数据结构——优先队列与堆
什么是优先队列?
普通队列:先进先出,后进后出
优先队列:出队顺序和入队顺序无关;和优先级相关,如医院中,病重先安排病床
优先队列的现实例子:
①cpu任务调度,动态选择优先级最高的任务执行
②王者荣耀中,攻击键优先打敌人,无敌人时候优先打最近的小兵
关于优先队列的实现:
普通的线性结构和堆都可以作为优先队列的底层实现。

堆实现优先队列,在最坏的情况下,入队与出队的操作,时间复杂都为O(logn)
二叉堆

①堆是一棵完全二叉树
②堆中某个节点的值总是不大于其父节点的值,图示为最大堆
补充:在堆中,所有节点的值都大于他们的孩子节点,那么层次比较低的节点一定大于层次比较高的节点呢?
不一定,如16、13和19。
可以使用一个数组表示而不需要使用链,数组如图所示:

父子索引之间的关系
parent(i) = i / 2;
left child(i) = 2 * i;
right child(i) = 2 * i + 1;索引也可以从0开始,但公式有所变化

父子索引之间的关系
parent(i) = (i - 1 ) / 2;
left child(i) = 2 * i + 1;
right child(i) = 2 * i + 2;
大根堆中
向堆中添加一个元素(Sift Up上浮)
先添加,再上浮【满足父节点一定大于新添加的节点,否则(while)两者交换位置,并更新索引值】
/**
* 向堆中添加元素
*/
public void add(T t) {
data.addLast(t);
siftUp(data.getSize() - 1);
}
//上浮
private void siftUp(int i) {
while (i > 0 && data.get(i).compareTo(data.get(parent(i))) > 0) {
//交换位置
data.swap(i, parent(i));
//更新i值
i = parent(i);
}
}
堆中移除最大一个元素后(Sift Up下沉)
移除最大元素后,实际上变为了52和30为根节点的子树,为了简化操作,将索引值最大的元素size-1复制到索引0的位置,再删除size-1的元素,这样总的元素个数就保证了。

那么造成一个问题,16元素作为父节点并不大于它的两个子节点,所以需要有Sift Up下沉的动作,直到满足父节点元素值大于子节点元素值。

每次我们需要下沉的元素都和子孩子比较,选择两个孩子中最大的元素,如果最大的元素比父节点更大的话,则子节点与父节点交换位置,此时父节点52就一定比左右节点都大了。
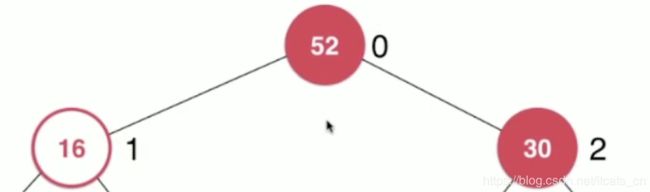
此时再将16与他的最大子节点进行比较,如果仍不满足父节点大于子节点的话,继续交换位置。

