cJSON的模拟实现
CJSON
CJSON是C语言的一个编解码工具,JSON是一种轻量级数据交换格式(基于JavaScript的一个子集)
CJSON主要功能:
构建和解析 json格式,发送的数据用json封装,收到数据再以json格式解析
优点:轻量级、速度快
缺点:功能上不够强大
1、CJSON的六种基本类型
NULL、布尔型、数值型、字符型、数组、对象.(object)
减少在解析是传递多个参数的问题
将字符串解析至json类型的结构体中
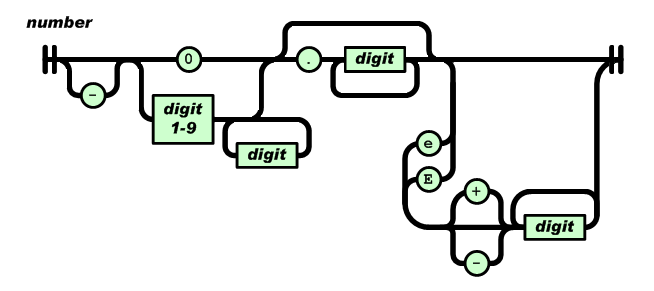
1、解析数值:
注意数字的语法,最开始不能有+, 可以时科学计数法等
通过对数值语法的判断和库函数strtod()将字符串转为double数值
通过状态机完成判断,用double类型存储数值:
2、解析字符串:
由于有转义字符、非转义字符和\uXXXX等特殊字符等,引入码点的概念。
注意:在json语法中允许有空字符的存在。所有我们加入记录字符串长度的变量,由于C语言的字符串都以\0结尾,所以我们在字符串结尾也加入\0。
解析字符串(以及之后的数组、对象)时,需要把解析的结果先储存在一个临时的缓冲区,最后再用lept_set_string() 把缓冲区的结果设进值之中,所以在lept_context结构中引入由字符串实现的栈结构。在解析前初始化栈结构,解析后释放栈空间。
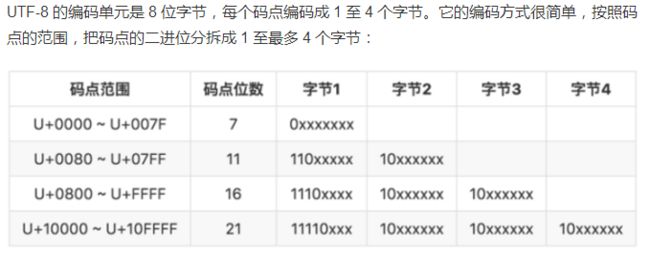
Unicode编码:
由于不止有Ascll字符,还有中文。韩文等许多字符,所以引入Unicode编码,Unicode使每个字符映射唯一码点,码点的范围是0~0x10FFFF。码点通常记做U+XXXX,后面的X表示四位16进制数字。Unicode制定了各种存储码点的方式,UTF会将一个码点存至一个或多个编码单元,比如UTF_8的编码单元为8位的字节(可变长编码 )。
对于编码的存储:
1、非转义字符直接存储
2、U+0000~U+FFFF:解析4位16进制,存至一至四个字节
3、大于0xFFFF的属于代理对,即通过公式将高代理项和低代理项得出码点,然后将码点转换为UTF-8编码。
3、数组的解析:
JSON 数组的语法很简单,实现的难点不在语法上,而是怎样管理内存
存储 JSON 数组类型的数据结构:数组。
我们将会通过之前在解析字符串时实现的堆栈,来解决解析 JSON 数组时未知数组大小的问题
4、对象的解析:
五步:
第 1 步是利用刚才重构出来的 lept_parse_string_raw() 去解析键的字符串
第 2 步是解析冒号,冒号前后可有空白字符:
第 3 步是解析任意的 JSON 值。这部分与解析数组一样,递归调用 lept_parse_value(),把结果写入临时 lept_member 的 v 字段,然后把整个 lept_member 压入栈:
第 4 步,解析逗号或右花括号。遇上右花括号的话,当前的 JSON 对象就解析完结了,我们把栈上的成员复制至结果,并直接返回:
最后,当 for (;;) 中遇到任何错误便会到达这第 5 步,要释放临时的 key 字符串及栈上的成员
生成器:
将json类型的结构体生成字符串
JSON 生成器(generator)负责相反的事情,就是把树形数据结构转换成 JSON 文本。这个过程又称为「字符串化(stringify)」。
在实现 JSON 解析时,我们加入了一个动态变长的堆栈,用于存储临时的解析结果。而现在,我们也需要存储生成的结果,所以最简单是再利用该数据结构,作为输出缓冲区。
单元测试:
测试驱动开发TDD(即先写测试用例,再写代码满足测试用例):
步骤:
1. 加入一个测试。
2. 运行所有测试,新的测试应该会失败。
3. 编写实现代码。
4. 运行所有测试,若有测试失败回到3。
5. 重构代码。
6. 回到 1。
项目难点:
1、数字的校验:
虽然#include库函数strtod()可以将字符串转化为数值,但是不符合json语法的字符串在strtod函数中可以有效转换,所以需要先对字符串格式进行校验,合法后再进行转换
2、字符串的解析:
在json语法中允许出现空字符,为了解决该问题,我们分配内存存储解析后的字符串,并且存储字符串的长度,考虑C语言字符串以空结尾,故在最后我们还需要再加一个空字符。
对字符串的解析是动态申请的堆内存,所以在最后我们要调用lept_free()函数释放内存。
3、引入Unicode编码:
引入了Unicode编码,对转移字符的解析,将码点转换为UTF-8存储,并且有代理项的特殊情况需要计算出码点后再转化为UTF-8存储。
4、释放内存时需要对数组和对象类型进行递给释放。
cJSON.c文件
测试文件:
CJSON是C语言的一个编解码工具,JSON是一种轻量级数据交换格式(基于JavaScript的一个子集)
CJSON主要功能:
构建和解析 json格式,发送的数据用json封装,收到数据再以json格式解析
优点:轻量级、速度快
缺点:功能上不够强大
1、CJSON的六种基本类型
NULL、布尔型、数值型、字符型、数组、对象.(object)
json类型的结构---存储各种类型的单元
struct lept_value //json树结点的类型
{
//因为一个值不能同为数字和字符串,联合体节省空间
union{
struct { lept_member* m; size_t size; }o;
struct { lept_value* e; size_t size; }a; //array
struct { char* s; size_t len; }s; //string
double n; //number
}u;
lept_type type;
};减少在解析是传递多个参数的问题
typedef struct{
const char* json;
char* stack; //该栈按字节存储---动态的栈结构
size_t size, top; //size为栈的大小,top为栈顶
}lept_context;struct lept_member
{
char* k; //对象的键值key
size_t klen; //键值的长度
lept_value v; //对象的value
};将字符串解析至json类型的结构体中
1、解析数值:
注意数字的语法,最开始不能有+, 可以时科学计数法等
通过对数值语法的判断和库函数strtod()将字符串转为double数值
通过状态机完成判断,用double类型存储数值:
2、解析字符串:
由于有转义字符、非转义字符和\uXXXX等特殊字符等,引入码点的概念。
注意:在json语法中允许有空字符的存在。所有我们加入记录字符串长度的变量,由于C语言的字符串都以\0结尾,所以我们在字符串结尾也加入\0。
解析字符串(以及之后的数组、对象)时,需要把解析的结果先储存在一个临时的缓冲区,最后再用lept_set_string() 把缓冲区的结果设进值之中,所以在lept_context结构中引入由字符串实现的栈结构。在解析前初始化栈结构,解析后释放栈空间。
Unicode编码:
由于不止有Ascll字符,还有中文。韩文等许多字符,所以引入Unicode编码,Unicode使每个字符映射唯一码点,码点的范围是0~0x10FFFF。码点通常记做U+XXXX,后面的X表示四位16进制数字。Unicode制定了各种存储码点的方式,UTF会将一个码点存至一个或多个编码单元,比如UTF_8的编码单元为8位的字节(可变长编码 )。
对于编码的存储:
1、非转义字符直接存储
2、U+0000~U+FFFF:解析4位16进制,存至一至四个字节
3、大于0xFFFF的属于代理对,即通过公式将高代理项和低代理项得出码点,然后将码点转换为UTF-8编码。
3、数组的解析:
JSON 数组的语法很简单,实现的难点不在语法上,而是怎样管理内存
存储 JSON 数组类型的数据结构:数组。
我们将会通过之前在解析字符串时实现的堆栈,来解决解析 JSON 数组时未知数组大小的问题
4、对象的解析:
五步:
第 1 步是利用刚才重构出来的 lept_parse_string_raw() 去解析键的字符串
第 2 步是解析冒号,冒号前后可有空白字符:
第 3 步是解析任意的 JSON 值。这部分与解析数组一样,递归调用 lept_parse_value(),把结果写入临时 lept_member 的 v 字段,然后把整个 lept_member 压入栈:
第 4 步,解析逗号或右花括号。遇上右花括号的话,当前的 JSON 对象就解析完结了,我们把栈上的成员复制至结果,并直接返回:
最后,当 for (;;) 中遇到任何错误便会到达这第 5 步,要释放临时的 key 字符串及栈上的成员
生成器:
将json类型的结构体生成字符串
JSON 生成器(generator)负责相反的事情,就是把树形数据结构转换成 JSON 文本。这个过程又称为「字符串化(stringify)」。
在实现 JSON 解析时,我们加入了一个动态变长的堆栈,用于存储临时的解析结果。而现在,我们也需要存储生成的结果,所以最简单是再利用该数据结构,作为输出缓冲区。
单元测试:
测试驱动开发TDD(即先写测试用例,再写代码满足测试用例):
步骤:
1. 加入一个测试。
2. 运行所有测试,新的测试应该会失败。
3. 编写实现代码。
4. 运行所有测试,若有测试失败回到3。
5. 重构代码。
6. 回到 1。
项目难点:
1、数字的校验:
虽然#include
2、字符串的解析:
在json语法中允许出现空字符,为了解决该问题,我们分配内存存储解析后的字符串,并且存储字符串的长度,考虑C语言字符串以空结尾,故在最后我们还需要再加一个空字符。
对字符串的解析是动态申请的堆内存,所以在最后我们要调用lept_free()函数释放内存。
3、引入Unicode编码:
引入了Unicode编码,对转移字符的解析,将码点转换为UTF-8存储,并且有代理项的特殊情况需要计算出码点后再转化为UTF-8存储。
4、释放内存时需要对数组和对象类型进行递给释放。
源码:
cJSON.h文件
#ifndef _LEPTJSON_H__
#define _LEPTJSON_H__
#include /* size_t */
typedef enum //枚举json的6种数据类型
{
LEPT_NULL,
LEPT_FALSE,
LEPT_TRUE,
LEPT_NUMBER,
LEPT_STRING,
LEPT_ARRAY,
LEPT_OBJECT
