论文中英对照翻译--(Fusing Multiple Deep Features for Face Anti-spoofing)
【开始时间】2018.10.22
【完成时间】2018.10.22
【论文翻译】论文中英对照翻译--(Fusing Multiple Deep Features for Face Anti-spoofing)
【中文译名】融合多个深层特征的人脸防欺骗
【论文链接】链接:https://pan.baidu.com/s/1sPUGnFbKp9C-eFNi59JNhQ 提取码:zb16
【补充】
1)论文的发表时间是:2018,是在13th Chinese Conference, CCBR 2018上发表的论文
【声明】本文是本人根据原论文进行翻译,有些地方加上了自己的理解,有些专有名词用了最常用的译法,时间匆忙,如有遗漏及错误,望各位包涵

题目:融合多个深层特征的人脸防欺骗
Abstract(摘要)
With the growing deployment of face recognition system in recent years, face anti-spoofing has become increasingly important, due to the increasing number of spoofing attacks via printed photos or replayed videos. Motivated by the powerful representation ability of deep learning, in this paper we propose to use CNNs (Convolutional Neural Networks) to learn multiple deep features from different cues of the face images for anti-spoofing. We integrate temporal features, color based features and patch based local features for spoof detection. We evaluate our approach extensively on publicly available databases like CASIA FASD,REPLAY-MOBILE and OULU-NPU. The experimental results show that our approach can achieve much better performance than state-of-the-art methods.Specifically, 2.22% of EER (Equal Error Rate) on the CASIA FASD, 3.2% of ACER (Average Classification Error Rate) on the OULU-NPU (protocol 1) and 0.00% of ACER on the REPLAY-MOBILE database are achieved.
近年来,随着人脸识别系统的不断发展,通过打印的照片或重放视频进行的欺骗攻击的行为越来越多,因此人脸反欺骗已经变得越来越重要。在深度学习的强大表现能力的激励下,本文提出使用cnn(卷积神经网络)从人脸图像的不同线索中学习多个深层特征来进行反欺骗。我们将时间特征、基于颜色的特征、基于补丁的局部特征融合用于人脸反欺骗。我们在公开可用的数据库上广泛评估我们的方法,如CASIA FASD,REPLAY-MOBILE and OULU-NPU。实验结果表明,我们的方法可以获得比最先进的方法更好的性能。具体而言,在CASIA FASD上获得了2.22%的EER(Equal Error Rate---等错误率),在 OULU-NPU(protocol 1)上实现了3.2%的ACER(Average Classification Error Rate---平均分类错误率),在 REPLAY-MOBILE数据库上实现了0.00%的 ACER(平均分类错误率)。
Keywords: Deep convolutional neural networks · Face anti-spoofing Multiple features
关键词:深层卷积神经网络·人脸抗欺骗多重特征
1 Introduction(引言)
With the advancement of computer vision technologies, face recognition has beenwidely used in various applications such as access control and login system. As printed photos and replay videos of a user can easily spoof the face recognition system, approaches capable of detecting these spoof attacks are highly demanded.
