Mac下CentOS虚拟机装Hadoop集群、zookeeper集群、HBase集群
开工前的资源准备
1、电脑安装VMware Fusion,并安装centos 7
2、下载需要的工具包
jdk-8u161-linux-x64.tar.gz
hadoop-2.7.4.tar.gz
zookeeper-3.4.9.tar.gz
hbase-1.2.6-bin.tar.gz
一、虚拟机配置联网
3台虚拟机都安装完毕处于原始状态,这个时候虚拟机还是处于不可联网的状态,需要配置虚拟机处于可以联网,配置方式如下:
设置 -> 网络适配器 -> 与我的mac共享(NAT模式)

设置完之后,打开mac的终端,输入命令:
cat /Library/Preferences/VMware\ Fusion/vmnet8/nat.conf这个时候在终端窗口中会显示出一大串。我们需要的是其中最前面的一块:
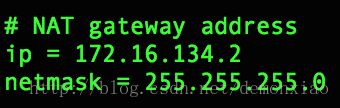
在这边,记住这个IP地址,因为后续配置虚拟机上网都的时候会用到。
接着到Mac的系统偏好设置中,打开网络,点击右下角的高级按钮,在新出现的对话框中,选择DNS,然后记下这个DNS地址。

接下来到虚拟机中,输入一下命令:
vi /etc/sysconfig/network-scripts/ifcfg-eno16777736打开网卡配置,默认网卡配置如截图显示:
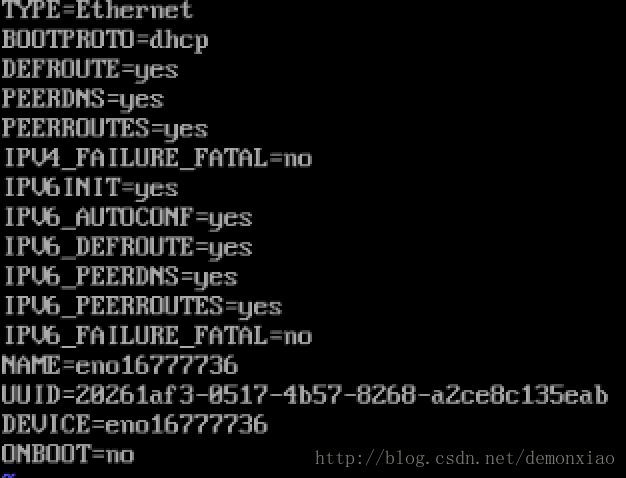
这个时候,我们应该改的东西有:
BOOTPROTO=static
ONBOOT=yes在后面加上:
IPADDR=172.16.134.252
NETMASH=255.255.255.0
PREFIX=24
IPV6_PRIVACY=no
DNS1=172.16.52.184
GATEWAY=172.16.134.2其中GATEWAY就是刚刚我们查询到的IP,DNS1则是查询到的DNS地址。
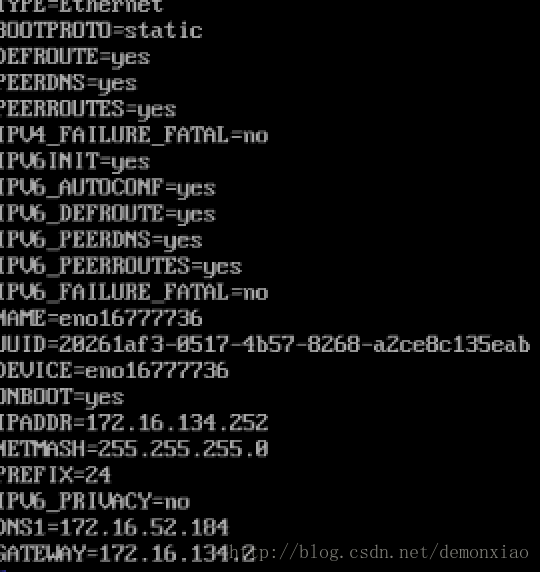