此时再次比较16所处位置的子节点,满足父节点大于子节点,不需要交换位置,下沉操作结束Sift down。
/**
* 查看堆中最大元素
*/
public T findMax() {
if (data.getSize() == 0)
throw new IllegalArgumentException("堆中没有元素");
return data.get(0);
}
/**
* 取出堆中最大元素
*/
public T extractMax() {
T t = findMax();
/**
* 将堆中最大的元素删除
* 1、将最后一个元素与第一个元素交换位置
* 2、删除最后一个元素
* 3、对索引0元素执行siftDown过程
*/
data.swap(0, data.getSize() - 1);
data.removeLast();
siftDown(0);
return t;
}
/**
* 元素下沉操作(大值上浮,小值下沉)
* 0、当该节点下是否具有左子节点:
* 1、如果该节点存在具备右子节点,且右子节点大于左子节点,记录下右子节点索引
* 2、如果不存在右子节点或右子节点小于左子节点,记录下左子节点索引
* 3、此时记录下的索引值一定是最大值,与其父节点做比较,如果父节点小于该值,交换值并更新索引index
*/
private void siftDown(int index) {
//0
while (leftChild(index) < data.getSize()) {
int tag = leftChild(index);
//1
if (tag + 1 < data.getSize() && data.get(tag + 1).compareTo(data.get(tag)) > 0) {
tag ++;
}
//2、3 tag
if(data.get(tag).compareTo(data.get(index)) > 0){
data.swap(tag,index);
index = tag;
}
}
}add和extractMax时间复杂度都是O(logn),同二叉树的高度。因为堆是一个完全二叉树,永远不会退化成一个链表。
replace
取出最大的元素后,再放入一个新的元素。
实现思路:①先执行一次extractMax的操作,再执行一次add操作,实际上是两次O(logn)的操作
②可以将堆顶的元素替换为新增元素,再调用一次siftDown,实际上是一次O(logn)操作
/**
* 先取出堆中最大元素,再新增新元素
* 将堆顶的元素替换为新增元素,再调用一次siftDown()
*/
public T replace(T t){
T t1 = findMax();
data.add(0,t);
siftDown(0);
return t1;
}
heapify
将任意数组整理成堆的形状
①将给定的数组看成一个完全二叉树
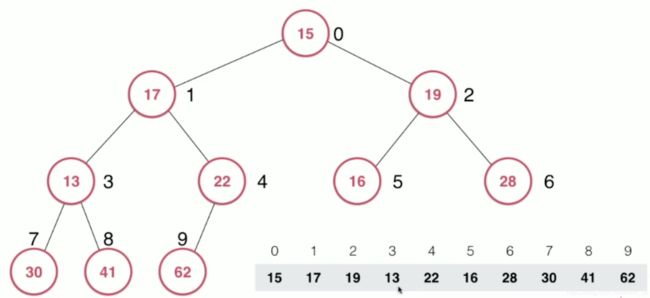
②从最后一个非叶子节点开始下沉siftDown(),即从索引4位置不断向前执行siftDown()操作
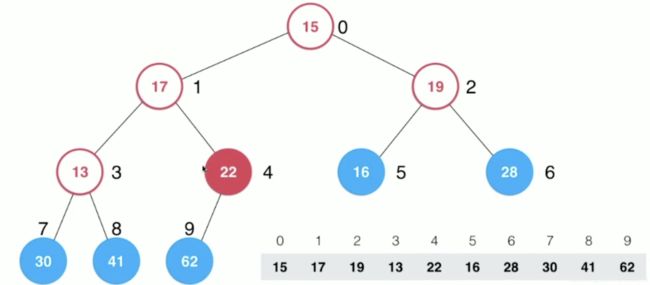
plus:最后一个非叶子节点的索引为:获得最后一个索引,计算出其父节点索引。
对于索引从0开始的完全二叉树,其父节点索引为(data.getSize() - 1 ) / 2,从1开始为data.getSize() / 2
③索引4上的22小于其子节点(索引为9的62),交换位置,下沉操作结束。再看索引为3所在节点,其左右节点最大值为41大于13,则41与13交换位置,下沉操作结束。再看索引为2所在节点,其左右节点最大值为28大于19,则28与19交换位置,下沉结束

④对于索引为1的节点17,它的最大子节点为62大于17,则62与17交换位置,此时17来到了索引为4的位置,由于17下还有子节点22且大于17,17与22交换位置,此时17来到了索引为9的位置。

