kaggle之房价分析与预测
数据
kaggle地址:https://www.kaggle.com/c/house-prices-advanced-regression-techniques
不能的同学可以去我的资源里下
数据分析
一、合并数据集
在此我将训练集和测试集合并到一个数据集中,仅在机器学习时将它俩分开。
先导入要使用的包,这里使用的是seaborn,会把matplotlib的样式覆盖。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
数据合并
sample_sub = pd.read_csv('./data/sample_submission.csv')
test_data = pd.read_csv('./data/test.csv')
train_data = pd.read_csv('./data/train.csv')
test_data = pd.merge(test_data, sample_sub, on=['Id'])
data = train_data.append(test_data, ignore_index=True)
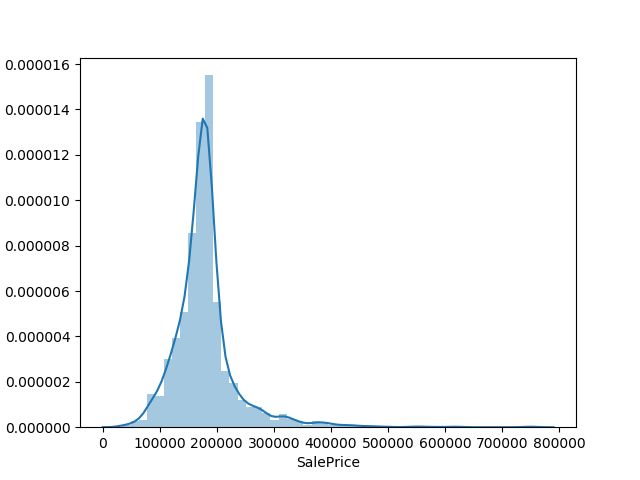
二、房价直方图
使用的是seaborn
data = self.merge_data()
sns.distplot(data['SalePrice'])
plt.savefig('./pic/price_map.png')
plt.show()
结果:
三、特征进行预处理
1.先打开csv文件看一下数据概况,发现该数据集有个别数据存在大量的空值,因此需要把这部分数据删除。先把训练集中的‘NA’替换为方便操作的np.nan类型,然后统计各特征中空值占的比例
train_data.replace('NA',np.nan)
na_data = train_data.apply(lambda col:sum(col.isnull())/col.size)
# 选出nan占比过多的特征
na_data = na_data[na_data>=0.3]
print(na_data.index)
train_data.drop(na_data.index,axis=1, inplace=True)
结果如下,以下5个特征直接删除,不考虑。

![]()
2.对数值类特征和非数值类特征进行分别处理,非数值类特征在加入np.nan后会整体显示为‘object’类型,使用dtypes区分。
data.drop('Id', axis=1, inplace=True)
# 选出data中数字列,替换nan
se_data_type = data.dtypes
type_index = se_data_type[se_data_type != 'object'].index
data[type_index] = data[type_index].replace(np.nan, data[type_index].mean())
data.dropna(axis=0, inplace=True)
3.对处理完的数据进行one-hot编码,由于get_dummies在接收dataframe数据时需要接收columns(不加columns会报type error),所以要先把需要编码的列名提取出来生成列表。
list_index = [i for i in se_data_type[se_data_type == 'object'].index]
ode_data = pd.get_dummies(new_data,columns=list_index)
4.线性回归
把数据集分为训练集和测试集,调用sklearn的LinearRegression进行拟合。
data = self.one_hot(self.del_na())
X=data.drop('SalePrice', axis=1)
y=data['SalePrice']
train_X, test_X, train_y, test_y = train_test_split(X,y)
# 线性回归
lr = LinearRegression()
lr.fit(train_X, train_y)
# 预测
y_pre = lr.predict(test_X)
print('准确率:', lr.score(test_X, test_y))
得到结果:
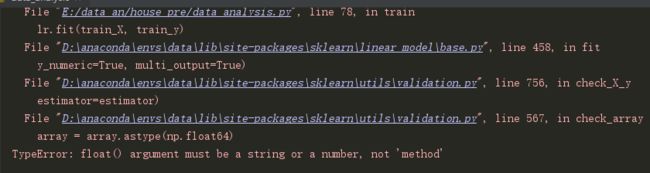
在拟合的时候出错,然后上百度搜了半天没找到一个有用的(laji百度),后来在stackoverflow上看见一个差不多的bug,我用dtypes显示dataframe各列的类型发现部分列是object:
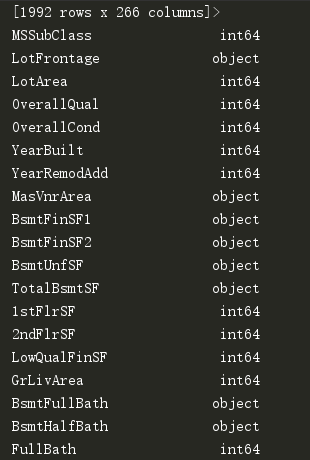
可能是在填充np.nan时填入的数据类型不同导致的。。。。。。在填充mean时少打了括号导致填入了方法(chǔn)
预测结果不是很好,有时会出现负值。
![]()