随着计算机视觉技术的进步,人脸识别在访问控制、登录系统等各种应用中得到了广泛的应用。因为用户的打印照片和重放视频很容易欺骗人脸识别系统,所以对识别这些欺骗攻击的方法提出了更高的要求。
To decide whether the faces presented before the camera are live person, or those spoof attacks, a number of approaches have been proposed in the literature. The main cues widely used are the depth information, the color texture information and the motion information. As majority of the attacks use printed photos or replayed videos, depth information could be a useful clue since live faces are 3D but the spoof faces are 2D. Wang et al. [11] combined the depth information and the textual information for face anti-spoofing. They used LBP (Local Binary Pattern) feature to represent the depth image captured by a Kinect and used a CNN (Convolutional Neural Network) to learn the texture information from the RGB image. This method needs an extra depth camera, which is usually not available for many applications. Instead of using the depth sensor like [11], the work presented in [9] adopted the CNN to estimate the depth information and then fused such depth information with the appearance information extracted from the face regions to distinguish between the spoof and the genuine faces. Besides the depth information, color texture or motion information has also been widely applied for face liveness detection [10, 13, 14]. Boulkenafet et al. [10] used different color spaces (HSV and YCbCr) to explore the color texture information and extracted LBP features from each space channel. The LBP features from all space channels were concatenated and then fed into the SVM (Support Vector Machine) for classification. An EER of 3.2% was obtained on the CASIA dataset. In contrast to the color texture information extracted from the static images, methods using motion cues tried to explore the temporal information of the genuine faces. Feng et al. [13] utilized the dense flow to capture the motion and designed optical flow based face motion and scene motion features. They also proposed a so called shearlet-based image quality feature, and then fused all the three features using a neural network for classification. Pan et al. [14] proposed a real-time liveness detection approach against photograph spoofing in face recognition by recognizing spontaneous eye blinks
为了判断相机前呈现的人脸是真人还是仿冒攻击,一些文献中提出了各自方法。广泛使用的主要线索是深度信息、颜色纹理信息和运动信息( the depth information, the color texture information and the motion information)。由于大多数攻击使用打印的照片或重放视频,深度信息可能是有用的线索,因为活人脸是三维的,而欺骗的人脸是2d的。[11]结合人脸反欺骗的深度信息和文本信息(depth information and the textual information),利用局部二值模式(LBP)特征来表示Kinect捕获的深度图像,并使用cnn(卷积神经网络)从rgb图像中学习纹理信息,这种方法需要一个额外的深度摄像机,而这通常是不可用的。而文[9]中提出的工作不像[11]那样使用深度传感器来估计深度信息,而是将深度信息与从人脸区域提取的外观信息融合起来,以区分假脸和真脸。此外,深度信息、颜色纹理或运动信息也被广泛应用于人脸活性检测[10,13,14]。Boulkenafet等人[10]使用不同的颜色空间(HSV和YCbCr)来探索颜色纹理信息,并从每个空间通道提取LBP特征,然后将所有空间通道的LBP特征连接起来,接着输入支持向量机(Svm)进行分类,在CASIA数据集上得到3.2%的表现率。与从静态图像中提取的颜色纹理信息相比,有的文献利用运动线索的方法试图探索真实面部的时间信息。[13]利用密集流捕捉运动,设计了基于光流的人脸运动和场景运动特征,并提出了一种基于剪切的图像质量特征,并利用神经网络对这三个特征进行融合。[14]提出了一种基于自然眨眼的人脸识别中对照片欺骗的实时活性检测方法。
Motivated by the fact that CNN can learn features with high discriminative ability, recently many methods [8, 15] tried to use CNN for face anti-spoofing. Yang et al. [8] trained a CNN network with five convolutional layers and three fully-connected layers. Both single frame and multiple frames were input to the network to learn the spatial features and the spatial-temporal features, respectively, and an EER of 4.64% was reported on the CASIA dataset. Li et al. [15] fine-tuned the pre-trained VGG-face, and used the learned deep features to identify spoof attacks. An EER of 4.5% was achieved on the CASIA dataset.
由于CNN能够学习到具有高分辨能力的特征,近年来许多方法[8,15]试图利用CNN来进行人脸反欺骗。[8]训练了一个包含5个卷积层和3个完全连通层的CNN网络,将单帧和多帧输入到网络中,分别学习空间特征和时空特征,并在CASIA数据集中获得了4.64%的EER。[15]对预先训练的VGG-face进行了精细的调整,并利用所学到的深层次特征来识别欺骗攻击。在 CASIA数据集上实现了4.5%的EER。
While the existing methods explore various information for face antis-spoofing, most of them apply only single cue of the face. Although several methods [11, 13] indeed explored multiple cues of the face for anti-spoofing, they only adopted hand-crafted features. In this paper we propose to use CNNs to learn multiple deep features from different cues of the face to integrate different complementary information. Experiments show that our approach can outperform state-of-the-art approaches.
