什么是神经网络
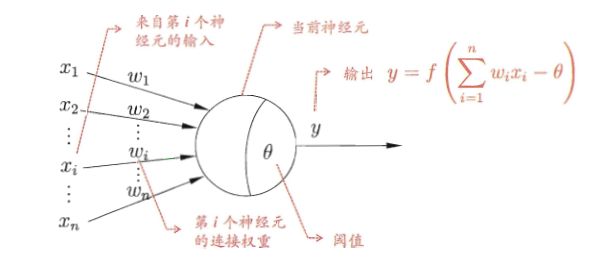
M-P神经元模型是一直沿用至今的神经元模型,神经元接收到来自n个其他神经元传递过来的输入信号,这些输入信号通过带权重的连接进行传递,神经元接收到的总输入将与神经元的阈值进行比较,然后通过“激活函数”处理以产生神经元的输出。
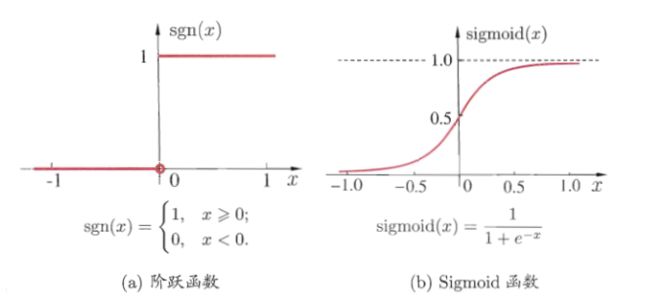
理想中的激活函数是阶跃函数,它将输入值映射为输出值“0”或“1”,显然“1”对应于神经元兴奋,“0”对应于神经元抑制。然而,阶跃函数具有不连续性、不光滑等不太好的性质,因此实际常用Sigmoid函数作为激活函数。Sigmoid把可能在较大范围内变化的输入值挤压到(0,1)输出值的范围内,因此有时也称为“挤压函数”。
把许多个这样的神经元按一定的层次结构连接起来,就得到了神经网络。
误差逆传播算法
误差逆传播(error BackPropagation,简称BP)算法是迄今最成功的神经网络学习算法。现实任务中使用神经网络时,大多是在使用BP算法进行训练。通常说“BP网络”时,一般是指用BP算法训练的多层前馈神经网络。
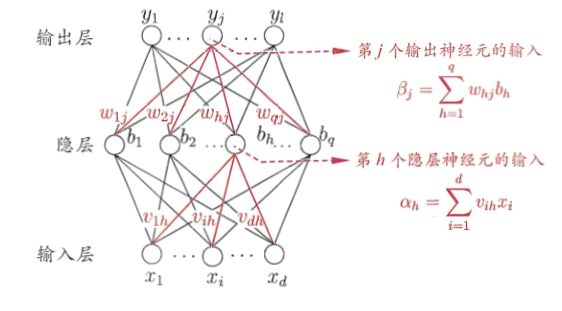



参数说明:

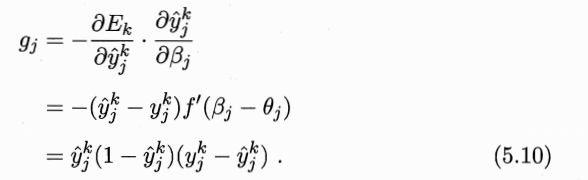


下图给出了BP算法的工作流程。对每个训练样例,BP算法执行以下操作:先将输入示例提供给输入层神经元,然后逐层将信号前传,知道产生输出层的结果;然后计算输出层的误差(第4-5行),再将误差逆传播至隐层神经元(第6行),最后根据隐层神经元的误差来对连接权和阈值进行调整(第7行)。该迭代过程循环进行,直到达到某些停止条件为止,例如训练误差已达到一个很小的值。

需注意的是,BP算法的目标是要最小化训练集D上的累积误差
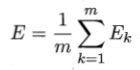
但上图的更新规则是基于单个的Ek推导而得。如果类似地推导出基于累积误差最小化的更新规则,就得到了累积误差逆传播算法。累积BP算法和标准BP算法都很常用。一般来说,标准BP算法每次更新只针对单个样例,参数更新的非常频繁,而且对不同样例更新的效果可能出现“抵消”现象。因此,为了达到同样的累积误差极小点,标准BP算法往往需进行更多次迭代。累积BP算法直接针对累积误差最小化,它在读取整个训练集D一遍后才对参数进行更新,其参数更新的频率低得多。但在很多任务中,累积误差下降到一定程度之后,进一步下降会非常缓慢,这时标准BP往往会更快获得较好的解,尤其是在训练集D非常大时更明显。
由于其强大的表示能力,BP神经网络经常遭遇过拟合,其训练误差持续降低,但测试误差却可能上升。有两种策略常用来缓解BP网络的过拟合。第一种策略是“早停”:将数据集分成训练集和测试集,训练集用来计算梯度、更新连接权和阈值,验证集用来估计误差,若训练集误差降低但验证集误差升高,则停止训练,同时返回具有最小验证集误差的连接权和阈值。第二种策略是“正则化”,其基本思想是在误差目标函数中增加一个用于描述网络复杂度的部分。
代码部分
数据来自西瓜书P84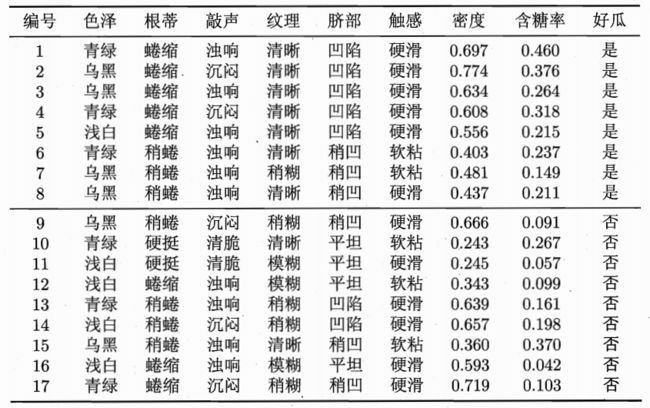
读取数据
import pandas as pd
import numpy as np
dataset = pd.read_csv('watermelon_3.csv', delimiter=",")
数据预处理
# 处理数据集
attributeMap = {}
attributeMap['浅白'] = 0