}lept_type;
typedef struct lept_value lept_value;
typedef struct lept_member lept_member;
struct lept_value //json树结点的类型
{
//因为一个值不能同为数字和字符串,联合体节省空间
union{
struct { lept_member* m; size_t size; }o;
struct { lept_value* e; size_t size; }a; //array
struct { char* s; size_t len; }s; //string
double n; //number
}u;
lept_type type;
};
struct lept_member
{
char* k; //对象的键值key
size_t klen; //键值的长度
lept_value v; //对象的value
};
//状态码
enum{
LEPT_PARSE_OK = 0, //无错误
LEPT_PARSE_EXPECT_VALUE, //若一个JSON只有空白
LEPT_PARSE_INVALID_VALUE, //若不是json的6中数据类型
LEPT_PARSE_ROOT_NOT_SINGULAR, //若一个值之后,空白之后还有其他字符
LEPT_PARSE_NUMBER_TOO_BIG, //数值太大
LEPT_PARSE_MISS_QUOTATION_MARK, //遇到字符串结束标记
LEPT_PARSE_INVALID_STRING_ESCAPE,//非法转义字符
LEPT_PARSE_INVALID_STRING_CHAR, //非法字符
LEPT_PARSE_INVALID_UNICODE_HEX, //\u后不是4位16进制
LEPT_PARSE_INVALID_UNICODE_SURROGATE, //unicode不在合法范围
LEPT_PARSE_MISS_COMMA_OR_SQUARE_BRACKET, //数组漏掉逗号或中括号
LEPT_PARSE_MISS_KEY, //漏掉了键值
LEPT_PARSE_MISS_COLON, //漏掉了冒号
LEPT_PARSE_MISS_COMMA_OR_CURLY_BRACKET //漏掉了逗号或大括号
};
#define lept_init(v) do{ (v)->type = LEPT_NULL; }while(0)
int lept_parse(lept_value* v, const char* json); //解析JSON---传入一个字符串,返回枚举类型错误码
char* lept_stringify(const lept_value* v, size_t* length); //将六种类型生成字符串返回
void lept_free(lept_value* v); //清空v里面可能分配的内存
lept_type lept_get_type(const lept_value* v); //访问结果的接口---获取类型
#define lept_set_null(v) lept_free(v)
int lept_get_boolean(const lept_value* v);
void lept_set_boolean(lept_value* v, int b);
double lept_get_number(const lept_value* v); //获取数值的接口
void lept_set_number(lept_value* v, double n);
const char* lept_get_string(const lept_value* v);
size_t lept_get_string_length(const lept_value* v);
void lept_set_string(lept_value* v, const char* s, size_t len); //将s复制一份至v
size_t lept_get_array_size(const lept_value* v);
lept_value* lept_get_array_element(const lept_value* v, size_t index); //获取数组下标对应的地址
size_t lept_get_object_size(const lept_value* v);
const char* lept_get_object_key(const lept_value* v, size_t index);
size_t lept_get_object_key_length(const lept_value* v, size_t index);
lept_value* lept_get_object_value(const lept_value* v, size_t index);
#endif //_LEPTJSON_H__
cJSON.c文件
#ifdef _WINDOWS
#define _CRTDBG_MAP_ALLOC
#include
#endif
#include "cJSON.h"
#include /* NULL, strtod() */
#include /* assert() */
#include /* errno, ERANGE */
#include /* HUGE_VAL */
#include
#ifndef LEPT_PARSE_STACK_INIT_SIZE
#define LEPT_PARSE_STACK_INIT_SIZE 256
#endif
#ifndef LEPT_PARSE_STRINGIFY_INIT_SIZE
#define LEPT_PARSE_STRINGIFY_INIT_SIZE 256
#endif
#define EXPECT(c, ch) do{ assert(*c->json == (ch)); c->json++; }while(0)
#define ISDIGIT(ch) ((ch) >= '0' && (ch) <= '9')
#define ISDIGIT1TO9(ch) ((ch) >= '1' && (ch) <= '9')
#define PUTC(c, ch) do{ *(char*)lept_context_push(c, sizeof(char)) = (ch); }while(0)
#define PUTS(c, s, len) memcpy(lept_context_push(c, len), s, len)
typedef struct{
const char* json;
char* stack; //该栈按字节存储
size_t size, top; //size为栈的大小,top为栈顶
}lept_context;
static void* lept_context_push(lept_context* c, size_t size) //扩容,返回栈顶指针
{
void* ret;
assert(size > 0);
if (c->top + size >= c->size)
{
if (c->size == 0)
c->size = LEPT_PARSE_STACK_INIT_SIZE;
while (c->top + size >= c->size)
c->size += c->size >> 1; /* c->size * 1.5 */
c->stack = (char*)realloc(c->stack, c->size);
}
ret = c->stack + c->top;
c->top += size; //返回将要入栈的位置,但top需要将即将入栈的字节加进去
return ret;
}
static void* lept_context_pop(lept_context* c, size_t size)
{
assert(c->top >= size);
return c->stack + (c->top -= size);
}
//ws = *(%x20 / %x09 / %x0A / %x0D)
static void lept_parse_whitespace(lept_context* c)
{
const char* p = c->json;
while (*p == ' ' || *p == '\t' || *p == '\n' || *p == '\r')
{
p++;
}
c->json = p;
}
//将null true false 三种类型合并处理
static int lept_parse_literal(lept_context* c, lept_value* v, char* src, int type)
{
assert(src != NULL);
int i = 0;
while (src[i] != '\0')
{
if (c->json[i] == src[i])
++i;
else
return LEPT_PARSE_INVALID_VALUE;
}
c->json += i;
v->type = type;
return LEPT_PARSE_OK;
}
static int lept_parse_number(lept_context* c, lept_value* v)
{
//strtod会将JSON认为的非法值正常转换---需要自行校验数值的合法性
const char* p = c->json;
//通过每一步if判断将不合法数值return
if (*p == '-')
p++;
if (*p == '0')
p++;
else // '+'
{
if (!ISDIGIT1TO9(*p))
return LEPT_PARSE_INVALID_VALUE;
for (p++; ISDIGIT(*p); p++);
}
if (*p == '.')
{
p++;
if (!ISDIGIT(*p))
return LEPT_PARSE_INVALID_VALUE;
for (p++; ISDIGIT(*p); p++);
}
if (*p == 'e' || *p == 'E')
{
p++;
if (*p == '+' || *p == '-')
p++;
if (!ISDIGIT(*p))
return LEPT_PARSE_INVALID_VALUE;
for (p++; ISDIGIT(*p); p++);
