Hive on Spark踩坑记
本文是我搭建Hive on Spark的一些经历,包括踩的各种坑,记录一下
首先说一下本人为什么要搭建Hive on Spark呢?因为本人使用的是Hive 2.1.1,每次输入hive命令准备启动Hive客户端的时候,命令行都会输出这样的一段信息:
![]()
信息中明确的说明了Hive on MapReduce在Hive 2中是过时的,并且在Hive未来的版本中可能是不可用的。推荐我们使用其他的执行引擎,比如:Tez、Spark,或者让我们使用1.x版本。Hive 2中的具有很多诱人的新特性,而且性能上有很大的提升,所以使用Hive 2肯定是大势所趋啊,重点是Hive on MapReduce真的是很慢啊。这里呢,本人也是跟着潮流走,准备将Hive的执行引擎切换成Spark。为什么不是Tez呢?这里就涉及到Tez是什么了?不知道的可以参考(Apache Tez 是什么)这篇文章。我个人理解,Tez本质是就是一个升级版的MapReduce,速度上明显提升了,但是还是无法和Spark想提并论的。重要的是,现在是Spark的时代,火的不要不要的,当然跟着潮流走啊。但是Hive on Spark兴起没多久,没有Hive on Tez时间长,所以Hive on Spark的稳定性和兼容性没有Hive on Tez好,所以对速度没有很高要求的,还是可以考虑Hive on Tez的。好了,不废话,开始Hive on Spark之旅。
首先肯定要准备软件了,我刚开始搭建Hive on Spark的时候,准备的软件版本是Hive 2.1.1、Spark 2.1.1、Hadoop 2.7.3。那么搭建Hive on Spark,可以参考Hive官方文档。 写了很多,总结了一下主要是下面几点:
增加Hive配置
Hive on Spark配置参数不少,但是下面的是必须的:
<property>
<name>hive.execution.enginename>
<value>sparkvalue>
property>
<property>
<name>spark.mastername>
<value>yarnvalue>
property>
其中spark.master根据实际情况配置即可,如果是standalone模式,那么值就是spark master URL了。下面的参数是可选的,你可以直接在Hive命令行中设置,也可以直接配置到hive-site.xml文件中(在命令行配置的话是临时的,只对当前会话有用):
set spark.eventLog.enabled=true;
set spark.eventLog.dir=<Spark event log folder (must exist)>
set spark.executor.memory=512m;
set spark.serializer=org.apache.spark.serializer.KryoSerializer;
可选参数很多,不止上面列举的那些,感兴趣可以自己查考上面给出的官方文档连接。
