RCFile在平台的应用场景中多数用于存储需要“长期留存”的数据文件,在我们的实践过程中,RCFile的数据压缩比通常可以达到8 : 1或者10 : 1,特别适用于存储用户通过Hive(MapReduce)分析的结果。目前平台的计算引擎正逐步由Hadoop MapReduce迁移至Spark,存储方面我们依然想利用RCFile的优势,但是具体实践中遇到那么几个“坑”。
数据分析师使用PySpark构建Spark分析程序,源数据是按行存储的文本文件(可能有压缩),结果数据为Python list,list的元素类型为tuple,而tuple的元素类型为unicode(Python2,为了保持大家对数据认知的一致性,源数据是文本,我们要求用户的处理结果也为文本),可以看出list实际可以理解为一张表(Table),list的元素tuple为行(Row),tuple的元素为列(Column),因此能够很好的利用RCFile的列式存储特性。
RCFile扩展自Hadoop InputFormat、OutputFormat、Writable:
org.apache.hadoop.hive.ql.io.RCFileInputFormat
org.apache.hadoop.hive.ql.io.RCFileOutputFormat
org.apache.hadoop.hive.serde2.columnar.BytesRefArrayWritable
注意:RCFile的使用需要依赖于Hive的Jar。
使用RCFileOutputFormat时我们需要处理tuple => BytesRefArrayWritable(Object[] => BytesRefArrayWritable)的数据类型转换,使用RCFileInputFormat时我们需要处理BytesRefArrayWritable => tuple(BytesRefArrayWritable => Object[])的数据类型转换,也就是说我们需要扩展两个Converter:
ObjectArrayToBytesRefArrayWritableConverter:用于Object[] => BytesRefArrayWritable的数据类型转换;
BytesRefArrayWritableToObjectArrayConverter:用于BytesRefArrayWritable => Object[]的数据类型转换;
注:有关PySpark Converter的相关原理可以参考 http://diptech.sinaapp.com/?p=125,在此我们只介绍具体的实现细节。
(1)ObjectArrayToBytesRefArrayWritableConverter;

convert的参数类型为Object[],返回值类型为BytesRefArrayWritable。
(2)BytesRefArrayWritableToObjectArrayConverter;

convert的参数类型为BytesRefArrayWritable,返回值类型为Object[]。
1. 模拟数据(用户分析结果),将其以RCFile的形式保存至HDFS;
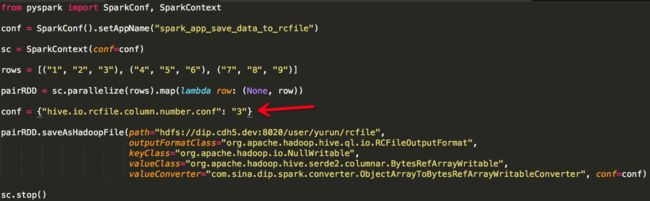
我们模拟的数据为三行三列,数据类型均为文本,需要注意的是RCFile在保存数据时需要通过Hadoop Configuration指定“列数”,否则会出现以下异常:

此外RCFileOutputFormat RecordWriter会丢弃“key”:

因此“key”可以是任意值,只要兼容Hadoop Writable即可,此处我们将“key”处理为None,并设置keyClass为org.apache.hadoop.io.NullWritable。
而且运行上述程序之前,还需要将com.sina.dip.spark.converter.ObjectArrayToBytesRefArrayWritableConverter编译打包为独立的Jar:rcfile.jar,运行命令如下:
spark-submit --jars rcfile.jar 1.5.1/examples/app/spark_app_save_data_to_rcfile.py
出乎意料,异常信息出现:

引发异常的代码并不是我们自定义扩展的ObjectArrayToBytesRefArrayWritableConverter,而是RCFileOutputFormat,怎么可能,这不是官方提供的代码么?根据异常堆栈可知,RCFileOutputFormat第79行(不同版本的Hive可能代码行数不同)代码出现空指针异常:

该行可能引发空指针异常的唯一原因就是outputPath == null,而outputPath的值由方法getWorkOutputPath计算而得:

其中JobContext.TASK_OUTPUT_DIR的值为mapreduce.task.output.dir。
熟悉Hadoop的同学可能已经想到,方法getWorkOutputPath是用来计算Map或Reduce Task临时输出目录的,JobContext.TASK_OUTPUT_DIR属性也是以前缀“mapreduce”开头的,“
Spark运行时是不会为该属性设置值的”,所以outputPath == null,那么我们应该如何计算outputPath呢?
困惑之余,我们联想到当初调研Spark时是以文本为基础进行功能测试的,也就是说在Spark中使用TextInputFormat、TextOutputFormat是没有任何问题的,果断参考一下TextOutputFormat是如何实现的?
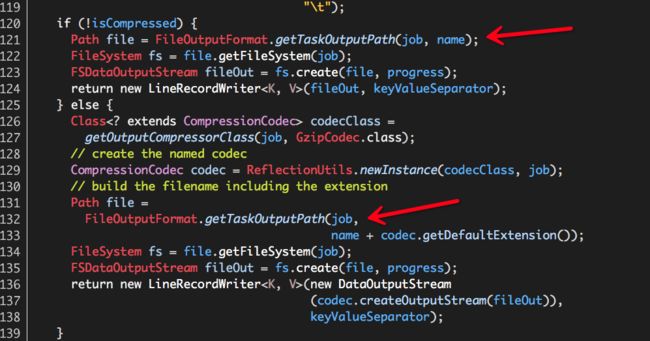
FileOutputFormat是一个基础类,这意味着我们可以重写RCFileOutputFormat getRecordWriter,使用FileOutputFormat.getTaskOutputPath替换getWorkOutputPath:
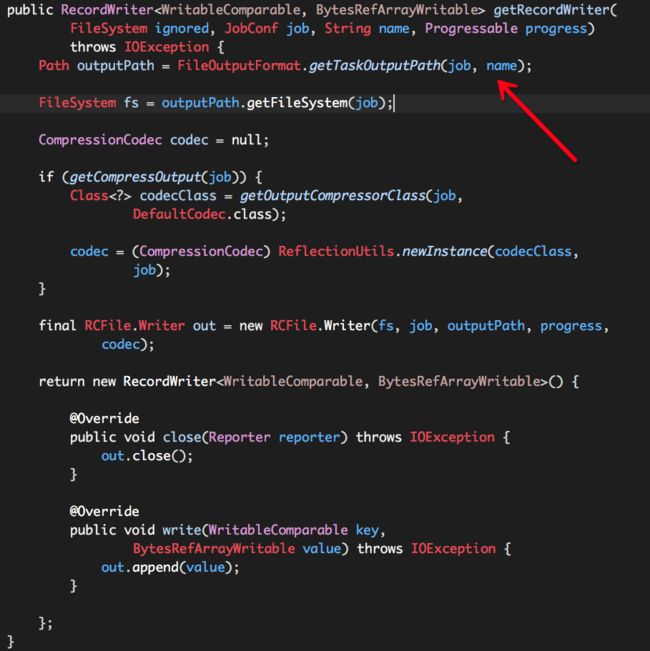
可以看出,重写后的getRecordWriter仅仅是改变了outputPath的计算方式,其它逻辑并没有改变,我们将重写后的类命名为com.sina.dip.spark.output.DipRCFileOutputFormat,并将其一并编译打包为独立的Jar:rcfile.jar。
重新修改Spark代码:

我们作出了两个地方的修改:
(1)parallelize numSlices:1,考虑到模拟的数据量比较小,为了便于查看结果,我们将“分区数”设置为1,这样最终仅有一个数据文件;
(2)outputFormatClass:com.sina.dip.spark.output.DipRCFileOutputFormat;
再次运行命令:
spark-submit --jars rcfile.jar 1.5.1/examples/app/spark_app_save_data_to_rcfile.py
程序执行结果之后,我们通过HDFS FS命令查看目录:hdfs://dip.dev.cdh5:8020/user/yurun/rcfile/:

数据文件已成功生成,为了确认写入的正确性,我们通过Hive RCFileCat命令查看文件:hdfs://dip.dev.cdh5:8020/user/yurun/rcfile/part-00000:

可见写入文件的数据与我们模拟的数据是一致的。
2. 读取上一步写入的数据;

运行上述程序之前,还需要将com.sina.dip.spark.converter.BytesRefArrayWritableToObjectArrayConverter编译打包为独立的Jar:rcfile.jar,运行命令如下:
spark-submit --jars rcfile.jar 1.5.1/examples/app/spark_app_read_data_from_rcfile.py
输出结果:
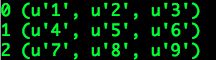
我们使用Hive原生的RCFileInputFormat,以及我们自己扩展的BytesRefArrayWritableToObjectArrayConverter正确完成了RCFile数据的读取,实际上pair[0]可以理解为“行数”(注意keyClass的设置),通常情况下没有实际意义,可以选择忽略。
综上所述,Spark(PySpark)使用RCFile的过程中会遇到三个“坑”:
(1)需要重写RCFileOutputFormat getRecordWriter;
(2)需要扩展Converter支持tuple(Object[]) => BytesRefArrayWritable的数据类型转换;
(3)需要扩展Converter支持BytesRefArrayWritable => tuple (Object[])的数据类型转换。