- 分布式中间件:Redisson 入门和分布式锁
顾北辰20
分布式中间件分布式中间件redisson
分布式中间件:Redisson入门和分布式锁在分布式系统的开发中,处理并发问题是一个常见且具有挑战性的任务。为了确保数据的一致性和完整性,我们常常需要使用分布式锁。Redisson作为一个强大的分布式Java驻内存数据网格(In-MemoryDataGrid)中间件,为我们提供了简单且高效的分布式锁解决方案。本文将带你入门Redisson,并介绍如何使用它实现分布式锁。1.引入Redisson依赖
- ZooKeeper集群高可用性测试与实践:从规划到故障模拟
磐基Stack专业服务团队
Zookeeperzookeeper可用性测试
#作者:任少近文章目录ZooKeeper集群环境规划1.集群数据一致性测试2.集群节点故障测试ZooKeeper集群高可用性测试的主要目的是确保在分布式环境中,ZooKeeper服务能够持续提供一致性和高可用性的协调服务。ZooKeeper集群环境规划节点ipZooKeeper版本java版本对外端口集群通信端口集群选举端口192.168.x.xZooKeeper-3.6.11.8.0_33221
- Kafka跨集群数据备份与同步:MirrorMaker运用
磐基Stack专业服务团队
Kafkakafka分布式
#作者:张桐瑞文章目录前言MirrorMaker是什么运行MirrorMaker各个参数的含义前言在大多数情况下,我们会部署一套Kafka集群来支撑业务需求。但在某些特定场景下,可能需要同时运行多个Kafka集群。比如,为了实现灾难恢复,你可以在不同机房分别部署独立的Kafka集群。如果一个机房发生故障,你可以快速切换流量到另一个正常运行的机房。另外,如果你希望为地理上较近的客户提供低延迟的消息服
- 【大模型系列】SFT(Supervised Fine-Tuning,监督微调)
Kwan的解忧杂货铺@新空间代码工作室
s2AIGC大模型
欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。推荐:kwan的首页,持续学习,不断总结,共同进步,活到老学到老导航檀越剑指大厂系列:全面总结java核心技术,jvm,并发编程redis,kafka,Spring,微服务等常用开发工具系列:常用的开发工具,IDEA,Mac,Alfred,Git,
- 深入理解 Kafka 的 ConsumerRebalanceListener
t0_54coder
编程问题解决手册kafkalinq分布式
深入理解Kafka的ConsumerRebalanceListener在分布式系统中,数据的一致性和可靠性是至关重要的。ApacheKafka作为一个流行的分布式流处理平台,提供了强大的数据传输和处理能力。在Kafka中,消费者组(ConsumerGroup)的概念允许多个消费者实例共同处理一个主题的数据。然而,当消费者实例的个数发生变化时,如何确保数据的平衡和一致性呢?这就引出了我们今天要讨论的
- 如何解决Kafka Rebalance引起的重复消费
maozexijr
kafkalinq分布式
在Kafka中,Rebalance(再平衡)是消费者组(ConsumerGroup)动态调整分区分配的过程。当消费者组中的成员发生变化(例如消费者加入或退出)、订阅的Topic分区数量变化、或者消费者长时间未发送心跳时,都会触发Rebalance。虽然Rebalance有助于负载均衡和容错,但它也可能导致重复消费的问题。以下是一些解决因Rebalance引起的重复消费问题的方法:1.禁用自动提交O
- oceanbase与mysql性能对比_金融业分布式数据库:TDSQL、HotDB、OceanBase等原理、POC性能对比及选择是......
高中物理宋老师
本帖最后由Amygo于2020-3-1501:33编辑1、分布式的实现,是通过中间件实现分布式,还是源码级别引入分布式算法实现的?解答:(1)分布式数据库是至少由计算节点、存储节点、管理平台、备份还原程序四个部分组成,从数据库系统理论知识上说分成:全局自治和场地自治,也粗略认为:全局可理解为计算节点、场地可理解为存储节点(2)这个问题的标题“中间件实现分布式还是源码级别引入分布式算法”这个说法存在
- 后端框架模块化
GIS程序媛—椰子
后端
后端框架的模块化设计旨在简化开发流程、提高可维护性,并通过分层解耦降低复杂性。以下是常见的后端模块及其在不同语言(Node.js、Java、Python)中的实现方式:目录1.路由(Routing)2.中间件(Middleware)3.数据库与ORM(models)4.迁移(Migration)5.服务层(ServiceLayer)6.配置管理(Configuration)7.依赖注入(DI)8.