保存完之后,输入下列命令重启网卡:
service network restart重启之后ping一下看是否能通:
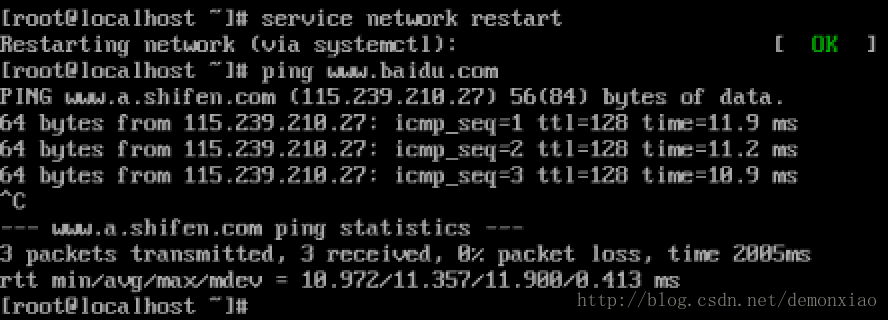
这个时候网络已经能连接通了,在剩下的两台虚拟机中也是做相同的配置。注意IP别搞混了。
二、新增配置用户
用root用户登录,然后创建一个登录名为hadoop的用户,并修改对应的密码:
useradd -m hadoop -s /bin/bash
passwd hadoop
完成之后。修改用户的对应权限:
visudo打开后直接输入 :98 可以跳转到对应的行数,在原有的root后面把hadoop用户的权限也加上:

保存退出即可,这个时候就可以直接su hadoop切换到hadoop用户了。(其他两台服务器也是同样的操作)
三、配置ssh免密登录
切换到hadoop用户后,输入下列命令生成公私钥:
ssh-keygen -t rsa这边会询问,直接三个回车就完成生成操作了。
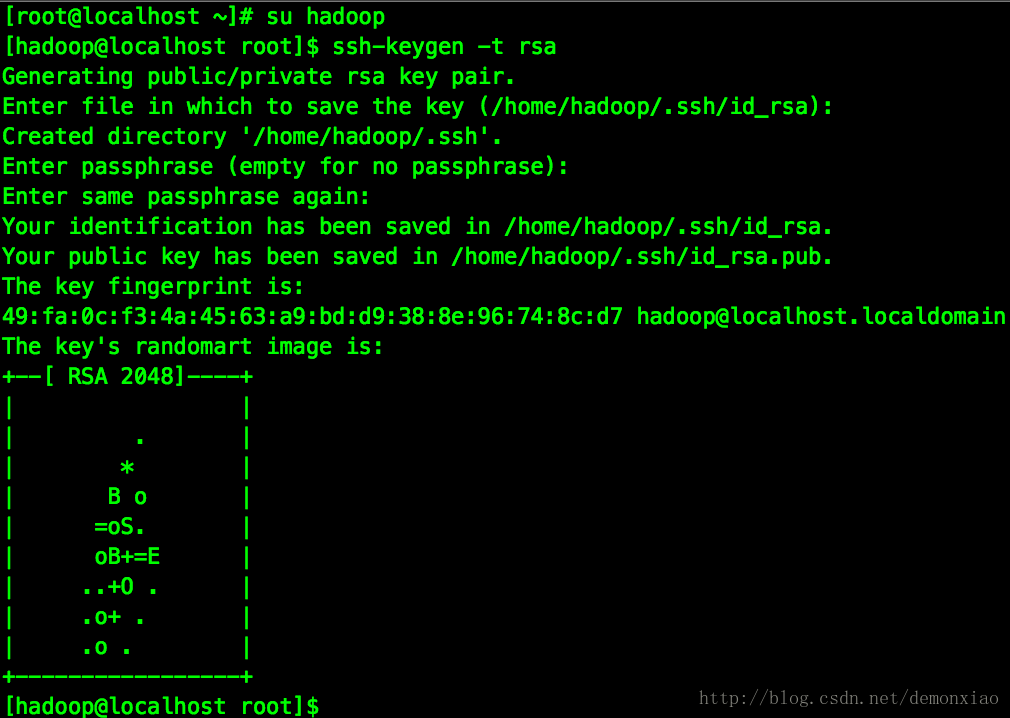
这个时候在 ~/.ssh/目录下就会生成对应的公私钥:
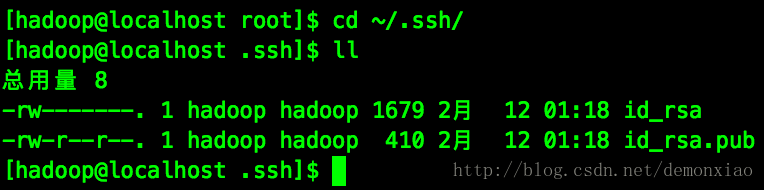
这个时候就可以把这边的公钥传到其他的机器上面,具体命令是:
ssh-copy-id [email protected] #这边输入想要免密登录机器的IP地址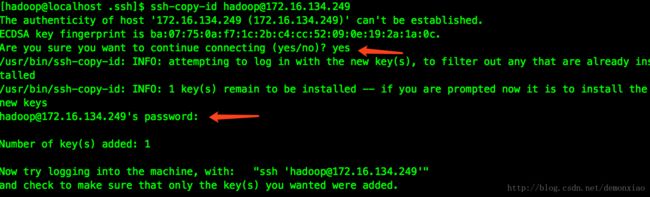
在提示是否输入yes的时候输入yes,接着提示输入密码的地方输入对应机器hadoop用户的密码回车即可。
这个时候我们试试直接ssh连接到对应的机器:
ssh [email protected]
这个时候就已经可以免密登录到对应的机器了。(另外的机器一样的配置)
四、配置Java环境
将一开始下载的包放在hadoop的用户目录下,然后进行解压。
tar -xvf jdk-8u161-linux-x64.tar.gz
