哥伦比亚大学 自然语言处理 公开课 授课讲稿 翻译(一)
前言:心血来潮看了一个自然语言处理公开课,大牛柯林斯讲授的。觉得很好,就自己动手把它的讲稿翻译成中文。一方面,希望通过这个翻译过程,让自己更加理解大牛的讲授内容,锻炼自己翻译能力。另一方面,造福人类,hah。括号内容是我自己的辅助理解内容。
翻译的不准的地方,欢迎大家指正。
课程地址:https://www.coursera.org/course/nlangp
哥伦比亚大学 自然语言处理 公开课 授课讲稿 翻译(一):自然语言处理介绍-1
导读:这节课柯老师引出三个问题:什么是自然语言处理?为什么自然语言处理如此困难?这个课程是什么样子的?柯老师会在这节课和下节课就这三个问题进行解答。这节课里面柯老师给我们介绍了标注、句法分析等自然语言处理基本问题和机器翻译、信息抽取、文本摘要、对话系统等应用。 通过这些来回答他的第一个问题。

Okay, so welcome to Natural Language Processing. My name is Michael Collins, I'm a professor in Computer Science at Columbia University.I've taught this course for several years now, most recently at Columbia, and before that at MIT. Natural language processing is I think, a tremendously exciting field.It builds on insights from computer science, from linguistics, and as we'll see, increasingly from probability and statistics. It's also having a huge impact in our daily lives. Many, many applications and technologies are now making use of basic ideas from Natural Language Processing. So, in this introductory lecture, we're going to cover a few basic points.
欢迎大家来到自然语言处理课程,我是来自哥伦毕业大学计算机系的教授迈克尔-柯林斯(个人主页:点击打开链接)。这门课我已经教授过多年,大部分是在近几年哥伦比亚大学教授的。在来哥伦比亚大学之前我呆在麻省理大学,在那里我也教过这门课程。在我看来,自然语言处理是一个令人非常兴奋的领域。它建立在对计算机,对语言学的深刻理解之上,当然,我们也将看到它越来越依靠概率和统计。自然语言处理对我们的日常生活也有着很大的影响,非常多的技术和应用正在利用着自然语言处理的基本思想。在这个课程里面,我们将要讲授一下几个基本的要点。

The first question we're going to ask is, what is Natural Language Processing? So, we'll discuss a few key applications in NLP and also a few key problems that are solved in Natural Language Processing. The second question we'll consider is, why is NLP hard? So, we'll consider some key challenges that we'll find in natural language processing. Finally, I'll talk a little bit about what this course will be about, what kind of material we'll cover in this course, and what in general you should expect taking this course? So, at a high level, natural language processing concerns the use of computers in processing human or natural languages. So, on one side of this problem, we have what is often referred to as natural language understanding where we take text as input to the computer and it then processes that text and, and does something useful with it. At the other hand, we have what is often referred to as natural language generation. Where a computer, in some sense produces language in communicating with a human or user.
第一点,我想问大家的是,什么是自然语言处理?在这里我们会讨论一些在自然语言处理领域的牛叉的应用和一些被解决的关键问题。第二点,为什么自然语言处理如此困难?我们会思考一些我们在自然语言处理遇到的巨大挑战。最后一点,我会聊聊这个课程是什么样的,在课上会接触到哪些东西,一般而言你们学生希望从课堂上获得什么。从更高一个层次来看,自然语言处理关心的是如何利用计算机处理人类语言或者自然语言。一方面,我们通常称之为自然语言处理自然语言理解:我们的将自然文本输入计算机,让计算机去处理去从中获取有价值信息。另一方面,我们通常称之为自然语言生成:在某种意义上可以说机器生成一种与人类沟通的语言(机器理解人类的输入,可以与人沟通)。