- Redis缓存中间件(非关系型数据库)
小狼人发JO酸奶
缓存redis中间件
最近一段时间整理了关于一些知识的总结,其中就拿出Redis来说说,其他的整理的有些杂还在梳理,相信不久就会和大家见面,期待ne.......,不废话了,开始!Redis作为非关系型数据库,终是要涉及到持久化的,毕竟缓存可没落地,很可能丢失的。Redis持久化主要为:RDB全量持久,AOF增量持久:RDB耗时长非实时记录应配合AOF使用,从而避免停机大量丢失数据。Redis重启时:RDB重构内存+A
- Dify - 架构、部署、扩展与二次开发指南
花千树-010
AIGC架构AIGCpromptembeddingllamagptagi
本文详细解析Dify的架构、部署流程、高可用中间件的独立部署方法,以及二次开发流程,帮助开发者更高效地管理和扩展Dify。1.本地DEMO部署安装Docker,执行下面脚本,可能需要配置镜像。gitclonehttps://github.com/langgenius/dify.gitcddifycddockercp.env.example.envdockercomposeup-d1.Dify部署后
- 亿级分布式系统架构演进实战(一)- 总体概要
power-辰南
java技术架构师成长专栏高并发分布式系统微服务架构设计springcloud
前言不说废话,这次分享是某500强企业真实亿级流量业务中台技术架构演进过程实战。核心目标构建一个兼具高性能、高可用、强一致性的分布式系统,支撑亿级流量场景下的稳定运行。演进路线大纲阶段一:横向扩展(应对万级QPS)核心目标:突破单机性能瓶颈,建立弹性基础[Nginx]/|\[App1][App2][App3]←无状态服务集群\|/[DBProxy]←读写分离中间件/\[Master]←写节点[Sl
- 自动驾驶中间件技术辨析:ROS、Apex.Grace、DDS、AutoSAR和AutoSAR Adaptive
赛卡
自动驾驶中间件人工智能
在自动驾驶技术的演进中,中间件作为连接硬件、操作系统与应用软件的核心枢纽,其安全性、实时性和可扩展性至关重要。当前市场上主流的中间件技术包括ROS/ROS2、Apex.Grace(Apex.OS)、DDS、AutoSAR(经典平台CP)和AutoSARAdaptive(自适应平台AP)。这些技术各有特点,但也存在交叉与互补。本文将从功能定位、技术架构、安全认证和应用场景等方面,深入分析它们的联系与
- Kafka深度解析
GarfieldEr007
Kafka/MQKafka深度解析MQ
原创文章,转载请务必将下面这段话置于文章开头处(保留超链接)。本文转发自Jason’sBlog,原文链接http://www.jasongj.com/2015/01/02/Kafka深度解析背景介绍Kafka简介Kafka是一种分布式的,基于发布/订阅的消息系统。主要设计目标如下:以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间的访问性能高吞吐率。即使在非常廉价
- 【运维的七种武器】
搞技术的季
运维
最近项目陆续增加,相应的运维方面压力逐步攀升,经常出现打包和发布失败的情况,给交付团队带来困扰。运维技术是随着软件技术的发展同步发展起来的,当前复杂的软件技术架构对运维的稳定和高效带了了很大挑战。一、运维平台发展史:1.第一阶段,以专业化网管工具为代表,包括网络设备、主机、数据库、中间件、存储等进行专业监控管理的各种专业化工具。2.第二阶段,以ITIL流程化管理为代表的综合网管,通过事件、服务、流
- Flink命令行启动Job任务
平凡的运维之路
linux程序人生
