基于DeepDive实现从股权交易公告获取企业与企业之间存在交易关系的概率--实践篇
文章目录
- 实践目标
- 1.示例目录说明
- 2.数据处理
- 2.1 定义原始数据导入数据库表结构
- 2.2 导入数据
- 3. 数据标注
- 3.1 定义处理后的数据存放结构
- 3.1 定义NLP处理函数
- 3.3 说明nlp_markup.sh
- 3.4 运行标注
- 4 实体抽取以及候选实体生成
- 4.1 实体抽取
- 4.2 生成实体对,即要预测关系的两个公司
- 4.3 特征抽取
- 4.4 样本打标
- 5. 模型构建,进行知识推理
- 5.1 变量表定义
- 5.2 因子图构建
- 6.总结
- 6.1 Deepdive知识抽取步骤
- 6.2 Deepdive学习与标注步骤
- 6.3 Deepdive训练原理
实践目标
基于DeepDive 经过 数据处理、数据标注、学习推理和交互迭代步骤实现从股权交易公告数据里面获取企业与企业之间存在交易关系的概率
控制台输入 docker exec -it sanbox_deepdive-notebooks_1 进入deepdive环境
1.示例目录说明
我们将使用 /deepdive-examples/spouse 示例目录,目录文件说明:
| 文件/文件夹名 | 描述 |
|---|---|
| app.ddlog | deepdive的规划文件,此文件定义了数据的来源,数据的结构,数据的处理,KBC的构建。 |
| db.url | 此文件定义了数据库的连接信息 |
| deepdive.conf | deepdive环境配置,不用修改。 |
| input | 此目录放置数据文件,该数据文件需要按照app.ddlog中的规则来命名,该数据文件为应用提供源数据。 |
| udf/ | 存放用户定义的函数的目录,可以从deepdive.conf引用相对于应用程序根目录的路径名 |
修改db.url,修改为本地环境数据库

2.数据处理
2.1 定义原始数据导入数据库表结构
编辑app.ddlog
定义数据库表结构,并且规范数据文件名称
@source
articles(
@key
@distributed_by
id text,
@searchable
content text
).
articles表示一个执行目标,上面代码定义articles的数据结构,包含主键id以及content,该目标首先去input目录下查找以articles开头的数据文件,然后将其按照上面定义的数据格式导入到数据库中。
执行编译命令,每次修改app.ddlog都需要执行编译
deepdive compile
2.2 导入数据
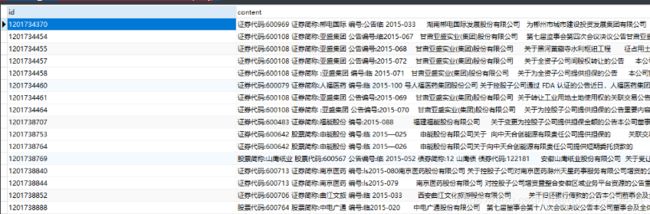
deepdive do articles
表示导入成功,查看数据库articles表如下:
3. 数据标注
我们将使用斯坦福大学的CoreNLP自然语言处理(NLP)系统向输入数据添加有用的标记和结构。此步骤将把我们的文章分成句子和它们的组成标记(大概是单词)。此外,我们还将获得引理(标准化词形式),词性(POS)标签,命名实体识别(NER)标签以及句子的依存关系分析。
3.1 定义处理后的数据存放结构
编辑app.ddlog
@source
sentences(
@key
@distributed_by
# XXX This breaks the search index. @source should not be derived from another @source
#@references(relation="articles", column="id")
doc_id text,
@key
sentence_index int,
@search_type("text[]")
tokens json,
@search_type("text[]")
lemmas json,
@search_type("text[]")
pos_tags json,
@search_type("text[]")
ner_tags json,
@search_type("int[]")
doc_offsets json,
@search_type("text[]")
dep_types json,
@search_type("int[]")
dep_tokens json
).