}
errno = 0;
v->u.n = strtod(c->json, NULL);
if (errno == ERANGE && (v->u.n == HUGE_VAL || v->u.n == -HUGE_VAL))
return LEPT_PARSE_NUMBER_TOO_BIG;
c->json = p;
v->type = LEPT_NUMBER;
return LEPT_PARSE_OK;
}
static const char* lept_parse_hex4(const char* p, unsigned* u) //解析4位16进制
{
int i = 0;
*u = 0;
for (i = 0; i < 4; ++i)
{
char ch = *p++;
*u <<= 4;
if (ch >= '0' && ch <= '9')
*u |= ch - '0';
else if (ch >= 'A' && ch <= 'F')
*u |= ch - ('A' - 10);
else if (ch >= 'a' && ch <= 'f')
*u |= ch - ('a' - 10);
else
return NULL;
}
return p;
}
static void lept_encode_utf8(lept_context* c, unsigned u) //将码点编成UTF-8,写入缓冲栈
{
if (u <= 0x7F)
PUTC(c, u & 0xFF);
else if (u <= 0x7FF)
{
PUTC(c, 0xC0 | ((u >> 6) & 0xFF));
PUTC(c, 0x80 | (u & 0x3F));
}
else if (u <= 0xFFFF)
{
PUTC(c, 0xE0 | ((u >> 12) & 0xFF));
PUTC(c, 0x80 | ((u >> 6) & 0x3F));
PUTC(c, 0x80 | (u & 0x3F));
}
else
{
assert(u <= 0x10FFFF);
PUTC(c, 0xF0 | ((u >> 18) & 0xFF));
PUTC(c, 0x80 | ((u >> 12) & 0x3F));
PUTC(c, 0x80 | ((u >> 6) & 0x3F));
PUTC(c, 0x80 | (u & 0x3F));
}
}
#define STRING_ERROR(ret) do{ c->top = head; return ret; }while(0)
static int lept_parse_string_raw(lept_context* c, char** str, size_t* len)
{
size_t head = c->top;
unsigned u = 0;
unsigned u2 = 0;
const char* p = NULL;
EXPECT(c, '\"');
p = c->json;
for (;;)
{
char ch = *p++;
switch (ch)
{
case '\"':
*len = c->top - head;
*str = lept_context_pop(c, *len);
c->json = p;
return LEPT_PARSE_OK;
case '\\':
switch (*p++)
{
case '\"':PUTC(c, '\"'); break;
case '\\':PUTC(c, '\\'); break;
case '/':PUTC(c, '/'); break;
case 'b':PUTC(c, '\b'); break;
case 'f':PUTC(c, '\f'); break;
case 'n':PUTC(c, '\n'); break;
case 'r':PUTC(c, '\r'); break;
case 't':PUTC(c, '\t'); break;
case 'u': //Unicode字符编码处理为UTF-8
if (!(p = lept_parse_hex4(p, &u)))
STRING_ERROR(LEPT_PARSE_INVALID_UNICODE_HEX);
if (u >= 0xD800 && u <= 0xDBFF) //代理对的处理
{
if (*p++ != '\\')
STRING_ERROR(LEPT_PARSE_INVALID_UNICODE_SURROGATE);
if (*p++ != 'u')
STRING_ERROR(LEPT_PARSE_INVALID_UNICODE_SURROGATE);
if (!(p = lept_parse_hex4(p, &u2)))
STRING_ERROR(LEPT_PARSE_INVALID_UNICODE_HEX);
if (u2 < 0xDC00 || u2 > 0xDFFF)
STRING_ERROR(LEPT_PARSE_INVALID_UNICODE_SURROGATE);
u = (((u - 0xD800) << 10) | (u2 - 0xDC00)) + 0x10000;
}
lept_encode_utf8(c, u);
break;
default:
STRING_ERROR(LEPT_PARSE_INVALID_STRING_ESCAPE);
}
break;
case '\0':
STRING_ERROR(LEPT_PARSE_MISS_QUOTATION_MARK);
default:
if ((unsigned char)ch < 0x20) //不合法字符
{
STRING_ERROR(LEPT_PARSE_INVALID_STRING_CHAR);
}
PUTC(c, ch);
break;
}
}
}
static int lept_parse_string(lept_context* c, lept_value* v)
{
int ret = 0;
char* s = NULL;
size_t len = 0;
if ((ret = lept_parse_string_raw(c, &s, &len)) == LEPT_PARSE_OK)
lept_set_string(v, s, len);
return ret;
}
static int lept_parse_value(lept_context* c, lept_value* v); //向前声明
static int lept_parse_array(lept_context* c, lept_value* v)
{
size_t size = 0;
int ret = 0;
EXPECT(c, '[');
lept_parse_whitespace(c);
if (*c->json == ']') //空数组
{
c->json++;
v->type = LEPT_ARRAY;
v->u.a.size = 0;
v->u.a.e = NULL;
return LEPT_PARSE_OK;
}
for (;;)
{
lept_value e; //将元素解析至临时变量e,再将e压栈
lept_init(&e);
if ((ret = lept_parse_value(c, &e)) != LEPT_PARSE_OK)
break;
memcpy(lept_context_push(c, sizeof(lept_value)), &e, sizeof(lept_value));
size++;
//解析完数组的一个元素
lept_parse_whitespace(c);
if (*c->json == ',')
{
c->json++;
lept_parse_whitespace(c);
}
else if (*c->json == ']')
{
c->json++;
v->type = LEPT_ARRAY;
v->u.a.size = size;
size *= sizeof(lept_value);
memcpy(v->u.a.e = (lept_value*)malloc(size), lept_context_pop(c, size), size);
return LEPT_PARSE_OK;
}
else
{
ret = LEPT_PARSE_MISS_COMMA_OR_SQUARE_BRACKET;
break;
}
}
//如果直接return错误码,堆栈还有值没有释放,会造成断言错误
size_t i = 0;
for (i = 0; i < size; ++i)
lept_free((lept_value*)lept_context_pop(c, sizeof(lept_value)));
return ret;
}
static int lept_parse_object(lept_context* c, lept_value* v)
{
size_t size = 0;
size_t i = 0;
lept_member m;
int ret = 0;
EXPECT(c, '{');
lept_parse_whitespace(c);
if (*c->json == '}')
{
c->json++;
v->type = LEPT_OBJECT;
v->u.o.m = NULL;
v->u.o.size = 0;
return LEPT_PARSE_OK;
}
m.k = NULL;
size = 0;
for (;;)
{
char* str;
lept_init(&m.v);
//parse key -> str -> m.k(缓冲区)
if (*c->json != '"')
{
ret = LEPT_PARSE_MISS_KEY;
break;
}
if ((ret = lept_parse_string_raw(c, &str, &m.klen)) != LEPT_PARSE_OK)
break;
m.k = (char*)malloc(m.klen + 1);
memcpy(m.k, str, m.klen);
m.k[m.klen] = '\0';
//parse ws colon ws
lept_parse_whitespace(c);
if (*c->json != ':')
{
ret = LEPT_PARSE_MISS_COLON;
break;
}
c->json++;
lept_parse_whitespace(c);