One of the oldest applications and a problem of great importance is machine translation. This is the problem of mapping sentences in one language to sentences in another language. And this is a very, very challenging task. But remarkable progress is being made in the last 10 or 20 years in this area. So here, I have an example translation from Google translate which many of you will be familiar with, this is a translation from Arabic into English. And, while these translations perfect, you can still understand a great deal of what was said in the original language. So, later in this course, we'll actually go through all of the key steps in building a model in the machine translation system.
一个比较经典的应用是机器翻译,同时它也是一个非常重要的难题。这个难题就是将一种语言的句子映射到另一种语言上去。这是一项非常非常具有挑战性的工作。但是最近十到二十年这个领域取得了巨大的进步。在此,我会向大家展示几个大家都比较熟的谷歌翻译上自动翻译的例子,额,这个是一个从阿拉伯语翻译到英语的例子。大家看得到,谷歌翻译的非常漂亮。(通过自动翻译的句子)你可以了解到原文(阿拉伯语)意思。额,在接下来的课程中,我们会将搭建一个机器翻译系统中关键几步梳理一遍。

So, a second example application is what is often referred to as information extraction. So, the problem in this case is totake some text as input and to produce some structured, basically a database representation of some key content in this text. So, in this particular example, we have input which is a job posting. And the output captures various important aspects of this posting. For example, the industry involved, the position involved, the location, the company, the salary, and so on. And you'll see that this information is pulled out from this document. So, the salary in this case comes from this, this portion here. So this is a, a critical example of a natural lang, language on the standing problem where the promise to, in some sense understand this input were unstructured text and to turn it into a structured data base kind of representation. So there's some clear motivation for this particular problem, information extraction. Once we've performed this step, we can, for example, perform complex searches. So say I want to find all jobs in the advertising sector paying at least a certain salary in a particular location. This would be a search that is very difficult to formulate using a regular search engine, but if I first run my information extraction system over websites all of the job postings that I find in the web. I can then perform a database query and, and perform much more complex searches such as this one. In addition, we might be able to perform st, statistical queries. So we might be able to ask you know how is the number of jobs in accounting changed over the years, or what is the number of jobs in software engineering in the Boston area posted during the last year.
嗯,第二个应用就是我们通常说的信息抽取。这个应用下的问题就是将一些文本作为输入,产生结构化、数据库基本表示的文本核心内容。展示一个例子,我们输入一则招聘启事,输出显示了这则招聘启事的各个重要信息。比如涉及的行业、涉及的职位,工作地点,公司,薪水等等。你可以看到输出的信息就是从上面这则招聘启事抽取出来的。你看,薪水在招聘启事这一块提及,在这里。(画面上是柯林斯用比指着招聘启事的一行)。这是自然语言理解的一个重要例子—我们希望(计算机)在一定程度上理解无结构化的文本输入,并将它转化为一种数据库结构化表示。额,对这个信息抽取问题,我们的动机很明确:一旦我们能够达到这一步,我们就能够做一些非常复杂的搜索。(画面显示搜索的一个query):I want to find all jobs inthe advertising sector paying at least a certain salary in aparticular location.对普通的搜索引擎来说,这是一个非常难解决的搜索。(要对这句话进行语义理解,而不是简单字面匹配)。但是如果我先使用我的信息抽取系统对网上能找到的招聘启事进行处理,我们就可以执行数据库查询,回答像上面一样复杂的搜索。另外,我们可以执行统计搜索,告诉你会计方面的岗位近几年的变化,告诉你去年波士顿地区软件工程岗位的数目。

Another key application in natural language processing is text summarization. And the problem in this case is to take a single document or, potentially a group of several documents and to try to condense them down to a summary. Which, in some sense, preserves the main information in those documents. So here, I actually have an example screenshot from a system developed at Columbia, which is called News Blaster. And this is actually a multi-document system. It will take multiple documents on the same news story, and produce a condensed summary of the main content of those documents. So in this particular example, we have a large group of documents all about vaccination program. And here is a summary which attempts to capture the main information in all of these documents. So summarization again has clear motivation in making sense of the vast amount of data or text available on the web and the news sources, and so on. It's very useful to be able to summarize that data.
另一个自然语言处理应用就是文本摘要。这里的问题就是输入单个或者多个文档,试着将他们融合为一个显示这些文档主要内容的摘要。在此,我有一个来自哥伦比亚大学的News Blaster系统截图。这个系统实际上是一个多文档摘要系统。系统会处理相似新闻报道的多文档,生成一个显示这些文档主要内容的摘要。在这个特定的例子中,我们有一大批关于疫苗接种计划的文档,嗯,这就是(画面显示一些文字)这批文档的摘要,他试图去总结这批文档的主要内容。摘要在利用互联网上大量的新闻数据方面也有着明确的动机,对这些数据进行摘要是一件非常有用的事情。