虽然现有的方法探索了人脸反欺骗的各种信息,但它们大多只使用了面部的单一线索信息。虽然有几种方法[11,13]确实探索了人脸的多个线索来进行反欺骗,但它们只采用手工制作的特征(hand-crafted features.)。本文提出利用神经网络从人脸的不同线索中学习多个深层特征,以整合不同的互补信息( complementary information),实验表明,该方法优于现有的最先进的方法。
Below we detail the proposed method in Sect. 2. Then we present the experimental results in Sect. 3. And in Sect. 4 some conclusions are drawn.
下面我们I在Sect 2中详细介绍了所提出的方法。在Sect.3中给出了实验结果。并在Sec.4中得出了一些结论。
2 The Proposed Method(提出的方法)
In this paper, we aim to exploit three types of information, i.e. the temporal information, the color information and local information, for face anti-spoofing. As shown in Fig. 1, the face detector proposed in [2] is firstly applied to detect and crop the face from a given image. Then we use CNNs to learn three deep features from different cues of the face. Specifically, we learned temporal feature from the image sequences, the color based feature from different color spaces and the patch based local feature from the local patches. Each CNN learning process is supervised by a binary softmax classifier. Considering all the multiple features are complementary to another, we further propose a strategy to integrate all of the features: the class probabilities output by the softmax function of each CNN are concatenated as a class probability vector, which is then fed into SVM for classification.
本文旨在利用三种类型的信息,即时间信息、颜色信息和局部信息,用于人脸防欺骗,如图所示。首先利用文[2]中提出的人脸检测器从给定的图像中检测和裁剪人脸,然后利用神经网络从人脸的不同线索中学习三个深层特征,具体而言,是从图像序列中学习时间特征,从不同颜色空间中学习基于颜色的特征,从局部斑块中学习基于补丁的局部特征。
每个CNN学习过程都由一个二进制的Softmax分类器来监督。考虑到所有的多个特征都是互补的,我们进一步提出了一种整合所有特征的策略:将每个CNN的Softmax函数输出的类别概率作为类别概率向量连接起来,然后输入svm进行分类。

图1、提出的多深度特征法
2.1 Multiple Deep Features(多深特征)
Temporal Feature. Here we introduce a strategy to exploit the temporal information between image frames in the video sequence. Specifically, we first convert three color images at different temporal positions into three gray images, and then stack the gray images as a whole sample and feed the stacked volume into the CNN. Figure 2 shows an example volume stacked by three gray images.
时间特征。在这里,我们介绍了一种利用视频序列中图像帧间时间信息的策略。具体而言,我们首先将三幅不同时间位置的彩色图像转换成三幅灰度图像,然后将灰度图像作为一个整体叠加,并将叠加的体积输入到cnn中。图2显示了一个由三幅灰度图像叠加的示例卷。

图2.CASIA数据库中由三幅灰度图像叠加的卷。
Color Based Feature. It was demonstrated in [12] that the color information in the HSV and YCbCr color spaces were more discriminative than that in the RGB space for face anti-spoofing. But [12] used hand-crafted features (i.e. LBP features) to encode these color information. Here we use CNN to learn high-level color-based features from the RGB, HSV and YCbCr color spaces, respectively. For the HSV (or YCbCr) color space, we first convert the RGB image into the HSV (or YCbCr) color space and then feed the converted image into the CNNs for feature learning. Figure 3 shows an example face with different color spaces i.e. RGB, HSV and YCbCr.