⑤索引为0的节点15,其最大子节点为62大于15,则15与62交换位置,此时15来到了索引为1的位置,由于其下面还有子节点,索引为1下的子节点最大值为41大于15,则41与15交换位置,此时15来到了索引为3的位置,由于其下面还有子节点,接着下沉索引为3下的子节点最大值为30大于15,30与15交换位置,此时15来到了索引为7的位置,由于索引为7不存在子节点,下沉结束。
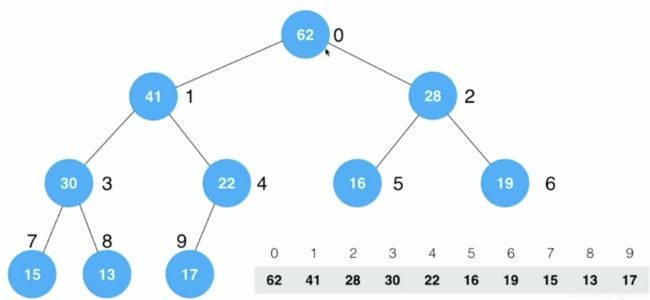
自此位置,heapify过程完成了,数组变成了一个最大堆。我们在heapfiy之前就排除了所有叶子节点,相当于一次抛弃了一半的节点,再进行siftDown操作,相比从一个空堆开始一个个添加元素要快很多(因为对每一个元素都要执行O(logn)的操作,相当于O(nlogn)级别的操作,而heapify的过程,时间复杂度为0(n)级别)
//Array类中
public Array(E[] arr){
data = (E[]) new Object[arr.length];
for(int i = 0 ; i < arr.length ; i ++)
data[i] = arr[i];
size = arr.length;
} public MaxHeap(T[] arr){
//构建一个完全二叉树
data = new Array<>(arr);
//从最后一个非叶子节点开始向前siftDown
for(int i = parent(arr.length - 1) ; i >= 0 ; i--)
siftDown(i);
}
使用最大堆实现优先队列
public class PriorityQueue> implements Queue {
private MaxHeap maxHeap;
public PriorityQueue(){
maxHeap = new MaxHeap<>();
}
public void enqueue(E e) {
maxHeap.add(e);
}
public E dequeue() {
return maxHeap.extractMax();
}
public E getFront() {
return maxHeap.findMax();
}
public int getSize() {
return maxHeap.getSize();
}
public boolean isEmpty() {
return maxHeap.isEmpty();
}
}
优先队列的经典问题
在100万元素中选出前100名
即从N个元素中取出前M个元素【对应Leetcode 347题】
①如果通过先对100万元素排序,再取出前100个元素,使用高级排序算法可以达到O(NlogN)时间复杂度
②如果使用优先队列,可以达到O(NlogM)时间复杂度。实现思路:【使用优先队列,维护当前看到的前M个元素】如题中先取100万元素中索引为0-99的100个元素放入优先队列中,之后每个新的元素大于优先队列中最小的元素,则替换。直到扫描完100万个元素,最终留下来的元素则为前100名【需要使用最小堆】
/**
* 从N个元素中取出出现频率最高的前k个元素
* 实现思路:
* 1、遍历数组,使用Map统计频次
* 2、创建优先队列,当优先队列的大小小于k时,入队操作。
* 当优先队列的大小大于k时,将优先队列中元素出现频率最少次数与新加入的元素比较
* 如果即将入队元素频率大于优先队列中出现的最少频率,则最少频率的元素出队,新增元素入队替换
* 3、创建LinkedList将优先队列的元素加入到链表中
*/
public class Solution {
private class Freq implements Comparable{
public int e , freq ;
public int compareTo(Freq another) {
if(this.freq < another.freq)
return 1;
else if(this.freq > another.freq)
return -1;
return 0;
}
public Freq(int e,int freq){
this.e = e;
this.freq = freq;
}
}
public List topKFrequent(int [] nums, int k){
Map map = new TreeMap<>();
for(int num : nums){
if(map.containsKey(num)){
map.put(num,map.get(num)+1);
}else{
map.put(num,1);
}
}
//执行完在queue中所剩的就是前k个元素 O(nlogk)
PriorityQueue queue = new PriorityQueue<>();
for(int key : map.keySet()){
if(queue.getSize() < k){
queue.enqueue(new Freq(key,map.get(key)));
}
else if(map.get(key) > queue.getFront().freq){
queue.dequeue();
queue.enqueue(new Freq(key,map.get(key)));
}
}
LinkedList linkedList = new LinkedList();
while(!queue.isEmpty()){
linkedList.add(queue.dequeue().e);
}
return linkedList;
}
} plus: Java中的PriorityQueue为最小堆(小根堆),使用Java内置的优先队列完成Leetcode
class Solution {
public List topKFrequent(int [] nums, int k){
TreeMap map = new TreeMap<>();
for(int num : nums){
if(map.containsKey(num)){
map.put(num,map.get(num)+1);
}else{
map.put(num,1);
}
}
//简化前
PriorityQueue queue = new PriorityQueue<>(new Comparator(){
public int compare(Integer a, Integer b) {
return map.get(a) - map.get(b);
}
});
//可以使用Lambda表达式简化为: 简化后
PriorityQueue queue = new PriorityQueue<>(
(a,b) -> map.get(a) - map.get(b)
);
for(int key : map.keySet()){
if(queue.size() < k){
queue.add(key);
}
else if(map.get(key) > map.get(queue.peek())){
queue.remove();
queue.add(key);
}
}
LinkedList linkedList = new LinkedList();
while(!queue.isEmpty()){
linkedList.add(queue.remove());
}
return linkedList;
}
}