Flink非交互式运行Job任务Flink命令行启动Job任务具体命令flink参数说明-c,--class-d,--detached后台运行-p,--parallelism并行度[test@xxx~]$flinkrun-d-cclass_nameJob-p3./flink-statics-1.0.jar-zookeeper"10.130.41.51:2181,10.130.41.52:2181,
- 关于kafka常见的问题小结
BAStriver
#Kafka中间件kafka分布式
目录1.Kafka怎么避免重复消费1.1什么时候出现重复消费1.2如何处理重复消费问题2.Kafka怎么保证消息不丢失2.1Producer2.2Broker2.3Consumer3.Kafka怎么保证消息消费的顺序最近面试遇到一些常见kafka问题,所以做一下总结。1.Kafka怎么避免重复消费1.1什么时候出现重复消费1)Kafka的broker上存储的消息都有一个offset作为标记,然后K
- 【Kafka高级】Kafka性能优化与调优实践
全栈追梦人
kafka性能优化linq
在大规模数据处理和实时消息传递场景中,Kafka的性能优化至关重要。本文将从生产者性能优化、消费者性能优化以及集群性能调优三个方面展开,结合实际代码示例和配置参数,帮助读者更好地理解和应用Kafka性能优化策略。一、生产者性能优化Kafka生产者的性能直接影响消息发送的效率和系统的吞吐量。以下是一些关键优化策略:1.1批量发送生产者会将消息批量发送到Kafka,减少网络请求次数。以下参数对批量发送
- 消息中间件:RabbitMQ、Kafka 和 Redis如何选择?一文让您了解!
写bug如流水
架构设计rabbitmqkafkaredis中间件
RabbitMQ、Kafka和Redis是三种常见的消息中间件,它们各自具有不同的特点和适用的场景。以下是对它们使用场景及选择的分析:1.RabbitMQRabbitMQ是一个基于AMQP(AdvancedMessageQueuingProtocol)的消息队列系统,主要用于消息传递和任务分发,具有可靠的消息传递机制。使用场景:复杂的路由机制:RabbitMQ支持多种交换器类型(如fanout、d
- Kafka Connect Node.js Connector 指南
丁操余
KafkaConnectNode.jsConnector指南kafka-connectequivalenttokafka-connect:wrench:fornodejs:sparkles::turtle::rocket::sparkles:项目地址:https://gitcode.com/gh_mirrors/ka/kafka-connect项目介绍KafkaConnectNode.jsConn
- 消息中间件选型: kafka与rabbitmq的对比
HS_Henry
消息中间件rabbitmqkafka消息中间件选型
RabbitMQ总结_陈海龙的格物之路-CSDN博客https://blog.csdn.net/chl87783255/article/details/122606212kafka总结_陈海龙的格物之路-CSDN博客kafka,仅支持拉取的分布式流式平台。本文从简介、使用场景、设计、实现四个方面阐述kafka。https://blog.csdn.net/chl87783255/article/de
- RabbitMQ 与 Kafka:消息中间件的终极对比与选型指南
海上彼尚
node.jsrabbitmqkafka分布式node.js
引言在分布式系统架构中,消息中间件是异步通信的核心组件。RabbitMQ和Kafka作为两大主流技术,常被开发者拿来比较。本文深入解析两者的设计哲学、性能差异和典型场景,助你做出精准技术选型。目录引言一、核心设计差异1.定位与数据模型二、性能与架构对比1.吞吐量与延迟2.集群与扩展三、功能特性对决1.消息可靠性2.消息路由四、典型场景与选型决策1.优先选择Kafka的场景2.优先选择RabbitM