解压完毕后用su切换到root把解压出来的文件夹移动到/usr/local/java/目录下:
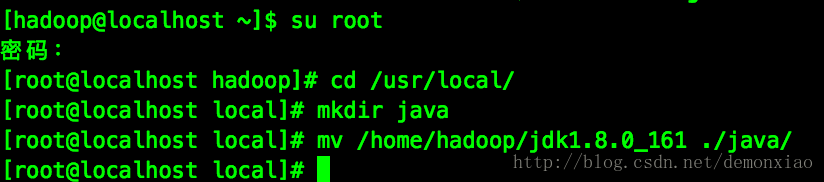
这时候的jdk地址为:/usr/local/java/jdk1.8.0_161。然后配置Java的环境变量。
vim /etc/profile打开配置文件后,在文件最后加入如下配置:
export JAVA_HOME=/usr/local/java/jdk1.8.0_161
export CLASSPATH=.:${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar
export PATH=$PATH:${JAVA_HOME}/bin保存退出并使用使用命令重新加载一次配置文件:
source /etc/profile这个时候就可以使用exit退出root用户,切换会hadoop用户后记得重新source一次,这个时候就可以使用java -version和echo $JAVA_HOME来查看环境是否生效了:
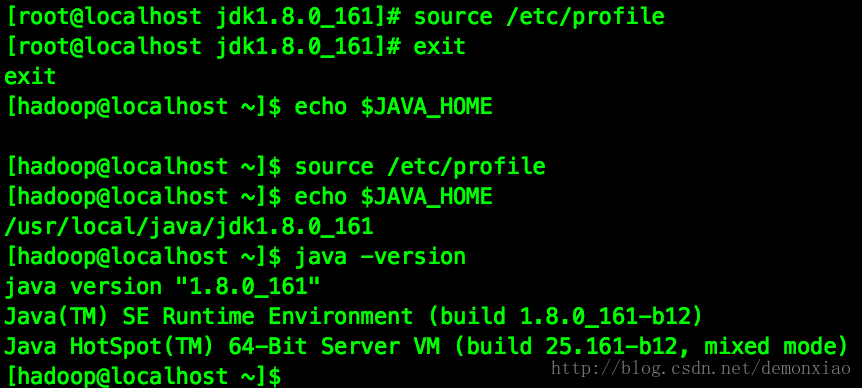
接着修改 ~/.bashrc的配置文件一样加入Java的环境配置:
保存后重新source一下这个配置文件即可。
五、安装Hadoop环境
上传文章一开始下载的Hadoop文件到用户文件夹下并解压文件:
tar -xvf hadoop-2.7.4.tar.gz解压后为了方便把文件夹改名成hadoop,同刚刚安装Java环境一样把Hadoop的目录用root权限移动到/usr/local/下:
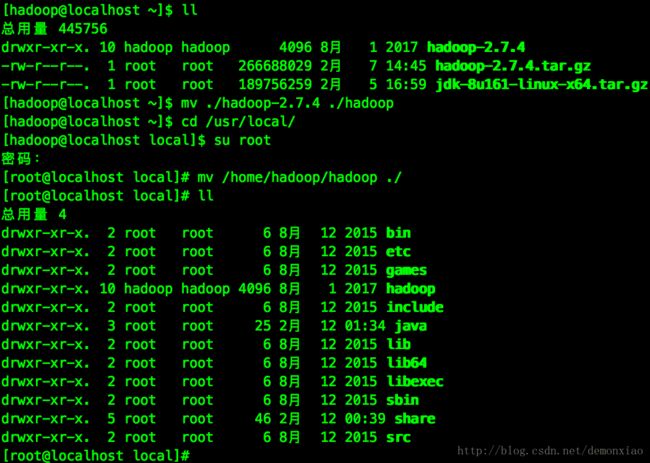
Hadoop解压完成之后可以直接用Hadoop的bin目录下的hadoop命令。
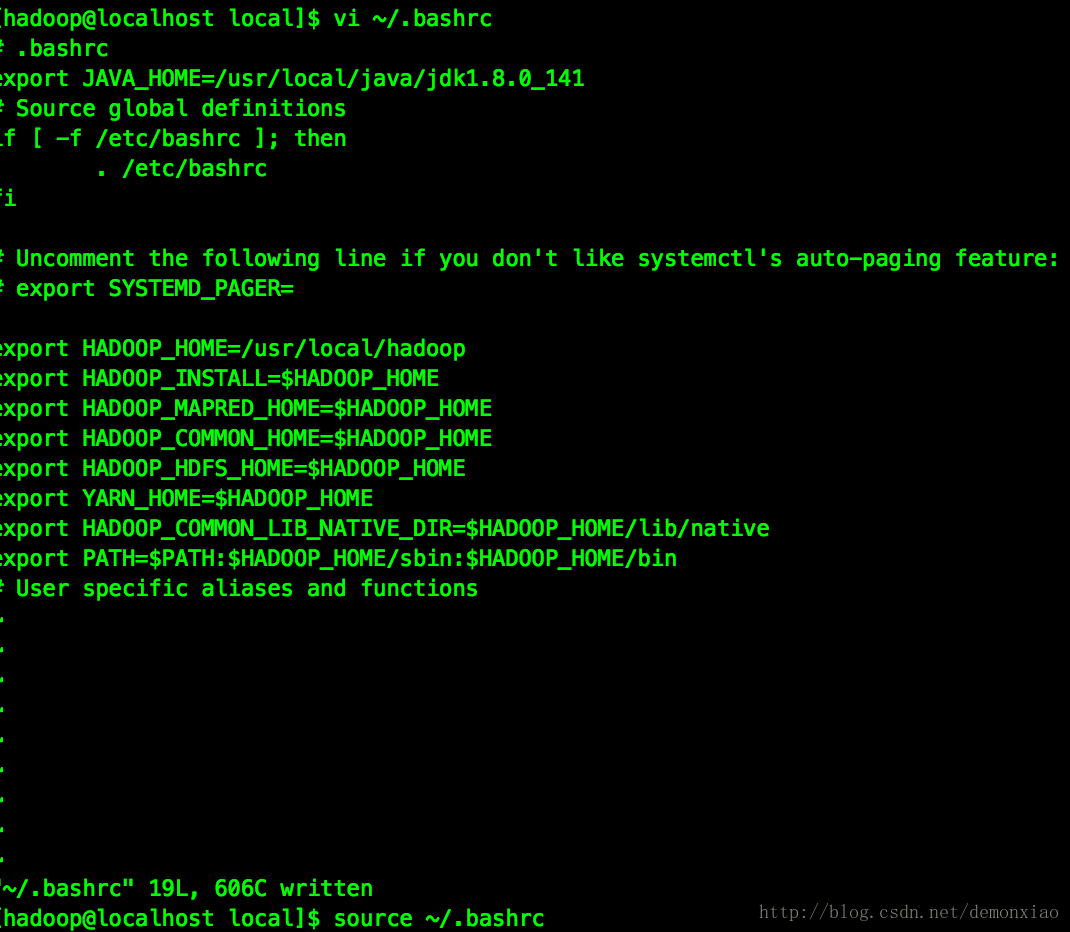
 接下来为了方便使用,我们要配置Hadoop的环境变量,打开 ~/.bashrc 然后在文件最后输入下面的配置:
接下来为了方便使用,我们要配置Hadoop的环境变量,打开 ~/.bashrc 然后在文件最后输入下面的配置:
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin保存退出后,重新source一下该配置文件:
然后再随意路径下只用Hadoop命令测试一下:

成功。(另外两台虚拟机也是一样的操作)
六、Hadoop集群配置
首先,切换到root用户下把三台配置完成的虚拟机重新修改一下机器名称:
vi /etc/hostname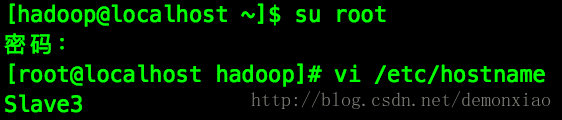
其中一台机器改成Master,其他的机器可以改成Slave1、Slave2、Slave3... 等等用于区分机器。
接着修改对应的hosts配置文件,用于做机器名称和ip的映射关系:
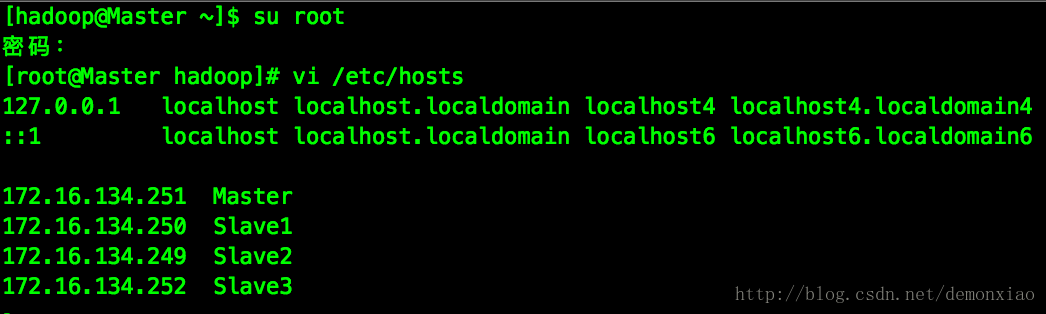
这个时候Master机器必须可以免密登录所有的Slave机器、并且要关掉所有虚拟机的防火墙。CentOs 7的防火墙关闭方式如下:
systemctl stop firewalld.service #停止firewall
systemctl disable firewalld.service #禁止firewall开机启动
firewall-cmd --state #查看默认防火墙状态
提示 not running则表示防火墙已经关闭。
然后把操作界面转到作为Master的机器上,把路径切换到 /usr/local/hadoop/etc/hadoop 我们要修改下面的几个文件
1、修改slaves,删除原有内容,把配置的节点名称加入到文件中:
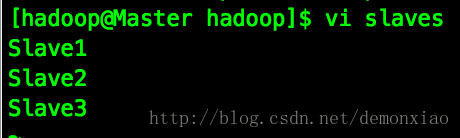
有几个加几个,两个就只写Slave1、Slave2,N个就一直写到SlaveN。
2、修改core-site.xml文件。加入如下配置:
fs.defaultFS
hdfs://Master:9000
hadoop.tmp.dir
file:/usr/local/hadoop/tmp
Abase for other temporary directories.
3、修改hdfs-site.xml文件,加入如下配置:
dfs.namenode.secondary.http-address
Master:50090
dfs.replication
2
dfs.namenode.name.dir
file:/usr/local/hadoop/tmp/dfs/name
dfs.datanode.data.dir
file:/usr/local/hadoop/tmp/dfs/data
4、修改mapred-site.xml文件,得先复制一下mapred-site.xml.template,然后改个名称,配置如下:
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
Master:10020
mapreduce.jobhistory.webapp.address
Master:19888
5、修改yarn-site.xml,配置如下:
yarn.resourcemanager.hostname
Master
yarn.nodemanager.aux-services
mapreduce_shuffle
这些文件修改完之后。把改目录复制到各个节点中。覆盖原有的配置文件。
scp -r ./hadoop hadoop@Slave1:/usr/local/hadoop/etc/
在Master节点上执行以下命令:
hdfs namenode -format #首次执行的时候才需要在Slave节点执行以下命令:
hdfs datanode -format #首次执行的时候才需要最后启动在Master端进入到/usr/local/hadoop/sbin模流下启动Hadoop环境:
./start-all.sh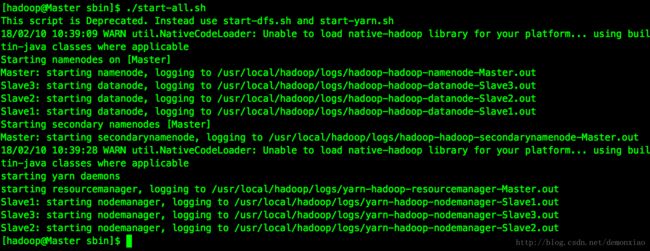
