哈夫曼编码问题再续(下篇)——优先队列求解
上篇描述了哈夫曼编码问题的基本描述以及建造一个哈夫曼树的过程分析,那么当算法已经描述清楚之后,我们要怎么样来实现
代码呢?或者说,给你一些带有权值的叶子节点,要怎么样利用程序快速算出所对应的哈夫曼树的带权路径WPL呢?
我们首先回顾一下上篇讲到的那个问题:
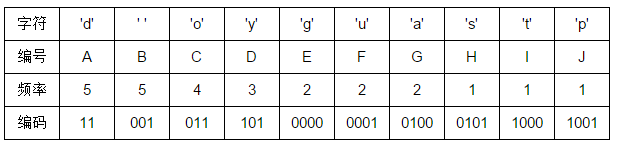
例如有这一个字符串“good good study day day up”,现在我们要对字符串进行哈夫曼编码,该字符串一共有 26 个字符,10 种字符,我们首先统计出每个字符的频率,然后按从大到小顺序排列如下(第二列的字符是空格):

最后,我们根据每个字符出现的频率,建造出了这样的一棵哈夫曼树:
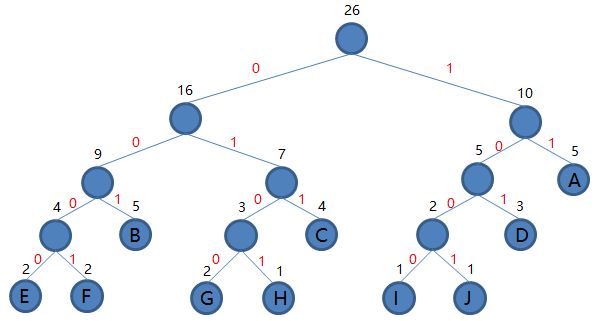
然后根结点到每个叶子结点的路径便是其对应字母的编码了,于是我们可以得到:
然后就是计算一下哈夫曼树的带权路径长度 WPL,也就是每个叶子节点的权值乘以到根的距离(即每个叶子节点的深度,在这个例子中根节点为第0层)结果之和。
WPL = 5 * 2 + 5 * 3 + 4 * 3 + 3 * 3 + 2 * 4 + 2 * 4 + 2 * 4 + 1 * 4 + 1 * 4 + 1 * 4 = 82。
算法描述得非常清楚了,那么我们思考这样一个问题,要怎么将具体的算法实现成相应代码呢?是否模拟上述过程,每次都是取其中权值最小的两个节点呢?这样的话在数据量较小的情况下是可以实现的,但是如果当数据量比较大的时候,比如说节点数到达10^6以上时,那么每取两个节点,加入新的节点后就要重新排序一次,然后在整棵哈夫曼树建立完成之后,再根据每个叶节点的深度以及权值,计算整棵哈夫曼树的带权路径WPL,但是这样的话会由于时间复杂度过大而无法在短时间内运行出程序结果。
那么问题来了,我们不用这种方法去计算WPL,还有其他的办法吗?