- 【存储中间件】Redis核心技术与实战(六):Redis的设计与实现(缓存淘汰算法、过期策略与惰性删除)
道友老李
#Redis核心技术与实战架构师进阶-存储中间件缓存中间件redis
文章目录Redis的设计与实现缓存淘汰算法maxmemoryNoevictionvolatile-lruvolatile-ttlvolatile-randomallkeys-lruallkeys-randomLRU算法近似LRU算法LFU算法为什么Redis要缓存系统时间戳过期策略和惰性删除过期惰性删除lazyfree个人主页:道友老李欢迎加入社区:道友老李的学习社区Redis的设计与实现缓存淘汰
- ActiveMQ
z小天才b
ActiveMQjava-activemqactivemqspringboot
一、ActiveMQ概述1.1什么是ActiveMQ?ActiveMQ是Apache软件基金会开发的一个开源消息中间件,它完全支持JMS(Java消息服务)规范,并提供了高可用性、高性能和可扩展性。ActiveMQ允许不同的应用程序通过消息传递进行异步通信,从而实现系统解耦。1.2ActiveMQ核心特性多协议支持:支持OpenWire、STOMP、AMQP、MQTT等多种协议持久化:支持多种持久
- RocketMQ 和 Kafka
重生之我在成电转码
rocketmqKafkajava消息队列
✅RocketMQ和Kafka是两种非常流行的分布式消息队列系统,它们广泛用于大规模、高并发的消息传递和事件驱动架构中。虽然它们都属于消息队列,但在设计理念、特性和应用场景上有一些差异。接下来,我们来深入分析这两者的区别与优缺点。一、Kafka和RocketMQ的概述✅1️⃣KafkaKafka是一个分布式的流处理平台,由Apache软件基金会开发,最初由LinkedIn开发并开源。Kafka主要
- springboot+kafka+邮件发送(最佳实践)
weixin_30347335
大数据java数据库
导读集成spring-kafka,生产者生产邮件message,消费者负责发送引入线程池,多线程发送消息多邮件服务器配置定时任务生产消息;计划邮件发送实现过程导入依赖1.85.1.382.1.51.3.22.8.23.4org.springframework.bootspring-boot-starterorg.springframework.bootspring-boot-starter-tes
- vue中js简单创建一个事件中心/中间件/eventBus
星月前端
javascriptvue.js前端
vue中js简单创建一个事件中心/中间件/eventBus目录结构如下:eventBus.jsclasseventBus{constructor(){this.events={};}//监听事件on(event,callback){if(!this.events[event]){this.events[event]=[];}this.events[event].push(callback);}//
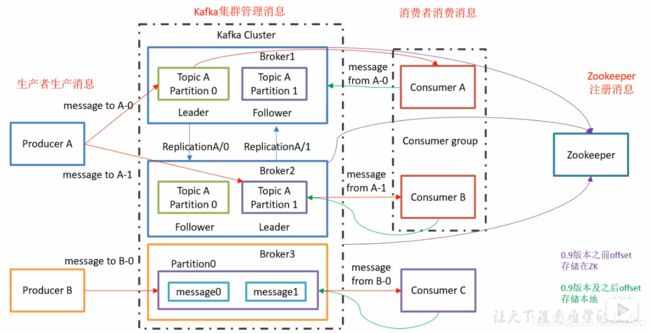
- zookeeper&nacos&kafka之间的联系
Gold Steps.
技术博文分享zookeeperkafka微服务服务发现
一、ZooKeeper与Kafka的协同工作原理1.核心关系:Kafka对ZooKeeper的依赖在Kafka2.8版本之前,ZooKeeper是Kafka集群的“大脑”,负责管理集群元数据、协调节点状态和故障恢复。两者的协同主要通过以下关键机制实现:Broker注册与心跳KafkaBroker启动时会在ZooKeeper的/brokers/ids路径下注册临时节点(EphemeralNode),
- Kafka集群部署实战
Gold Steps.
