Active Object Localization with Deep Reinforcement Learning
ICCV 2015
最近Deep Reinforcement Learning算是火了一把,在Google Deep Mind的主页上,更是许多关于此的paper,基本都发在ICML,AAAI,IJCAI等各种人工智能,机器学习的牛会顶刊,甚至是Nature,可以参考其官方publication page: https://www.deepmind.com/publications.html
本文是做特定物体的定位和检测,但是不用提取proposal的方式。本文的方法采用从上至下的搜索策略,刚开始的时候,是分析整个场景,然后向物体准确的位置行进。其实,就是先用一个较大的box将物体框住,然后一步一步的缩小,最终使得物体完美的被一个紧凑的box围住。重点是这个step by step的定位过程,该过程是由一个机制确定,并且分析当前可见区域的内容,然后选择下一步最优的action,每一步transformation都尽可能将背景部分砍掉,并且要将物体完整的留在box之中,示例的调整过程如下图所示:

本文所用的方法是 dynamic attention-action strategy,需要注意当前区域的内容,使得转移box的导向是:the target object is progressively more focused. 为了模拟所提出机制的attention,当前box覆盖目标物体的好坏决定了奖励函数(reward function)。基于DeepQNetwork algorithm,作者将奖励函数和增强学习(reinforcement learning setting)结合来学习一个定位策略(localization policy)。作者的结果表明,一个训练的agent可以在11步左右定位到一个物体的示例,这意味着该算法可以在处理11个区域之后准确的找到一个物体。
Object Localization as a Dynamic Decision Process
本文将物体定位问题看做为马尔科夫决策过程(Markov decision process (MDP)),因为这套设置提供了一个正式的框架来建模一个agent,能够做出一系列的决策。该机制拥有当前可见区域的状态描述(state representation with information of the currently visible region) 和 过去的动作(past actions),在训练的过程中,会对每一个决定都会给出positive or negative rewards。在测试的过程中,该机制不在收到反馈,不再更新model,只是遵循学习到的策略。所以,MDP由三个部分构成,即:a set of actions A, a set of states S, and a reward function R.
1. Localization Actions
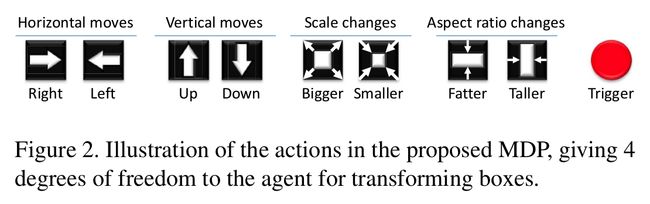
可以看到 action set A 有8个转移动作(四个方向的移动,尺寸的放大和缩小,长宽比例的变换)和1个终止动作(Trigger)。box的位置:b = [x1, y1, x2, y2], 任何一个转移动作(transformation actions)都会对box造成一个discrete change,通过:

2. State
The state representation is a tuple (o, h), 其中 o 是观测区域的特征向量,h 是一个向量,存储的是所采用action的历史记录。特征向量 o 是用CNN网络结构提取的,将输入改为224*224,将fc6层的feature提出来。在历史记录向量中,每一个action都表示为一个9维的二进制向量,除了存在的那个动作为1,其余的都为0. 文中将该记录编码为10个 past actions,那么h就是一个 90维的向量。
3. Reward Function
奖励函数 R 和选定一个特定区域后该机制定位物体的提升程度成正比。预测box和给定box的重叠程度作为我们setup的改善的衡量标准。More specifically,奖励函数用从一个状态到另一个状态的IoU的不同来预测。假设观测区域的box 为b,目标物体的gt box为 g。b和g之间的IoU定义为:
IoU(b, g) = area(b^g) / area(bvg).
当agent选定action a 从 s 移动到 s'时,执行奖励函数 Ra(s, s'). 每一个状态 s 有一个相关的box b包含倾向的区域,then the reward is as follows:
Ra(s, s') = sign ( IoU(b', g) - IoU(b, g) )
可以看到,从状态s到s',如果IoU改善了,那么奖励就是positive的,否则就是negative的。奖励机制是二值 r 属于{-1, +1}, 适合用所有转移box的action。通过这种方式,agent对于那些移走box的操作给予惩罚,对于那些符合要求的action给予奖励,直到没有其余的转移可以更好的改善定位,在这种情况下,就要进行trigger操作了。
Trigger拥有一个不同的奖励机制,因为这个操作会带来终止状态,该action的IoU差别会永远为0。IoU的阈值函数作为trigger的奖励:
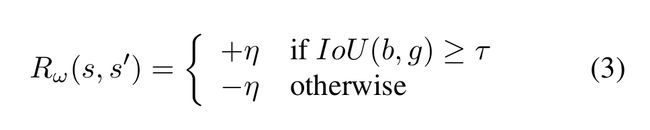
最终,the reward scheme显示的考虑了step的个数作为一个cost,the agent follow a greedy strategy,which prefers short sequences because any unnecessary step pays a penalty that reduces the accumulated utility.
Finding a Localization Policy with Reinforcement Learning
Agent的设计是为了一系列的选择actions来转移bbox,使得在与环境交互的过程中,得到的rewards最大。核心问题是找到一个策略指导agent的决策制定的过程。一个策略就是一个函数pi(s)来指定选择action a,当current state is s。由于我们没有状态转移概率,且奖励函数是依赖于数据的,该问题就构成了利用Q-Learning的增强学习问题。
本文follow了Mnih et al.的deep Q-learning algorithm,该算法利用神经网络预测 action-value function,与之前的Q-learning方法对比,有如下几点优势:
(1). Q-network的输出有许多单元(units),像该问题的多个actions一样。
(2). 该算法结合一个 replay-memory来收集不同的经验和在长期运行中进行学习。
(3). 为了更新model,该算法从replay-memory uniformly at random的选择transitions,来破坏状态之间的短期关系。这使得算法更加稳定并且阻止了参数的不收敛。
在学习了 action-value function Q(s, a)之后,agent采用的策略就是选择拥有最大预测值的 action a。

1. Q-learning for Object Localization
网络结构如上图所示,输入图像是:224*224,经过5个卷基层,提取fc6层的feature,然后训练 Deep Q-Network,最终输出9个actions, 这9个action 就是 对应 fc 的9个输出。
2. Training Localization Agents


另外,为了更好的理解Deep Q-Network,还是抽空看一下这篇文章" Human-level control through deep reinforcement learning"。
The link is here: http://gnusha.org/~nmz787/pdf/Human-level_control_through_deep_reinforcement_learning.pdf
大家有什么疑惑,欢迎一起讨论学习!