基于颜色的特征。在[12]中证明,HSV和YCbCr颜色空间中的颜色信息比RGB空间中的颜色信息更具识别性。但是,[12]使用手工绘制的特征(即LBP特征)对这些颜色信息进行编码。在这里,我们使用CNN从RGB、HSV和YCbCr颜色空间分别学习高级基于颜色的特征。对于HSV(或YCbCr)颜色空间,我们分别学习了 HSV(或YCbCr)颜色空间中的高级颜色特征。首先将RGB图像转换为HSV( 或YCbCr)颜色空间,然后将转换后的图像输入CNN进行特征学习。图3显示了一个具有不同颜色空间的示例脸,即RGB、HSV和YCbCr。

图3、不同颜色空间的示例图像,即rgb、hsv和ycbcr。第一行显示真实的面部图像,第二行显示扭曲的打印照片脸图像,第三行显示剪切打印的照片脸图像,最后一行显示重放视频人脸图像。所有示例图像都从CAASA数据库中取样。
Patch Based Local Feature. While the temporal and color features are mainly learnt from the whole face images, important local information could be missing. In order to exploit the local information, we divided the face image into a number of patches with the same size for local feature representation. A set of ten patches with size 96 × 96 are randomly cropped from training faces and then used to train the network. Figure 4 shows a set of patches cropped from an example face.
基于补丁的局部特征。既然人脸图像的时间特征和颜色特征主要是从整个人脸图像中提取出来的,那么也可能会丢失重要的局部信息。为了利用局部信息,我们将人脸图像分成若干个大小相同的斑块进行局部特征表示。从训练人脸中随机裁剪出大小为96×96的10个斑块,然后进行训练。图4显示了从示例脸上裁剪的一组斑块(patches)。

图4、CASIA数据库中的面部斑块(patches)样本
2.2 Network Architecture
In our work, we employ the 18-layer residual network (ResNet) [16] as the CNN.However, the last 1000-unit softmax layer (originally designed to predict 1000 classes) is replaced by a 2-unit softmax layer, which assigns a score for genuine and spoof classes. A brief illustration of the network architecture is shown in Fig. 5. The network consists of seventeen convolutional (conv) layers and one fully-connected (fc) layer. The orange, green, dark green and red rectangles represent the convolutional layer, max pooling layer, average pooling layer and fully-connected layer, respectively. The purple rectangle represents BatchNorm (BN) and ReLU layers. As shown in Fig. 6, the light blue rectangle represents residual blocks 1 (RB1), and the dark blue rectangle represents residual blocks 2 (RB2).
在我们的工作中,我们使用18层残差网络(RESNET)[16]作为CNN。然而,最后1000个单元的Softmax层(最初设计是用于预测1000个类)被一个2单元的Softmax层所取代,该层为真正的和伪造的类分配了一个分数。图5中展示出了网络体系结构的简要说明。该网络由17个卷积(Conv)层和1个全连通(FC)层组成,橙色、绿色、深绿色和红色矩形分别表示卷积层、最大池化层、平均池层和完全连接层。紫色矩形表示批次规范(BatchNorm---BN)和relu层。如图6所示,浅蓝矩形表示残差块1(RB1),深蓝色矩形表示残差块2(RB2)。

图5.网络架构。(在线彩色图形)

图6、左:残差块1,右:残差块2。(在线彩色图形)
2.3 SVM Classification with Integration of Multiple Deep Features(多深度特征集成的支持向量机分类)
Different features capture different characteristics of the face and are complementary to each other. So we perform the classification with the integration of all multiple features. As shown in Fig. 1, each CNN can output a probability of whether the given face belongs to the genuine class or the spoof class. Then the class probabilities output by the softmax function of each CNN are concatenated as a class probability vector and then fed into SVM for classification. Given a video with N frames, N class probability vectors can be generated, then the video can be classified using the average of these class probability vectors.
不同的特征捕捉不同的面部特征,并相互补充。所以我们把所有的多个特征结合起来进行分类,如图1所示,每个CNN都可以输出给定人脸属于真实类或欺骗类的概率,然后将每个CNN的Softmax函数输出的类概率作为类概率向量串联起来,然后输入svm进行分类。给定具有n帧的视频,可以生成n个类概率向量,然后利用这些类概率向量的平均值对视频进行分类。
3 Experiments(实验)
3.1 Datasets and Protocol(数据集以及协议)
In this paper, the experiments were conducted on three databases, i.e.CASIA FASD, OULU-NPU and REPLAY-MOBILE databases, whose details are summarized in
Table 1.
