【深度学习——BNN】:二值神经网络BNN——学习与总结
最近一直在做深度学习的FPGA布署,偶然研读到Bengio大神的著作《Binarized Neural Networks: Training Neural Networks with Weights and Activations Constrained to +1 or −1》:
链接:https://arxiv.org/abs/1602.02830
关于BNN,已经有不少前辈做了mark,根据这几天的学习,做了一下整理。
二值神经网络是在CNN的基础上,对权值和激活值(特征值)做二值化处理,即取值是+1或-1。BNN网络结构与CNN相同,主要在梯度下降、权值更新、卷积运算上做了一些优化处理。
1.二值化
所谓二值化,就是权值和激活值只能取+1或-1,作者指明,二值化,有两种方法:①Deterministic(确定法);②Stochastic(统计法)。
Deterministic(确定法):大于等于0,取+1;否则,取-1。
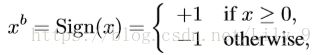
Stochastic(统计法):以一定的概率 ![]() ,取+1,或-1。
,取+1,或-1。

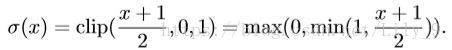
虽然Stochastic(统计法)更合理,但是,实际操作需要用硬件生成随机数,比较困难,所以在这篇paper中,作者采用的是Deterministic(确定法)。
在前向传播过程中,经Deterministic(确定法)的Sign函数,可以将实数型的权值和激活值量化成+1,-1,当用于预测时,参数值仅为+1或-1,可以减小参数的内存占用和存取量;但是,训练时,仍需要对实数型的权值和激活值计算梯度,并以此更新权值。
2.权值更新
在权值更新之前,需要先了解一下前向传播的具体过程。作者在第一个算法中,给出了前向传播、梯度下降、权值更新的算法。


训练时的前向传播:二值网络训练时的权值参数W,必须包含实数型的参数,然后将实数型权值参数二值化得到二值型权值参数,即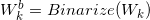 。然后利用二值化后的参数计算得到实数型的中间向量,该向量再通过Batch Normalization操作,得到实数型的隐藏层激活向量。如果不是输出层的话,就将该向量二值化。
。然后利用二值化后的参数计算得到实数型的中间向量,该向量再通过Batch Normalization操作,得到实数型的隐藏层激活向量。如果不是输出层的话,就将该向量二值化。
求梯度:由于Sign(x)函数的梯度,几乎处处为0,这显然不利于反向传播,所以,作者采用straight-through estimator策略,即:
![]()
![]()
其中,![]() 表示
表示![]() 的梯度,C表示损失函数。
的梯度,C表示损失函数。![]() 表示当|r|<=1时,Sign(r)的梯度等于1;否则,均为0。可见,这样处理,既保留了梯度信息,当r太大时,又取消梯度,加速网络的收敛。这就相当于,用HTanh(x)代替Sign(x):
表示当|r|<=1时,Sign(r)的梯度等于1;否则,均为0。可见,这样处理,既保留了梯度信息,当r太大时,又取消梯度,加速网络的收敛。这就相当于,用HTanh(x)代替Sign(x):
![]()
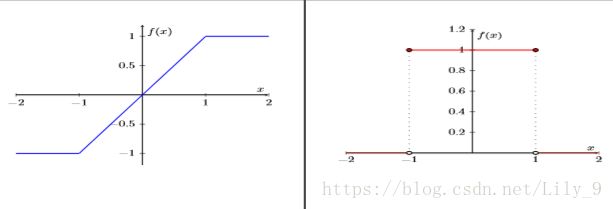
左图表示HTanh(x)函数,右图表示HTanh(x)梯度。
然后,基于链式法则,先求实数型激活值的梯度![]() ,再求出BatchNorm前的实数型中间向量梯度
,再求出BatchNorm前的实数型中间向量梯度![]() ,以及BatchNorm参数的梯度
,以及BatchNorm参数的梯度![]() ,继而求出二值化的权值梯度
,继而求出二值化的权值梯度![]() ,和前一层的二值化激活值梯度
,和前一层的二值化激活值梯度![]() 。(注:二值网络在对权值求梯度的时候,是对二值化后的权值求梯度,而不是对二值化前的实数型权值求梯度。这是因为二值化前的权值并没有真正的参与网络的前向传播过程)
。(注:二值网络在对权值求梯度的时候,是对二值化后的权值求梯度,而不是对二值化前的实数型权值求梯度。这是因为二值化前的权值并没有真正的参与网络的前向传播过程)
训练时的权值更新:在求权值(W)梯度的时候是对二值化后的权值求梯度,但是在权值更新的时候,需要根据已知的二值化后的权值梯度,加上学习速率,对实数型权值进行更新![]() 。
。
3、乘法优化
Shift-based Batch Normalization:二值网络对Batch Normalization操作的优化主要是通过AP2(x)操作和<<>>操作来代替普通的乘法。AP2(x)的作用是求与x最接近的2的幂次方,如AP2(3.14)=4,AP2(2.5)=2;而<<>>操作就是位移操作。根据AP2(x)确定<<>>左移右移的位数,AP2(x)的操作,在作者给出的源码中能够找到;但是<<>>的操作,从源码中只能看到Torch的点乘函数cmul()。(注:Shift-based AdaMax中的乘法操作也是用上述两个操作代替 )
前向传播:二值网络中最重要的乘法优化是前向传播中隐藏层的输出乘以权值W的乘法优化,也就是卷积优化。对于二值网络的卷积运算,只是+1与-1之间的乘累加运算,根据+1与-1的乘法运算真值表的特点,作者提出了“XNOR”代替“乘法”的优化方式。在源码中,也给出了两条对应的指令,即popcount和xnor。下图是论文中BNN的测试时前向传播算法。需要注意的是,只有输入层数据是8位二进制,而激活向量和权值矩阵中的元素全都是1位二进制表示的。因此,为了可以统一,输入层与第一层隐藏层之间的乘法也拆成“Xnor”的运算方式,即![]() 。(注:从作者给出的代码来看,似乎并没有采用这个操作,而是直接用普通的乘法。作者在论文中也说明了这一层的乘法的耗费很小。)
。(注:从作者给出的代码来看,似乎并没有采用这个操作,而是直接用普通的乘法。作者在论文中也说明了这一层的乘法的耗费很小。)

