linux-配置hadoop集群(配置文件及环境配置)
文章目录
- 一、前期准备
- 1.虚拟机启动成功后注意以下配置
- 2.Linux(CentOS)虚拟机中jdk需要配置好【注意:关闭防火墙】
- 3.将hadoop压缩包拖入
- 4.使用 tar -zxvf 命令解压文件
- 5.将文件夹名字简化
- 6.生成密钥
- 7.设置免密登录
- 二、hadoop 环境配置
- 1.输入cd /opt/hadoop/etc/hadoop,进入hadoop
- 2.配置 hadoop-env.sh
- 3.配置core-site.xml
- 3.配置hdfs-site.xml
- 4.配置mapred-site.xml
- 5.配置yarn-site.xml
- 6.配置slaves
- 7.安装native文件
- 8.Hadoop环境变量配置
- 三、启动hadoop
- 1.格式化HDFS
- 2.启动hadoop
- 3.启动历史服务
- 4.检查是否启动成功
- 5.访问Hadoop
- 四.配置hadoop集群
- 1.关闭当前虚拟机,并复制
- 2.依此启动并修改ip地址和用户名
- 3.重启网络
- 4.生成密钥,免密登录并远程连接
- 5.Moba连接成功,修改相关配置文件
- 6.格式化HDFS并启动
- 7.进入网址 192.168.56.201:50070
虚拟机配置请参考: Linux—安装虚拟机(CentOS)及moba连接虚拟机
hadoop相关文件百度网盘地址:
hadoop-2.6.0-cdh5.14.2.tar.gz
hadoop-native-64-2.6.0.tar
一、前期准备
1.虚拟机启动成功后注意以下配置
①如果防火墙为开启状态需要停止防火墙服务
停止防火墙服务
systemctl stop firewalld
禁用防火墙,下次开机启动后防火墙服务不再启动
systemctl disable firewalld

②修改用户名hostname
输入 vi /etc/hostname 将用户名修改为hadoop04
![]()

#用户名修改即时成效
hostnamectl set-hostname hadoop04

可通过 vi /etc/hostname 查看是否修改成功
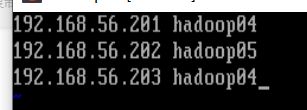
③修改hosts
输入 vi etc/hosts 进入hosts文件(因为我这边是要搭建三个虚拟机集群所以配置了三个)
2.Linux(CentOS)虚拟机中jdk需要配置好【注意:关闭防火墙】
linux-jdk配置请参考:Linux系统安装jdk(包括环境配置)
3.将hadoop压缩包拖入
我这边放在了opt目录下

4.使用 tar -zxvf 命令解压文件
tar -zxvf hadoop-2.6.0-cdh5.14.2.tar.gz

5.将文件夹名字简化
不是必要步骤
mv hadoop-2.6.0-cdh5.14.2 hadoop

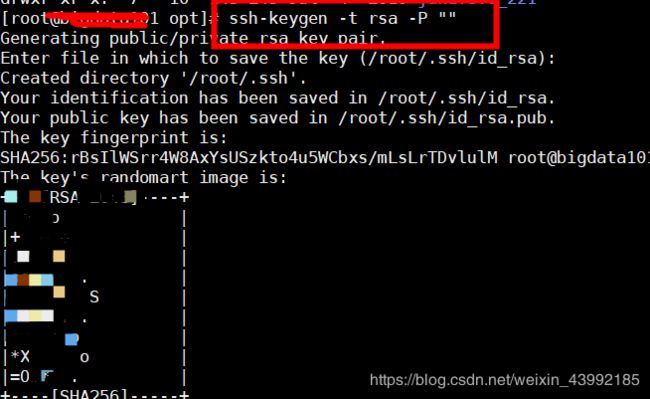
6.生成密钥
ssh-keygen -t rsa -P ""
7.设置免密登录
cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
二、hadoop 环境配置
1.输入cd /opt/hadoop/etc/hadoop,进入hadoop
cd /opt/hadoop/etc/hadoop
2.配置 hadoop-env.sh
#进入hadoop.sh文件
vi hadoop-env.sh
#配置j JAVA_HOME 后面为java路径
export JAVA_HOME=/opt/jdk1.8.0_221/