本文在CASIA FASD、OULU-NPU和回放移动数据库三个数据库上进行了实验,详细情况见表1。

表1.三个面欺骗数据库的汇总。
CASIA FASD Database. The CASIA FASD (face anti-spoofing database) [4] contains 600 genuine and spoof videos of 50 subjects, 12 videos (3 genuine and 9 spoof) were captured for each subject. This database consists of three imaging qualities and attacks, i.e. the warped photo attack, the cut photo attack (hides behind the cut photo and blink, another intact photo is up-down moved behind the cut one) and video attack. In [4], they design 7 testing scenarios, i.e. three imaging qualities, three fake face types and overall data (all data are used). In our experiments, we use all the videos (overall scenarios). The training and the test set consist of 20 subjects (60 live videos and 180 attack videos) and 30 subjects (90 live videos and 270 attack videos), respectively. As shown in Fig. 7, we detected and aligned faces in the video with the detector from MTCNN [2] and cropped them to 256 × 256. The same face alignment and cropping way also applied to the following two databases.
CASIA FASD 数据库。 CASIA FASD (face anti-spoofing database---脸反欺骗数据库)[4]包含600个真假视频,每个人物捕获12个视频(3个真假和9个伪造),该数据库由三种成像质量和攻击组成,即扭曲的照片攻击、剪切的照片攻击(隐藏在剪切的照片后面并眨眼,另一张完整的照片被上下移动到剪接的后面)和视频攻击。在[4]中,他们设计了7种测试场景,即三种成像质量、三种假人脸类型和总体数据(所有数据都使用)。在实验中,我们使用所有的视频(总体场景),训练和测试集分别由20名受试者(60名真实视频和180名攻击视频)和30名受试者(90名真实视频和270名攻击视频)组成,如图7所示.我们用MTCNN[2]中的检测器检测和校准了视频中的人脸,并将它们裁剪成256×256 。同样的人脸对齐和裁剪方式也应用于以下两个数据库。
REPLAY-MOBILE Database. The REPLAY-MOBILE database [6] consists of 1190 videos of 40 subjects, i.e. 16 attack videos for each subject. This database has five different mobile scenarios, including the background of the scene that is uniform or complex, lighting conditions. Real client accesses were recorded under five different lighting conditions (controlled, adverse, direct, lateral and diffuse) [6]. In our experiments, we use 120 genuine videos and 192 spoof videos for training. The development set contains 160 real videos and 256 attack videos, and there are 110 live videos and 192 fake videos in the test set.
REPLAY-MOBILE数据库。 REPLAY-MOBIL数据库[6]由40个被试者的1190个视频组成,每个被试者有16个攻击视频。该数据库有五种不同的移动场景,包括均匀或复杂的场景背景、光照条件。在五种不同的照明条件下(受控的、不利的、直接的、横向的和漫射的--controlled, adverse, direct, lateral and diffuse)记录真实的客户通路[6]。在我们的实验中,我们使用120个真正的视频和192张假视频进行训练。开发集包含160个真实视频和256个攻击视频,测试集中有110个真实视频和192个假视频。
OULU-NPU Database. The OULU-NPU database [5] consists of 5940 real access and attack videos of 55 subjects (15 female and 40 male). The attacks contain both print and video-replay attacks. Furthermore, the print and video-replay attacks were produced using two different printers and display devices. We use 4950 genuine and spoof videos in the public set [5] for testing. This database has three sessions with different illumination conditions, six different smartphones and four kinds of attacks, which has 90 videos for each client. The database is divided into three disjoint subsets, i.e. training set (20 users), development set (15 users) and testing set (20 users). In our experiments, two protocols were employed to evaluate the robustness of the proposed algorithm, i.e. protocol 1 for illumination variation and protocol 2 for presentation attack instruments (PAI) variation.