技术博文分享kafka分布式
服务背景ApacheKafka作为分布式流处理平台,在金融交易系统、物联网数据处理、实时日志分析等场景中发挥关键作用。某电商平台日均处理订单消息1.2亿条,峰值QPS达5万,采用Kafka集群实现订单状态流转、用户行为追踪和库存同步等功能。以下是经过生产验证的集群部署方案及典型故障处理经验。集群运维最佳实践1.容量规划建议指标推荐值监控阈值分区数量/Broker≤4000≥3500告警副本同步延迟
- Nodejs模块:使用Helmet 增强Web应用安全性
ohn.yu
Nodejsjavascriptnode.js
Helmet是一个Node.js中间件,主要用于增强Web应用的安全性。它通过设置各种HTTP响应头,帮助你的应用抵御多种常见的Web漏洞攻击,例如跨站脚本攻击(XSS)、点击劫持(Clickjacking)、内容嗅探攻击(ContentSniffing)等。1.什么是Helmet?为什么使用Helmet?Helmet本身并不是一个"银弹",不能解决所有的安全问题,但它提供了一个简单有效的方式来设
- Springboot启动失败:解决「org.yaml.snakeyaml.error.YAMLException」报错全记录
-天凉好秋-
springbootjavaideavisualstudiocode
##关键字Java、Springboot、vscode、idea、nacos启动失败、YAMLException、字符集配置---##背景环境###项目架构-**框架**:SSM(Spring+SpringMVC+MyBatis)-**中间件**:Nacos(配置管理+服务发现)-**配置存储**:Nacos中存储了Springboot的配置,包括:数据库连接信息、Redis连接信息、服务配置等。
- apache ftpserver-CentOS config
gengzg
apache
<server xmlns="http://mina.apache.org/ftpserver/spring/v1"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://mina.apache.o
- 优化MySQL数据库性能的八种方法
AILIKES
sqlmysql
1、选取最适用的字段属性 MySQL可以很好的支持大数据量的存取,但是一般说来,数据库中的表越小,在它上面执行的查询也就会越快。因此,在创建表的时候,为了获得更好的 性能,我们可以将表中字段的宽度设得尽可能小。例如,在定义邮政编码这个字段时,如果将其设置为CHAR(255),显然给数据库增加了不必要的空间,甚至使用VARCHAR这种类型也是多余的,因为CHAR(6)就可以很
- JeeSite 企业信息化快速开发平台
Kai_Ge
JeeSite
JeeSite 企业信息化快速开发平台
平台简介
JeeSite是基于多个优秀的开源项目,高度整合封装而成的高效,高性能,强安全性的开源Java EE快速开发平台。
JeeSite本身是以Spring Framework为核心容器,Spring MVC为模型视图控制器,MyBatis为数据访问层, Apache Shiro为权限授权层,Ehcahe对常用数据进行缓存,Activit为工作流
- 通过Spring Mail Api发送邮件
120153216
邮件main
原文地址:http://www.open-open.com/lib/view/open1346857871615.html
使用Java Mail API来发送邮件也很容易实现,但是最近公司一个同事封装的邮件API实在让我无法接受,于是便打算改用Spring Mail API来发送邮件,顺便记录下这篇文章。 【Spring Mail API】
Spring Mail API都在org.spri
- Pysvn 程序员使用指南
2002wmj
SVN
源文件:http://ju.outofmemory.cn/entry/35762
这是一篇关于pysvn模块的指南.
完整和详细的API请参考 http://pysvn.tigris.org/docs/pysvn_prog_ref.html.
pysvn是操作Subversion版本控制的Python接口模块. 这个API接口可以管理一个工作副本, 查询档案库, 和同步两个.
该
- 在SQLSERVER中查找被阻塞和正在被阻塞的SQL
357029540
SQL Server
SELECT R.session_id AS BlockedSessionID ,
S.session_id AS BlockingSessionID ,
Q1.text AS Block
- Intent 常用的用法备忘
7454103
.netandroidGoogleBlogF#
Intent
应该算是Android中特有的东西。你可以在Intent中指定程序 要执行的动作(比如:view,edit,dial),以及程序执行到该动作时所需要的资料 。都指定好后,只要调用startActivity(),Android系统 会自动寻找最符合你指定要求的应用 程序,并执行该程序。
下面列出几种Intent 的用法
显示网页:
- Spring定时器时间配置
adminjun
spring时间配置定时器
红圈中的值由6个数字组成,中间用空格分隔。第一个数字表示定时任务执行时间的秒,第二个数字表示分钟,第三个数字表示小时,后面三个数字表示日,月,年,< xmlnamespace prefix ="o" ns ="urn:schemas-microsoft-com:office:office" />
测试的时候,由于是每天定时执行,所以后面三个数