//parse value -> m.v(缓冲区) -> c.stack(缓冲区)
if ((ret = lept_parse_value(c, &m.v)) != LEPT_PARSE_OK)
break;
memcpy(lept_context_push(c, sizeof(lept_member)), &m, sizeof(lept_member));
size++;
m.k = NULL;
//prase 逗号或右大括号
lept_parse_whitespace(c);
if (*c->json == ',')
{
c->json++;
lept_parse_whitespace(c);
}
else if (*c->json == '}')
{
size_t s = sizeof(lept_member)*size;
c->json++;
v->type = LEPT_OBJECT;
v->u.o.size = size;
v->u.o.m = (lept_member*)malloc(s);
memcpy(v->u.o.m, lept_context_pop(c, s), s);
return LEPT_PARSE_OK;
}
else
{
ret = LEPT_PARSE_MISS_COMMA_OR_CURLY_BRACKET;
break;
}
}
/* Pop and free members on the stack */
free(m.k);
for (i = 0; i < size; ++i)
{
lept_member* m = (lept_member*)lept_context_pop(c, sizeof(lept_member));
free(m->k);
lept_free(&m->v);
}
v->type = LEPT_NULL;
return ret;
}
static int lept_parse_value(lept_context* c, lept_value* v)
{
switch (*c->json)
{
case 't':return lept_parse_literal(c, v, "true", LEPT_TRUE);
case 'f':return lept_parse_literal(c, v, "false", LEPT_FALSE);
case 'n':return lept_parse_literal(c, v, "null", LEPT_NULL);
case '\0':return LEPT_PARSE_EXPECT_VALUE;
case '"':return lept_parse_string(c, v);
case '[':return lept_parse_array(c, v);
case '{':return lept_parse_object(c, v);
default: return lept_parse_number(c, v);
}
}
//主解析函数
int lept_parse(lept_value* v, const char* json)
{
lept_context c;
int ret = 0;
assert(v != NULL);
c.json = json;
c.stack = NULL;
c.size = c.top = 0;
lept_init(v); //默认将类型置空,若是其他类型在lept_parse_value函数中会改变
lept_parse_whitespace(&c);
if ((ret = lept_parse_value(&c, v)) == LEPT_PARSE_OK)
{
lept_parse_whitespace(&c);
if (*c.json != '\0') //判断null后面是否还有值
{
v->type = LEPT_NULL;
return LEPT_PARSE_ROOT_NOT_SINGULAR;
}
}
assert(c.top == 0); //保证所有元素出栈
free(c.stack);
return ret;
}
static void lept_stringify_string(lept_context* c, const char* s, size_t len)
{
size_t i = 0;
assert(s != NULL);
PUTC(c, '"');
for (i = 0; i < len; ++i)
{
unsigned char ch = (unsigned char)s[i];
switch (ch)
{
case '\"':PUTS(c, "\\\"", 2); break;
case '\\':PUTS(c, "\\\\", 2); break;
case '\b':PUTS(c, "\\b", 2); break;
case '\f':PUTS(c, "\\f", 2); break;
case '\n':PUTS(c, "\\n", 2); break;
case '\r':PUTS(c, "\\r", 2); break;
case '\t':PUTS(c, "\\t", 2); break;
default:
if (ch < 0x20)
{
char buffer[7];
sprintf(buffer, "\\u%04X", ch);
PUTS(c, buffer, 6);
}
else
PUTC(c, s[i]);
}
}
PUTC(c, '"');
}
static void lept_stringify_value(lept_context* c, const lept_value* v)
{
size_t i = 0;
switch (v->type)
{
case LEPT_NULL: PUTS(c, "null", 4); break;
case LEPT_FALSE:PUTS(c, "false", 5); break;
case LEPT_TRUE: PUTS(c, "true", 4); break;
case LEPT_NUMBER:
c->top -= 32 - sprintf(lept_context_push(c, 32), "%.17g", v->u.n);
break;
case LEPT_STRING:
lept_stringify_string(c, v->u.s.s, v->u.s.len);
break;
case LEPT_ARRAY:
{
PUTC(c, '[');
for (i = 0; i < v->u.a.size; ++i)
{
if (i > 0)
PUTC(c, ',');
lept_stringify_value(c, &v->u.a.e[i]);
}
PUTC(c, ']');
}
break;
case LEPT_OBJECT:
{
PUTC(c, '{');
for (i = 0; i < v->u.o.size; ++i)
{
if (i > 0)
PUTC(c, ',');
lept_stringify_string(c, v->u.o.m[i].k, v->u.o.m[i].klen);
PUTC(c, ':');
lept_stringify_value(c, &v->u.o.m[i].v);
}
PUTC(c, '}');
}
break;
default:
assert(0 && "invalid type");
}
}
//将六种类型反解析成字符串返回
char* lept_stringify(const lept_value* v, size_t* length)
{
lept_context c;
assert(v != NULL);
c.stack = (char*)malloc(c.size = LEPT_PARSE_STRINGIFY_INIT_SIZE);
c.top = 0;
lept_stringify_value(&c, v);
if (length)
*length = c.top;
PUTC(&c, '\0');
return c.stack;
}
void lept_free(lept_value* v) //清空v里面可能分配的内存
{
size_t i = 0;
assert(v != NULL);
switch (v->type)
{
case LEPT_STRING:
free(v->u.s.s);
break;
case LEPT_ARRAY:
for (i = 0; i < v->u.a.size; ++i)
lept_free(&v->u.a.e[i]);
free(v->u.a.e);
break;
case LEPT_OBJECT:
for (i = 0; i < v->u.o.size; ++i)
{
free(v->u.o.m[i].k);
lept_free(&v->u.o.m[i].v);
}
free(v->u.o.m);
break;
default:
break;
}
v->type = LEPT_NULL;
}
lept_type lept_get_type(const lept_value* v)
{
assert(v != NULL);
return v->type;
}
int lept_get_boolean(const lept_value* v)
{
assert(v != NULL && (v->type == LEPT_TRUE || v->type == LEPT_FALSE));
return v->type == LEPT_TRUE;
}
void lept_set_boolean(lept_value* v, int b)
{
lept_free(v);
v->type = b ? LEPT_TRUE : LEPT_FALSE;
}
double lept_get_number(const lept_value* v)
{
assert(v != NULL && v->type == LEPT_NUMBER);
return v->u.n;
}
void lept_set_number(lept_value* v, double n)
{
lept_free(v);
v->u.n = n;
v->type = LEPT_NUMBER;
}
const char* lept_get_string(const lept_value* v)
{
assert(v != NULL && v->type == LEPT_STRING);