OULU-NPU数据库。 OULU-NPU数据库[5]包括5940个真实访问和攻击视频,包括55名受试者(15名女性和40名男性),攻击包括打印和视频重播攻击。此外,打印和视频重播攻击是使用两种不同的打印机和显示设备产生的。我们使用4950真实和欺骗视频在公共集[5]进行测试。这个数据库有三个会话(sessions),在不同的照明条件,六部不同的智能手机和四种攻击下,每个人物有90个视频。将数据库划分为训练集(20用户)、开发集(15用户)和测试集(20用户)三个不相交子集,实验中采用两种协议对算法的鲁棒性进行了评估,即光照变化协议1和表示攻击工具((PAI))协议2。
3.2 Performance Metrics(性能标准)
FAR (False Acceptance Rate) [3] is the ratio of the number of false acceptances and the number of negative samples. FRR (False Rejection Rate) is the ratio of the number of false rejections and the number of positive samples. The EER is the point in the ROC curve where the FAR equals the FRR. In our experiment, the results of CASIA-FASD are reported in EER. The Replay-mobile and OULU-NPU database are reported using the standardized ISO/IEC 30107-3 metrics [18], i.e. APCER (Attack Presentation Classification Error Rate) and BPCER (Bona Fide Presentation Classification Error Rate). The ACER (Average Classification Error Rate) is half of the sum of the APCER and the BPCER.
假接受率(FAR)[3]是错误接受数与阴性样本数之比,假拒绝率(FRR)为假拒绝次数与阳性样本数之比。EER是ROC曲线中FAR等于FRR的点。在我们的实验中, CASIA-FASD的结果使用EER指标。使用标准化的ISO/IEC 30107-3度量标准[18]来报告Replay-mobile和 OULU-NPU数据库[18],即APCER (Attack Presentation Classification Error Rate---攻击呈现分类错误率)和BPCER(Bona Fide Presentation Classification Error Rate---善意表示分类错误率),ACER(平均分类错误率)是 APCER和 BPCER之和的一半。
3.3 Experimental Settings(实验设置)
As the number of samples in publicly available datasets is very limited, CNN could easily over-fit when trained from scratch. So we fine-tune the ResNet-18 [16] model pre-trained on the ImageNet database. The proposed framework is implemented using the Caffe toolbox [19]. Size of input images is 256 × 256. The network is trained with a mini-batch size of 64. In the training of CNN, the learning rate is 0.0001; the decay rate is 0.0005; and the momentum during training is 0.9. These parameters are constant in our experiments.
由于公开数据集中的样本数量非常有限,CNN在从头开始的训练中很容易变得过于适合。因此,我们微调RESNET-18[16]模型,在ImageNet数据库上进行预培训。该框架是使用caffe工具箱[19]实现的。输入图像大小为256×256。在cnn的训练中,学习率为0.0001,衰减率为0.0005,训练过程中的动量为0.9时,这些参数在我们的实验中是恒定的。
3.4 Results(结果)
We first use the CASIA-FASD dataset to test the performance of different features, i.e. the temporal feature, the color based features in three different color space (RGB, HSV, and YCbCr), the patch based local feature, and their fusion. Table 2 details the EERs of different features on CASIA-FASD. It can be observed from the table that when only single feature is used, patch based local feature achieves the best performance, i.e. EER of 2.59%. After we fuse all different features, the EER is further reduced to 2.22%. This validates the proposed multiple deep feature method. Then we compare the proposed multiple deep feature method with the state of the art in Table 3. As shown in Table 3, our approach achieves the lowest EER among all of the approaches.