attributeMap['青绿'] = 0.5
attributeMap['乌黑'] = 1
attributeMap['蜷缩'] = 0
attributeMap['稍蜷'] = 0.5
attributeMap['硬挺'] = 1
attributeMap['沉闷'] = 0
attributeMap['浊响'] = 0.5
attributeMap['清脆'] = 1
attributeMap['模糊'] = 0
attributeMap['稍糊'] = 0.5
attributeMap['清晰'] = 1
attributeMap['凹陷'] = 0
attributeMap['稍凹'] = 0.5
attributeMap['平坦'] = 1
attributeMap['硬滑'] = 0
attributeMap['软粘'] = 1
attributeMap['否'] = 0
attributeMap['是'] = 1
del dataset['编号']
dataset = np.array(dataset)
m, n = np.shape(dataset)
for i in range(m):
for j in range(n):
if dataset[i, j] in attributeMap:
dataset[i, j] = attributeMap[dataset[i, j]]
dataset[i, j] = round(dataset[i, j], 3)
trueY = dataset[:, n-1]
X = dataset[:, :n-1]
m, n = np.shape(X)
初始化参数
# P101,初始化参数
import random
d = n # 输入向量的维数
l = 1 # 输出向量的维数
q = d+1 # 隐层节点的数量
theta = [random.random() for i in range(l)] # 输出神经元的阈值
gamma = [random.random() for i in range(q)] # 隐层神经元的阈值
# v size= d*q .输入和隐层神经元之间的连接权重
v = [[random.random() for i in range(q)] for j in range(d)]
# w size= q*l .隐藏和输出神经元之间的连接权重
w = [[random.random() for i in range(l)] for j in range(q)]
eta = 0.2 # 学习率,控制每一轮迭代的步长
maxIter = 5000 # 最大训练次数
sigmoid函数
import math
def sigmoid(iX,dimension): # iX is a matrix with a dimension
if dimension == 1:
for i in range(len(iX)):
iX[i] = 1 / (1 + math.exp(-iX[i]))
else:
for i in range(len(iX)):
iX[i] = sigmoid(iX[i], dimension-1)
return iX
标准的误差逆传播
# 标准BP
while(maxIter > 0):
maxIter -= 1
sumE = 0
for i in range(m):
alpha = np.dot(X[i], v) # p101 line 2 from bottom, shape=1*q
b = sigmoid(alpha-gamma, 1) # b=f(alpha-gamma), shape=1*q