| 字段名 | 字段解释 |
|---|---|
| doc_id | doc_id表示的是articles表中公告对应的id |
| sentence_index | sentence_index表示的是公司所在的句子在文章中对应的索引 |
| tokens | tokens的结构如下:1: “证券”,其中1是分词的索引,“证券”是分词的内容 |
| lemmas | lemmas与pos_tag、ner_tags、dep_types和tokens的结构是一样的,表示词元 |
| pos_tags | pos_tags表示的是句子的词性 |
| ner_tags | ner_tags表示的是实体类型的识别,如果是公司则表示为“ORG” |
| doc_offsets | doc_offsets表示的是每个分词在文章中的开始位置的索引 |
| dep_types | dep_types表示的是每个分词的句法结构 |
3.1 定义NLP处理函数
编辑app.ddlog
该函数遵守ddlog的语法规则。需要在
udf目录下创建nlp_markup.sh脚本文件,里面包含对内容的处理逻辑。
function nlp_markup over (
doc_id text,
content text
) returns rows like sentences
implementation "udf/nlp_markup.sh" handles tsj lines.
sentences += nlp_markup(doc_id, content) :-
articles(doc_id, content).
function用来定义函数,后面
nlp_markup是函数名 over后面接的是参数表。
returns 说明了函数返回的形式,返回就像我们前面定义的sentences那样的一行。
最后一句说明了我们这个程序文件是udf/nlp_markup.sh,输入是tsv的一行说明:上面的
+=其实和其他语言差不多,就是对于来源是articles中的每一行的doc_id和content我们都调用nlp_markup然后结果添加到sentences表中。
3.3 说明nlp_markup.sh
#!/usr/bin/env bash
# A shell script that runs Bazaar/Parser over documents passed as input TSV lines
#
# $ deepdive env udf/nlp_markup.sh doc_id _ _ content _
##
set -euo pipefail
cd "$(dirname "$0")"
: ${BAZAAR_HOME:=$PWD/bazaar}
[[ -x "$BAZAAR_HOME"/parser/target/start ]] || {
echo "No Bazaar/Parser set up at: $BAZAAR_HOME/parser"
exit 2
} >&2
[[ $# -gt 0 ]] ||
# default column order of input TSV
set -- doc_id content
# convert input tsv lines into JSON lines for Bazaar/Parser
# start Bazaar/Parser to emit sentences TSV
tsv2json "$@" |
"$BAZAAR_HOME"/parser/run.sh -i json -k doc_id -v content
所有#开头的(除了#!)都是普通注释
参数的用法(
- $0:调用文件使用的文件名,带有前面的路径,
- $1-∞:传给脚本的各个参数,
- @ , @, @,*:这两个都表示传入的所有参数,
- $#:表示传入参数的个数)
第一行指定了脚本的执行程序
第六行指定了一些程序的错误处理方式等(详见Shell相关文档)
第七行改变当前目录到nlp_markup.py所在目录,也就是udf目录
第九行设置了一个变量BAZZER_HOME他的值是bazaar的路径
第10-13行执行/parser/target/start文件,如果有错会不正常退出,并提示
第15-17行检查输入参数的正确性,看参数个数是不是大于0个,如果没有参数,自己设定参数名
第23-24行把全部输入的参数用tsv2json工具转换成json格式,然后在执行parser/run.sh并以刚才的json作为参数输入。
3.4 运行标注
控制台输入以下命令执行处理函数:
deepdive do sentences
一开始会报错
2020-03-25 20:18:43.677869 Exception in thread "main" Error: A JNI error has occurred, please check your installation and try again
2020-03-25 20:18:43.678557 Exception in thread "main" java.lang.NoClassDefFoundError: scala/Function0
2020-03-25 20:18:43.678739 at java.lang.Class.getDeclaredMethods0(Native Method)
2020-03-25 20:18:43.678798 at java.lang.Class.privateGetDeclaredMethods(Class.java:2701)
2020-03-25 20:18:43.678856 at java.lang.Class.privateGetMethodRecursive(Class.java:3048)
2020-03-25 20:18:43.678957 at java.lang.Class.getMethod0(Class.java:3018)
2020-03-25 20:18:43.678986 at java.lang.Class.getMethod(Class.java:1784)
2020-03-25 20:18:43.679003 at sun.launcher.LauncherHelper.validateMainClass(LauncherHelper.java:544)
2020-03-25 20:18:43.679019 at sun.launcher.LauncherHelper.checkAndLoadMain(LauncherHelper.java:526)