我们首先使用CASIA-FASD数据集来测试不同特征的性能,即时间特征、三种不同颜色空间(RGB、HSV和ycbcr)中基于颜色的特征、基于补丁的局部特征及其融合。表2详细介绍了 CASIA-FASD上不同特征的EERs,从表中可以看出,当只使用单一特征时,基于斑块的局部特征的性能最好,为2.59%。在融合了所有不同的特征后,EER进一步降低到2.22%,验证了本文提出的多深度特征方法的有效性。然后,我们将所提出的多深度特征方法与表3中的最新技术进行了比较。如表3所示,我们的方法达到了所有方法中的最低EER。

表2、不同特征在Casua-FASD数据库上的性能。
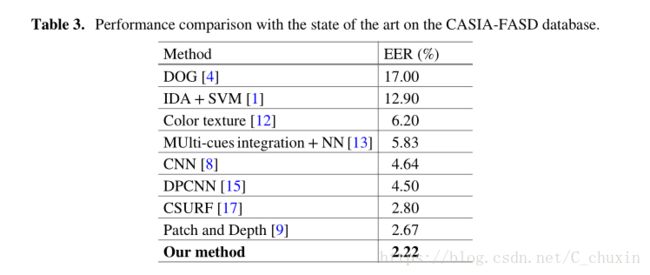
表3、在CASIA-FASD数据库中与最先进技术的性能比较。
Tables 4 and 5 lists the results of the proposed approach and the other methods on the REPLAY-MOBILE and the OULU-NPU databases, respectively. For the REPLAY-MOBILE database, our approach achieves much better performance than IQM and Gabor, i.e. no error was recorded. For the OULU-NPU dataset, the ACER on protocol 1 and 2 for our proposed method are 3.2% and 2.4%, respectively, which are much better than that of CPqD and GRADIANT. Overall, with the above experiments we can demonstrate the superiority of the proposed approach over the other methods.
表4和表5分别列出了所提出的方法和其他方法在REPLAY-MOBILE数据库和OULU-NPU数据库上的结果。对于 REPLAY-MOBILE数据库,我们的方法获得了比IQM和Gabor更好的性能,即没有错误记录。对于 OULU-NPU数据集,我们提出的方法在协议1和协议2上的ACER分别为3.2%和2.4%,远远优于CPQD和梯度算法。总之,通过以上的实验,我们可以证明所提出的方法比其他方法的优越性。
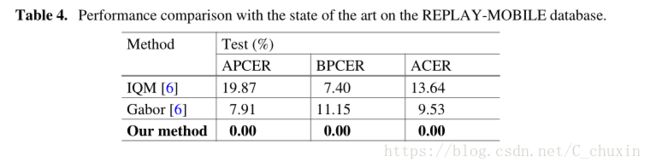
表4、在 REPLAY-MOBILE数据库中与最先进技术的性能比较。
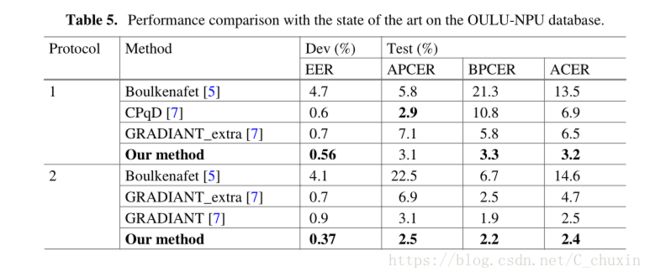
表4、在 OULU-NPU数据库中与最先进技术的性能比较。
4 Conclusions(结论)
In this paper, we proposed to employ the CNNs to learn discriminative multiple deep features from different cues of the face for face anti-spoofing. Because theses multiple features are complementary to each other, we further presented a strategy to integrate all the multiple features to boost the performance. We evaluated the proposed approach in three public databases and the experimental results demonstrated that the proposed approach can outperform the state of the art for face anti-spoofing. Regarding to the future work, we will conduct more cross-dataset experiments to investigate the generalization ability of the proposed method.
在本文中,我们提出了利用cnn来学习人脸不同线索的鉴别多深度特征,因为这些多特征是互补的,因此我们进一步提出了一种综合所有多个特征以提高性能的策略。我们在三个公共数据库中进行了评价,而实验结果表明,该方法在抗人脸欺骗方面具有较好的性能。针对未来的工作,我们将进行更多的交叉数据集实验,考察该方法的泛化能力。
Acknowledgments. The work is supported by Natural Science Foundation of China under grands No. 61672357 and U1713214.