beta = np.dot(b, w) # shape=(1*q)*(q*l)=1*l
predictY = sigmoid(beta-theta, 1) # shape=1*l ,p102--5.3
E = sum((predictY-trueY[i])*(predictY-trueY[i]))/2 # 5.4
sumE += E # 5.16
# p104
g = predictY*(1-predictY)*(trueY[i]-predictY) # shape=1*l p103--5.10
e = b*(1-b)*((np.dot(w, g.T)).T) # shape=1*q , p104--5.15
w += eta*np.dot(b.reshape((q, 1)), g.reshape((1, l))) # 5.11
theta -= eta*g # 5.12
v += eta*np.dot(X[i].reshape((d, 1)), e.reshape((1, q))) # 5.13
gamma -= eta*e # 5.14
# print(sumE)
累积的误差逆传播
# #累积 BP
# trueY=trueY.reshape((m,l))
# while(maxIter>0):
# maxIter-=1
# sumE=0
# alpha = np.dot(X, v)#p101 line 2 from bottom, shape=m*q
# b = sigmoid(alpha - gamma,2) # b=f(alpha-gamma), shape=m*q
# beta = np.dot(b, w) # shape=(m*q)*(q*l)=m*l
# predictY = sigmoid(beta - theta,2) # shape=m*l ,p102--5.3
#
# E = sum(sum((predictY - trueY) * (predictY - trueY))) / 2 # 5.4
# # print(round(E,5))
# g = predictY * (1 - predictY) * (trueY - predictY) # shape=m*l p103--5.10
# e = b * (1 - b) * ((np.dot(w, g.T)).T) # shape=m*q , p104--5.15
# w += eta * np.dot(b.T, g) # 5.11 shape (q*l)=(q*m) * (m*l)
# theta -= eta * g # 5.12
# v += eta * np.dot(X.T, e) # 5.13 (d,q)=(d,m)*(m,q)
# gamma -= eta * e # 5.14
预测
def predict(iX):
alpha = np.dot(iX, v) # p101 line 2 from bottom, shape=m*q
b = sigmoid(alpha-gamma, 2) # b=f(alpha-gamma), shape=m*q
beta = np.dot(b, w) # shape=(m*q)*(q*l)=m*l
predictY = sigmoid(beta - theta, 2) # shape=m*l ,p102--5.3
return predictY
print(predict(X))
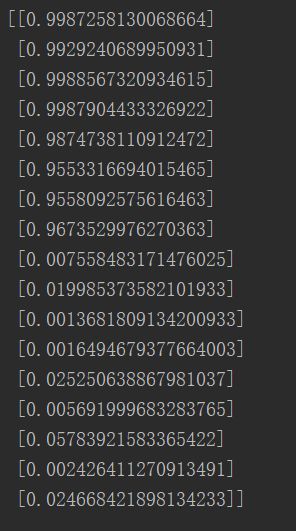
代码以及数据集可以到我码云下载