- POJ 2421 Constructing Roads 最小生成树
aijuans
最小生成树
来源:http://poj.org/problem?id=2421
题意:还是给你n个点,然后求最小生成树。特殊之处在于有一些点之间已经连上了边。
思路:对于已经有边的点,特殊标记一下,加边的时候把这些边的权值赋值为0即可。这样就可以既保证这些边一定存在,又保证了所求的结果正确。
代码:
#include <iostream>
#include <cstdio>
- 重构笔记——提取方法(Extract Method)
ayaoxinchao
java重构提炼函数局部变量提取方法
提取方法(Extract Method)是最常用的重构手法之一。当看到一个方法过长或者方法很难让人理解其意图的时候,这时候就可以用提取方法这种重构手法。
下面是我学习这个重构手法的笔记:
提取方法看起来好像仅仅是将被提取方法中的一段代码,放到目标方法中。其实,当方法足够复杂的时候,提取方法也会变得复杂。当然,如果提取方法这种重构手法无法进行时,就可能需要选择其他
- 为UILabel添加点击事件
bewithme
UILabel
默认情况下UILabel是不支持点击事件的,网上查了查居然没有一个是完整的答案,现在我提供一个完整的代码。
UILabel *l = [[UILabel alloc] initWithFrame:CGRectMake(60, 0, listV.frame.size.width - 60, listV.frame.size.height)]
- NoSQL数据库之Redis数据库管理(PHP-REDIS实例)
bijian1013
redis数据库NoSQL
一.redis.php
<?php
//实例化
$redis = new Redis();
//连接服务器
$redis->connect("localhost");
//授权
$redis->auth("lamplijie");
//相关操
- SecureCRT使用备注
bingyingao
secureCRT每页行数
SecureCRT日志和卷屏行数设置
一、使用securecrt时,设置自动日志记录功能。
1、在C:\Program Files\SecureCRT\下新建一个文件夹(也就是你的CRT可执行文件的路径),命名为Logs;
2、点击Options -> Global Options -> Default Session -> Edite Default Sett
- 【Scala九】Scala核心三:泛型
bit1129
scala
泛型类
package spark.examples.scala.generics
class GenericClass[K, V](val k: K, val v: V) {
def print() {
println(k + "," + v)
}
}
object GenericClass {
def main(args: Arr
- 素数与音乐
bookjovi
素数数学haskell
由于一直在看haskell,不可避免的接触到了很多数学知识,其中数论最多,如素数,斐波那契数列等,很多在学生时代无法理解的数学现在似乎也能领悟到那么一点。
闲暇之余,从图书馆找了<<The music of primes>>和<<世界数学通史>>读了几遍。其中素数的音乐这本书与软件界熟知的&l
- Java-Collections Framework学习与总结-IdentityHashMap
BrokenDreams
Collections
这篇总结一下java.util.IdentityHashMap。从类名上可以猜到,这个类本质应该还是一个散列表,只是前面有Identity修饰,是一种特殊的HashMap。
简单的说,IdentityHashMap和HashM
- 读《研磨设计模式》-代码笔记-享元模式-Flyweight
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
import java.util.ArrayList;
import java.util.Collection;
import java.util.HashMap;
import java.util.List;
import java
- PS人像润饰&调色教程集锦
cherishLC
PS
1、仿制图章沿轮廓润饰——柔化图像,凸显轮廓
http://www.howzhi.com/course/retouching/
新建一个透明图层,使用仿制图章不断Alt+鼠标左键选点,设置透明度为21%,大小为修饰区域的1/3左右(比如胳膊宽度的1/3),再沿纹理方向(比如胳膊方向)进行修饰。
所有修饰完成后,对该润饰图层添加噪声,噪声大小应该和
- 更新多个字段的UPDATE语句
crabdave
update
更新多个字段的UPDATE语句
update tableA a
set (a.v1, a.v2, a.v3, a.v4) = --使用括号确定更新的字段范围
- hive实例讲解实现in和not in子句
daizj
hivenot inin
本文转自:http://www.cnblogs.com/ggjucheng/archive/2013/01/03/2842855.html
当前hive不支持 in或not in 中包含查询子句的语法,所以只能通过left join实现。
假设有一个登陆表login(当天登陆记录,只有一个uid),和一个用户注册表regusers(当天注册用户,字段只有一个uid),这两个表都包含
- 一道24点的10+种非人类解法(2,3,10,10)
dsjt
算法
这是人类算24点的方法?!!!
