别再蒸馏3层BERT了!变矮又能变瘦的DynaBERT了解一下
2020-06-27 03:19:34

作者 | rumor酱
编辑 | 丛 末
神经网络模型除了部署在远程服务器之外,也会部署在手机、音响等智能硬件上。比如在自动驾驶的场景下,大部分模型都得放在车上的终端里,不然荒山野岭没有网的时候就尴尬了。对于BERT这类大模型来说,也有部署在终端的需求,但考虑到设备的运算速度和内存大小,是没法部署完整版的,必须对模型进行瘦身压缩。
说到模型压缩,常用的方法有以下几种:
- 量化:用FP16或者INT8代替模型参数,一是占用了更少内存,二是接近成倍地提升了计算速度。目前FP16已经很常用了,INT8由于涉及到更多的精度损失还没普及。
- 低轶近似/权重共享:低轶近似是用两个更小的矩阵相乘代替一个大矩阵,权重共享是12层transformer共享相同参数。这两种方法都在ALBERT中应用了,对速度基本没有提升,主要是减少了内存占用。但通过ALBRET方式预训练出来的Transformer理论上比BERT中的层更通用,可以直接拿来初始化浅层transformer模型,相当于提升了速度。
- 剪枝:通过去掉模型的一部分减少运算。最细粒度为权重剪枝,即将某个连接权重置为0,得到稀疏矩阵;其次为神经元剪枝,去掉矩阵中的一个vector;模型层面则为结构性剪枝,可以是去掉attention、FFN或整个层,典型的工作是LayerDrop[1]。这两种方法都是同时对速度和内存进行优化。
- 蒸馏:训练时让小模型学习大模型的泛化能力,预测时只是用小模型。比较有名的工作是DistillBERT[2]和TinyBERT[3]。
实际工作中,减少BERT层数+蒸馏是一种常见且有效的提速做法。但由于不同任务对速度的要求不一样,可能任务A可以用6层的BERT,任务B就只能用3层的,因此每次都要花费不少时间对小模型进行调参蒸馏。

有没有办法一次获得多个尺寸的小模型呢?
今天就给大家介绍一篇论文《DynaBERT: Dynamic BERT with Adaptive Width and Depth》[4]。论文中作者提出了新的训练算法,同时对不同尺寸的子网络进行训练,通过该方法训练后可以在推理阶段直接对模型裁剪。依靠新的训练算法,本文在效果上超越了众多压缩模型,比如DistillBERT、TinyBERT以及LayerDrop后的模型。

