深度强化学习
深度强化学习
1.机器学习
要提深度强化学习,首先就要提机器学习,机器学习主要分为三类,监督学习,无监督的学习和强化学习。

监督学习

如果在学习过程中,我们不断向计算机提供数据和这些数据所对应的值,比如说给计算机看猫和狗的照片,告诉计算机哪些图片里的是猫,哪些是狗,然后让它去学习去分辨猫和狗,通过这些指引的方式,让计算机学习我们是如何把这些图片数据对应上图片所代表的物品,也就是让计算机学习这些标签可以代表哪些图片,这种学习方式叫做监督学习。预测房屋的价格,股票的涨停同样可以用监督学习来实现,我们所熟知的神经网络同样是一种监督学习的方式。
无监督的学习

如果同样在这种学习过程中,我们只给计算机提供猫和狗的图片,但是并没有告诉它哪些是猫,哪些是狗,取而代之的是让它自己去判断和分类,让它自己总结出这两种类型的图片的不同之处,这就是一种非监督学习。在这一种学习中,我们可以不用提供数据对应的标签信息,计算机观察各种数据之间的特性,会发现这些特性背后的规律,这些规律也就是非监督学习所学到的东西。
强化学习

强化学习就是把计算机丢到一个对于它完全陌生的环境,或者让它完成一项从未接触过的任务, 它自己会去尝试各种手段,最后让自己成功适应这一陌生的环境或者学会完成这件任务的方法途径。比如说我想训练一个机器人去投篮,我只需要个它一个球,并告诉它你投进了我给你记一分,让它自己去尝试各种各样的投篮方法,在开始阶段,它的命中率可能会非常低,不过它会向人类一样,自己总结和学习投篮成功或失败的经验,最终达到很高的命中率。Google开发的AlphaGo也是应用了这一种学习方式。
2.背景
近几年来,深度学习在一系列领域里大放异彩,大幅超越了一些传统的方法,包括物体识别,文字理解,语言识别等等,我们把这类应用归于一类相似的问题,叫做低层次的感知问题,给定图像语音这样低层次的输入,深度学习可以帮助我们得到一个高层次的表达,但这对我们来说是不够的,人类最重要的能力是会思考,换句话来说我们也想让机器基于这些感知信息作出一些复杂的决策,
举个例子来说,为了玩好魂斗罗游戏,机器首先需要理解当前的图像内容,基于当前的游戏内容,它还要学会在游戏中的正确时机发出正确的操作指令,在右边的机器人导航问题中,机器人也必须对于周围的感知作出各种关系高层次决策。

 下面首先我会介绍一下深度学习,然后我会介绍RL的框架和一系列方法,最后会介绍深度强化学习对于传统RL的一些拓展。
下面首先我会介绍一下深度学习,然后我会介绍RL的框架和一系列方法,最后会介绍深度强化学习对于传统RL的一些拓展。
3.深度学习
深度学习是机器学习中一种基于对数据进行表征学习的方法。观测值(例如一幅图像)可以使用多种方式来表示,如每个像素强度值的向量,或者更抽象地表示成一系列边、特定形状的区域等。而使用某些特定的表示方法更容易从实例中学习任务(例如,人脸识别或面部表情识别)。深度学习的好处是用非监督式或半监督式的特征学习和分层特征提取高效算法来替代手工获取特征。
那么一个深度神经网络通常由以下几部分组成,我们会有线性的函数,比如说矩阵乘法;也会有非线性的激活函数,这样可以增强模型的表达能力。为了拟合我们的模型,我们还会有一个损失函数去定义我们模型的输出和真实的标签距离有多远,根据这个信息,我们就能优化我们的模型去渐渐的逼近目标。
梯度下降法