看到这个界面就表示启动完毕。
在浏览器中访问管理器,地址有如下两个:
http://172.16.134.251:50070/
http://172.16.134.251:8088/

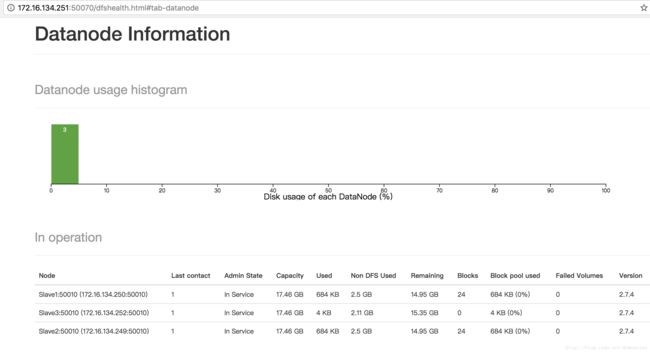
图中会显示目前处于活动状态的节点。
七、zookeeper集群
把文章一开始下载的zookeeper-3.4.9.tar.gz上传到各服务器中,然后解压。
tar -xvf zookeeper-3.4.9.tar.gz 解压完成之后的文件夹用root权限移动至/usr/local/目录下
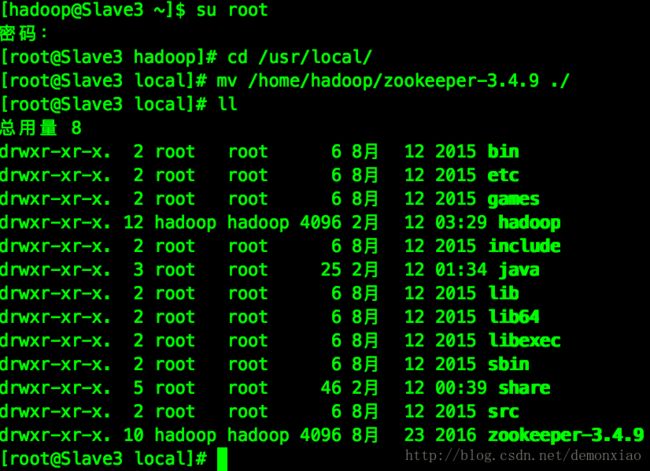
完成之后。进入到zookeeper目录下的conf文件夹中,这时候我们要复制一份zoo_sample.cfg文件并改名成zoo.cfg,然后在该文件中修改配置:
cp zoo_sample.cfg zoo.cfg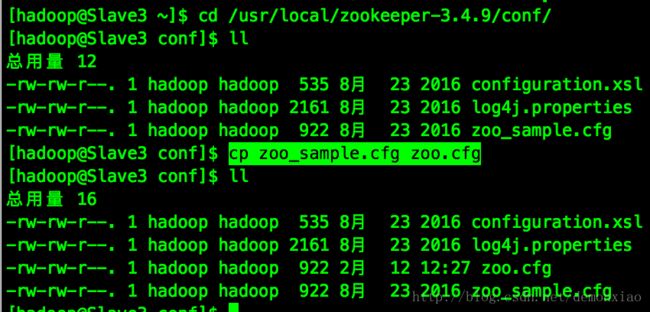
接下来用vi命令打开zoo.cfg文件,然后用 :12 切换到第十二行,把这边的参数改成如下两项:
dataDir=/usr/local/zookeeper-3.4.9/data
dataLogDir=/usr/local/zookeeper-3.4.9/logs接着在文件的最后位置。加入集群里服务器的地址信息:
server.1=Master:2888:3888
server.2=Slave1:2888:3888
server.3=Slave2:2888:3888
server.4=Slave3:2888:3888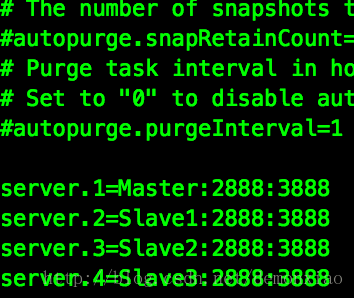
保存退出即可,在集群环境中,所有的zookeeper的zoo.cfg均得是同一套配置。