3.配置core-site.xml
#进入core-site.xml
vi core-site.xml
#配置属性
fs.defaultFS #默认节点
hdfs://192.168.56.201:9000
hadoop.tmp.dir #HDFS文件系统的临时目录
/opt/hadoop/tmp
hadoop.proxyuser.root.hosts #其他机器的root用户可访问
*
hadoop.proxyuser.root.groups #其他root组下的用户都可以访问
*
3.配置hdfs-site.xml
#进入hdfs-site.xml
vi hdfs-site.xml
#配置相关属性
dfs.replication #复制的份数(与连接机器的数量相等)
1
dfs.namenode.secondary.http-address #namenode的备用节点
192.168.56.201:50090
4.配置mapred-site.xml
#新建mapred-site.xml
vi mapred-site.xml
#配置属性 将文件mapred-site.xml.template的内容复制到mapred-site.xml
mapreduce.framework.name #mapreduce的框架名称
yarn
mapreduce.jobhistory.address #mapreduce的工作地址
hadoop04:10020
mapreduce.jobhistory.webapp.address #web页面访问历史服务端口的配置
hadoop04:19888
5.配置yarn-site.xml
#进入yarn-site.xml
vi yarn-site.xml
#配置
yarn.nodemanager.aux-services #reducer获取数据方式
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.resourcemanager.hostname #指定YARN的ResourceManager的地址
handoop04
yarn.log-aggregation-enable #日志聚集功能使用
true
yarn.log-aggregation.retain-seconds #日志保留时间设置7天
604800
6.配置slaves
#进入slaves
vi slaves
#添加主机名
hadoop04

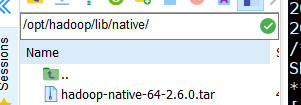
7.安装native文件
请将 hadoop-native-64-2.6.0.tar 文件拖入/opt/hadoop/lib/native 文件夹内
解压文件
tar -xf hadoop-native-64-2.6.0.tar
删除文件
rm -f hadoop-native-64-2.6.0.tar

如果不安装,在启动时可能会出现以下警告

8.Hadoop环境变量配置
#进入profile
vi /etc/profile
#环境配置(shift+g 快速定位末行,在最后插入)
export HADOOP_HOME=/opt/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_COMMON_LIB_NATIVE_DIR"
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
#保存退出并source
source /etc/profile
三、启动hadoop
1.格式化HDFS
hadoop namenode -format
2.启动hadoop
start-all.sh
3.启动历史服务
mr-jobhistory-daemon.sh start historyserver
4.检查是否启动成功
输入jps

5.访问Hadoop
#访问HDFS页面
http://192.168.56.201:50070
#访问YARN的管理界面
http://192.168.56.201:8088
#访问jobhistory页面
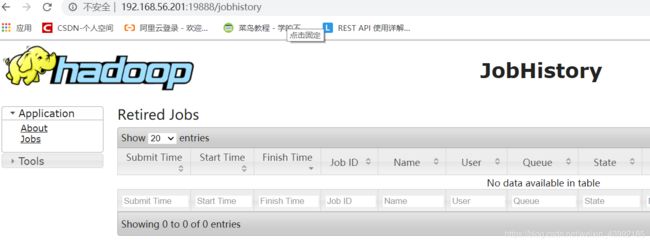
http://192.168.56.201:19888
出现以下界面说明启动成功


四.配置hadoop集群
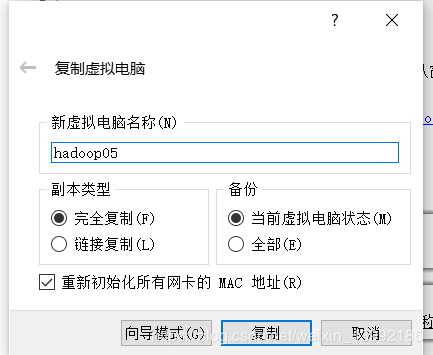
1.关闭当前虚拟机,并复制

2.依此启动并修改ip地址和用户名
除去被复制的虚拟机,其他两个都需要修改
#修改ip地址
vi /etc/sysconfig/network-scripts/ifcfg-enp0s3


