哈希表充分体现了算法设计领域的经典思想:空间换时间
哈希函数
不管是散列还是哈希,这都是中文翻译的差别,英文其实就是 “Hash” 。所以,我们常听到有人把 “散列表 ” 叫作 “哈希表”“Hash 表 ” ,把 “哈希算法 ” 叫作 “Hash 算法” 或者 “散列算法 ”
键转换成索引,同时键通过哈希函数得到的索引分布越均匀越好。
原则
1一致性 如果a==b 则hash(a)==hash(b)
2 高效性 计算高效简单
3 均匀性 哈希值均匀分布
hashcode
整型
小范围正整数直接使用
小范围负整数进行偏移
大整数
通常做法取模,也就是取大整数的后几位,容易出现分布不均匀。模一个素数
字符串
转换成整数处理

Hash 取模
余数总是在一个固定的范围内。
整数是没有边界的,它可能是正无穷,也可能是负无穷。但是余数却可以通过某 一种关系,让整数处于一个确定的边界内。
计算星期
2019年的6月3号是周一 那么30天之后的2019年7月3日是星期几
拿 30 除以 7(因为一个星期有 7 天),然后余 2,最后在今天的基础上加2天,这样你就能知道 30 天之后是星期三了。
index = hash(key) % N
其中 hash 函数是一个将字符串转换为正整数的哈希映射方法,N 就是节点的数量。
同余定理
两个整数 a 和 b,如果它们除以正整数 m 得到的余数相等,我们就可以说 a 和 b 对于模 m 同余。
同余定理的用途:同余定理其实就是用来分类
安全加密与校验
哈希算法是MD5(MD5 Message-Digest Algorithm,MD5 消息摘要算法)和 SHA (Secure Hash Algorithm,安全散列算法)。
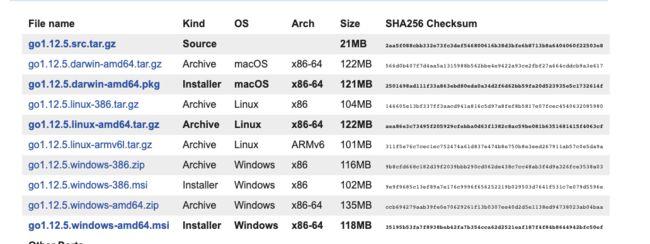
数据传输中的问题
A 向 B 发送的消息可能会在传输途中被 X 偷看(如右图)。这就是“窃听”。

▶ 假冒
A 以为向 B 发送了消息,然而 B 有可能是 X 冒充的(如下页上图);反过来, B 以为从 A
那里收到了消息,然而 A 也有可能是 X 冒充的。这种问题就叫作“假冒”。
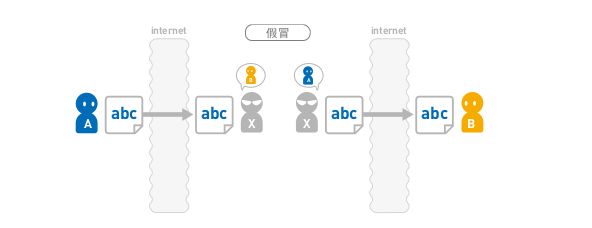
篡改
即便 B 确实收到了 A 发送的消息,该消息的内容在途中就被 X 更改了。
这种行为就叫作“篡改”。除了被第三者篡改外,通信故障导致的数据损坏也可能会使消息内容发生变化。

事后否认
B 从 A 那里收到了消息,但作为消息发送者的 A 可能对 B 抱有恶意,并在事后声称“这不是我发送的消息”
这种情况会导致互联网上的商业交易或合同签署无法成立。这种行为便是“事后否认”。