return v->u.s.s;
}
size_t lept_get_string_length(const lept_value* v)
{
assert(v != NULL && v->type == LEPT_STRING);
return v->u.s.len;
}
void lept_set_string(lept_value* v, const char* s, size_t len) //将s复制一份至v
{
assert(v != NULL && (s != NULL || len == 0));
lept_free(v);
v->u.s.s = (char*)malloc(len + 1);
memcpy(v->u.s.s, s, len);
v->u.s.s[len] = '\0';
v->u.s.len = len;
v->type = LEPT_STRING;
}
size_t lept_get_array_size(const lept_value* v)
{
assert(v != NULL && v->type == LEPT_ARRAY);
return v->u.a.size;
}
lept_value* lept_get_array_element(const lept_value* v, size_t index) //获取数组下标对应的地址
{
assert(v != NULL && v->type == LEPT_ARRAY);
assert(index < v->u.a.size);
return &v->u.a.e[index];
}
size_t lept_get_object_size(const lept_value* v)
{
assert(v != NULL && v->type == LEPT_OBJECT);
return v->u.o.size;
}
const char* lept_get_object_key(const lept_value* v, size_t index)
{
assert(v != NULL && v->type == LEPT_OBJECT);
assert(index < v->u.o.size);
return v->u.o.m[index].k;
}
size_t lept_get_object_key_length(const lept_value* v, size_t index)
{
assert(v != NULL && v->type == LEPT_OBJECT);
assert(index < v->u.o.size);
return v->u.o.m[index].klen;
}
lept_value* lept_get_object_value(const lept_value* v, size_t index)
{
assert(v != NULL && v->type == LEPT_OBJECT);
assert(index < v->u.o.size);
return &v->u.o.m[index].v;
} 测试文件:
#ifdef _WINDOWS
#define _CRTDBG_MAP_ALLOC
#include
#endif
#include
#include
#include
#include "cJSON.h"
static int main_ret = 0;
static int test_count = 0; //总数
static int test_pass = 0; //通过的数
#define EXPECT_EQ_BASE(equality, expect, actual, format)\
do{\
test_count++;\
if(equality)\
test_pass++;\
else{\
fprintf(stderr,"%s:%d: expect: " format " actual: " format "\n", __FILE__,__LINE__,expect,actual);\
main_ret = 1;\
}\
} while(0)
#define EXPECT_EQ_INT(expect, actual) EXPECT_EQ_BASE((expect) == (actual), expect, actual, "%d")
#define EXPECT_EQ_DOUBLE(expect, actual) EXPECT_EQ_BASE((expect) == (actual), expect, actual, "%.17g")
#define EXPECT_EQ_STRING(expect, actual, alength)\
EXPECT_EQ_BASE(sizeof(expect)-1 == alength && memcmp(expect, actual, alength)==0, expect, actual, "%s")
#define EXPECT_TRUE(actual) EXPECT_EQ_BASE((actual) != 0, "true", "false", "%s")
#define EXPECT_FALSE(actual) EXPECT_EQ_BASE((actual) == 0, "false", "true", "%s")
//size_t不同的两种打印方式(两个标准)
#if defined(_MSC_VER)
#define EXPECT_EQ_SIZE_T(expect, actual) EXPECT_EQ_BASE((expect) == (actual), (size_t)expect, (size_t)actual, "%Iu")
#else
#define EXPECT_EQ_SIZE_T(expect, actual) EXPECT_EQ_BASE((expect) == (actual), (size_t)expect, (size_t)actual, "%zu")
#endif
static void test_parse_null()
{
lept_value v;
lept_init(&v);
lept_set_boolean(&v, 0);
EXPECT_EQ_INT(LEPT_PARSE_OK, lept_parse(&v, "null"));
EXPECT_EQ_INT(LEPT_NULL, lept_get_type(&v));
lept_free(&v);
}
static void test_parse_true()
{
lept_value v;
lept_init(&v);
lept_set_boolean(&v, 0);
EXPECT_EQ_INT(LEPT_PARSE_OK, lept_parse(&v, "true"));
EXPECT_EQ_INT(LEPT_TRUE, lept_get_type(&v));
lept_free(&v);
}
static void test_parse_false()
{
lept_value v;
lept_init(&v);
lept_set_boolean(&v, 1);
EXPECT_EQ_INT(LEPT_PARSE_OK, lept_parse(&v, "false"));
EXPECT_EQ_INT(LEPT_FALSE, lept_get_type(&v));
lept_free(&v);
}
//测试正常数值
#define TEST_NUMBER(expect, json)\
do{\
lept_value v;\
EXPECT_EQ_INT(LEPT_PARSE_OK, lept_parse(&v, json));\
EXPECT_EQ_INT(LEPT_NUMBER, lept_get_type(&v));\
EXPECT_EQ_DOUBLE(expect, lept_get_number(&v));\
} while (0)
static void test_parse_number()
{
TEST_NUMBER(0.0, "0");
TEST_NUMBER(0.0, "-0");
TEST_NUMBER(0.0, "-0.0");
TEST_NUMBER(1.0, "1");
TEST_NUMBER(-1.0, "-1");
TEST_NUMBER(1.5, "1.5");
TEST_NUMBER(-1.5, "-1.5");
TEST_NUMBER(3.1416, "3.1416");
TEST_NUMBER(1E10, "1E10");
TEST_NUMBER(1e10, "1e10");
TEST_NUMBER(1E+10, "1E+10");
TEST_NUMBER(1E-10, "1E-10");
TEST_NUMBER(-1E10, "-1E10");
TEST_NUMBER(-1e10, "-1e10");
TEST_NUMBER(-1E+10, "-1E+10");
TEST_NUMBER(-1E-10, "-1E-10");
TEST_NUMBER(1.234E+10, "1.234E+10");
TEST_NUMBER(1.234E-10, "1.234E-10");
TEST_NUMBER(0.0, "1e-10000"); /* must underflow */
TEST_NUMBER(1.0000000000000002, "1.0000000000000002"); /* the smallest number > 1 */
TEST_NUMBER(4.9406564584124654e-324, "4.9406564584124654e-324"); /* minimum denormal */
TEST_NUMBER(-4.9406564584124654e-324, "-4.9406564584124654e-324");
TEST_NUMBER(2.2250738585072009e-308, "2.2250738585072009e-308"); /* Max subnormal double */
TEST_NUMBER(-2.2250738585072009e-308, "-2.2250738585072009e-308");
TEST_NUMBER(2.2250738585072014e-308, "2.2250738585072014e-308"); /* Min normal positive double */
