Datawhale 零基础入门CV赛事-街景字符识别-Task1 赛题理解
1 赛题理解
- 赛题名称:零基础入门CV之街道字符识别
- 赛题目标:通过这道赛题可以引导大家走入计算机视觉的世界,主要针对竞赛选手上手视觉赛题,提高对数据建模能力。
- 赛题任务:赛题以计算机视觉中字符识别为背景,要求选手预测街道字符编码,这是一个典型的字符识别问题。
为了简化赛题难度,赛题数据采用公开数据集SVHN,因此大家可以选择很多相应的paper作为思路参考。
1.1 学习目标
- 理解赛题背景和赛题数据
- 完成赛题报名和数据下载,理解赛题的解题思路
训练集数据包括3W张照片,验证集数据包括1W张照片,每张照片包括颜色图像和对应的编码类别和具体位置;为了保证比赛的公平性,测试集A包括4W张照片,测试集B包括4W张照片。
理解数据标签:

首先是看一张数据集中的图:
对于训练数据每张图片将给出对于的编码标签,和具体的字符框的位置(训练集、验证集都给出字符位置),可用于模型训练:
| Field | Description |
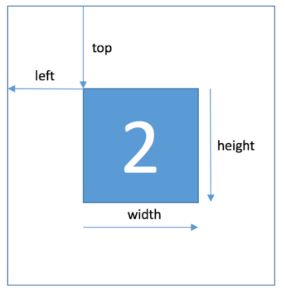
|---|---|
| top | 左上角坐标X |
| height | 字符高度 |
| left | 左上角坐标Y |
| width | 字符宽度 |
| label | 字符编码 |
top表示的是打标签图中数字的左上角坐标X,height表示图中的数字的高度,left是图中数字的左上角坐标Y,width表示数字的宽度,label就是图中数字的标号
在比赛数据(训练集和验证集)中,同一张图片中可能包括一个或者多个字符,因此在比赛数据的JSON标注中,会有两个字符的边框信息:

在json文件里面的标签形式就是这样的:
"000000.png": {"height": [219, 219], "label": [1, 9], "left": [246, 323], "top": [77, 81], "width": [81, 96]}
评测标准
评价标准为准确率,选手提交结果与实际图片的编码进行对比,以编码整体识别准确率为评价指标,结果越大越好,具体计算公式如下:
Score = 编码识别正确的数量/测试集图片数量
读取数据
import json
train_json = json.load(open('../input/train.json'))
# 数据标注处理
def parse_json(d):
arr = np.array([
d['top'], d['height'], d['left'], d['width'], d['label']
])
arr = arr.astype(int) #将数组的形式转换为Int类型
return arr
img = cv2.imread('../input/train/000000.png')
arr = parse_json(train_json['000000.png'])
plt.figure(figsize=(10, 10))
plt.subplot(1, arr.shape[1]+1, 1)
plt.imshow(img)
plt.xticks([]); plt.yticks([])
for idx in range(arr.shape[1]):
plt.subplot(1, arr.shape[1]+1, idx+2) #在matplotlib下,一个Figure对象可以包含多个子图(Axes),可以使用subplot()快速绘制,位置是由三个整型数值构成,第一个代表行数,第二个代表列数,第三个代表索引位置
plt.imshow(img[arr[0, idx]:arr[0, idx]+arr[1, idx],arr[2, idx]:arr[2, idx]+arr[3, idx]]) #显示图像和格式,有些图里有两个字符,有些有三个,让每个字符单独显示
plt.title(arr[4, idx])
plt.xticks([]); plt.yticks([])
解题思路:
官方的解题思路为将不定长的数字,通过数据增扩,转化为定长字符识别,在赛题数据集中大部分图像中字符个数为2-4个,最多的字符 个数为6个。因此可以对于所有的图像都抽象为6个字符的识别问题,字符23填充为23XXXX,字符231填充为231XXX。

还有一种是不定长字符识别,比较典型的有CRNN字符识别模型。在本次赛题中给定的图像数据都比较规整,可以视为一个单词或者一个句子。本人小白,看不太懂
学习总结:
学习如何给图片打标签,打标签的意义就是为了让计算机更容易识别和理解图中的东西,此次的标签是提供好的,不用自己再处理