首先我们来看这棵构造好的哈夫曼树:
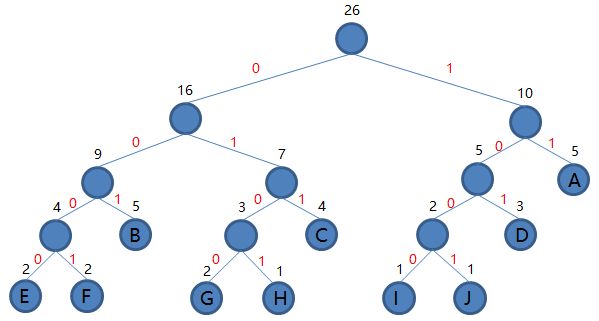
为了简便起见,我们从树的左边开始考虑,即B,E,F节点。
对于节点B,其深度为3,权值为5,那么其带权路径长度为5*3 = 15;
那么我们再看一下节点B的父亲节点,其权值为9,是由权值为4和权值为5的节点B构造而成,那么即是9 = 4 + 5;
同样的再往上一层,节点B的爷爷节点,其权值为16,是由权值为9和权值为7的节点构造而成,而权值为9的节点的构造前面已经说明,则有16 = 4 + 5 + 7;
再往上一层就到根节点了。
那么到这里我们可以看到,节点B的父亲节点和爷爷节点的组成部分都有节点B的“功劳”,即节点B的权值是其另外两个的“组成部分”,那么节点B的带权路径长度即为其到根节点路径上(不包含根节点),与其(或者说是与其父节点,爷爷节点等)有父子关系的节点抽取出节点B的组成部分(包括节点B本身),再全部相加,这样的话就得到了节点B的带权路径长度为5 + 5 + 5 = 15;
同样的,节点E,F按照同样的方法进行推导。
所以我们从上面的分析得出:
每个带权叶节点到根节点的带权路径长度等于其到根节点路径上所有节点的包含该带权叶节点权值组成部分之和。
因此,最后我们推导出,所有叶节点,即整棵哈夫曼树的带权路径长度 WPL即为:
除了根节点以外,所有节点的权值之和。
如上图哈夫曼树的带权路径长度 WPL即为:
WPL = 16 + 10 + 9 + 7 + 5 + 5 + 4 + 5 + 3 + 4 + 2 + 3 + 2 + 2 + 2 + 1 + 1 + 1 = 82
有了这样的判断之后,我们便很容易计算出一颗哈夫曼树的带权路径WPL了。
因此我们可以借助一个叫做优先队列的数据结构,而优先队列的实现往往是借助于二叉堆的结构实现,在这里我们要实现的是小根堆的数据结构。一开始的时候,我们可以将所有的节点一个一个的压入队列中,每次有节点入队,队列都会进行自调整,使其保持一个小根堆的状态。当所有的节点全部入队之后,这时候我们根据以上推导出来的结论,每次取两个权值最小的节点,将其值计算之后,然后再将两个节点权值之和的节点压入队列中,直到队列中只剩下一个节点(即根节点),跳出循环体,输出最后的答案。即整棵哈夫曼树的带权路径WPL。
完整代码实现(C++版,非STL):
#include
using namespace std;
class Heap {
private:
int *data, size;
public:
Heap(int length_input) {
data = new int[length_input];
size = 0;
}
~Heap() {
delete[] data;
}
void push(int value) {
data[size] = value;
int current = size;
int father = (current - 1) / 2;
while (data[current] < data[father]) {
swap(data[current], data[father]);
current = father;
father = (current - 1) / 2;
}
size++;
}
int top() {
return data[0];
}
void update(int pos, int n) {
int lchild = 2 * pos + 1, rchild = 2 * pos + 2;
int max_value = pos;
if (lchild < n && data[lchild] < data[max_value]) {
max_value = lchild;
}
if (rchild < n && data[rchild] < data[max_value]) {
max_value = rchild;
}
if (max_value != pos) {
swap(data[pos], data[max_value]);
update(max_value, n);
}
}
void pop() {
swap(data[0], data[size - 1]);
size--;
update(0, size);
}
int heap_size() {
return size;
}
};
int main() {
int n,value,ans = 0;
cin >> n;
Heap heap(n); //表示队列中的元素的上限
for(int i = 1;i <= n;++i){
cin >> value;
heap.push(value);
}
if(n==1){
ans = ans + heap.top();
}
while(heap.heap_size() > 1){
int a = heap.top();
heap.pop();
int b = heap.top();
heap.pop();
ans += a + b;
heap.push(a+b);
}
cout << ans << endl;
return 0;
}
完整代码实现(C++版,STL优先队列实现):
#include
#include
#include
using namespace std;
int main(){
int num[10];
priority_queue ,greater > que;
printf("叶节点的权值分别为:\n");
for(int i = 0;i < 10;++i){
scanf("%d",&num[i]);
que.push(num[i]);
}
int ans = 0;
while(que.size() > 1){
int a = que.top();
que.pop();
int b = que.top();
que.pop();
ans += a + b;
que.push(a + b);
}
printf("所对应的哈夫曼树的带权路径长度WPL = %d\n",ans);
return 0;
}