TEST_NUMBER(-2.2250738585072014e-308, "-2.2250738585072014e-308");
TEST_NUMBER(1.7976931348623157e+308, "1.7976931348623157e+308"); /* Max double */
TEST_NUMBER(-1.7976931348623157e+308, "-1.7976931348623157e+308");
}
#define TEST_STRING(expect,json)\
do{\
lept_value v;\
lept_init(&v);\
EXPECT_EQ_INT(LEPT_PARSE_OK, lept_parse(&v, json));\
EXPECT_EQ_INT(LEPT_STRING, lept_get_type(&v));\
EXPECT_EQ_STRING(expect, lept_get_string(&v), lept_get_string_length(&v));\
lept_free(&v);\
}while(0)
static void test_parse_string() {
TEST_STRING("", "\"\"");
TEST_STRING("Hello", "\"Hello\"");
TEST_STRING("Hello\nWorld", "\"Hello\\nWorld\"");
TEST_STRING("\" \\ / \b \f \n \r \t", "\"\\\" \\\\ \\/ \\b \\f \\n \\r \\t\"");
TEST_STRING("Hello\0World", "\"Hello\\u0000World\"");
TEST_STRING("\x24", "\"\\u0024\""); /* Dollar sign U+0024 */
TEST_STRING("\xC2\xA2", "\"\\u00A2\""); /* Cents sign U+00A2 */
TEST_STRING("\xE2\x82\xAC", "\"\\u20AC\""); /* Euro sign U+20AC */
TEST_STRING("\xF0\x9D\x84\x9E", "\"\\uD834\\uDD1E\""); /* G clef sign U+1D11E */
TEST_STRING("\xF0\x9D\x84\x9E", "\"\\ud834\\udd1e\""); /* G clef sign U+1D11E */
}
static void test_parse_array()
{
size_t i = 0;
size_t j = 0;
lept_value v;
lept_init(&v);
EXPECT_EQ_INT(LEPT_PARSE_OK, lept_parse(&v, "[ ]"));
EXPECT_EQ_INT(LEPT_ARRAY, lept_get_type(&v));
EXPECT_EQ_SIZE_T(0, lept_get_array_size(&v));
lept_free(&v);
lept_init(&v);
EXPECT_EQ_INT(LEPT_PARSE_OK, lept_parse(&v, "[ null , false , true , 123 , \"abc\" ]"));
EXPECT_EQ_INT(LEPT_ARRAY, lept_get_type(&v));
EXPECT_EQ_SIZE_T(5, lept_get_array_size(&v));
EXPECT_EQ_INT(LEPT_NULL, lept_get_type(lept_get_array_element(&v, 0)));
EXPECT_EQ_INT(LEPT_FALSE, lept_get_type(lept_get_array_element(&v, 1)));
EXPECT_EQ_INT(LEPT_TRUE, lept_get_type(lept_get_array_element(&v, 2)));
EXPECT_EQ_INT(LEPT_NUMBER, lept_get_type(lept_get_array_element(&v, 3)));
EXPECT_EQ_INT(LEPT_STRING, lept_get_type(lept_get_array_element(&v, 4)));
EXPECT_EQ_DOUBLE(123.0, lept_get_number(lept_get_array_element(&v, 3)));
EXPECT_EQ_STRING("abc", lept_get_string(lept_get_array_element(&v, 4)), lept_get_string_length(lept_get_array_element(&v, 4)));
lept_free(&v);
lept_init(&v);
EXPECT_EQ_INT(LEPT_PARSE_OK, lept_parse(&v, "[ [ ] , [ 0 ] , [ 0 , 1 ] , [ 0 , 1 , 2 ] ]"));
EXPECT_EQ_INT(LEPT_ARRAY, lept_get_type(&v));
EXPECT_EQ_SIZE_T(4, lept_get_array_size(&v));
for (i = 0; i < 4; i++) {
lept_value* a = lept_get_array_element(&v, i);
EXPECT_EQ_INT(LEPT_ARRAY, lept_get_type(a));
EXPECT_EQ_SIZE_T(i, lept_get_array_size(a));
for (j = 0; j < i; j++) {
lept_value* e = lept_get_array_element(a, j);
EXPECT_EQ_INT(LEPT_NUMBER, lept_get_type(e));
EXPECT_EQ_DOUBLE((double)j, lept_get_number(e));
}
}
lept_free(&v);
}
static void test_parse_object()
{
lept_value v;
size_t i;
lept_init(&v);
EXPECT_EQ_INT(LEPT_PARSE_OK, lept_parse(&v, " { } "));
EXPECT_EQ_INT(LEPT_OBJECT, lept_get_type(&v));
EXPECT_EQ_SIZE_T(0, lept_get_object_size(&v));
lept_free(&v);
lept_init(&v);
EXPECT_EQ_INT(LEPT_PARSE_OK, lept_parse(&v,
" { "
"\"n\" : null , "
"\"f\" : false , "
"\"t\" : true , "
"\"i\" : 123 , "
"\"s\" : \"abc\", "
"\"a\" : [ 1, 2, 3 ],"
"\"o\" : { \"1\" : 1, \"2\" : 2, \"3\" : 3 }"
" } "
));
EXPECT_EQ_INT(LEPT_OBJECT, lept_get_type(&v));
EXPECT_EQ_SIZE_T(7, lept_get_object_size(&v));
EXPECT_EQ_STRING("n", lept_get_object_key(&v, 0), lept_get_object_key_length(&v, 0));
EXPECT_EQ_INT(LEPT_NULL, lept_get_type(lept_get_object_value(&v, 0)));
EXPECT_EQ_STRING("f", lept_get_object_key(&v, 1), lept_get_object_key_length(&v, 1));
EXPECT_EQ_INT(LEPT_FALSE, lept_get_type(lept_get_object_value(&v, 1)));
EXPECT_EQ_STRING("t", lept_get_object_key(&v, 2), lept_get_object_key_length(&v, 2));
EXPECT_EQ_INT(LEPT_TRUE, lept_get_type(lept_get_object_value(&v, 2)));
EXPECT_EQ_STRING("i", lept_get_object_key(&v, 3), lept_get_object_key_length(&v, 3));
EXPECT_EQ_INT(LEPT_NUMBER, lept_get_type(lept_get_object_value(&v, 3)));
EXPECT_EQ_DOUBLE(123.0, lept_get_number(lept_get_object_value(&v, 3)));
EXPECT_EQ_STRING("s", lept_get_object_key(&v, 4), lept_get_object_key_length(&v, 4));
EXPECT_EQ_INT(LEPT_STRING, lept_get_type(lept_get_object_value(&v, 4)));
EXPECT_EQ_STRING("abc", lept_get_string(lept_get_object_value(&v, 4)), lept_get_string_length(lept_get_object_value(&v, 4)));
EXPECT_EQ_STRING("a", lept_get_object_key(&v, 5), lept_get_object_key_length(&v, 5));
EXPECT_EQ_INT(LEPT_ARRAY, lept_get_type(lept_get_object_value(&v, 5)));
EXPECT_EQ_SIZE_T(3, lept_get_array_size(lept_get_object_value(&v, 5)));
for (i = 0; i < 3; i++) {