深度学习当中,需要使用大量的样本进行训练,数据量越大,得到的模型就越不可能出现过拟合的问题。也就是说每个样本都要计算梯度,然后更新网络的参数。对于上百万甚至上亿的数据进行学习是不可能被接受的。因此,随机梯度下降法就是为了解决这个问题而出现的。
首先来看看梯度下降的一个直观的解释。比如我们在一座大山上的某处位置,由于我们不知道怎么下山,于是决定走一步算一步,也就是在每走到一个位置的时候,求解当前位置的梯度,沿着梯度的负方向,也就是当前最陡峭的位置向下走一步,然后继续求解当前位置梯度,向这一步所在位置沿着最陡峭最易下山的位置走一步。这样一步步的走下去,一直走到觉得我们已经到了山脚。当然这样走下去,有可能我们不能走到山脚,而是到了某一个局部的山峰低处。
在这里我也列出了一些常用的深度学习模型,第一个模型叫做MLPs,就是在MLP里面两个不同层次的神经元之间只有全连接层。全连接层对于高位数据的扩展性很差,因为冗余连接太多,模型参数很快就会太大;针对于高位数据特别是图像,大家又提出了卷积神经网络CNN,通过局部连接来共享模型参数,还有一类针对有时间维度数据提出的RNN模型,是通过共享不同时间点上的参数来减少参数的体积。
深度学习的缺陷
深度学习作为一种有监督学习方法有着自己的局限性,在有监督学习中,标数据是一个费事费力的工作,尤其是一个无比庞大的数据集,而且现实生活中的很多问题都有一个和环境交互的过程,这就意味着我们得到的数据具有很强的相关性。
4.强化学习
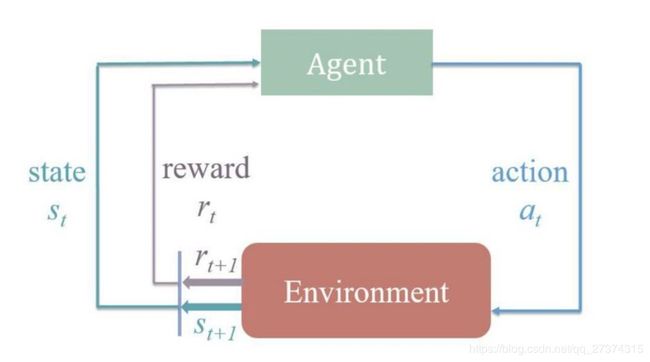
不同于有监督的学习框架,增强学习(RL)提供了一个更通用的框架去标书这类决策问题,相较于机器学习经典的有监督学习、无监督学习问题,强化学习最大的特点是在交互中学习,在强化学习中,我们用agent指代我们最终想实现的人工智能,在一个潜在的environment中不断交互,在机器人导航例子里,environment可以看成机器人周围的环境,在每个时间点上,agent可以采取一个action,environment接收到这个action后,会返回给agent一个state,同时返回一个reward来评估agent这个采取的action到底是好还是不好,最终的目标是选取一系列action以实现最大化奖励,这实际上是一个非常通用的框架,很多现实生活中的问题比如玩游戏,机器人控制都可以表述在这类框架下。
MDPs
下面介绍强化学习完整的框架,我们首先从介绍马尔科夫决策过程开始,MDP从数学的角度去描述了RL里面agent和environment交互的过程,我们采用下面的定义:
S:环境状态空间
P:状态转移的概率分布,实际上用P(r,s′|s,a)来表示
A:动作空间
γ:折扣因子
R:奖励值或者是奖励值函数
首先S表示环境状态空间,在MDP里面,我们首先假设environment是可以完全被感知的,这个意思就是说只要知道当前时间点的转态,那么一切之前的状态对我们来说都不在重要了,未来的状态就只会和当前的状态相关,第二个我们会有一个Action space,就是agent可以采取的所有action的集合,然后我们会有一个P来表示状态转移的概率分布,可以根据当前状态s和动作a预测下一个状态s_。还有一个R代表奖励值或者奖励函数。每个状态对应一个值,或者一个状态-动作对对应于一个奖励值。γ表示折扣因子,是一个0-1之间的数。一般根据时间的延长作用越来越小,表明越远的奖励对当前的贡献越少。
另外对于策略π还需要说明一点。
一个策略指的是agent的行为
如果是一个随机的策略,那么π就表示一个概率分布 P(a|s)= π(s|a)
如果是一个决定性的策略,那么π就表示一个从状态到动作的映射 a= π(s)
值函数
我们知道在强化学习中往往有延迟回报的特点,也就是前面所说的标签延迟的学习算法。以下棋为例,下一步棋后,除非这一步棋就是最后一步棋了,否则无法知道这一步对后面的影响。如果知道每一个状态的好坏,那么最好的策略就是朝着这些好的状态行走。所以,定义在某种策略情况下的一个函数来表明当前的状态下所做的策略对长远的影响,也就是用它来衡量该状态的好坏程度,这个函数被称作值函数,或者效用函数。值函数有两种表示,一种叫做state value function, 通常用V来表示
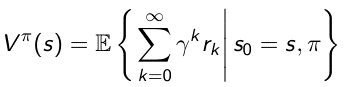
另一种叫state-action value function,通常用Q function来表示,