Another key application is what are called dialogue systems. And these are systems where a human can actually interact with a computer to achieve some task. So, the example I've shown here is from a flight domain, where a user is attempting to book a flight. And so the user might come with some query to the system. And the system then goes and processes this query, in some sense it understands that query. And in this particular case it realizes that there's a piece of missing information, namely the day of the flight and so the system them responds with a query, what day are you flying on? The user provides this information and the system returns a list of flights. So in dialog systems the basic problem is to build a system where the user can interact with a computer using natural language. And notice that this type of system involves both natural language understanding components, we have to understand what the user is saying. And there's also importantly a natural language generation component. In that we're going to have to generate text in some cases. For example clarification questions as we've shown here.
还有一项关键应用就是我们所说的对话系统,人类可以与计算机进行真实互动去完成一些任务。额,在此,我向大家展示一个来自航空领域(的人机对话)。这里用户希望定一个航班,所以呢,用户就对系统进行请求,然后,系统处理请求后在一定意义上理解请求,这时候系统发现(用户请求)有一个没有说明白的信息,即day of the flight(用户定航班的时间)。系统理解对用户回复一个对话:what day are you flying on?。用户收到这个对话后提供时间时间给系统,系统收到信息后返回符合用户需求的航班列表。从这个例子我们可以看到,一个对话系统的基本问题就是建立一个人类可以使用自然语言与计算机互动的系统。我们注意到这个系统涉及自然语言理解:计算机需要理解用户所说的。另外还涉及自然语言生成部分:计算机需要生成(供用户理解的)文本。就像上面我们展示的计算机回复的对话(what day are you flying on?)。

