效果展示
可以看到“施法”前后的图片肉眼看不出区别,然而图片却真是的隐藏了一些数据在里面。
程序的实现
先导入 Pillow 模块:
from PIL import Image
- 编码
我们首先设计将隐藏信息编码到图片中的函数encodeDataInImage(),其有两个参数,分别是用作载体的图片对象和需要被隐藏的字符串。也就是说我们可以这样调用它:
encodeDataInImage(Image.open("steganographia.png"), '你好世界,Hello World!')
encodeDataInImage()函数如下:
def encodeDataInImage(image, data):
"""
将字符串编码到图片中
"""
# 获得最低有效位为 0 的图片副本
evenImage = makeImageEven(image)
# 将需要被隐藏的字符串转换成二进制字符串
binary = ''.join(map(constLenBin, bytearray(data, 'utf-8')))
if len(binary) > len(image.getdata()) * 4:
# 如果不可能编码全部数据,跑出异常
raise Exception("Error: Can't encode more than" + len(evenImage.getdata()) * 4 + " bits in this image. ")
# 将binary中的二进制字符串信息编码进像素里
encodedPixels = [(r+int(binary[index*4+0]), g+int(binary[index*4+1]), b+int(binary[index*4+2]), t+int(binary[index*4+3])) if index*4 < len(binary) else (r,g,b,t) for index,(r,g,b,t) in enumerate(list(evenImage.getdata()))]
# 创建新图片以存放编码后的像素
encodedImage = Image.new(evenImage.mode, evenImage.size)
# 添加编码后的数据
encodedImage.putdata(encodedPixels)
return encodedImage
makeImageEven()函数的实现如下:
def makeImageEven(image):
"""
取得一个 PIL 图像并且更改所有值为偶数(使最低有效位为0)
"""
#得到一个这样的列表:[(r,g,b,t),(r,g,b,t)...]
pixels = list(image.getdata())
# 更改所有值为偶数(魔法般的移位)
evenPixels = [(r>>1<<1,g>>1<<1,b>>1<<1,t>>1<<1) for [r,g,b,t] in pixels]
# 创建一个相同大小的图片副本
evenImage = Image.new(image.mode, image.size)
# 把上面的像素放入到图片副本
evenImage.putdata(evenPixels)
return evenImage
encodeDataInImage()中,bytearray()将字符串转换为整数值序列(数字范围是0到2^8-1),数值序列由字符串的字节数据转换而来,如下图:
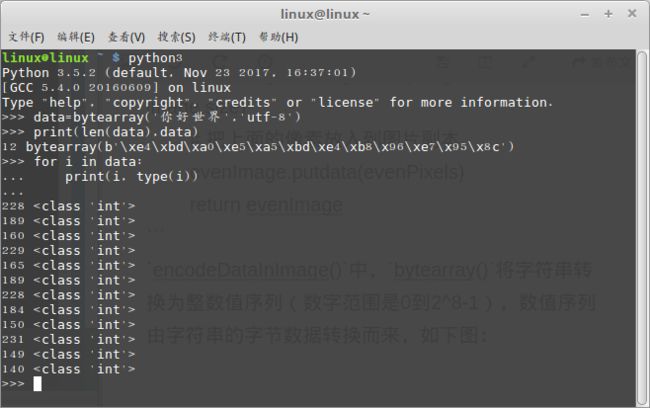
utf-8编码的中文字符一个就占了3个字节,那么四个字符共占3x4=12个字节,于是共有12个数字。(可以在右下角切换到中文输入法,这样就能输入中文了)
然后
map(constLenBin,Bytearray(data, 'utf-8'))对数值序列中的每一个值应用
constLenBin()函数,将十进制数值学列转换为二进制自字符转序列。
def constLenBin(int):
"""
内置函数bin()的替代,返回固定长度的二进制字符串
"""
#去掉bin()返回的二进制字符串中的'0b',并在左边补足'0'直到字符串长度为8
binary = "0"*(8-(len(bin(int))-2))+bin(int).replace('0b','')
return binary
在这里bin()的作用是将一个int值转换为二进制字符串。详见https://docs.python.org/3/library/functions.html#bin
- 解码
decodeImage()返回图片解码后的隐藏文字,其接受一个图片对象参数。
def decodeImage(image):
"""
解码隐藏数据
"""
pixels = list(image.getdata()) #获得像素列表
#提取图片中所有最低有效位中的数据
binary = ''.join([str(int(r>>1<<1!=r))+str(int(g>>1<<1!=g))+str(int(b>>1<<1!=b))+str(int(t>>1<<1!=t)) for (r,g,b,t) in pixels])
#找到数据截止处的索引
locationDoubleNull = binary.find('0000000000000000')
