射,其中dimen参数可用于指定所考虑的维数:

为了可视化组的质心,我们可以创建自定义图:
解释后验概率
除了将数据转换为由分量x提供的判别变量之外,预测函数还给出后验概率,其可以用于分类器的进一步解释。例如:
## [1] "Posterior of predicted class 'sh' is: 1"
## aa ao dcl iy sh
## aa 0.797 0.203 0.000 0.000 0.000
## ao 0.123 0.877 0.000 0.000 0.000
## dcl 0.000 0.000 0.985 0.014 0.002
## iy 0.000 0.000 0.001 0.999 0.000
## sh 0.000 0.000 0.000 0.000 1.000各个班级的后验表格表明该模型对音素aa和ao最不确定,这与我们对可视化的期望一致。
LDA作为分类器
如前所述,LDA的好处是我们可以选择用于分类的规范变量的数量。在这里,我们仍将通过使用多达四个规范变量进行分类来展示降级LDA的使用。
## Rank Accuracy
## 1 1 0.51
## 2 2 0.71
## 3 3 0.86
## 4 4 0.92正如从变换空间的视觉探索所预期的那样,测试精度随着每个附加维度而增加。由于具有四维的LDA获得最大精度,我们将决定使用所有判别坐标进行分类。
为了解释模型,我们可以可视化 分类器的性能:
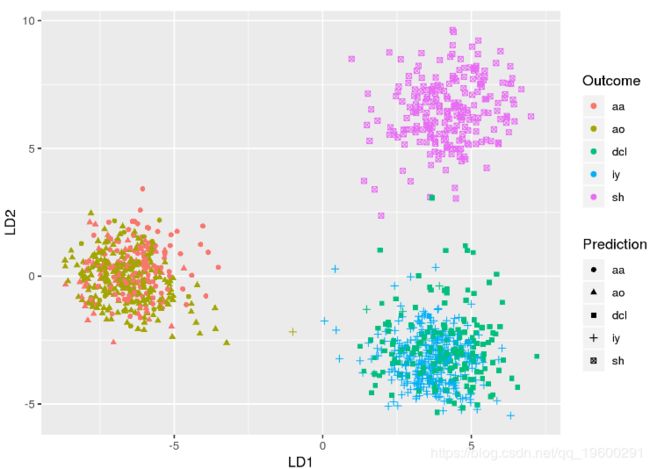
在图中,预期的音素以不同的颜色显示,而模型预测通过不同的符号显示。具有100%准确度的模型将为每种颜色分配单个符号。
二次判别分析
QDA是LDA的变体,其中针对每类观察估计单个协方差矩阵。如果事先知道个别类别表现出不同的协方差,则QDA特别有用。QDA的缺点是它不能用作降维技术。
由于QDA估计每个类的协方差矩阵,因此它具有比LDA更多的有效参数。我们可以通过以下方式得出参数的数量。
因此,QDA参数的有效数量是ķ- 1 + K.p + K.p (p + 1 )2K−1+Kp+Kp(p+1)2。
由于QDA参数的数量在pp是二次的,因此当特征空间很大时,应小心使用QDA。
QDA在R
我们可以通过以下方式执行QDA:
的QDA和LDA对象之间的主要区别是,QDA具有p×pp×p的变换矩阵对于每个类k∈{1,…,K}k∈{1,…,K}。这些矩阵确保组内协方差矩阵是球形的,但不会导致子空间减小。因此,QDA不能用作可视化技术。
让我们确定QDA在音素数据集上是否优于LDA:
## [1] "Accuracy of QDA is: 0.84"
QDA的准确度略低于全级LDA的准确度。这可能表明共同协方差的假设适合于该数据集。规范的判别分析
由于RDA是一种正则化技术,因此当存在许多潜在相关的特征时。现在让我们评估音素数据集上的RDA。
R中的RDA
rda.preds <- predict(rda.model, t(train.set), train.responses, t(test.set))
# determine performance for each alpha
rda.perf <- vector(, dim(rda.preds)[1])
for(i in seq(dim(rda.preds)[1])) {
# performance for each gamma
res <- apply(rda.preds[i,,], 1, function(x) length(which(x == as.numeric(test.responses))) / length(test.responses))
rda.perf[[i]] <- res
}
rda.perf <- do.call(rbind, rda.perf)
rownames(rda.perf) <- alphas结论
判别分析对于多类问题特别有用。LDA非常易于理解,因为它可以减少维数。使用QDA,可以建模非线性关系。RDA是一种正则化判别分析技术,对大量特征特别有用。