2020-03-25 20:18:43.679124 Caused by: java.lang.ClassNotFoundException: scala.Function0
2020-03-25 20:18:43.679160 at java.net.URLClassLoader.findClass(URLClassLoader.java:382)
2020-03-25 20:18:43.679178 at java.lang.ClassLoader.loadClass(ClassLoader.java:419)
2020-03-25 20:18:43.679247 at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:352)
2020-03-25 20:18:43.679283 at java.lang.ClassLoader.loadClass(ClassLoader.java:352)
2020-03-25 20:18:43.679301 ... 7 more
需要进行编译nlp处理器,执行以下命令
cd ~/CNdeepdive/transaction/udf/bazaar/parser
sbt/sbt stage
重新执行 deepdive compile && deepdive do sentences
这一段会很慢,所以想快点就删数据吧。
tips: 可以看到sentences给出的plan中包含articles表的执行。plan中前面有冒号的行表示默认已经执行,不会重做,否则将要生成。如果articles有更新,需要重新deepdive redo articles或者用deepdive mark todo articles来将articles标记为未执行,这样在生成sentences的过程中就会默认更新articles了。
在数据库sentences表可以看到解析结果

4 实体抽取以及候选实体生成
4.1 实体抽取
- 实体数据表定义
每个实体都是表中的一列数据,同时存储了实体在句中的起始位置和结束位置。
@extraction
company_mention(
@key
mention_id text,
@searchable
mention_text text,
@distributed_by
@references(relation="sentences", column="doc_id", alias="appears_in")
doc_id text,
@references(relation="sentences", column="doc_id", alias="appears_in")
sentence_index int,
begin_index int,
end_index int
).
- 实体抽取函数
定义实体抽取函数
function map_company_mention over (
doc_id text,
sentence_index int,
tokens text[],
ner_tags text[]
) returns rows like company_mention
implementation "udf/map_company_mention.py" handles tsv lines.
map_company_mention.py见样例。这个脚本遍历每个数据库中的句子,找出连续的NER标记为ORG的序列,再做其它过滤处理,其它脚本也要复制过去。这个脚本是一个生成函数,用yield语句返回输出行。
- 调用函数定义:
company_mention += map_company_mention(
doc_id, sentence_index, tokens, ner_tags
) :-
sentences(doc_id, sentence_index, _, tokens, _, _, ner_tags, _, _, _).
- 执行实体抽取
修改~/udf/transform.py
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1vYOGoOv-1585289391176)(C:\Users\lps\Documents\myblog\deepdive\DeepDiveSAMPLE.assets\image-20200326161451669.png)]](http://img.e-com-net.com/image/info8/c58c69b896a24372a9525847e581da8c.jpg)
控制台输入:
deepdive compile && deepdive do company_mention
查看具体解析实体列表如下:

4.2 生成实体对,即要预测关系的两个公司
- 实体对表结构定义
transaction_candidate(
p1_id text,
p1_name text,
p2_id text,
p2_name text
).
-
统计每个句子的实体数:
num_company(doc_id, sentence_index, COUNT§) :-
company_mention(p, _, doc_id, sentence_index, _, _). -
定义过滤函数:
function map_transaction_candidate over ( p1_id text, p1_name text, p2_id text, p2_name text ) returns rows like transaction_candidate implementation "udf/map_transaction_candidate.py" handles tsv lines. -
描述函数的调用:
transaction_candidate += map_transaction_candidate(p1, p1_name, p2, p2_name) :- num_company(same_doc, same_sentence, num_p), company_mention(p1, p1_name, same_doc, same_sentence, p1_begin, _), company_mention(p2, p2_name, same_doc, same_sentence, p2_begin, _), num_p < 5, p1_name != p2_name, p1_begin != p2_begin.