endIndex = locationDoubleNull+(8-(locationDoubleNull %8)) if locationDoubleNull%8 != 0 else locationDoubleNull
data = binaryToString(binary[0:endIndex])
return data
找到数据截止处所用的字符串0000000000000000很有意思,它的长度为16,而不是直觉上的8,因为两个包含数据的字节的接触部分可能有8个0。
binaryToString()函数将提取出来的二进制字符串转换为隐藏的文本:
def binaryToString(binary):
"""
从二进制字符串转为 UTF-8 字符串
"""
index = 0
string = []
rec = lambda x, i: x[2:8] + (rec(x[8:], i-1) if i > 1 else '') if x else ''
fun = lambda x, i: x[i+1:8] + rec(x[8:], i-1)
while index + 1 < len(binary):
chartype = binary[index:].index('0') # 存放字符所占字节数,一个字节的字符会存为0
length = chartype*8 if chartype else 8
string.append(chr(int(fun(binary[index:index+length],chartype),2)))
index += length
return ''.join(string)
要看明白这个,必须要先搞懂UTF-8编码的方式,可以在wikipedia上了解utf-8编码https://zh.wikipedia.org/wiki/UTF-8
utf-8是UNICODE的一种变长度的编码表达方式,也就是说一个字符串中,不同的字符所占的字节数不一定相同,这就给我们的工作带来了一点复杂度,如果我们要支持中文的话。
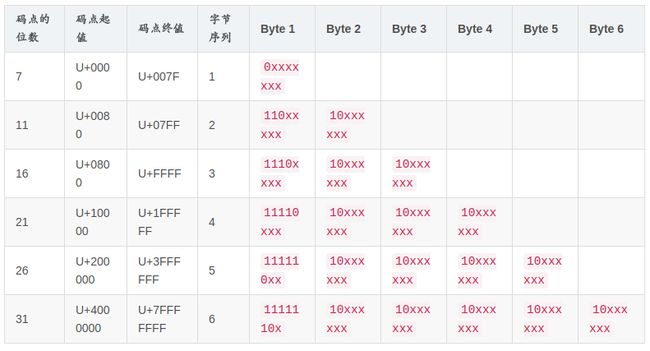
在上图中,只有
x所在的位置(也即是字节中第一个0之后的数据)存储的是真正的字符数据,因此我们使用下面两个匿名函数来提取出这些数据:
rec = lambda x, i: x[2:8] + (rec(x[8:], i-1) if i > 1 else '') if x else ''
fun = lambda x, i: x[i+1:8] + rec(x[8:], i-1)
fun()接受2个参数,第一个参数为表示一个字符的二进制字符串,这个二进制字符串可能有不同的长度(8\16\24...48);第二个参数为这个字符占多少个字节。
lambda x, i: x[x+1:8] + rec(x[8:], i-1) 中 x[i+1:8]获得第一个字节的数据,然后调用rec(),以递归的方式提取后面字节中的数据。
这里要提一句,rec = lambda x, i: x[2:8] + (rec(x[8:], i-1) if i > 1 else ' ') if x else ' ',你可能对在表达式里面引用了 rec 感到不可理解,的确,严格意义上这样是不能实现递归的,但在python里这样是可以的,这就是python的语法糖了。
使用lambda表达式写递归从来不是一件简单的事,因为匿名函数引用自身并不简单,大家可以参考一下大牛刘未鹏的博文:http://blog.csdn.net/pongba/article/details/1336028
我们注意到,字符的字节数据中,第一个字节开头1的数目便是字符所占的字节数:
chartype = binary[index:].index('0')
string.append(chr(int(fun(binary[index:index+length],chartype),2)))这一行中用到的函数int()以及chr的作用如下:
int():接受两个参数,第一个参数为数字字符串,第二个参数为这个字符串代表的数字的进度。详见:https://docs.python.org/3/library/functions.html#int
chr():接受一个参数,参数为int值,返回Unicode码点为这个int值的字符。见下图:
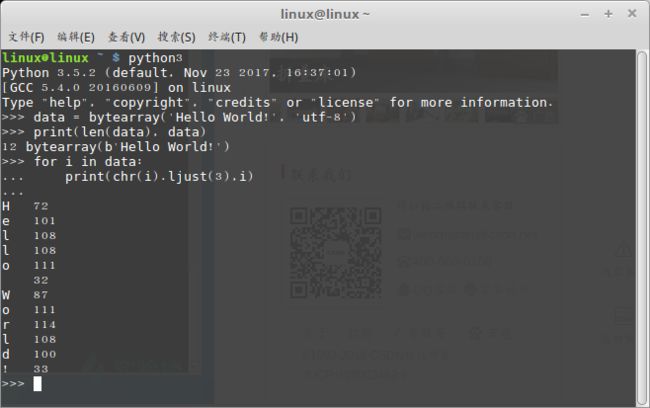
while循环的最后我们将当前字符的索引增加当前字符的长度,得到下一个字符的索引。
这样,我们可以识别出二进制字符串中哪些部分代表哪些字符了,然后就能调用
fun()取得各个字符的数据了。
- 测试效果
输入下面的命令获得测试用的图片:
$ wget http://labfile.oss.aliyuncs.com/courses/651/coffee.png
在我们的代码后添加这两行:
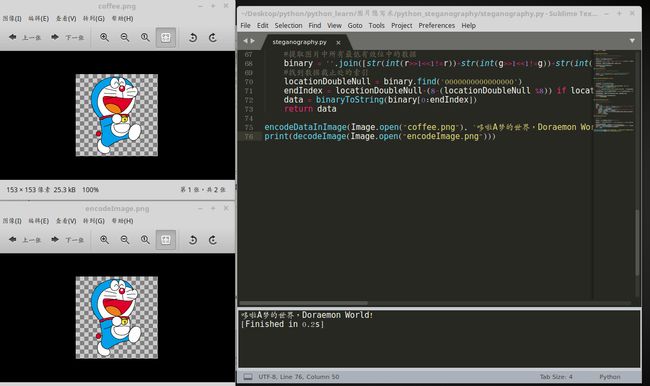
encodeDataInImage(Image.open("coffee.png"), '哆啦A梦的世界,Doraemon World!').save('encodeImage.png')
print(decodeImage(Image.open("encodeImage.png")))
假设你的源代码文件为 steganography.py:
$ python3 steganography
它应该打印出“哆啦A梦的世界,Doraemon World!”