两者的主要区别在于两者条件期望的依赖不一样,status-value function只依赖于s但action-value function同事依赖于当前时间点的状态s和当前采取的action。两者的关系可以通过期望的公式来表示出来。
status-value function其表达式为:vπ(s)=Eπ[Gt|St=s]。上述值函数表示为当前状态到无穷远的状态的累计奖励值。如果加上一个折扣因子γ来衡量奖励值在值函数当中的作用的大小。离当前距离越远的奖励值的作用应该越小,(例如在一场跑步比赛当中距离终点很远的一个状态只要朝着目标前进,它的奖励值也会很大,但是这显然不合理,因此折扣因子的引入,是的离它较远的状态给它的奖励贡献是比较小的。)因此可以得到如下公式:
我们可以从另一个角度来理解上式,下面是动作执行的整个过程,表示的就是各个状态之间通过动作进行转换。
S0->s1->….
经过上面的转移路劲之后,可以得到从初始奖励开始行动的累积奖励,也就是将整个状态转移过程中所有的奖励值R(s,a)加起来,但是考虑到越远的奖励值对当前状态的值函数贡献越小,因此乘以折扣因子r就可以得出:
V(s)=R(s0,a0)+rR(s1,a1)+…
如果不考虑智能体采取什么样的动作从s0状态到达s1状态,那么值函数就可以表示为一种只与s有关的函数:
V(s)=R(s0)+rR(s1)+…
因此,强化学习的目标就是选择一组最佳的动作,使得全部的回报加权和期望最大。这个期望的奖励的累计奖励值就可以通过值函数来衡量。(值函数是一个累积的量,在算法当中迭代的次数越多越接近真实值。)
下面我们将介绍解决RL问题的常用算法,RL算法有很多种不同的分类,下面我们采用如下的方法将RL算法分为三类。
动态规划算法(DP)
动态规划算法分为两个过程:策略评估和策略更新,
在策略评估过程中,每一个迭代都会在当前的策略中去更新各个状态的值函数,如果达到迭代的次数或者是值函数已经收敛就不再进行迭代;
在策略更新过程中,使用当前的策略再去更新各个状态的值函数,然后再得到当前的最优策略,直到策略不再发生改变,结束策略迭代,返回最优策略。
动态规划的典型方法:策略迭代:策略迭代就是采用策略评估和策略更新不断交替,直到策略没有在发生改变,就可以结束策略迭代得到最终的结果。
值迭代:策略迭代包括策略评估和策略更新两个过程,如果策略空间非常大,那么策略评估是非常耗时的。并且经过观察知道,策略的改进和值函数的改进是一致的。因此在每一个的值迭代中都可以找到让当前的值函数最大的更新方式,并且用这种方式来更新值函数。不断更新迭代,直到值函数不再发生变化。
前面我们介绍了有模型的强化学习问题的求解,就是基于动态规划算法的求解。主要的方式是通过状态转移到下一个状态,然后使用Bellman方程进行求解。
蒙特卡洛算法(MC)
在无模型的强化学习的情况下,策略迭代算法会遇到如下几个问题:首先,策略无法评估,因为无法做全概率展开。此时只能通过在环境中执行相应的动作观察绕的奖励和转移的状态。一种直接的策略评估替代方法就是“采样”,然后求平均累积奖励,作为期望累积奖励的近似,这种方法称为“蒙特卡洛方法”。