配置完成之后,我们在zookeeper的目录下,新建两个文件夹data、logs。新建完成之后进入到data文件夹中。使用vi命令创建一个myid的文件。并在里面赋值对应的id。 比如上面配置Slave3是第4节点,则在文件中写入4即可。
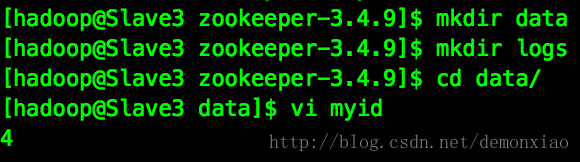
接下来进入到zookeeper的bin目录下。然后使用下列命令启动zookeeper:
./zkServer.sh start
把其他节点上的zookeeper也全部启动起来后检查一下状态是否正常。
./zkServer.sh status

会出现两种角色,leader和follower。然后就算启动完成了。尝试的连接一下zookeeper集群:
./zkCli.sh -server Master:2181,Slave1:2181,Slave2:2181,Slave3:2181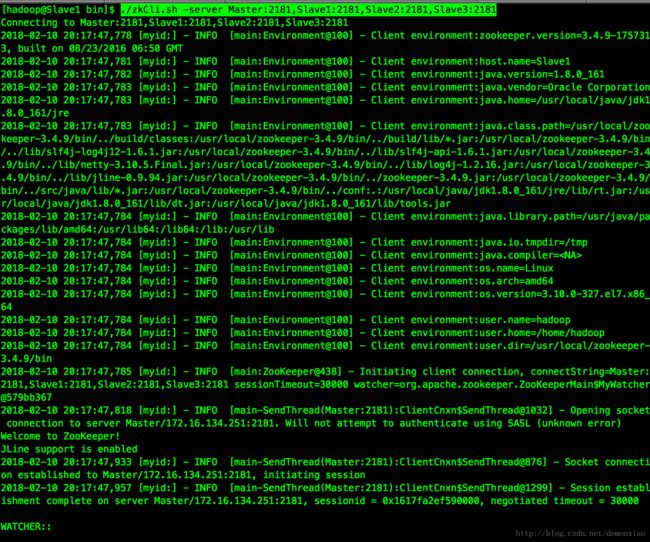
发现已经成功了。zookeeper配置就到这了。
八、HBase集群安装
老样子,把文章一开始的HBASE下载下来后,传到服务器中进行解压操作:
tar -xvf hbase-1.2.6-bin.tar.gz
接着跟着上面的方式,同样的把hbase的文件夹移动到/usr/local/目录下:
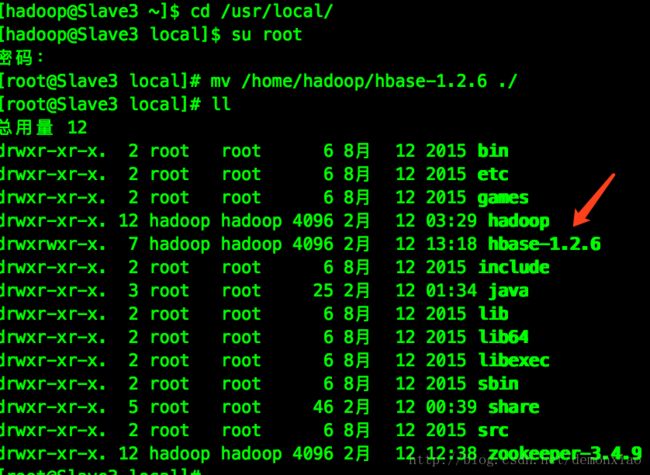
接着切换到root权限下配置环境变量:
vi /etc/profile在文件的最后加入下面的配置后保存退出:
export HBASE_HOME=/usr/local/hbase-1.2.6
export PATH=$HBASE_HOME/bin:$PATH
退出root权限。然后source下修改后的文件即可。接着切换到/usr/local/hbase-1.2.6/conf的路径下。然后用vi命令打开hbase-env.sh文件,接着使用:27切换到第27行:

把这边的注释去掉,并且后面的值改成jdk所在的目录:

然后使用:128切换到第128行,将下列配置项改成false,不用hbase自带的zookeeper:

打开hbase-site.xml,加入如下的配置:
hbase.rootdir
hdfs://Master:9000/opt/hbase/hbase_db
hbase.cluster.distributed
true
hbase.zookeeper.quorum
Master,Slave1,Slave2,Slave3
hbase.zookeeper.property.dataDir
/usr/local/zookeeper-3.4.9

修改regionservers文件,加入配置文件中写的节点:
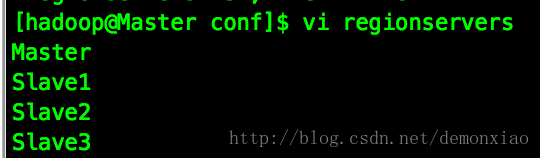
然后通过scp命令把配置文件复制到各个节点中:
cd /usr/local/hbase-1.2.6
scp -r ./conf hadoop@Slave1:/usr/local/hbase-1.2.6/
scp -r ./conf hadoop@Slave2:/usr/local/hbase-1.2.6/
scp -r ./conf hadoop@Slave3:/usr/local/hbase-1.2.6/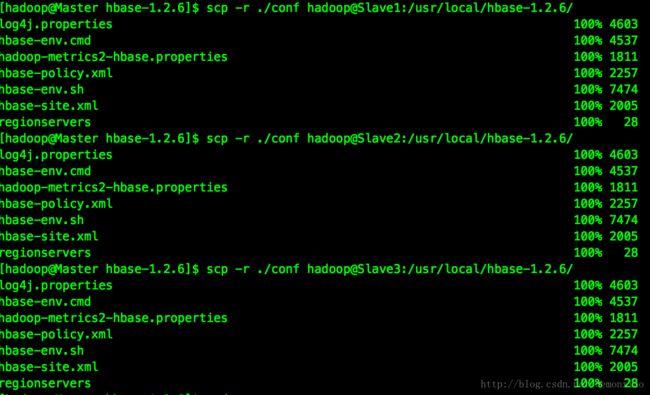
后面就是。切换到hbase目录下的bin目录里面,然后通过启动文件启动hbase:
./start-hbase.sh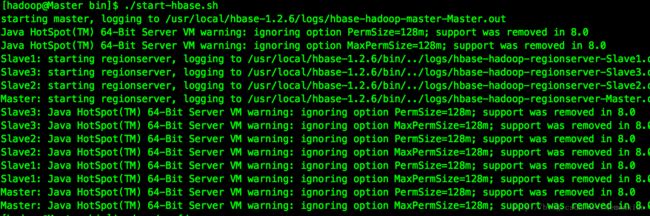
启动完毕,使用jps命令查一下:
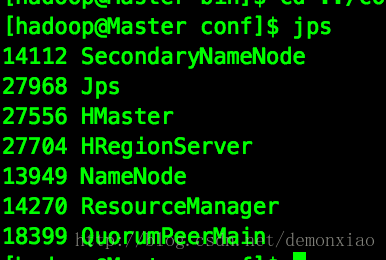
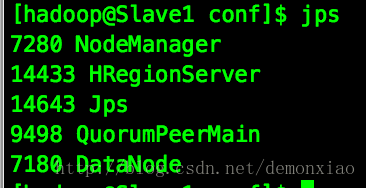
在Master节点中,HMaster是Hbase的进程,在Slave节点中HRegionServer是Hbase的进程。表示启动完成,然后访问下,管理界面出来了:
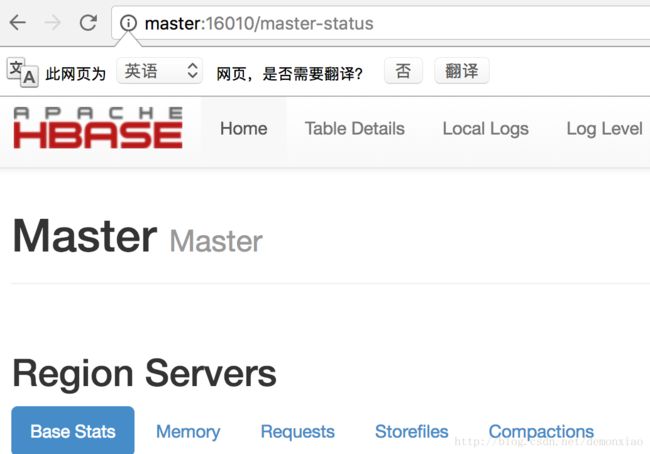
完毕……