深度学习个人总结之四----自编码算法(AutoEncoder)
本篇文章主要参考了以下内容:
1.http://blog.csdn.net/zouxy09/article/details/8775524
2.http://ufldl.stanford.edu/wiki/index.php/UFLDL%E6%95%99%E7%A8%8B
AutoEncoder是采用无监督学习方式进行训练学习的(如果不知道什么是无监督学习,请看这篇http://blog.csdn.net/kevin_bobolkevin/article/details/50539693)。它是是一种尽可能复现输入信号的神经网络。为了实现这种复现,自动编码器就必须捕捉可以代表输入数据的最重要的因素,就像PCA那样,找到可以代表原信息的主要成分。
一、AutoEncoder算法的思路
1)给定无标签数据,用非监督学习学习特征:

在我们之前的神经网络中,如第一个图,我们输入的样本是有标签的,即(input, target),这样我们根据当前输出和target(label)之间的差去改变前面各层的参数,直到收敛。但现在我们只有无标签数据,也就是右边的图。那么这个误差怎么得到呢?

如上图,我们将input输入一个encoder编码器,就会得到一个code,这个code也就是输入的一个表示,那么我们怎么知道这个code表示的就是input呢?我们加一个decoder解码器,这时候decoder就会输出一个信息,那么如果输出的这个信息和一开始的输入信号input是很像的(理想情况下就是一样的),那很明显,我们就有理由相信这个code是靠谱的。所以,我们就通过调整encoder和decoder的参数,使得重构误差最小,这时候我们就得到了输入input信号的第一个表示了,也就是编码code了。因为是无标签数据,所以误差的来源就是直接重构后与原输入相比得到。

2)通过编码器产生特征,然后训练下一层。这样逐层训练:
那上面我们就得到第一层的code,我们的重构误差最小让我们相信这个code就是原输入信号的良好表达了,或者牵强点说,它和原信号是一模一样的(表达不一样,反映的是一个东西)。那第二层和第一层的训练方式就没有差别了,我们将第一层输出的code当成第二层的输入信号,同样最小化重构误差,就会得到第二层的参数,并且得到第二层输入的code,也就是原输入信息的第二个表达了。其他层就同样的方法炮制就行了(训练这一层,前面层的参数都是固定的,并且他们的decoder已经没用了,都不需要了)。

3)有监督微调:
经过上面的方法,我们就可以得到很多层了。至于需要多少层(或者深度需要多少,这个目前本身就没有一个科学的评价方法)需要自己试验调了。每一层都会得到原始输入的不同的表达。当然了,我们觉得它是越抽象越好了,就像人的视觉系统一样。
到这里,这个AutoEncoder还不能用来分类数据,因为它还没有学习如何去连结一个输入和一个类。它只是学会了如何去重构或者复现它的输入而已。或者说,它只是学习获得了一个可以良好代表输入的特征,这个特征可以最大程度上代表原输入信号。那么,为了实现分类,我们就可以在AutoEncoder的最顶的编码层添加一个分类器(例如罗杰斯特回归、SVM等),然后通过标准的多层神经网络的监督训练方法(梯度下降法)去训练。
也就是说,这时候,我们需要将最后层的特征code输入到最后的分类器,通过有标签样本,通过监督学习进行微调,这也分两种,一个是只调整分类器(黑色部分):

另一种:通过有标签样本,微调整个系统:(如果有足够多的数据,这个是最好的。end-to-end learning端对端学习)

一旦监督训练完成,这个网络就可以用来分类了。神经网络的最顶层可以作为一个线性分类器,然后我们可以用一个更好性能的分类器去取代它。
二、AutoEncoder算法步骤
1)求各神经层的激活值
2)计算W和B的残差,用梯度下降法更新W和B,使输出不断接近输入
这个“神经元”是一个以 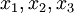 及截距
及截距 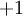 为输入值的运算单元,其输出为
为输入值的运算单元,其输出为 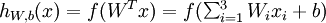 ,其中函数
,其中函数 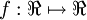 被称为“激活函数”。在本教程中,我们选用sigmoid函数作为激活函数
被称为“激活函数”。在本教程中,我们选用sigmoid函数作为激活函数 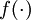
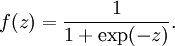
可以看出,这个单一“神经元”的输入-输出映射关系其实就是一个逻辑回归(logistic regression)。