4.为什么可以用“Xnor”代替乘法?
我在这里做了一下推导,我们不妨先写出+1,-1的乘法运算真值表,和Xnor(同或)真值表:
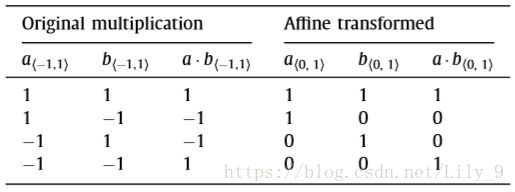
不难发现,假如用0表示-1,那么原来的二值乘法运算,与Xnor的真值表,一毛一样。。。
如果,用数学表达式,描述这种转换关系的话,可以这样写:
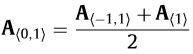
所以,用“Xnor”代替乘法是合理、可行的!
但是,代码里是没有“xnor”的操作符的,所以作者在源码里,用“异或取反”代替,因为xnor本来就是“异非或”的意思。。。
举个例子,a=[1,-1, 1, 1, -1],W=[-1,1,1,-1,-1]。按照正常的乘法应该是:
a1*w1+a2*w2+a3*w3+a4*w4+a5*w5=1*-1+-1*1+1*1+1*-1+-1*-1=-1
那么转成Xnor的计算方式,在程序中,a=[1,0,1,1,0],W=[0,1,1,0,0]表示的,具体运算过程如下:
a^W=[1^0,0^1,1^1,1^0,0^0]=[1,1,0,1,0]
Popcount(a^w)=3
-(2*Popcount(a^w)-5) = -1
Popcount(x)表示统计向量x中1的个数,我们知道0表示-1,1表示+1,所以,a和W异或求和,应该等于(Popcount-(5-Popcount))=2*Popcount-5=1,而我们要求的是Xnor求和,所以还需要在前面加个负号“-”,即-(2*Popcount(a^w)-5) = -1。
如果用vec_len表示向量元素个数的话,那么用xnor代替正常的乘累加(卷积),可以用通式:-(2*Popcount(a^w)-vec_len)来计算。
5.小结
总的来说,二值化神经网络BNN有一下几个特点:
① 减小内存占用:显然,权值和激活值二值化后,只需1bit即可表示,大幅度地降低了内存的占用。
② 降低功耗:因为二值化,原来32位浮点数,只需要1bit表示,存取内存的操作量降低了;其实,存取内存的功耗远大于计算的功耗,所以相比于32-bit DNN,BNN的内存占用和存取操作量缩小了32倍,极大地降低了功耗。
③减小面向深度学习的硬件的面积开销:XNOR代替乘法,用1-bit的XNOR-gate代替了原来的32-bit浮点数乘法,对面向深度学习的硬件来说,有很大影响。譬如,FPGA,原来完成一个32-bit的浮点数乘法需要大约200个Slices,而1-bit 的Xnor-gate 只需要1个Slice,硬件面积开销,直接缩小了200倍。
④速度快:作者专门写了一个二值乘法矩阵的GPU核,可以保证在准确率无损失的前提下,运行速度提高7倍。
参考代码:https://github.com/MatthieuCourbariaux/BinaryNet
参考博文:https://blog.csdn.net/linmingan/article/details/51008830