增加Spark jar包
需要将Spark相关的jar包都拷贝到HIVE_HOME/lib目录下,在Spark 1.x中,只要拷贝SPARK_HOME/lib/spark-assembly-xxx.jar就可以了,但是Spark 2.x变了,没有这个包了,所以呢,我们就将SPARK_HOME/jars下面的所有以spark开头的包拷贝到HIVE_HOME/lib目录下即可:
spark-catalyst_2.11-2.1.1.jar
spark-core_2.11-2.1.1.jar
spark-graphx_2.11-2.1.1.jar
spark-hive_2.11-2.1.1.jar
spark-hive-thriftserver_2.11-2.1.1.jar
spark-launcher_2.11-2.1.1.jar
spark-mesos_2.11-2.1.1.jar
spark-mllib_2.11-2.1.1.jar
spark-mllib-local_2.11-2.1.1.jar
spark-network-common_2.11-2.1.1.jar
spark-network-shuffle_2.11-2.1.1.jar
spark-repl_2.11-2.1.1.jar
spark-sketch_2.11-2.1.1.jar
spark-sql_2.11-2.1.1.jar
spark-streaming_2.11-2.1.1.jar
spark-tags_2.11-2.1.1.jar
spark-unsafe_2.11-2.1.1.jar
spark-yarn_2.11-2.1.1.jar
还可以将Spark的jar包上传到HDFS上,然后在hive-site.xml进行如下的配置:
<property>
<name>spark.yarn.jarname>
<value>hdfs://xxxx:8020/spark-assembly.jarvalue>
property>
这是对Hive 2.2.0之前的版本,Hive 2.2.0开始的配置如下:
<property>
<name>spark.yarn.jarsname>
<value>hdfs://xxxx:8020/spark-jars/*value>
property>
为什么Hive 2.2.0开始变了呢?其实是有原因的,因为Hive 2.2.0之前,Hive on Spark是不支持Spark 2.x的。接下来的内容也会说到。
然后就可以启动hive了。启动的时候没有问题,但是当你执行一个hql语句的时候,可能会报下面的错:
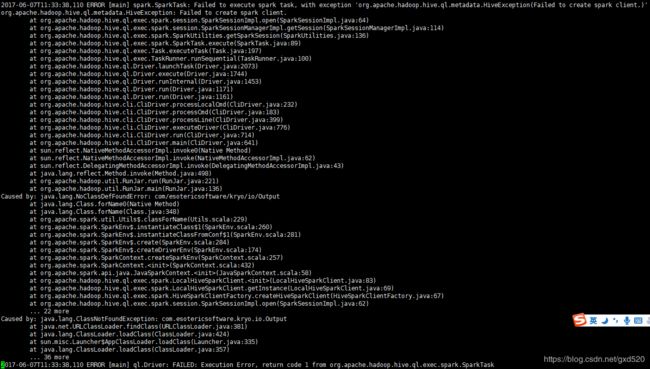
上面的错误的原因是与kryo有关的,其实是缺少了jar包,将SPARK_HOME/jars/objenesis-2.1.jar包拷贝到HIVE_HOME/lib下即可。
你满心欢喜的准备启动,执行hql命令,然而现实又给了你一记响亮的大嘴巴子。又报错了:
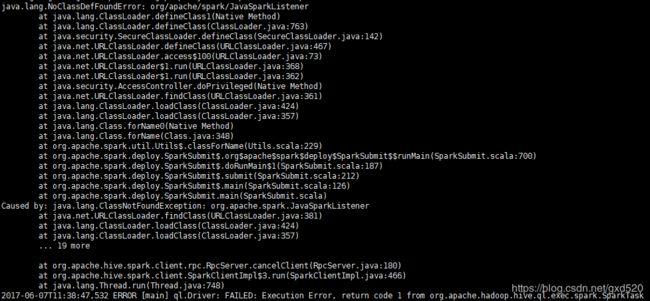
从上面的错误不难看出是缺少了org.apache.spark.JavaSparkListener这个类,可是这个类在哪呢?其实Spark 2.x的时候,已经把这个类给移除了,是不是很懵逼。这个其实也是Hive on Spark的一个bug,根本上说是Hive对Spark 2.x还没有完全支持,但是从Hive 2.2.0开始,修复了对Spark 2.x的支持。那我们该怎么办?两种解决方案,要么把Spark换成1.x,要么把Hive换成2.2.0及以上版本。可是Hive 2.2.0发布,本人本想从GitHub上下载Hive 2.2源码自己编译的,可是没成功,尴尬了。不得已将Spark换成1.6.3。换成Spark之后,需要从拷贝Spark的jar包。
OK,我们再一次满心欢喜的启动Hive并且执行HQL,又报错了:
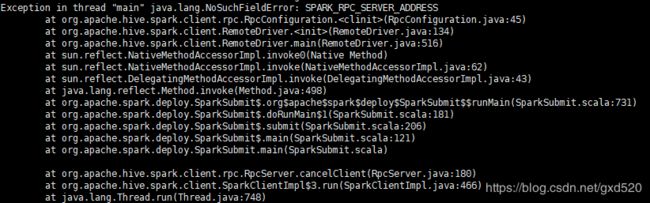
只要是报java.lang.NoSuchFieldError: SPARK_RPC_XXX之类的错,都是因为Spark包的问题,在使用Hive on Spark的时候,Spark包中不能够带有对Hive相关的支持,也就是说编译Spark的时候不能够带-Phive参数,我们这里使用的是官方已经编译好的Spark,里面是带有对hive的支持的,所以我们不得不自己从新编译Spark。编译参考官方文档。
这里我自己从新编译了一份Spark 1.6.3,从新又安装了一次。再次执行,可惜又报错了,报错如下:
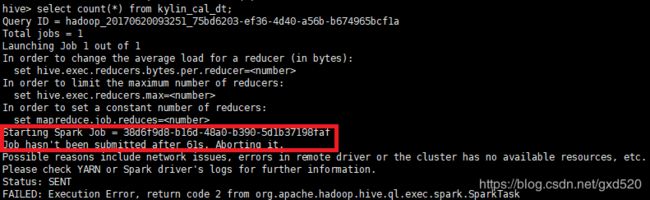
从图中可以看出Hive执行的HQL语句已经变成了Spark任务,不错,这是好的开端。那么从图中标红的报错信息并没有看出特别的原因,可以到/tmp/$USER/hive.log日志中查看具体的日志信息,下图是我截出来的报错信息:
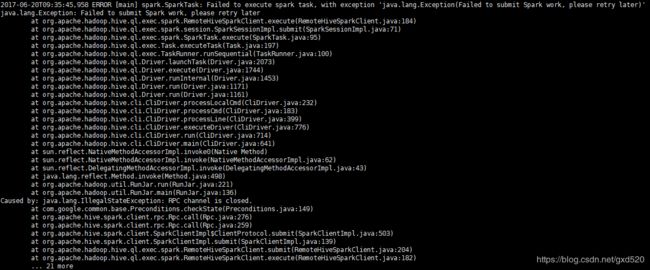
通过分析原因,不难分析出其实是超时了,超过60s任务没有提交成功就自动失败了,关闭了连接。解决方案是通过设置hive.spark.job.monitor.timeout参数,该参数的默认值就是60秒,该参数的含义就是监控Spark任务获取任务状态的超时时间,60s内任务如果没有被成功提交,就会失败。所以我们将该参数调大。设置方式有两种,直接在hive命令行设置如下:
hive> set hive.spark.job.monitor.timeout=600;
或者在hive-site.xml文件中设置:
<property>
<name>hive.spark.job.monitor.timeoutname>
<value>600value>
property>
设置好之后,再运行一遍任务,结果如下:
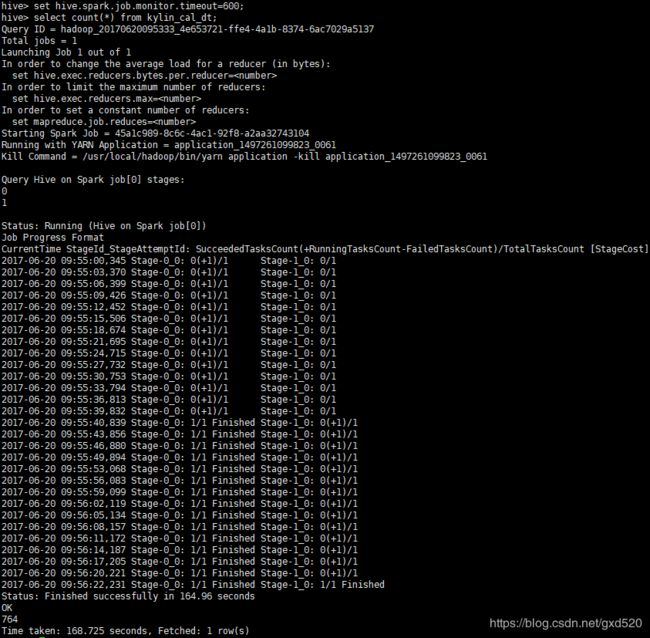
哈哈,成功了!是不是有点小激动!