#修改用户名
vi /etc/hostname

#用户名修改即时生效
hostnamectl set-hostname hadoop05


#如果之前hosts没有配置过,需要配置
输入 vi /etc/hosts
3.重启网络
systemctl restart network

4.生成密钥,免密登录并远程连接
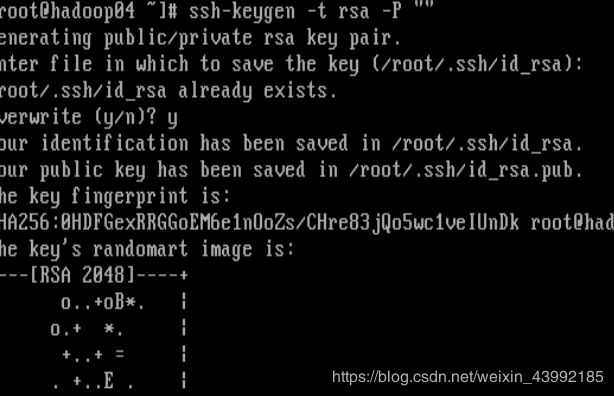
①.输入 ssh-keygen -t rsa -P "" 生成密钥(Overwrite (y/n)? y )
②.设置免密登录(> 为替换 >> 为追加)
cat /root/.ssh/id_rsa.pub > /root/.ssh/authorized_keys
![]()
③.远程连接
每一台虚拟机需要与其他虚拟机相连(@后面也可以写ip地址)
ssh-copy-id -i .ssh/id_rsa.pub -p22 root@hadoop05
以hadoop04为例


④.验证连接是否成功
#方式一
ssh root@hadoop05
#方拾二
ssh [email protected]
5.Moba连接成功,修改相关配置文件
在hadoop04中修改配置文件并将配置文件复制给另外两台虚拟机
①Moba连接成功

②进入到hadoop
输入 cd /opt/hadoop/etc/hadoop
③修改hdfs-site.xml文件配置
dfs.replication
3 #文件的副本数
dfs.namenode.secondary.http-address
192.168.56.202:50090 #备用节点

③在slaves文件中增加其他两个虚拟机的用户名
输入 vi slaves

④将刚刚修改的配置文件传给另外两台虚拟机[使用scp命令]
scp hdfs-site.xml 192.168.56.202:/opt/hadoop/etc/hadoop/hdfs-site.xml
scp hdfs-site.xml 192.168.56.203:/opt/hadoop/etc/hadoop/hdfs-site.xml
scp slaves 192.168.56.202:/opt/hadoop/etc/hadoop/slaves
scp slaves 192.168.56.203:/opt/hadoop/etc/hadoop/slaves

6.格式化HDFS并启动
①格式化HDFS
hadoop namenode -format
②启动
输入 start-all.sh 启动
启动结束后输入jps 检查是否启动
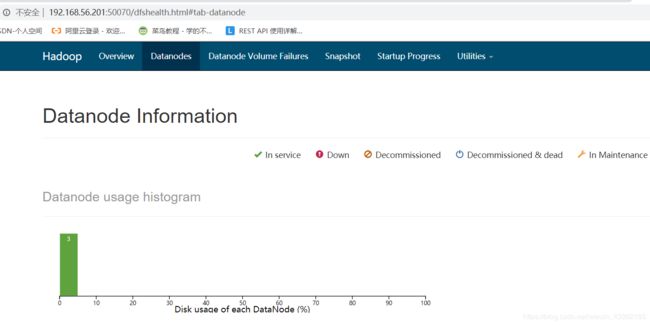
7.进入网址 192.168.56.201:50070
如果显示节点为3则说明集群配置成功