特别鸣谢。这项工作得到中国自然科学基金的支持,地块编号为61672357和U 1713214。
References(参考文献)
1. Wen, D., Han, H., Jain, A.K.: Face spoof detection with image distortion analysis. IEEE Trans. Inf. Forensics Secur. 10(4), 746–761 (2015)
2. Zhang, K., Zhang, Z., Li, Z., Qiao, Y.: Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process. Lett. 23(10), 1499–1503 (2016)
3. Bengio, S., Mariéthoz, J.: A statistical significance test for person authentication. In: The Speaker and Language Recognition Workshop (Odyssey), pp. 237–244, Toledo (2004)
4. Zhang, Z., Yan, J., Liu, S., Lei, Z., Yi, D., Li, S. Z.: A Face antispoofing database with diverse attacks. In: IAPR International Conference on Biometrics, pp. 26–31 (2012)
5. Boulkenafet, Z., Komulainen, J., Li, L., Feng, X., Hadid, A.: OULU-NPU: a mobile face presentation attack database with real-world variations. In: IEEE International Conference on Automatic Face and Gesture Recognition, pp. 612–618 (2017)
6. Costa-Pazo, A., Bhattacharjee, S., Vazquez-Fernandez, E., Marcel, S.: The replay-mobile face presentation-attack database. In: Biometrics Special Interest Group (2016)
7. Boulkenafet, Z., Komulainen, J., Akhtar, Z., Benlamoudi, A., Samai, D., Bekhouche, S., et al.: A competition on generalized software-based face presentation attack detection in mobile scenarios. In: IEEE International Joint Conference on Biometrics (2017)
8. Yang, J., Lei, Z., Li, S.Z.: Learn convolutional neural network for face anti-spoofing. Comput. Sci. 9218, 373–384 (2014)
9. Atoum, Y., Liu, Y., Jourabloo, A., Liu, X.: Face Anti-spoofing using patch and depth-based CNNs. In: IEEE International Joint Conference on Biometrics (2018)
10. Boulkenafet, Z., Komulainen, J., Hadid, A.: Face spoofing detection using colour texture analysis. IEEE Trans. Inf. Forensics Secur. 11(8), 1818–1830 (2016)
11. Wang, Y., Nian, F., Li, T., Meng, Z., Wang, K.: Robust face anti-spoofing with depth information. J. Vis. Commun. Image Represent. 49, 332–337 (2017)
12. Boulkenafet, Z., Komulainen, J., Hadid, A.: Face anti-spoofing based on colour texture analysis. In: IEEE International Conference on Image Processing, pp. 2636–2640 (2015)
13. Feng, L., Po, L.M., Li, Y., Xu, X., Yuan, F., Cheung, C.H., et al.: Integration of image quality and motion cues for face anti-spoofing. J. Vis. Commun. Image Represent. 38(2), 451–460 (2016)
14. Pan, G., Sun, L., Wu, Z., Lao, S.: Eyeblink-based anti-spoofing in face recognition from a generic webcamera. In: IEEE International Conference on Computer Vision, pp. 1–8 (2007)
15. Li, L., Feng, X., Boulkenafet, Z., Xia, Z., Li, M., Hadid, A.: An original face anti-spoofing approach using partial convolutional neural network. In: International Conference on Image Processing Theory TOOLS and Applications, pp. 1–6. IEEE (2017)
16. He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp. 770–778 (2016)
17. Boulkenafet, Z., Komulainen, J., Hadid, A.: Face antispoofing using speeded-up robust features and fisher vector encoding. IEEE Sig. Process. Lett. 24, 141–145 (2017)
18. ISO/IEC JTC 1/SC 37 Biometrics. Information technology - Biometric Presentation attack detection - Part 1: Framework. International Organization for Standardization (2016)
19. Jia, Y., Shelhamer, E., Donahue, J., Karayev, S., Long, J., Girshick, R., et al.: Caffe: convolutional architecture for fast feature embedding. In: 22nd ACM International Conference on Multimedia, pp. 675–678. ACM (2014)