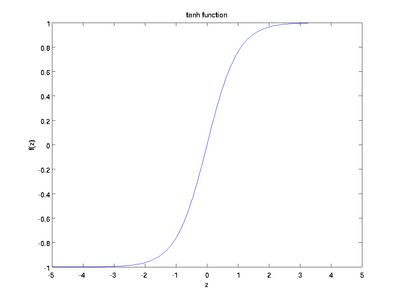
虽然本系列教程采用sigmoid函数,但你也可以选择双曲正切函数(tanh):
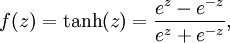
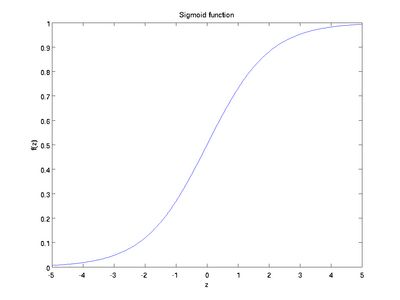
以下分别是sigmoid及tanh的函数图像
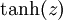 函数是sigmoid函数的一种变体,它的取值范围为
函数是sigmoid函数的一种变体,它的取值范围为 ![\textstyle [-1,1]](http://img.e-com-net.com/image/info8/f881eed4e1f547b28ec30b62f6bee412.png) ,而不是sigmoid函数的
,而不是sigmoid函数的 ![\textstyle [0,1]](http://img.e-com-net.com/image/info8/81aa8cfcc0074a0ea6d7d48daead7fc5.png) 。
。
注意,这里我们不再令  。取而代之,我们用单独的参数
。取而代之,我们用单独的参数 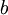 来表示截距。
来表示截距。
最后要说明的是,有一个等式我们以后会经常用到:如果选择 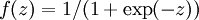 ,也就是sigmoid函数,那么它的导数就是
,也就是sigmoid函数,那么它的导数就是 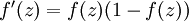 (如果选择tanh函数,那它的导数就是
(如果选择tanh函数,那它的导数就是 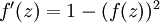 ,你可以根据sigmoid(或tanh)函数的定义自行推导这个等式。
,你可以根据sigmoid(或tanh)函数的定义自行推导这个等式。
神经网络就是由多个神经元组成,要求出神经网络的各层激活值,就需要用到前向传导算法。
那么所谓神经网络就是将许多个单一“神经元”联结在一起,这样,一个“神经元”的输出就可以是另一个“神经元”的输入。例如,下图就是一个简单的神经网络:
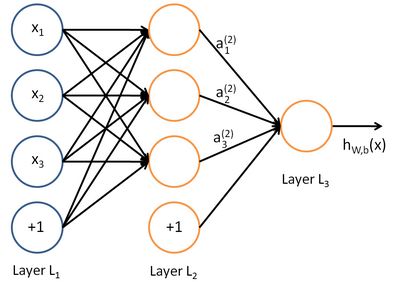
我们使用圆圈来表示神经网络的输入,标上“”的圆圈被称为偏置节点,也就是截距项。神经网络最左边的一层叫做输入层,最右的一层叫做输出层(本例中,输出层只有一个节点)。中间所有节点组成的一层叫做隐藏层,因为我们不能在训练样本集中观测到它们的值。同时可以看到,以上神经网络的例子中有3个输入单元(偏置单元不计在内),3个隐藏单元及一个输出单元。
我们用 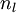 来表示网络的层数,本例中
来表示网络的层数,本例中 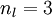 ,我们将第
,我们将第 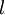 层记为
层记为 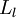 ,于是
,于是 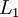 是输入层,输出层是
是输入层,输出层是 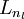 。本例神经网络有参数
。本例神经网络有参数 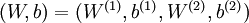 ,其中
,其中 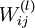 (下面的式子中用到)是第 层第
(下面的式子中用到)是第 层第 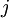 单元与第
单元与第 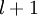 层第
层第 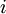 单元之间的联接参数(其实就是连接线上的权重,注意标号顺序),
单元之间的联接参数(其实就是连接线上的权重,注意标号顺序), 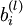 是第 层第 单元的偏置项。因此在本例中,
是第 层第 单元的偏置项。因此在本例中, 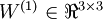 ,
, 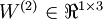 。注意,没有其他单元连向偏置单元(即偏置单元没有输入),因为它们总是输出 。同时,我们用
