转
毕业设计(论文)中期报告
标签(空格分隔): 论文
目录
- 毕业设计的进展情况 1
1.1. 课题工作完成情况 1
1.2. 知识学习情况 1
1.3. 解决复杂工程问题情况 1 - 存在问题与解决方案 1
2.1. 存在的主要问题 1
2.2. 解决方案与可行性研究 1 - 下一步计划 2
1 毕业设计的进展情况
1.1课题完成情况
首先我尝试了SIGGRAPH 2017年的一篇文章: Globally and Locally Consistent Image Completion(以下简称GL)。这篇文章是由早稻田大学(Waseda University)的Satoshi Iizuka等人发表的,他们并没有公布源代码以及训练模型。
我自己按照他们的文章实现后,发现效果并不理想,但这一点和我的训练数据以及GAN模型本身的不稳定性有很大关系,也有可能我的实现方法有问题。但是基于他们的思路以及DCGAN原本代码重新修改后,我得到了一个可以继续训练的模型。
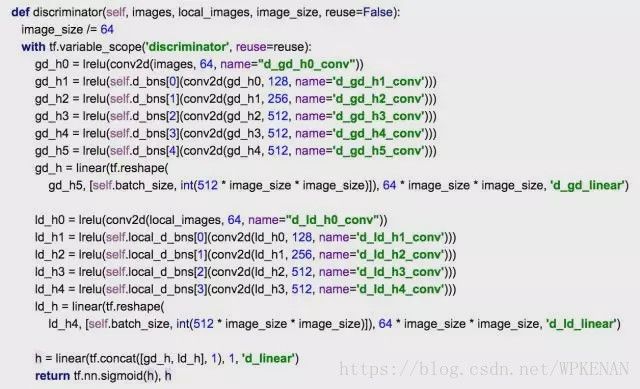
GL这篇文章完全以卷积网络作为基础,遵循GAN的思路,设计两部分网络,一部分用于生成图像,一部分用于鉴别生成图像是否与原图片一致。
生成图片部分,GL采用12层卷积网络对原始图片(去除需要进行填充的部分)进行encoding,得到一张原图16分之一大小的网格。然后再对该网格采用4层卷积网络进行decoding,从而得到复原图像。
鉴别器也被分为两个部分,一个全局鉴别器(Global Discriminator)以及一个局部鉴别器(Local Discriminator)。全局鉴别器将完整图像作为输入,识别场景的全局一致性,而局部鉴别器仅在以填充区域为中心的原图像4分之一大小区域上观测,识别局部一致性。

通过采用两个不同的鉴别器,使得最终网络不但可以使全局观测一致,并且能够优化其细节,最终产生更好的图片填充效果。
1.2知识学习情况
填充网络
具体到其填充网络部分,是完全基于卷积网络的。原文中给出的卷积网络设置如下:

网络输入时原始图像,包含RGB三色的通道,以及一个binary的覆盖层,用于盖住需要填充的部分。论文中有提到因为作者不想修改原始图片的内容,所以对于没有被覆盖的部分,他们会直接采用原始图片中的像素进行填充。
除此之外,通过观察网络结构,我们可以看出这个网络前面若干层是对原始图像的encoding,在第二层以及第四层网络,通过2X2的stride降低分辨率,减少存储空间和计算时间。再通过一系列的convolution和dilated convolution调整后,结果通过deconvolution layer恢复到原始分辨率。在整个网络中,作者采用ReLU函数,在最后一层采用Sigmoid函数使得输出在0到1区间内。
作者在文章中提到两点注意事项,第一点是他们的网络模型仅仅降低了两次分辨率,使用大小为原始大小4分之一的卷积,其目的是为了降低最终图像的纹理模糊程度。
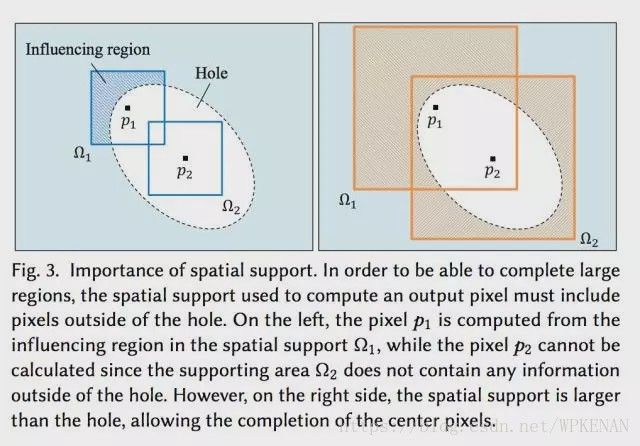
第二点就是他们使用了Multi-Scale Context Aggregation by Dilated Convolutions中提到的dilated convolutional layer。这种卷积形式中文被称作空洞卷积,能够通过相同数量的参数和计算能力感知每个像素周围更大的区域。在文章中,作者通过一张图给出说明,为了能够计算填充图像每一个像素的颜色,该像素需要知道周围图像的内容,采用空洞卷积能够帮助每一个点有效的“看到”比使用标准卷积更大的输入图像区域,从而填充图中点p2的颜色。对这一方面感兴趣的同学可以再阅读一下知乎上的问题“如何理解空洞卷积”。
在tensorflow当中,atrous_conv2d实现了所谓的dilated convolution,可以通过一段函数对他进行包装:

鉴别网络
如上文所示,鉴别网络分为全局鉴别网络和局部鉴别网络两个部分。全局鉴别网络输入是256X256,RGB三通道图片,局部网络输入是128X128,RGB三通道图片,根据原始论文当中的设置,全局网络和局部网络都会通过5X5的convolution layer,以及2X2的stride降低分辨率,最终分别得到1024维向量。
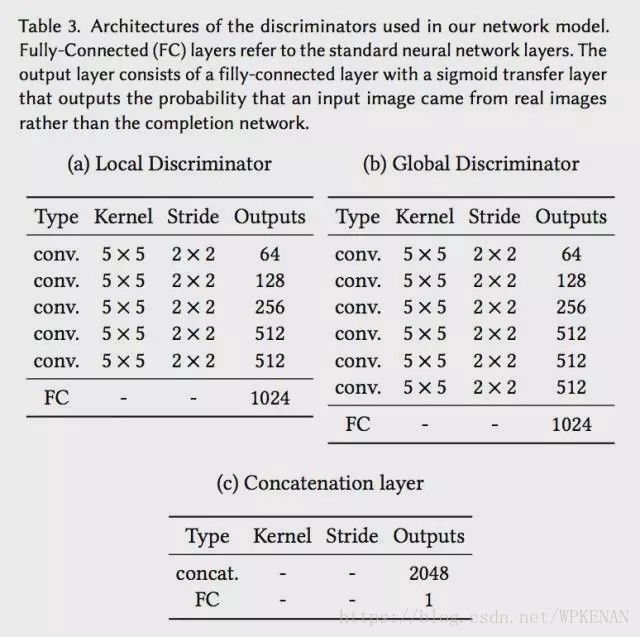
然后,我们将全局和局部两个鉴别器输出连接成一个2048维向量,通过一个全连接然后用sigmoid函数得到整体图像一致性打分。
我个人比较赞同他们这样打分系统的设计理念,但是再具体实现上持有一定怀疑态度。因为最终鉴别器是基于两部分鉴别器产生的中间结果,我个人感觉优化鉴别器并不等于同时优化了全局和局部鉴别器的一致性,不知道各位读者怎么看?
训练过程
训练图片填充所要优化的函数和上一篇文章“民科带你读文章: 用DCGAN补全图片”类似,除了要对GAN系统进行最大最小优化之外,我们需要同时考虑填充图像与真实图像误差。这里我们采用MSE(Mean Squared Error)作为对填充图像C(x)与真实图像x之间的误差衡量函数:

通过加权,我们可以合并MSE函数和对抗网络GAN的loss function:

针对我在上一段提到的两个鉴别器的问题,这一张作者也有说到“As the optimization consists of jointly minimizing and maximizing conflicting objectives, it is not very stable.”
由于图像填充问题本来就是非常有挑战性的,所以训练过程需要非常小心。作者在这一张给出了如下图所示的训练过程,整个算法分为三个阶段:第一阶段(最初的Tc轮)主要优化completion network C;第二阶段(Tc~Tc+Td轮)主要优化discriminators D;最后在同时优化所有损失函数。

除了基本的深度学习以外,还通过传统的图像处理方法对生成图片边缘进行了修正,下图展示了修正带来的效果:

解决复杂工程问题情况
由于这篇文章没有公开任何代码和训练模型,所以我不得不从头开始自己实现,过程中最大的挑战就是GAN自身的不稳定性。
实现方面,因为有上一篇文章DCGAN开源的代码,所以我直接去修改了Discriminator和Generator。因为没有GPU,所以我采用64X64的人脸进行学习而非256X256的Place2数据集。
识别部分分别鉴定两个区域的一致性。
存在问题与解决方案
存在的主要问题
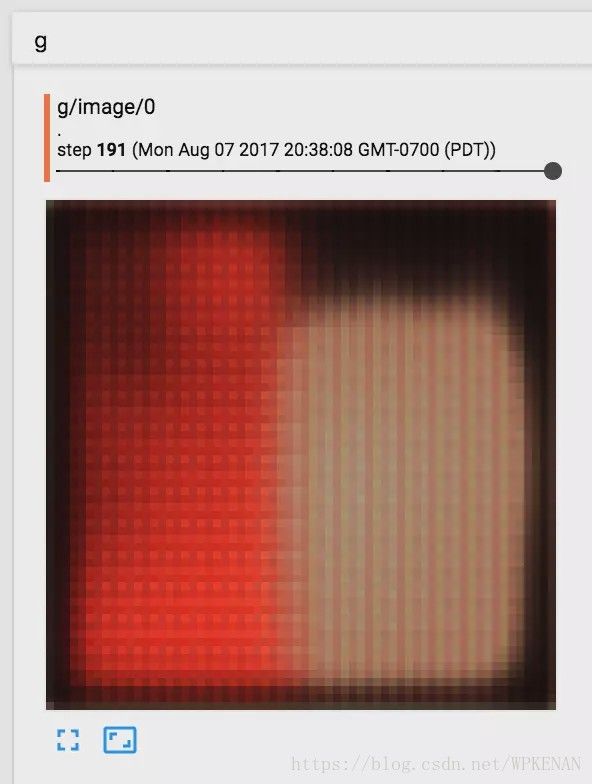
在我实现这篇文章中提到的算法时,遇到最大的问题就是GAN的不稳定性。起初,我设置的MSE权重比例太低,另外discriminator比generator训练速度快非常多,导致我的discriminator可以轻易的分辨出哪张是自然图像,哪张是生成图像,但是传递给generator的梯度只能使他生成奇怪的纹路:
在我调整了MSE权重后,目前可以生成人脸轮廓,但是只训练了300多轮,估计以我现在的CPU还要等好多天才行。

解决方案与可行性研究
首先,先对原始人脸进行一定程度的降维,然后通过一个简单的全连接层,将人脸变为一个128维向量。在得到人脸的encoding结果后,采用原始DCGAN的思路生成新的图像,在生成过程中同时优化MSE和GAN损失函数。这样的生成网络进行在我的破电脑上运行一轮大约只要10秒钟。

几千轮训练过后,我们生成的图像在一定程度上与原图相似,但是最终的64X64大小的像素是根据encoding后128维向量生成,边界非常不平滑,纹理也不清晰。也许我还是应该尝试将图片编码压缩为16X16,多通道参数,而非一维编码。
下一步计划
接下来我会继续调试现在的代码,然后研究一下如何稳定GAN的训练过程,也许应该看WGAN?针对图片补全这一个问题,我们回头看看传统的研究思路,能不能结合GAN得到提高。