Hive on Spark 搭建&踩坑
背景:想通过jdbc连接hive的方式,用spark引擎,hive的数据,来处理业务需求。
环境:一台1C2G的ECS,渣渣机器;需要搭建集群的只需要更改yarn、slaves的配置即可。
接下来肯定会关注的问题就是版本了,版本的选择有千千万万种,这边的参考版本可在下面的参考配置中获得。
最关键的就是版本的匹配了,之前瞎配,最后会导致各种无法解决的问题。所以还是在动手前,先好好看看官方文档吧。
Hive和Spark版本匹配官方文档:
https://cwiki.apache.org/confluence/display/Hive/Hive+on+Spark:+Getting+Started
Spark和Hadoop、Scala、Java、Python等版本匹配官方文档:
http://spark.apache.org/documentation.html
----------------------------------------------------------------------------------------
首先配置Hive:
hive-site.xml增加或修改以下内容:
set spark.master=yarn-cluster; //默认即为yarn-cluster模式,该参数可以不配置
set hive.execution.engine=spark;
set spark.eventLog.enabled=true;
set spark.eventLog.dir=hdfs://cdh5/tmp/sparkeventlog;
set spark.executor.memory=1g;
set spark.executor.instances=50; //executor数量,默认貌似只有2个
set spark.driver.memory=1g;
set spark.serializer=org.apache.spark.serializer.KryoSerializer;根据实际情况自行转换为:
spark.home
/opt/spark-2.2.1-bin-hadoop2.7
spark.master
yarn
spark.executor.memory
800m
spark.executor.instances
5
spark.driver.memory
800m
spark.serializer
org.apache.spark.serializer.KryoSerializer
hive和hadoop的环境配置就不过多赘述了,概括的来说,对于hive就是需要配置hive-env.sh和环境变量。
Spark中相关配置:
hive-site.xml:
hive.metastore.uris
thrift://master:9083
Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.
spark-env.sh:
export SCALA_HOME=/opt/scala-2.12.1
export JAVA_HOME=/opt/tools/jdk1.8.0_162
export HADOOP_HOME=/opt/tools/hadoop-2.7.3
export HADOOP_CONF_DIR=/opt/tools/hadoop-2.7.3/etc/hadoop
export SPARK_MASTER_IP=master
export SPARK_MASTER_INSTANCES=2
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_PORT=7077
export SPARK_WORKER_MEMORY=1g
export SPARK_EXECUTOR_MEMORY=1g
export SPARK_DRIVER_MEMORY=1g
export SPARK_WORKER_CORES=1
export MASTER=spark://master:7077spark-default.conf:
spark.master yarn
spark.home /opt/spark-2.2.1-bin-hadoop2.7
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.executor.memory 1g
spark.driver.memory 1g
spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"需要配置yarn集群的,需要在slaves中添加相应的节点配置。
之后去${HADOOP_HOME}/sbin中 启动集群:
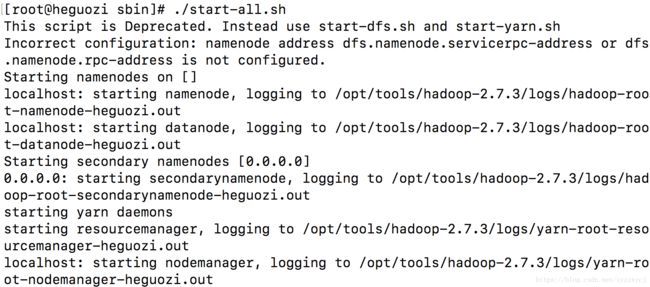
查看jps:

启动hive metastore和hiveserver2:


验证进程均已启动:
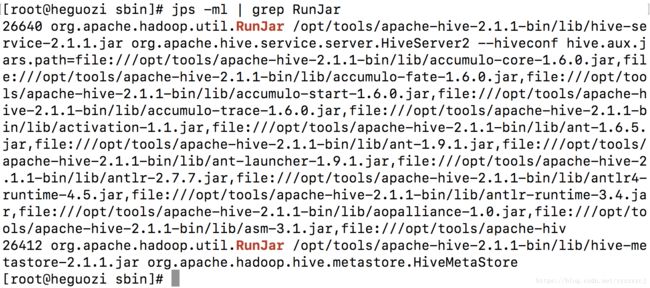
验证端口一开始监听:
![]()
启动spark:

确认启动,jps:

做到这里,没有意外的话 接下来就可以运行hive了。