事件缘由:今天晚上突然看到一条24点状态,当时惊为天人,这NM叫人啊?以下是那条状态
朱明西 : 24点,算2 3 10 10,我LX炮狗等面对四张牌痛不欲生,结果跑跑同学扫了一眼说,算出来了,2的10次方减10的3次方。。我草这是人类的算24点啊。。
然后么。。。我就在深夜很得瑟的问室友求室友算
刚出完题,文哥的暴走之旅开始了
5秒后
- 关于YII的菜单插件 CMenu和面包末breadcrumbs路径管理插件的一些使用问题
dcj3sjt126com
yiiframework
在使用 YIi的路径管理工具时,发现了一个问题。 <?php
- 对象与关系之间的矛盾:“阻抗失配”效应[转]
come_for_dream
对象
概述
“阻抗失配”这一词组通常用来描述面向对象应用向传统的关系数据库(RDBMS)存放数据时所遇到的数据表述不一致问题。C++程序员已经被这个问题困扰了好多年,而现在的Java程序员和其它面向对象开发人员也对这个问题深感头痛。
“阻抗失配”产生的原因是因为对象模型与关系模型之间缺乏固有的亲合力。“阻抗失配”所带来的问题包括:类的层次关系必须绑定为关系模式(将对象
- 学习编程那点事
gcq511120594
编程互联网
一年前的夏天,我还在纠结要不要改行,要不要去学php?能学到真本事吗?改行能成功吗?太多的问题,我终于不顾一切,下定决心,辞去了工作,来到传说中的帝都。老师给的乘车方式还算有效,很顺利的就到了学校,赶巧了,正好学校搬到了新校区。先安顿了下来,过了个轻松的周末,第一次到帝都,逛逛吧!
接下来的周一,是我噩梦的开始,学习内容对我这个零基础的人来说,除了勉强完成老师布置的作业外,我已经没有时间和精力去
- Reverse Linked List II
hcx2013
list
Reverse a linked list from position m to n. Do it in-place and in one-pass.
For example:Given 1->2->3->4->5->NULL, m = 2 and n = 4,
return
- Spring4.1新特性——页面自动化测试框架Spring MVC Test HtmlUnit简介
jinnianshilongnian
spring 4.1
目录
Spring4.1新特性——综述
Spring4.1新特性——Spring核心部分及其他
Spring4.1新特性——Spring缓存框架增强
Spring4.1新特性——异步调用和事件机制的异常处理
Spring4.1新特性——数据库集成测试脚本初始化
Spring4.1新特性——Spring MVC增强
Spring4.1新特性——页面自动化测试框架Spring MVC T
- Hadoop集群工具distcp
liyonghui160com
1. 环境描述
两个集群:rock 和 stone
rock无kerberos权限认证,stone有要求认证。
1. 从rock复制到stone,采用hdfs
Hadoop distcp -i hdfs://rock-nn:8020/user/cxz/input hdfs://stone-nn:8020/user/cxz/运行在rock端,即源端问题:报版本
- 一个备份MySQL数据库的简单Shell脚本
pda158
mysql脚本
主脚本(用于备份mysql数据库): 该Shell脚本可以自动备份
数据库。只要复制粘贴本脚本到文本编辑器中,输入数据库用户名、密码以及数据库名即可。我备份数据库使用的是mysqlump 命令。后面会对每行脚本命令进行说明。
1. 分别建立目录“backup”和“oldbackup” #mkdir /backup #mkdir /oldbackup
- 300个涵盖IT各方面的免费资源(中)——设计与编码篇
shoothao
IT资源图标库图片库色彩板字体
A. 免费的设计资源
Freebbble:来自于Dribbble的免费的高质量作品。
Dribbble:Dribbble上“免费”的搜索结果——这是巨大的宝藏。
Graphic Burger:每个像素点都做得很细的绝佳的设计资源。
Pixel Buddha:免费和优质资源的专业社区。
Premium Pixels:为那些有创意的人提供免费的素材。
- thrift总结 - 跨语言服务开发
uule
thrift
官网
官网JAVA例子
thrift入门介绍
IBM-Apache Thrift - 可伸缩的跨语言服务开发框架
Thrift入门及Java实例演示
thrift的使用介绍
RPC
POM:
<dependency>
<groupId>org.apache.thrift</groupId>