在蒙特卡洛算法中不需要知道状态转移的概率分布,但是必须要当环境到了停止状态下才能有关于value function的估计,即agent必须一直和environment交互直至environment达到停止的状态。
关于蒙特卡洛最直接的应用就是用它来进行圆周率的估计。为了估计π的大小,在正方形内随机生成点,利用正方形两部分内点的个数的比例就可以估计出π的大小。
相对于蒙特卡洛方法,时间差分算法是一种实时的算法。蒙特卡洛算法通过对样本轨迹进行采样克服了未知模型造成的困难,将一个无模型的强化学习问题转化成一个有模型的强化学习问题进行求解。显然,采样越精细得到的结果越准确。但是,蒙特卡洛算法并没有利用MDP模型在强化学习中的优势,导致蒙特卡洛算法的计算效率很低。于是,将蒙特卡洛算法结合马尔科夫决策过程变构成了时序差分强化学习算法。
TD和MC一样也是直接从环境中学习,并且也是无模型的,TD可以从不完整的时间片段中学习,(这样的话agent在environment中每交互一步。我们都可以用这一步的数据去更新当前对value function 的估计,这样子的话在很多情况下都可以收敛更快。但是TD的方法没有很大的理论保证,一般来说他的估计是有偏差的。但是在实际中它的效果还可以,因为他的variance比较小。
强化学习的学习过程实质是在不断更新一张表的过程。这张表一般称之为Q_Table,此张表由State和Action作为横纵轴,每一个格就代表在当前State下执行当前Action能获得的价值回馈,用Q(s,a)表示,称为Q值。获得整个决策过程最优的价值回馈的决策链是唯一的,完善了此张表,也就完成了Agent的学习过程。但是传统的RL方法大都限于低维的状态空间或者手工设置的特征,试想一下,当State和Action的维度都很高时,此张表的维度也会相应非常高,我们不可能获得每一个State下执行Action能获得的Q值,这样在高维度数据下每次去维护Q_Table的做法显然不可行。
5.深度强化学习
Q Learning
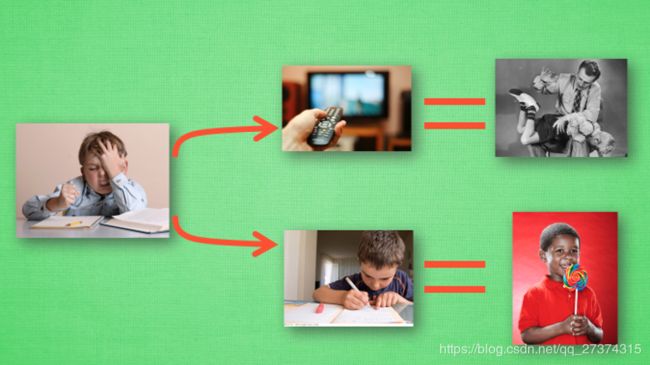
我们做事情都会有一个自己的行为准则, 比如小时候爸妈常说”不写完作业就不准看电视”. 所以我们在 写作业的这种状态下, 好的行为就是继续写作业, 直到写完它, 我们还可以得到奖励, 不好的行为 就是没写完就跑去看电视了, 被爸妈发现, 后果很严重. 小时候这种事情做多了, 也就变成我们不可磨灭的记忆. 这和我们要提到的 Q learning 有什么关系呢? 原来 Q learning 也是一个决策过程, 和小时候的这种情况差不多. 我们举例说明.
假设现在我们处于写作业的状态而且我们以前并没有尝试过写作业时看电视, 所以现在我们有两种选择 , 1, 继续写作业, 2, 跑去看电视. 因为以前没有被罚过, 所以我选看电视, 然后现在的状态变成了看电视, 我又选了 继续看电视, 接着我还是看电视, 最后爸妈回家, 发现我没写完作业就去看电视了, 狠狠地惩罚了我一次, 我也深刻地记下了这一次经历, 并在我的脑海中将 “没写完作业就看电视” 这种行为更改为负面行为, 我们在看看 Q learning 根据很多这样的经历是如何来决策的吧.
Q-Learning 决策