一些简单的过滤操作可以直接通过app.ddlog中的数据库语法执行,比如p1_name != p2_name,过滤掉两个相同实体组成的实体对。
- 编译并执行:
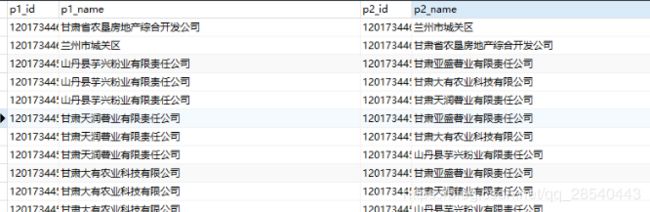
deepdive compile && deepdive do transaction_candidate
生成候选实体表。
4.3 特征抽取
这一步我们抽取候选实体对的文本特征。
(1). 定义特征表:
transaction_feature(
p1_id text,
p2_id text,
feature text
)
这里的feature列是实体对间一系列文本特征的集合。
(2). 生成feature表需要的输入为实体对表和文本表,输入和输出属性在app.ddlog中定义如下:
function extract_transaction_features over (
p1_id text,
p2_id text,
p1_begin_index int,
p1_end_index int,
p2_begin_index int,
p2_end_index int,
doc_id text,
sent_index int,
tokens text[],
lemmas text[],
pos_tags text[],
ner_tags text[],
dep_types text[],
dep_tokens int[]
) returns rows like transaction_feature
implementation "udf/extract_transaction_features.py" handles tsv lines.
- 函数调用extract_transaction_features.py来抽取特征。这里调用了deepdive自带的ddlib库,得到各种POS/NER/词序列的窗口特征。此处也可以自定义特征。
(3).把sentences表和mention表做join,得到的结果输入函数,输出到transaction_feature表中。
transaction_feature += extract_transaction_features(
p1_id, p2_id, p1_begin_index, p1_end_index, p2_begin_index, p2_end_index,
doc_id, sent_index, tokens, lemmas, pos_tags, ner_tags, dep_types, dep_tokens
) :-
company_mention(p1_id, _, doc_id, sent_index, p1_begin_index, p1_end_index),
company_mention(p2_id, _, doc_id, sent_index, p2_begin_index, p2_end_index),
sentences(doc_id, sent_index, _, tokens, lemmas, pos_tags, ner_tags, _, dep_types, dep_tokens).
(4). 然后编译并执行,生成特征数据库:
deepdive compile && deepdive do transaction_feature
执行如下语句,查看生成结果:
deepdive query '| 20 ?- transaction_feature(_, _, feature).'
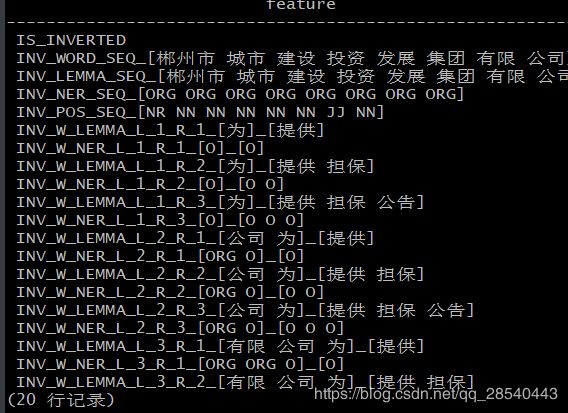
现在,我们已经有了想要判定关系的实体对和它们的特征集合。
4.4 样本打标
这一步,我们希望在候选实体对中标出部分正负例。
- 利用已知的实体对和候选实体对关联
- 利用规则打部分正负标签
(1). 首先在app.ddlog里定义transaction_label表,存储监督数据:
@extraction
transaction_label(
@key
@references(relation="has_transaction", column="p1_id", alias="has_transaction")
p1_id text,
@key
@references(relation="has_transaction", column="p2_id", alias="has_transaction")
p2_id text,
@navigable
label int,
@navigable
rule_id text
).
rule_id代表在标记决定相关性的规则名称。label为正值表示正相关,负值表示负相关。绝对值越大,相关性越大。
(2). 初始化定义,复制transaction_candidate表,label均定义为零。
transaction_label(p1, p2, 0, NULL) :- transaction_candidate(p1, _, p2, _).
(3).将前面准备的db数据导入transaction_label表中,rule_id标记为"from_dbdata"。因为国泰安的数据比较官方,可以基于较高的权重,这里设为3。在app.ddlog中定义如下:
transaction_label(p1,p2, 3, "from_dbdata") :-
transaction_candidate(p1, p1_name, p2, p2_name), transaction_dbdata(n1, n2),
[ lower(n1) = lower(p1_name), lower(n2) = lower(p2_name) ;
lower(n2) = lower(p1_name), lower(n1) = lower(p2_name) ].
