KMP算法详解——第一篇
首先思考一个问题:给你两个字符串,一个叫s(文本串,长串),一个叫p(模式串,短串),查找p在s中出现的位置。
为了思路更清晰,再强调一下是返回首位置,第一个出现的位置,没有返回-1。
一般思路是暴力算法,遍历整个s,每个位置和p的首位置比较,这样要strlen(s)*strlen(p)的次数,数据一大就无法使用。
KMP,就是三个发现者的首字母连在一起, Knuth-Morris-Pratt 字符串查找算法,简称为 “KMP算法”。
http://acm.hdu.edu.cn/showproblem.php?pid=1711
题意是两个整形数组,找模式串在文本串出现的位置,和字符串一个意思。
先看以下代码:
#include
using namespace std;
int a[1000000+10],b[10000+10];//数组开的比题意大一些,防止溢出,在main之外的数组可以开的比较大
int next[10000+10];//思考next里存放的是什么?
int n,m;
void getnext()
{
int i=1,j=0;
next[1]=0;
while(im) printf("%d\n",i-m);
else printf("-1\n");
return ;
}
int main()
{
int t;
scanf("%d",&t);
while(t--){
scanf("%d%d",&n,&m);
for(int i=1;i<=n;i++)
scanf("%d",&a[i]);
for(int i=1;i<=m;i++)
scanf("%d",&b[i]);
a[0]=b[0]=-1;
getnext();
kmp();
}
return 0;
} 要了解next在干什么东西,我们先选择一组数据:1 2 3 1 3
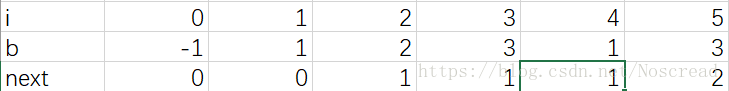
直接说next的意义,存储前缀的长度,长串的i位置与短串的j位置的值不同时,j=next[j]的位置开始继续与i比较,
例如:1 2 3 1 2 3,我们要找1 2 3 1 3
虽然不存在,但我们比较到1 2 3 1 2 3与1 2 3 1 3 时,不再重复不可能的操作(就是 2 3 1 2 3与1 2 3 1 3之类的比较,前面几个都不一样,也就是为什么next存储前缀的长度),从next开始,也就是next[5]=2开始(1 2 3 1 2 3 ,1 2 3 1 3)这样就节省了时间。
这样的思路理清楚后,理解下操作:
void getnext()
{
int i=1,j=0;
next[1]=0;
while(inext怎么初始化?看上面的代码不难理解,完成后next[1]之后的数据>0,也就是说next[1]=0是唯一的;
next[++i]=++j; j会指向下个位置,也就是还没赋值的位置,next[j]的值是0,也就重新开始,和j=0时一样。
void kmp()
{
int i=1,j=1;
while(i<=n&&j<=m){
if(j==0||a[i]==b[j])
i++,j++;
else
j=next[j];
}
if(j>m) printf("%d\n",i-m);
else printf("-1\n");
return ;
}再看kmp是如何查找的?
j在查找到不相符时同样指向下一个位置,此时i没变,这时也说明没找到长串中短串的位置,如果可能找到,
只能是从a[i]==b[j]中跳出循环,不会从j=next[j]中出来,next起到的作用是提前找到下一个可能的情况。
我的理解就是这样,希望你能理解。试试考虑next[1]赋其他值看看,多思考改动,比一直死记有用的多。
熟悉了基础,那我们再加些难度,如果长串中有多个短串存在,求出存在的个数。
acm.hdu.edu.cn/showproblem.php?pid=1686
题意:n组字符串,p串和s串(p在前),求s串中p串出现的次数。
#include
#include
using namespace std;
const int maxs=1e7+10;
const int maxp=1e5+10;
int next[maxp];
char s[maxs],p[maxp];
void get_next(int len)
{
next[0]=-1;
int k=-1;
int j=0;
while(j 嘿嘿嘿,是不是发现有点奇怪啊,上一个代码明明next[1]不能等于-1的啊,是不是看别人的代码也有写next[1]=-1的,那这是怎么回事呢?不急,看代码,首先注意数组指向不会越界,这种写法不过是从0位开始判断,因为输入字符串习惯上不会从1位开始输入,这就和上面的整形数组发生了细节差别。理解后不妨把上面整形数组的改一下看看细节有哪些。