- 完整代码
from PIL import Image
def makeImageEven(image):
"""
取得一个 PIL 图像并且更改所有值为偶数(使最低有效位为0)
"""
#得到一个这样的列表:[(r,g,b,t),(r,g,b,t)...]
pixels = list(image.getdata())
# 更改所有值为偶数(魔法般的移位)
evenPixels = [(r>>1<<1,g>>1<<1,b>>1<<1,t>>1<<1) for [r,g,b,t] in pixels]
# 创建一个相同大小的图片副本
evenImage = Image.new(image.mode, image.size)
# 把上面的像素放入到图片副本
evenImage.putdata(evenPixels)
return evenImage
def constLenBin(int):
"""
内置函数bin()的替代,返回固定长度的二进制字符串
"""
#去掉bin()返回的二进制字符串中的'0b',并在左边补足'0'直到字符串长度为8
binary = "0"*(8-(len(bin(int))-2))+bin(int).replace('0b','')
return binary
def encodeDataInImage(image, data):
"""
将字符串编码到图片中
"""
# 获得最低有效位为 0 的图片副本
evenImage = makeImageEven(image)
# 将需要被隐藏的字符串转换成二进制字符串
binary = ''.join(map(constLenBin, bytearray(data, 'utf-8')))
if len(binary) > len(image.getdata()) * 4:
# 如果不可能编码全部数据,跑出异常
raise Exception("Error: Can't encode more than" + len(evenImage.getdata()) * 4 + " bits in this image. ")
# 将binary中的二进制字符串信息编码进像素里
encodedPixels = [(r+int(binary[index*4+0]), g+int(binary[index*4+1]), b+int(binary[index*4+2]), t+int(binary[index*4+3])) if index*4 < len(binary) else (r,g,b,t) for index,(r,g,b,t) in enumerate(list(evenImage.getdata()))]
# 创建新图片以存放编码后的像素
encodedImage = Image.new(evenImage.mode, evenImage.size)
# 添加编码后的数据
encodedImage.putdata(encodedPixels)
return encodedImage
def binaryToString(binary):
"""
从二进制字符串转为 UTF-8 字符串
"""
index = 0
string = []
rec = lambda x, i: x[2:8] + (rec(x[8:], i-1) if i > 1 else '') if x else ''
fun = lambda x, i: x[i+1:8] + rec(x[8:], i-1)
while index + 1 < len(binary):
chartype = binary[index:].index('0') # 存放字符所占字节数,一个字节的字符会存为0
length = chartype*8 if chartype else 8
string.append(chr(int(fun(binary[index:index+length],chartype),2)))
index += length
return ''.join(string)
def decodeImage(image):
"""
解码隐藏数据
"""
pixels = list(image.getdata()) #获得像素列表
#提取图片中所有最低有效位中的数据
binary = ''.join([str(int(r>>1<<1!=r))+str(int(g>>1<<1!=g))+str(int(b>>1<<1!=b))+str(int(t>>1<<1!=t)) for (r,g,b,t) in pixels])
#找到数据截止处的索引
locationDoubleNull = binary.find('0000000000000000')
endIndex = locationDoubleNull+(8-(locationDoubleNull %8)) if locationDoubleNull%8 != 0 else locationDoubleNull
data = binaryToString(binary[0:endIndex])
return data
encodeDataInImage(Image.open("coffee.png"), '哆啦A梦的世界,Doraemon World!').save('encodeImage.png')
print(decodeImage(Image.open("encodeImage.png")))