So in addition to the applications I've just described, we'll also consider some very basic natural language processing problems which on depend many of these applications. And the first, we'll talk about is something called the tagging problem. So abstractly tagging problems take the following form. As input we have some sequence, in this case a sequence of letters and as output we are going to have a tagged sequence where each letter in the input now has an associated tag. This is probably best illustrated through a couple of examples. The first one is part-of-speech tagging. So the problem in this case is to take a sentences input, for example profits, soared, at Boeing Co and so on, and to tag each word in the input with its part of speech. So N stands for Noun, V stands for verb, P stands for preposition, ADV stands for adverb, and so on and so on. So, this is one of the sort of, most basic problems in natural language processing. If you can perform this mapping with high accuracy, it's actually useful across a very wide range of applications.
除了我刚才所提的应用之外,我们再来看看一些自然语言处理的基础问题,很多应用都要靠他们做支撑。首先,我们聊聊标注问题,简单的说标注就是下面这个样子。这些序列(字符)作为输入,输出上我们会得到一个被标注的序列。这里呢,输入的字符会捆绑上一个标签。还是通过几个例子来展示下吧。第一个例子就是词性标注,这里的问题就是将一个句子作为输入,比如输入profits,soared, at Boeing Co对输入句子的单词标注出它的词性。额,这里N代表名词,V代表动词,P代表介词,ADV代表形容词等等。这是自然语言处理基础问题系列中的一个,如果你能将这个映射过程的精度提高,它对很多很多应用都有极大的帮助。
The second example of a tagging problem is what's called named entity recognition. So the basic problem here is, again, to take some sentence's input. And now, to identify basic entities in that sentence. So, entities are things like companies. So we have Boeing Co here. Locations. Wall Street here. We might also, for example, identify people. Again, named entity recognition is a very basic problem. But it's clearly very useful in many applications to be able to identify companies, locations, people, and other entity types. This problem could be again this problem could again be framed as a tagging problem where each word in the input is tagged either as not belonging to any named entity, so NA means we're not part of an entity, or we might be part of a company. Sc means we have the first word in a company, it's a start company. Cc means we have the continuation of a company. And similarly, SL means we have the start of a location. Cl means we have the continuation of a location. So again abstractly, a tagging problem is a problem of mapping an input sequence of items, usually words to some tag sequence, where each word in the sequence has an associated tag.
第二个标注问题例子就是我们所说的实体识别。这里的问题同样是将一句话作为输入,但现在问题是识别句子中的基本实体。额,实体就是一些像公司之类的东西。拿Boeing Co here.Locations. WallStreet here. Locations. Wall Street here.这句话来说,我们可以识别人名。再次强调,虽然命名实体识别是一个基础问题,但是识别出公司、地址、人物等等实体类别对很多应用是十分有用的。这个实体识别问题可以由标注问题深入,这里给输入的字符标记命名实体:NA表示他不属于任何实体,或者有的字符属于公司(命名实体)的一部分,Sc表示公司(命名实体)的开始部分,Cc表示公司(命名实体)的组成部分。类似地,SL表示地址(命名实体)的开始部分,CL表示地址(命名实体)组成部分。简单的说,标记问题就是一个输入序列的映射问题,通常是将字符映射到标记序列,使每个字符都有自己的标记。
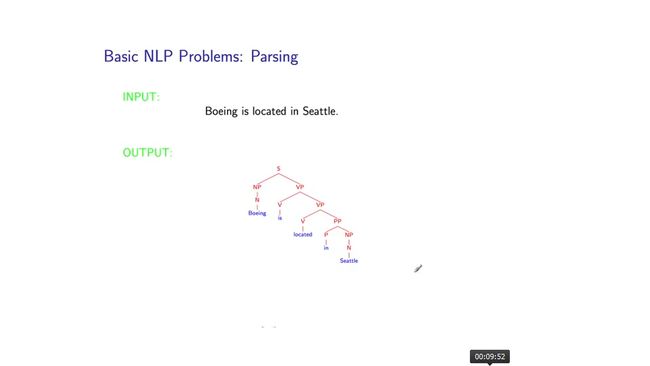
These are two key problems, and there are many, many others. Another basic problem in natural language processing is the problem of natural language parsing. And this goes back to work in linguistics, going back to sort of the foundation of modern linguistics with Noam Chomskys work in the 1950s. The problem here is again to take some sentence as input, and to map this to some output, which is usually referred to as a parse tree. So we'll talk a lot about this later in this course, but at a very high level. The parse tree essentially gives some hierarchical decomposition of a sentence. Corresponding to its grammatical structure. And once we've recovered these kind of representations. We can, for example, recover basic grammatical relations. The fact that Boeing is the subject of this verb is, or the fact that this prepositional phrase in Seattle is a modifier to located. So, again this is a very basic problem in natural language processing. Well see that, if you can recover these representations with high accuracy. It's useful, again across a very wide range of applications to gain a first basic step in natural language understanding. And trying to make sense of what an underlying sentence means.And it's also quite challenging problem.
这里举例两个关键的问题,但是自然语言处理中有着很多其他的基础问题。另外一个基础问题就是自然语言处理句法分析。这项工作始于语言学,始于二十世纪五十年代Noam Chomskys的现代语言学基础工作。这里我们仍然使用一些句子作为输入,将它映射到输出,通常输出被称之为句法树,后面课程中我们会深入句法树。句法树是依照其语法知识对句子进行基本的层次分解。一旦我们可以识别出这种表示,我们可以识别出基本语法单元的关系。比如,Boeing是这个动词的主语,介词短语in Seattle是located的修饰语。再次强调,这是一个自然语言处理的基础工作,如果你能提高这些表示识别准确率,它对很多很多自然语言理解方面的应用都有极大的帮助。试图去理解一句话的潜在含义是一件非常具有挑战性的工作。
<第一节完>
哥伦比亚大学 自然语言处理 公开课 授课讲稿 翻译(二):自然语言处理介绍-2
哥伦比亚大学 自然语言处理 公开课 授课讲稿 翻译(三):语言模型介绍-1
哥伦比亚大学 自然语言处理 公开课 授课讲稿 翻译(四):语言模型介绍-2