lept_value* e = lept_get_array_element(lept_get_object_value(&v, 5), i);
EXPECT_EQ_INT(LEPT_NUMBER, lept_get_type(e));
EXPECT_EQ_DOUBLE(i + 1.0, lept_get_number(e));
}
EXPECT_EQ_STRING("o", lept_get_object_key(&v, 6), lept_get_object_key_length(&v, 6));
{
lept_value* o = lept_get_object_value(&v, 6);
EXPECT_EQ_INT(LEPT_OBJECT, lept_get_type(o));
for (i = 0; i < 3; i++) {
lept_value* ov = lept_get_object_value(o, i);
EXPECT_TRUE('1' + i == lept_get_object_key(o, i)[0]);
EXPECT_EQ_SIZE_T(1, lept_get_object_key_length(o, i));
EXPECT_EQ_INT(LEPT_NUMBER, lept_get_type(ov));
EXPECT_EQ_DOUBLE(i + 1.0, lept_get_number(ov));
}
}
lept_free(&v);
}
//测试错误数值
#define TEST_ERROR(error, json)\
do{\
lept_value v;\
lept_init(&v);\
v.type = LEPT_FALSE;\
EXPECT_EQ_INT(error,lept_parse(&v, json));\
EXPECT_EQ_INT(LEPT_NULL, lept_get_type(&v));\
lept_free(&v);\
} while (0)
static void test_parse_expect_value()
{
TEST_ERROR(LEPT_PARSE_EXPECT_VALUE, "");
TEST_ERROR(LEPT_PARSE_EXPECT_VALUE, " ");
}
static void test_parse_invalid_value() {
TEST_ERROR(LEPT_PARSE_INVALID_VALUE, "nul");
TEST_ERROR(LEPT_PARSE_INVALID_VALUE, "?");
/* invalid number */
TEST_ERROR(LEPT_PARSE_INVALID_VALUE, "+0");
TEST_ERROR(LEPT_PARSE_INVALID_VALUE, "+1");
TEST_ERROR(LEPT_PARSE_INVALID_VALUE, ".123"); /* at least one digit before '.' */
TEST_ERROR(LEPT_PARSE_INVALID_VALUE, "1."); /* at least one digit after '.' */
TEST_ERROR(LEPT_PARSE_INVALID_VALUE, "INF");
TEST_ERROR(LEPT_PARSE_INVALID_VALUE, "inf");
TEST_ERROR(LEPT_PARSE_INVALID_VALUE, "NAN");
TEST_ERROR(LEPT_PARSE_INVALID_VALUE, "nan");
TEST_ERROR(LEPT_PARSE_INVALID_VALUE, "[1,]");
TEST_ERROR(LEPT_PARSE_INVALID_VALUE, "[\"a\", nul]");
}
static void test_parse_root_not_singular()
{
TEST_ERROR(LEPT_PARSE_ROOT_NOT_SINGULAR, "null x");
/* invalid number */
TEST_ERROR(LEPT_PARSE_ROOT_NOT_SINGULAR, "0123"); /* after zero should be '.' or nothing */
TEST_ERROR(LEPT_PARSE_ROOT_NOT_SINGULAR, "0x0");
TEST_ERROR(LEPT_PARSE_ROOT_NOT_SINGULAR, "0x123");
}
static void test_parse_number_too_big()
{
TEST_ERROR(LEPT_PARSE_NUMBER_TOO_BIG, "1e309");
TEST_ERROR(LEPT_PARSE_NUMBER_TOO_BIG, "-1e309");
}
static void test_parse_missing_quotation_mark()
{
TEST_ERROR(LEPT_PARSE_MISS_QUOTATION_MARK, "\"");
TEST_ERROR(LEPT_PARSE_MISS_QUOTATION_MARK, "\"abc");
}
static void test_parse_invalid_string_escape()
{
TEST_ERROR(LEPT_PARSE_INVALID_STRING_ESCAPE, "\"\\v\"");
TEST_ERROR(LEPT_PARSE_INVALID_STRING_ESCAPE, "\"\\'\"");
TEST_ERROR(LEPT_PARSE_INVALID_STRING_ESCAPE, "\"\\0\"");
TEST_ERROR(LEPT_PARSE_INVALID_STRING_ESCAPE, "\"\\x12\"");
}
static void test_parse_invalid_string_char()
{
TEST_ERROR(LEPT_PARSE_INVALID_STRING_CHAR, "\"\x01\"");
TEST_ERROR(LEPT_PARSE_INVALID_STRING_CHAR, "\"\x1F\"");
}
static void test_parse_invalid_unicode_hex()
{
TEST_ERROR(LEPT_PARSE_INVALID_UNICODE_HEX, "\"\\u\"");
TEST_ERROR(LEPT_PARSE_INVALID_UNICODE_HEX, "\"\\u0\"");
TEST_ERROR(LEPT_PARSE_INVALID_UNICODE_HEX, "\"\\u01\"");
TEST_ERROR(LEPT_PARSE_INVALID_UNICODE_HEX, "\"\\u012\"");
TEST_ERROR(LEPT_PARSE_INVALID_UNICODE_HEX, "\"\\u/000\"");
TEST_ERROR(LEPT_PARSE_INVALID_UNICODE_HEX, "\"\\uG000\"");
TEST_ERROR(LEPT_PARSE_INVALID_UNICODE_HEX, "\"\\u0/00\"");
TEST_ERROR(LEPT_PARSE_INVALID_UNICODE_HEX, "\"\\u0G00\"");
TEST_ERROR(LEPT_PARSE_INVALID_UNICODE_HEX, "\"\\u0/00\"");
TEST_ERROR(LEPT_PARSE_INVALID_UNICODE_HEX, "\"\\u00G0\"");
TEST_ERROR(LEPT_PARSE_INVALID_UNICODE_HEX, "\"\\u000/\"");
TEST_ERROR(LEPT_PARSE_INVALID_UNICODE_HEX, "\"\\u000G\"");
TEST_ERROR(LEPT_PARSE_INVALID_UNICODE_HEX, "\"\\u 123\"");
}
static void test_parse_invalid_unicode_surrogate()
{
TEST_ERROR(LEPT_PARSE_INVALID_UNICODE_SURROGATE, "\"\\uD800\"");
TEST_ERROR(LEPT_PARSE_INVALID_UNICODE_SURROGATE, "\"\\uDBFF\"");
TEST_ERROR(LEPT_PARSE_INVALID_UNICODE_SURROGATE, "\"\\uD800\\\\\"");
TEST_ERROR(LEPT_PARSE_INVALID_UNICODE_SURROGATE, "\"\\uD800\\uDBFF\"");
TEST_ERROR(LEPT_PARSE_INVALID_UNICODE_SURROGATE, "\"\\uD800\\uE000\"");
}
static void test_parse_miss_comma_or_square_bracket()
{
#if 1
TEST_ERROR(LEPT_PARSE_MISS_COMMA_OR_SQUARE_BRACKET, "[1");
TEST_ERROR(LEPT_PARSE_MISS_COMMA_OR_SQUARE_BRACKET, "[1}");
TEST_ERROR(LEPT_PARSE_MISS_COMMA_OR_SQUARE_BRACKET, "[1 2");
TEST_ERROR(LEPT_PARSE_MISS_COMMA_OR_SQUARE_BRACKET, "[[]");
#endif
}
static void test_parse_miss_key()
{
TEST_ERROR(LEPT_PARSE_MISS_KEY, "{:1,");
TEST_ERROR(LEPT_PARSE_MISS_KEY, "{1:1,");
TEST_ERROR(LEPT_PARSE_MISS_KEY, "{true:1,");
TEST_ERROR(LEPT_PARSE_MISS_KEY, "{false:1,");
TEST_ERROR(LEPT_PARSE_MISS_KEY, "{null:1,");
TEST_ERROR(LEPT_PARSE_MISS_KEY, "{[]:1,");