论文地址:
https://arxiv.org/abs/2004.04037
1
原理
论文对于BERT的压缩流程是这样的:
- 训练时,对宽度和深度进行裁剪,训练不同的子网络
- 推理时,根据速度需要直接裁剪,用裁剪后的子网络进行预测
想法其实很简单,但如何能保证更好的效果呢?这就要看炼丹功力了 (..•˘_˘•..),请听我下面道来~
整体的训练分为两个阶段,先进行宽度自适应训练,再进行宽度+深度自适应训练。
1、宽度自适应 Adaptive Width
宽度自适应的训练流程是:
1)得到适合裁剪的teacher模型,并用它初始化student模型
2)裁剪得到不同尺寸的子网络作为student模型,对teacher进行蒸馏
最重要的就是如何得到适合裁剪的teacher。先说一下宽度的定义和剪枝方法。Transformer中主要有Multi-head Self-attention(MHA)和Feed Forward Network(FFN)两个模块,为了简化,作者用注意力头的个数和intermediate层神经元的个数来定义MHA和FFN的宽度,并使用同一个缩放系数来剪枝,剪枝后注意力头减小到个,intermediate层神经元减少到个。
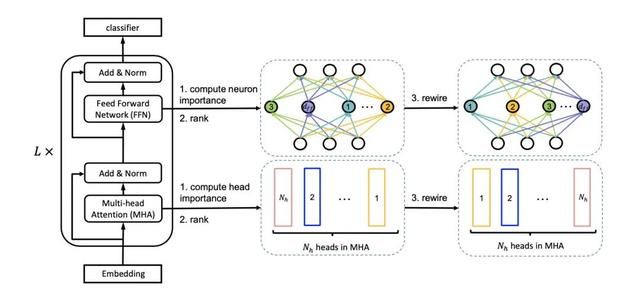
在MHA中,我们认为不同的head抽取到了不同的特征,因此每个head的作用和权重肯定也是不同的,intermediate中的神经元连接也是。如果直接按照粗暴裁剪的话,大概率会丢失重要的信息,因此作者想到了一种方法,对head和神经元进行排序,每次剪枝掉不重要的部分,并称这种方法为Netword Rewiring。
对于重要程度的计算参考了论文[5],核心思想是计算去掉head之前和之后的loss变化,变化越大则越重要。
利用Rewiring机制,便可以对注意力头和神经元进行排序,得到第一步的teacher模型,如图:
要注意的是,虽然随着参数更新,注意力头和神经元的权重会变化,但teacher模型只初始化一次(在后文有验证增加频率并没带来太大提升)。之后,每个batch会训练四种student模型,如图:
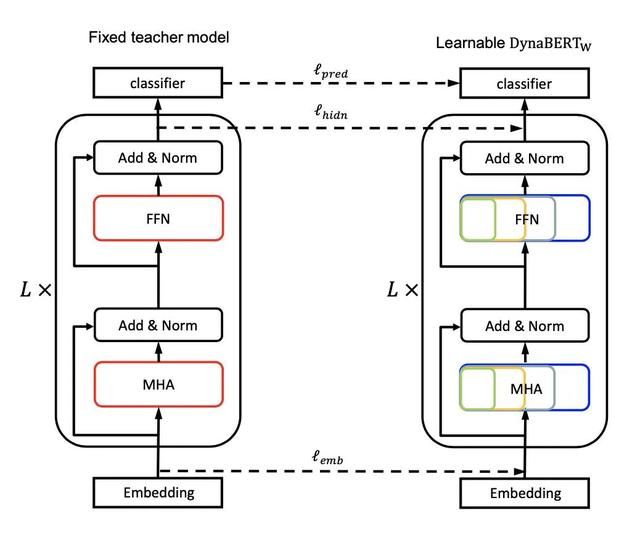
蒸馏的最终loss来源于三方面:logits、embedding和每层的hidden state。
2、深度自适应 Adaptive Depth
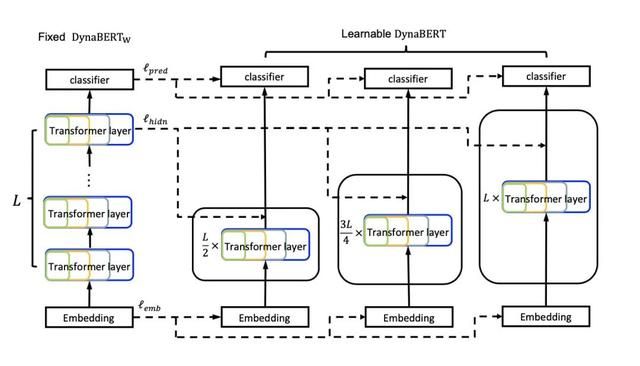
训好了width-adaptive的模型之后,就可以训自适应深度的了。浅层BERT模型的优化其实比较成熟了,主要的技巧就是蒸馏。作者直接使用训好的作为teacher,蒸馏裁剪深度后的小版本BERT。
对于深度,系数,设层的深度为[1,12],作者根据去掉深度为d的层。之所以取是因为研究表明最后一层比较重要[6]。
最后,为了避免灾难性遗忘,作者继续对宽度进行剪枝训练,第二阶段的训练方式如图:
2
实验
根据训练时宽度和深度的裁剪系数,作者最终可得到12个大小不同的BERT模型,在GLUE上的效果如下:
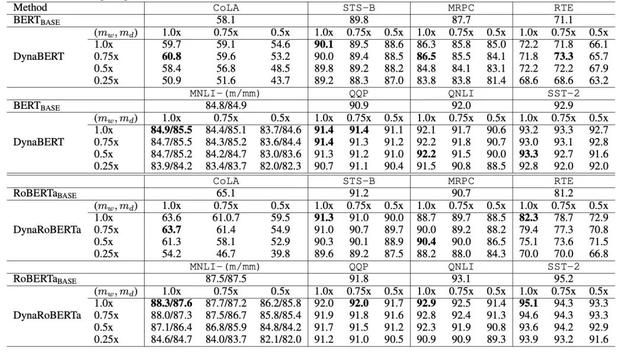
可以看到,剪枝的BERT效果并没有太多下降,并且在9个任务中都超越了BERT-base。同时,这种灵活的训练方式也给BERT本身的效果带来了提升,在与BERT和RoBERTa的对比中都更胜一筹:

另外,作者还和DistillBERT、TinyBERT、LayerDrop进行了实验对比,DynaBERT均获得了更好的效果。
在消融实验中,作者发现在加了rewiring机制后准确率平均提升了2个点之多:
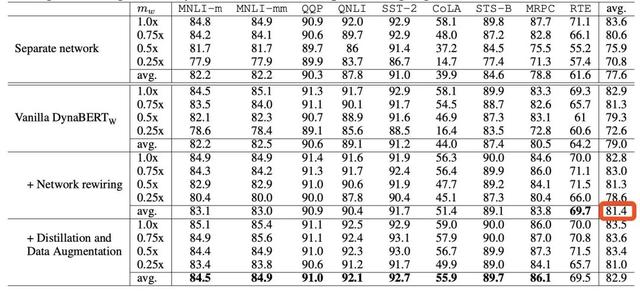
3
结论
本篇论文的创新点主要在于Adaptive width的训练方式,考虑到后续的裁剪,作者对head和neuron进行了排序,并利用蒸馏让子网络学习大网络的知识。
总体来说还是有些点可以挖的,比如作者为什么选择先对宽度进行自适应,再宽度+深度自适应?这样的好处可能是在第二阶段的蒸馏中学习到宽度自适应过的子网络知识。但直接进行同时训练不可以吗?还是希望作者再验证一下不同顺序的差距。
为了简化,作者在宽度上所做的压缩比较简单,之后可以继续尝试压缩hidden dim。另外,ALBERT相比原始BERT其实更适合浅层Transformer,也可以作为之后的尝试方向。
参考文献:
[1]LayerDrop: https://arxiv.org/abs/1909.11556
[2]DistillBERT: https://arxiv.org/abs/1910.01108
[3]TinyBERT: https://arxiv.org/abs/1909.10351
[4]DynaBERT: https://www.researchgate.net/publication/340523407_DynaBERT_Dynamic_BERT_with_Adaptive_Width_and_Depth
[5]Analyzing multi-head self-attention: https://arxiv.org/abs/1905.09418
[6]Minilm: https://arxiv.org/abs/2002.10957