(4). 如果只利用下载的实体对,可能和未知文本中提取的实体对重合度较小,不利于特征参数推导。因此可以通过一些逻辑规则,对未知文本进行预标记。
function supervise over (
p1_id text, p1_begin int, p1_end int,
p2_id text, p2_begin int, p2_end int,
doc_id text,
sentence_index int,
sentence_text text,
tokens text[],
lemmas text[],
pos_tags text[],
ner_tags text[],
dep_types text[],
dep_tokens int[]
) returns (
p1_id text, p2_id text, label int, rule_id text
)
implementation "udf/supervise_transaction.py" handles tsv lines.
- 输入候选实体对的关联文本,定义打标函数
- 函数调用udf/supervise_transaction.py,规则名称和所占的权重定义在脚本中。在app.ddlog中定义标记函数。
(5). 调用标记函数,将规则抽到的数据写入transaction_label表中。
transaction_label += supervise(
p1_id, p1_begin, p1_end,
p2_id, p2_begin, p2_end,
doc_id, sentence_index, sentence_text,
tokens, lemmas, pos_tags, ner_tags, dep_types, dep_token_indexes
) :-
transaction_candidate(p1_id, _, p2_id, _),
company_mention(p1_id, p1_text, doc_id, sentence_index, p1_begin, p1_end),
company_mention(p2_id, p2_text, _, _, p2_begin, p2_end),
sentences(
doc_id, sentence_index, sentence_text,
tokens, lemmas, pos_tags, ner_tags, _, dep_types, dep_token_indexes
).
(6). 不同的规则可能覆盖了相同的实体对,从未给出不同甚至相反的label。建立transaction_label_resolved表,统一实体对间的label。利用label求和,在多条规则和知识库标记的结果中,为每对实体做vote。
transaction_label_resolved(p1_id, p2_id, SUM(vote)) :-transaction_label(p1_id, p2_id, vote, rule_id).
(7). 执行以下命令,得到最终标签。
deepdive do transaction_label_resolved
5. 模型构建,进行知识推理
通过前面步骤,我们已经得到了所有前期需要准备的数据。下面可以构建模型了。
5.1 变量表定义
(1). 定义最终存储的表格,『?』表示此表是用户模式下的变量表,即需要推导关系的表。这里我们预测的是公司间是否存在交易关系。
@extraction
has_transaction?(
p1_id text,
p2_id text
).
(2). 根据打标的结果,灌入已知的变量
has_transaction(p1_id, p2_id) = if l > 0 then TRUE
else if l < 0 then FALSE
else NULL end :- transaction_label_resolved(p1_id, p2_id, l).
此时变量表中的部分变量label已知,成为了先验变量。
(3). 最后编译执行决策表:
$ deepdive compile && deepdive do has_transaction
5.2 因子图构建
(1). 指定特征
将每一对has_transaction中的实体对和特征表连接起来,通过特征factor的连接,全局学习这些特征的权重。在app.ddlog中定义:
@weight(f)
has_transaction(p1_id, p2_id) :-
transaction_candidate(p1_id, _, p2_id, _),
transaction_feature(p1_id, p2_id, f).
(2). 指定变量间的依赖性
我们可以指定两张变量表间遵守的规则,并给这个规则以权重。比如c1和c2有交易,可以推出c2和c1也有交易。这是一条可以确保的定理,因此给予较高权重:
@weight(3.0)
has_transaction(p1_id, p2_id) => has_transaction(p2_id, p1_id) :-
transaction_candidate(p1_id, _, p2_id, _).