| 窃听 | 加密 |
| 假冒 | 数字签名/消息认证码 |
| 篡改 | 数字签名/消息认证码 |
| 事后否认 | 数字签名 |
3唯一标示
我们可以从图片的二进制码串开头取 100 个字节,从中间取 100 个字节,从最后再取 100 个字 节,然后将这 300 个字节放到一块,通过哈希算法(比如 MD5 ),得到一个哈希字符串,用它作为图片的唯一标识。通过这个唯一标识来判定图片是否在图库 中,这样就可以减少很多工作量。
4负载均衡
会话粘滞(session sticky),在一次会话中的所有请求都路由到同一个服务器上。
通过哈希算法,对客户端IP地址或者会话ID计算哈希值,将取得的哈希值与服务器列表的大小进 行取模运算,最终得到的值就是应该被路由到的服务器编号。 这样,我们就可以把同一个IP过来的所有请求,都路由到同一个后端服务器上。
分布式session管理实现方案
1Session复制
在支持Session复制的Web服务器上,通过修改Web服务器的配置,可以实现将Session同步到其它Web服务器上,达到每个Web服务器上都保存一致的Session。
优点:代码上不需要做支持和修改。
缺点:需要依赖支持的Web服务器,一旦更换成不支持的Web服务器就不能使用了,在数据量很大的情况下不仅占用网络资源,而且会导致延迟。
适用场景:只适用于Web服务器比较少且Session数据量少的情况。
可用方案:开源方案tomcat-redis-session-manager,暂不支持Tomcat8。
2.Session粘滞
将用户的每次请求都通过某种方法强制分发到某一个Web服务器上,只要这个Web服务器上存储了对应Session数据,就可以实现会话跟踪。
优点:使用简单,没有额外开销。
缺点:一旦某个Web服务器重启或宕机,相对应的Session数据将会丢失,而且需要依赖负载均衡机制。
适用场景:对稳定性要求不是很高的业务情景。
.Session集中管理
在单独的服务器或服务器集群上使用缓存技术,如Redis存储Session数据,集中管理所有的Session,所有的Web服务器都从这个存储介质中存取对应的Session,实现Session共享。
优点:可靠性高,减少Web服务器的资源开销。
缺点:实现上有些复杂,配置较多。
适用场景:Web服务器较多、要求高可用性的情况。
可用方案:开源方案Spring Session,也可以自己实现,主要是重写HttpServletRequestWrapper中的getSession方法,博主也动手写了一个,github搜索joincat用户,然后自取。
基于Cookie管理
这种方式每次发起请求的时候都需要将Session数据放到Cookie中传递给服务端。
优点:不需要依赖额外外部存储,不需要额外配置。
缺点:不安全,易被盗取或篡改;Cookie数量和长度有限制,需要消耗更多网络带宽。
适用场景:数据不重要、不敏感且数据量小的情况。
5数据分片
统计 “ 搜索关键词 ” 出现的次数?
1搜索日志很大,没办法放到一台机器的内存中。
2如果只用一台机器来处理这么巨大的数据,处理时间会很长。
具体的思路是这样的:为了提高处理的速度,我们用n台机器并 行处理。我们从搜索记录的日志文件中,依次读出每个搜索关键词,并且通过哈希函数计算哈希值,然后再跟 n 取模,最终得到的值,就是应该被分配到的机器编号。处理过程也是MapReduce 的基本设计思想。
给这1亿张图片构建散列表大约需要多少台机器。
散列表中每个数据单元包含两个信息,哈希值和图片文件的路径。假设我们通过 MD5 来计算哈希值,那长度就是 128 比特,也就是 16 字节。文件路径长度的上限 是 256 字节,我们可以假设平均长度是 128 字节。如果我们用链表法来解决冲突,那还需要存储指针,指针只占用 8 字节。所以,散列表中每个数据单元就占 用 152 字节(这里只是估算,并不准确)。 假设一台机器的内存大小为 2GB ,散列表的装载因子为 0.75 ,那一台机器可以给大约 1000 万( 2GB*0.75/152 )张图片构建散列表。所以,如果要对 1 亿张图片构建 索引,需要大约十几台机器。在工程中,这种估算还是很重要的,能让我们事先对需要投入的资源、资金有个大概的了解,能更好地评估解决方案的可行性。 实际上,针对这种海量数据的处理问题,我们都可以采用多机分布式处理。借助这种分片的思路,可以突破单机内存、 CPU 等资源的限制。
6分布式存储