。注意,没有其他单元连向偏置单元(即偏置单元没有输入),因为它们总是输出 。同时,我们用 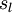 表示第 层的节点数(偏置单元不计在内)。
表示第 层的节点数(偏置单元不计在内)。
我们用 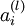 表示第 层第 单元的激活值(输出值)。当
表示第 层第 单元的激活值(输出值)。当 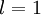 时,
时, 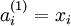 ,也就是第 个输入值(输入值的第 个特征)。对于给定参数集合
,也就是第 个输入值(输入值的第 个特征)。对于给定参数集合 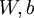 ,我们的神经网络就可以按照函数
,我们的神经网络就可以按照函数 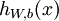 来计算输出结果。本例神经网络的计算步骤如下:
来计算输出结果。本例神经网络的计算步骤如下:
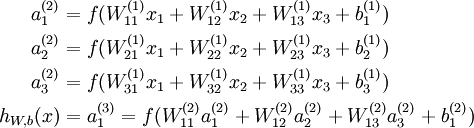
我们用 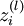 表示第 层第 单元输入加权和(包括偏置单元),比如,
表示第 层第 单元输入加权和(包括偏置单元),比如, 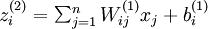 ,则
,则 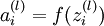 。
。
这样我们就可以得到一种更简洁的表示法。这里我们将激活函数 扩展为用向量(分量的形式)来表示,即 ![\textstyle f([z_1, z_2, z_3]) = [f(z_1), f(z_2), f(z_3)]](http://img.e-com-net.com/image/info8/5acc41c35b5d492284d2259b40dd669a.png) ,那么,上面的等式可以更简洁地表示为:
,那么,上面的等式可以更简洁地表示为:
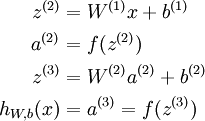
我们将上面的计算步骤叫作前向传播。回想一下,之前我们用 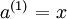 表示输入层的激活值,那么给定第 层的激活值
表示输入层的激活值,那么给定第 层的激活值 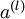 后,第 层的激活值
后,第 层的激活值 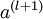 就可以按照下面步骤计算得到:
就可以按照下面步骤计算得到:
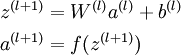
将参数矩阵化,使用矩阵-向量运算方式,我们就可以利用线性代数的优势对神经网络进行快速求解。
目前为止,我们讨论了一种神经网络,我们也可以构建另一种结构的神经网络(这里结构指的是神经元之间的联接模式),也就是包含多个隐藏层的神经网络。最常见的一个例子是 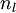 层的神经网络,第
层的神经网络,第 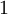 层是输入层,第 层是输出层,中间的每个层 与层 紧密相联。这种模式下,要计算神经网络的输出结果,我们可以按照之前描述的等式,按部就班,进行前向传播,逐一计算第
层是输入层,第 层是输出层,中间的每个层 与层 紧密相联。这种模式下,要计算神经网络的输出结果,我们可以按照之前描述的等式,按部就班,进行前向传播,逐一计算第 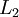 层的所有激活值,然后是第
层的所有激活值,然后是第 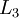 层的激活值,以此类推,直到第 层。这是一个前馈神经网络的例子,因为这种联接图没有闭环或回路。
层的激活值,以此类推,直到第 层。这是一个前馈神经网络的例子,因为这种联接图没有闭环或回路。
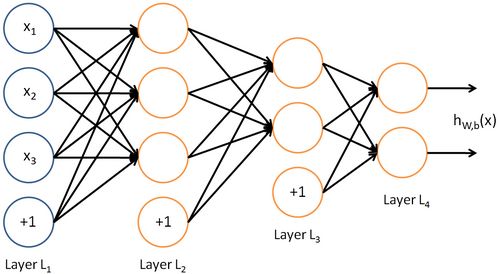
神经网络也可以有多个输出单元。比如,下面的神经网络有两层隐藏层: 及 ,输出层 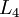 有两个输出单元。
有两个输出单元。
要求解这样的神经网络,需要样本集 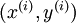 ,其中