变量表间的依赖性使得deepdive很好地支持了多关系下的抽取。
(3). 最后,编译,并生成最终的概率模型:
deepdive compile && deepdive do probabilities
假如出现报错:
pbzip2: error while loading shared libraries: libbz2.so.1.0: cannot open shared object file: No such file or directory
解决方案:建立libbz2.so.10软连接
cd /usr/lib64/
ls -alhtr | grep libbz2.so.1
ln -s libbz2.so.1.0.6 libbz2.so.1.0
ls -alhtr | grep libbz2.so.1
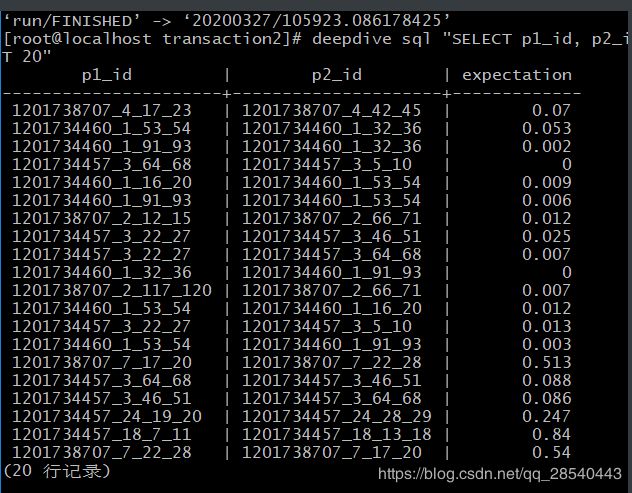
查看我们预测的公司间交易关系概率:
deepdive sql "SELECT p1_id, p2_id, expectation FROM has_transaction_label_inference ORDER BY random() LIMIT 20"
至此,我们的交易关系抽取就基本完成了。更多详细说明请见http://deepdive.stanford.edu
6.总结
经过实践可以得出:
6.1 Deepdive知识抽取步骤
一种基于Deepdive的领域文本知识抽取方法,包括以下步骤:
(1) 获取知识库构建系统所需的原始文本,并且采用jieba工具对原始文本分词, 并采用斯坦福的core NLP工具对分词后的文本进行词性标注、命名实体标注以及语法依 赖处理,得到预处理后的文本数据;
(2)对预处理后的文本数据进行实体连接,找到与预设特定关系对应的目标实体,并生成满足实体-关系-实体的三元组,组成候选关系实体对集;
(3)采用弱监督的方法对候选关系实体对集中的多个候选关系实体对进行学习和标注,生成大量的候选关系实体对作为Deepdive工具的训练样本,并将训练样本中候选关系实体对对应的关系组成的关系集作为真值标签;
⑷将训练样本和真值标签输入至Deepdive工具中,以目标函数y最大为目标,对 Deepdive进行训练,并输出概率值大于阈值的候选关系实体对,组成提取的知识库。
步骤(2)中,知识库构建的原始数据是非结构化的文本数据对象,通过特定的本 体和先验知识,从中提取出所需要的知识三元组。候选关系实体对的获取通过构建一个映射表和简单的判断规则来得到,例如对于公司类的实体,需要去除一些后缀词汇例如“股份”、“有限”等。
6.2 Deepdive学习与标注步骤
使用弱监督方法对候选关系实体对进行学习与标注的具体步骤包括:
(1) 候选关系实体对集中的候选关系实体对标注为正例,采用负抽样方法获得反例;
(2)使用规则进行弱监督,对于大多数垂直领域,领域专家都有相应的规则来表达某些特定的关系,因此可以利用相似的语法结构来制定相应的规则从而检测某些语句 是否表达某一特定关系,并且将这些数据标注为正例;
(3)不断迭代步骤(2),直到满足迭代次数或获得足够多的候选关系实体为止,输出最后得到的所有候选关系实体。
(4)不同于传统的基于规则提取的方法,Deepdive提供了一套更健壮性的特征提取的方法来获取目标知识三元组。
6.3 Deepdive训练原理
Deepdive进行训练的过程为:
(1) 首先,Deepdive内建的特征库处理训练样本中候选关系实体对的上下文,从上下文的分词结果、语法依赖、词性标注结果中提取词语的nGram特性和词性标签;
(2) 然后,根据提取的nGram特性和词性标签以及训练样本,采用Factor Graph进行图概率的统计推理和知识学习,得到概率值大于阈值的候选关系实体对,组成提取的知识库。
参考资料:
https://www.ljjyy.com/archives/2019/10/100595.html#2-%E7%BC%96%E8%AF%91%E5%8F%8A%E7%94%9F%E6%88%90%E6%95%B0%E6%8D%AE%E8%A1%A8
https://patents.google.com/patent/CN107169079A/zh
推荐阅读:
基于DeepDive实现从股权交易公告获取企业与企业之间存在交易关系的概率–解析篇