假设我们的行为准则已经学习好了, 现在我们处于状态s1, 我在写作业, 我有两个行为 a1, a2, 分别是看电视和写作业, 根据我的经验, 在这种 s1 状态下, a2 写作业 带来的潜在奖励要比 a1 看电视高, 这里的潜在奖励我们可以用一个有关于 s 和 a 的 Q 表格代替, 在我的记忆Q表格中, Q(s1, a1)=-2 要小于 Q(s1, a2)=1, 所以我们判断要选择 a2 作为下一个行为. 现在我们的状态更新成 s2 , 我们还是有两个同样的选择, 重复上面的过程, 在行为准则Q 表中寻找 Q(s2, a1) Q(s2, a2) 的值, 并比较他们的大小, 选取较大的一个. 接着根据 a2 我们到达 s3 并在此重复上面的决策过程. Q learning 的方法也就是这样决策的. 看完决策, 我看在来研究一下这张行为准则 Q 表是通过什么样的方式更改、 提升的.
Q Learning更新
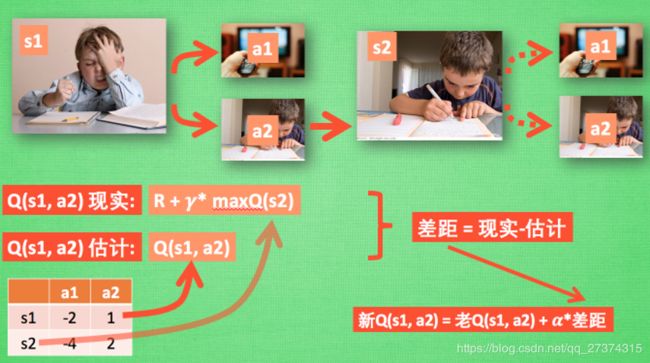
所以我们回到之前的流程, 根据 Q 表的估计, 因为在 s1 中, a2 的值比较大, 通过之前的决策方法, 我们在 s1 采取了 a2, 并到达 s2, 这时我们开始更新用于决策的 Q 表, 接着我们并没有在实际中采取任何行为, 而是再想象自己在 s2 上采取了每种行为, 分别看看两种行为哪一个的 Q 值大, 比如说 Q(s2, a2) 的值比 Q(s2, a1) 的大, 所以我们把大的 Q(s2, a2) 乘上一个衰减值 gamma (比如是0.9) 并加上到达s2时所获取的奖励 R (这里还没有获取到我们的棒棒糖, 所以奖励为 0), 因为会获取实实在在的奖励 R , 我们将这个作为我现实中 Q(s1, a2) 的值, 但是我们之前是根据 Q 表估计 Q(s1, a2) 的值. 所以有了现实和估计值, 我们就能更新Q(s1, a2) , 根据 估计与现实的差距, 将这个差距乘以一个学习效率 alpha 累加上老的 Q(s1, a2) 的值 变成新的值. 但时刻记住, 我们虽然用 maxQ(s2) 估算了一下 s2 状态, 但还没有在 s2 做出任何的行为, s2 的行为决策要等到更新完了以后再重新另外做. 这就是 off-policy 的 Q learning 是如何决策和学习优化决策的过程
Q Learning整体算法
这也是 Q learning 的算法, 每次更新我们都用到了 Q 现实和 Q 估计, 而且 Q learning 的迷人之处就是 在 Q(s1, a2) 现实 中, 也包含了一个 Q(s2) 的最大估计值, 将对下一步的衰减的最大估计和当前所得到的奖励当成这一步的现实, 很奇妙吧. 最后我们来说说这套算法中一些参数的意义. Epsilon greedy 是用在决策上的一种策略, 比如 epsilon = 0.9 时, 就说明有90% 的情况我会按照 Q 表的最优值选择行为, 10% 的时间使用随机选行为. alpha是学习率, 来决定这次的误差有多少是要被学习的, alpha是一个小于1 的数. gamma 是对未来 reward 的衰减值.
Initialize Q(s,a) arbitrarily
Repeat(for each episode):
Initialize s
Repeat (for each step of episode):
Choose a from s using policy derived from Q (e.g.,ɛ-greedy)
Take action a,observe r,s’
Q(s,a) ← Q(s,a) + α[r+γQ(s′,a′)-Q(x,a)]
s ← s’
until s is terminal