TEST_ERROR(LEPT_PARSE_MISS_KEY, "{{}:1,");
TEST_ERROR(LEPT_PARSE_MISS_KEY, "{\"a\":1,");
}
static void test_parse_miss_colon()
{
TEST_ERROR(LEPT_PARSE_MISS_COLON, "{\"a\"}");
TEST_ERROR(LEPT_PARSE_MISS_COLON, "{\"a\",\"b\"}");
}
static void test_parse_miss_comma_or_curly_bracket()
{
TEST_ERROR(LEPT_PARSE_MISS_COMMA_OR_CURLY_BRACKET, "{\"a\":1");
TEST_ERROR(LEPT_PARSE_MISS_COMMA_OR_CURLY_BRACKET, "{\"a\":1]");
TEST_ERROR(LEPT_PARSE_MISS_COMMA_OR_CURLY_BRACKET, "{\"a\":1 \"b\"");
TEST_ERROR(LEPT_PARSE_MISS_COMMA_OR_CURLY_BRACKET, "{\"a\":{}");
}
static void test_access_null()
{
lept_value v;
lept_init(&v);
lept_set_string(&v, "a", 1);
lept_set_null(&v);
EXPECT_EQ_INT(LEPT_NULL, lept_get_type(&v));
lept_free(&v);
}
static void test_access_boolean()
{
lept_value v;
lept_init(&v);
lept_set_string(&v, "a", 1);
lept_set_boolean(&v, 1);
EXPECT_TRUE(lept_get_boolean(&v));
lept_set_boolean(&v, 0);
EXPECT_FALSE(lept_get_boolean(&v));
lept_free(&v);
}
static void test_access_number()
{
lept_value v;
lept_init(&v);
lept_set_string(&v, "a", 1);
lept_set_number(&v, 1234.5);
EXPECT_EQ_DOUBLE(1234.5, lept_get_number(&v));
lept_free(&v);
}
static void test_access_string()
{
lept_value v;
lept_init(&v);
lept_set_string(&v, "", 0);
EXPECT_EQ_STRING("", lept_get_string(&v), lept_get_string_length(&v));
lept_set_string(&v, "Hello", 5);
EXPECT_EQ_STRING("Hello", lept_get_string(&v), lept_get_string_length(&v));
lept_free(&v);
}
#define TEST_ROUNDTRIP(json)\
do{\
lept_value v;\
char* json2;\
size_t length;\
lept_init(&v);\
EXPECT_EQ_INT(LEPT_PARSE_OK, lept_parse(&v, json));\
json2 = lept_stringify(&v, &length);\
EXPECT_EQ_STRING(json, json2, length);\
lept_free(&v);\
free(json2);\
}while(0)
static void test_stringify_number()
{
TEST_ROUNDTRIP("0");
TEST_ROUNDTRIP("-0");
TEST_ROUNDTRIP("1");
TEST_ROUNDTRIP("-1");
TEST_ROUNDTRIP("1.5");
TEST_ROUNDTRIP("-1.5");
TEST_ROUNDTRIP("3.25");
TEST_ROUNDTRIP("1e+020");
TEST_ROUNDTRIP("1.234e+020");
TEST_ROUNDTRIP("1.234e-020");
TEST_ROUNDTRIP("1.0000000000000002"); /* the smallest number > 1 */
TEST_ROUNDTRIP("4.9406564584124654e-324"); /* minimum denormal */
TEST_ROUNDTRIP("-4.9406564584124654e-324");
TEST_ROUNDTRIP("2.2250738585072009e-308"); /* Max subnormal double */
TEST_ROUNDTRIP("-2.2250738585072009e-308");
TEST_ROUNDTRIP("2.2250738585072014e-308"); /* Min normal positive double */
TEST_ROUNDTRIP("-2.2250738585072014e-308");
TEST_ROUNDTRIP("1.7976931348623157e+308"); /* Max double */
TEST_ROUNDTRIP("-1.7976931348623157e+308");
}
static void test_stringify_string()
{
TEST_ROUNDTRIP("\"\"");
TEST_ROUNDTRIP("\"Hello\"");
TEST_ROUNDTRIP("\"Hello\\nWorld\"");
TEST_ROUNDTRIP("\"\\\" \\\\ / \\b \\f \\n \\r \\t\"");
TEST_ROUNDTRIP("\"Hello\\u0000World\"");
}
static void test_stringify_array()
{
TEST_ROUNDTRIP("[]");
TEST_ROUNDTRIP("[null,false,true,123,\"abc\",[1,2,3]]");
}
static void test_stringify_object()
{
TEST_ROUNDTRIP("{}");
TEST_ROUNDTRIP("{\"n\":null,\"f\":false,\"t\":true,\"i\":123,\"s\":\"abc\",\"a\":[1,2,3],\"o\":{\"1\":1,\"2\":2,\"3\":3}}");
}
static void test_stringify()
{
TEST_ROUNDTRIP("null");
TEST_ROUNDTRIP("false");
TEST_ROUNDTRIP("true");
test_stringify_number();
test_stringify_string();
test_stringify_array();
test_stringify_object();
}
static void test_parse()
{
test_parse_null();
test_parse_true();
test_parse_false();
test_parse_number();
test_parse_string();
test_parse_array();
test_parse_object();
test_parse_expect_value();
test_parse_invalid_value();
test_parse_root_not_singular();
test_parse_number_too_big();
test_parse_missing_quotation_mark();
test_parse_invalid_string_escape();
test_parse_invalid_string_char();
test_parse_invalid_unicode_hex();
test_parse_invalid_unicode_surrogate();
test_parse_miss_comma_or_square_bracket();
test_parse_miss_key();
test_parse_miss_colon();
test_parse_miss_comma_or_curly_bracket();
}
static void test_access()
{
test_access_null();
test_access_boolean();
test_access_number();
test_access_string();
}
static void my_test()
{
char a[] = " {"
"\"n\" : null , "
"\"f\" : false , "
"\"t\" : true , "
"\"i\" : 123 , "
"\"s\" : \"abc\", "
"\"a\" : [ 1, 2, 3 ],"
"\"o\" : { \"1\" : 1, \"2\" : 2, \"3\" : 3 }"
" } ";
lept_value v;
lept_parse(&v, a);
printf("%s", lept_stringify(&v, NULL));
}
int main()
{
#ifdef _WINDOWS
_CrtSetDbgFlag(_CRTDBG_ALLOC_MAP_DF | _CRTDBG_LEAK_CHECK_DF);
#endif
test_stringify();
test_parse();
test_access();
//my_test();
printf("%d/%d (%3.2f%%) passed\n", test_pass, test_count, test_pass*100.0 / test_count);
return main_ret;
}