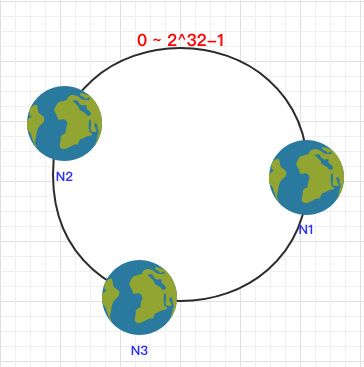
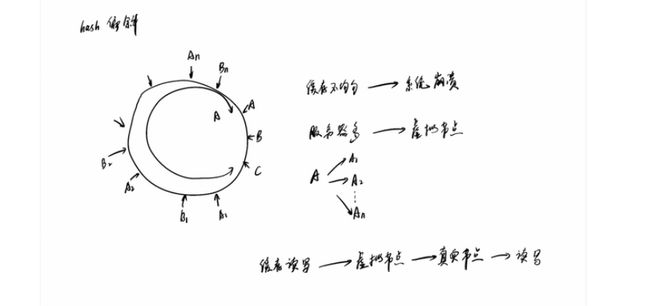
一致 Hash 算法是将所有的哈希值构成了一个环,其范围在 0 ~ 2^32-1。如下图:

之后将各个节点散列到这个环上,可以用节点的 IP、hostname 这样的唯一性字段作为 Key 进行 hash(key),散列之后如下:
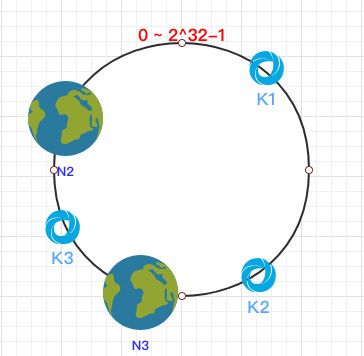
之后需要将数据定位到对应的节点上,使用同样的 hash 函数 将 Key 也映射到这个环上。

这样按照顺时针方向就可以把 k1 定位到 N1节点,k2 定位到 N3节点,k3 定位到 N2节点。
容错性这时假设 N1 宕机了:
依然根据顺时针方向,k2 和 k3 保持不变,只有 k1 被重新映射到了 N3。这样就很好的保证了容错性,当一个节点宕机时只会影响到少少部分的数据。
拓展性当新增一个节点时:
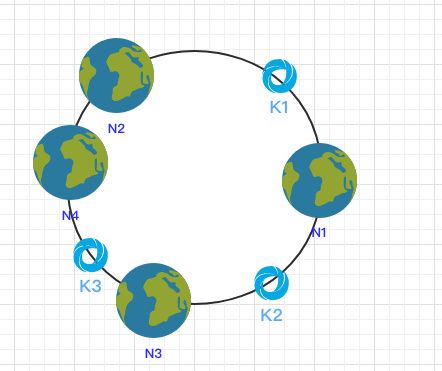
在 N2 和 N3 之间新增了一个节点 N4 ,这时会发现受印象的数据只有 k3,其余数据也是保持不变,所以这样也很好的保证了拓展性。
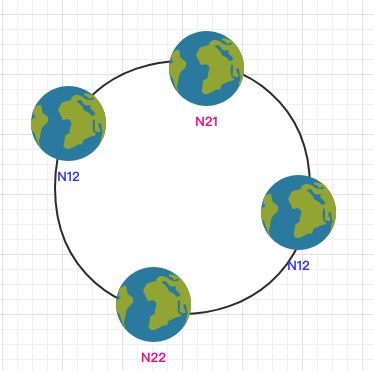
hash偏斜
当节点较少时会出现数据分布不均匀的情况:

都在 N1 节点,只有少量的数据在 N2 节点。
为了解决这个问题,一致哈希算法引入了虚拟节点。将每一个节点都进行多次 hash,生成多个节点放置在环上称为虚拟节点:
一致性哈希算法
假设我们有k个机器,数据的哈希值的范围是 [0, MAX] 。我们将整个范围划分成 m 个小区间( m 远大于 k ),每个机器负责 m/k 个小区间。当有新机器加入的时候, 我们就将某几个小区间的数据,从原来的机器中搬移到新的机器中。这样,既不用全部重新哈希、搬移数据,也保持了各个机器上数据数量的均衡。
参考文章
https://www.bilibili.com/video/av25184175?from=search&seid=10220130562591473572
https://zhuanlan.zhihu.com/p/57988082