我们重写一下 Q(s1) 的公式, 将 Q(s2) 拆开, 因为Q(s2)可以像 Q(s1)一样,是关于Q(s3) 的, 所以可以写成这样, 然后以此类推, 不停地这样写下去, 最后就能写成这样, 可以看出Q(s1) 是有关于之后所有的奖励, 但这些奖励正在衰减, 离 s1 越远的状态衰减越严重. 不好理解? 行, 我们想象 Qlearning 的机器人天生近视眼, gamma = 1 时, 机器人有了一副合适的眼镜, 在 s1 看到的 Q 是未来没有任何衰变的奖励, 也就是机器人能清清楚楚地看到之后所有步的全部价值, 但是当 gamma =0, 近视机器人没了眼镜, 只能摸到眼前的 reward, 同样也就只在乎最近的大奖励, 如果 gamma 从 0 变到 1, 眼镜的度数由浅变深, 对远处的价值看得越清楚, 所以机器人渐渐变得有远见, 不仅仅只看眼前的利益, 也为自己的未来着想.
Sarsa
决策

Sarsa 的决策部分和 Q learning 一模一样, 因为我们使用的是 Q 表的形式决策, 所以我们会在 Q 表中挑选值较大的动作值施加在环境中来换取奖惩. 但是不同的地方在于 Sarsa 的更新方式是不一样的.
更新行为准则

同样, 我们会经历正在写作业的状态 s1, 然后再挑选一个带来最大潜在奖励的动作 a2, 这样我们就到达了 继续写作业状态 s2, 而在这一步, 如果你用的是 Q learning, 你会观看一下在 s2 上选取哪一个动作会带来最大的奖励, 但是在真正要做决定时, 却不一定会选取到那个带来最大奖励的动作, Q-learning 在这一步只是估计了一下接下来的动作值. 而 Sarsa 是实践派, 他说到做到, 在 s2 这一步估算的动作也是接下来要做的动作. 所以 Q(s1, a2) 现实的计算值, 我们也会稍稍改动, 去掉maxQ, 取而代之的是在 s2 上我们实实在在选取的 a2 的 Q 值. 最后像 Q learning 一样, 求出现实和估计的差距 并更新 Q 表里的 Q(s1, a2).
算法对比

从算法来看, 这就是他们两最大的不同之处了. 因为 Sarsa 是说到做到型, 所以我们也叫他 on-policy, 在线学习, 学着自己在做的事情. 而 Q learning 是说到但并不一定做到, 所以它也叫作 Off-policy, 离线学习.
DQN

之前我们所谈论到的强化学习方法都是比较传统的方式, 而如今, 随着机器学习在日常生活中的各种应用, 各种机器学习方法也在融汇, 合并, 升级. 而我们今天所要探讨的强化学习则是这么一种融合了神经网络和 Q learning 的方法, 名字叫做 Deep Q Network. 这种新型结构是为什么被提出来呢? 原来, 传统的表格形式的强化学习有这样一个瓶颈.
神经网络的作用
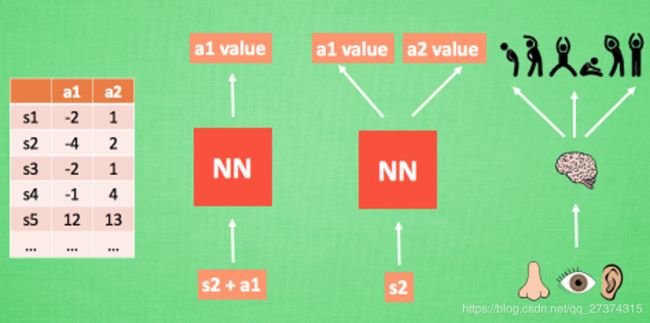
我们使用表格来存储每一个状态 state, 和在这个 state 每个行为 action 所拥有的 Q 值. 而当今问题是在太复杂, 状态可以多到比天上的星星还多(比如下围棋). 如果全用表格来存储它们, 恐怕我们的计算机有再大的内存都不够, 而且每次在这么大的表格中搜索对应的状态也是一件很耗时的事. 不过, 在机器学习中, 有一种方法对这种事情很在行, 那就是神经网络. 我们可以将状态和动作当成神经网络的输入, 然后经过神经网络分析后得到动作的 Q 值, 这样我们就没必要在表格中记录 Q 值, 而是直接使用神经网络生成 Q 值. 还有一种形式的是这样, 我们也能只输入状态值, 输出所有的动作值, 然后按照 Q learning 的原则, 直接选择拥有最大值的动作当做下一步要做的动作. 我们可以想象, 神经网络接受外部的信息, 相当于眼睛鼻子耳朵收集信息, 然后通过大脑加工输出每种动作的值, 最后通过强化学习的方式选择动作.
更新神经网络
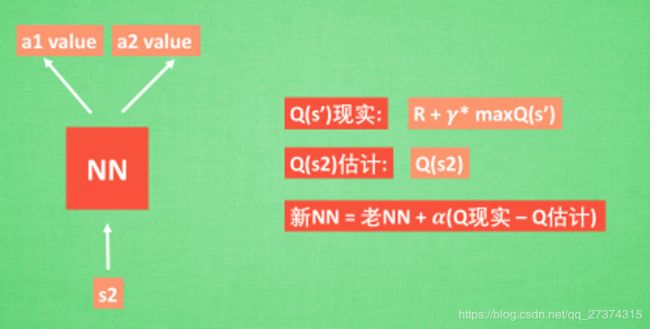
我们知道, 神经网络是要被训练才能预测出准确的值. 那在强化学习中, 神经网络是如何被训练的呢? 首先, 我们需要 a1, a2 正确的Q值, 这个 Q 值我们就用之前在 Q learning 中的 Q 现实来代替. 同样我们还需要一个 Q 估计 来实现神经网络的更新. 所以神经网络的的参数就是老的 NN 参数 加学习率 alpha 乘以 Q 现实 和 Q 估计 的差距. 我们整理一下。
两大利器

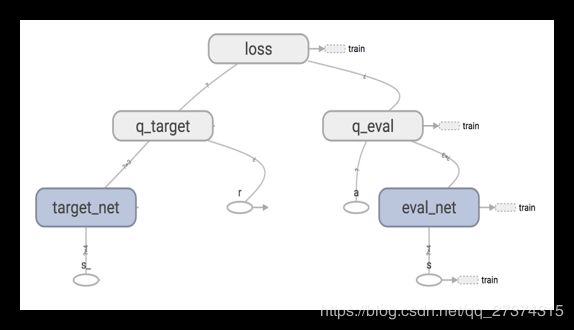
简单来说, DQN 有一个记忆库用于学习之前的经历. 在之前的简介影片中提到过, Q learning 是一种 off-policy 离线学习法, 它能学习当前经历着的, 也能学习过去经历过的, 甚至是学习别人的经历. 所以每次 DQN 更新的时候, 我们都可以随机抽取一些之前的经历进行学习. 随机抽取这种做法打乱了经历之间的相关性, 也使得神经网络更新更有效率. Fixed Q-targets 也是一种打乱相关性的机理, 如果使用 fixed Q-targets, 我们就会在 DQN 中使用到两个结构相同但参数不同的神经网络, 预测 Q 估计 的神经网络具备最新的参数, 而预测 Q 现实 的神经网络使用的参数则是很久以前的. 有了这两种提升手段, DQN 才能在一些游戏中超越人类.