,其中 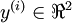 。如果你想预测的输出是多个的,那这种神经网络很适用。(比如,在医疗诊断应用中,患者的体征指标就可以作为向量的输入值,而不同的输出值
。如果你想预测的输出是多个的,那这种神经网络很适用。(比如,在医疗诊断应用中,患者的体征指标就可以作为向量的输入值,而不同的输出值 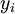 可以表示不同的疾病存在与否。)
可以表示不同的疾病存在与否。)
3.计算W和B的残差
使用后向传导算法(BP)求出最终输出层与各层神经元的“残差”
反向传导算法推算
假设我们有一个固定样本集 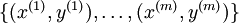 ,它包含
,它包含 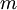 个样例。我们可以用批量梯度下降法来求解神经网络。具体来讲,对于单个样例
个样例。我们可以用批量梯度下降法来求解神经网络。具体来讲,对于单个样例 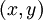 ,其代价函数为:
,其代价函数为:
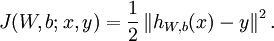
这是一个(二分之一的)方差代价函数。给定一个包含 个样例的数据集,我们可以定义整体代价函数为:
![\begin{align}J(W,b)&= \left[ \frac{1}{m} \sum_{i=1}^m J(W,b;x^{(i)},y^{(i)}) \right] + \frac{\lambda}{2} \sum_{l=1}^{n_l-1} \; \sum_{i=1}^{s_l} \; \sum_{j=1}^{s_{l+1}} \left( W^{(l)}_{ji} \right)^2 \\&= \left[ \frac{1}{m} \sum_{i=1}^m \left( \frac{1}{2} \left\| h_{W,b}(x^{(i)}) - y^{(i)} \right\|^2 \right) \right] + \frac{\lambda}{2} \sum_{l=1}^{n_l-1} \; \sum_{i=1}^{s_l} \; \sum_{j=1}^{s_{l+1}} \left( W^{(l)}_{ji} \right)^2\end{align}](http://img.e-com-net.com/image/info8/edf33f85af344a4aad70cd3818ebd36a.png)
以上公式中的第一项 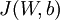 是一个均方差项。第二项是一个规则化项(也叫权重衰减项),其目的是减小权重的幅度,防止过度拟合。
是一个均方差项。第二项是一个规则化项(也叫权重衰减项),其目的是减小权重的幅度,防止过度拟合。
[注:通常权重衰减的计算并不使用偏置项 ,比如我们在 的定义中就没有使用。一般来说,将偏置项包含在权重衰减项中只会对最终的神经网络产生很小的影响。如果你在斯坦福选修过CS229(机器学习)课程,或者在YouTube上看过课程视频,你会发现这个权重衰减实际上是课上提到的贝叶斯规则化方法的变种。在贝叶斯规则化方法中,我们将高斯先验概率引入到参数中计算MAP(极大后验)估计(而不是极大似然估计)。]
权重衰减参数 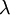 用于控制公式中两项的相对重要性。在此重申一下这两个复杂函数的含义:
用于控制公式中两项的相对重要性。在此重申一下这两个复杂函数的含义: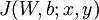 是针对单个样例计算得到的方差代价函数; 是整体样本代价函数,它包含权重衰减项。
是针对单个样例计算得到的方差代价函数; 是整体样本代价函数,它包含权重衰减项。
以上的代价函数经常被用于分类和回归问题。在分类问题中,我们用 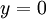 或 ,来代表两种类型的标签(回想一下,这是因为 sigmoid激活函数的值域为 ;如果我们使用双曲正切型激活函数,那么应该选用
或 ,来代表两种类型的标签(回想一下,这是因为 sigmoid激活函数的值域为 ;如果我们使用双曲正切型激活函数,那么应该选用 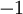 和 作为标签)。对于回归问题,我们首先要变换输出值域(译者注:也就是
和 作为标签)。对于回归问题,我们首先要变换输出值域(译者注:也就是 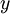 ),以保证其范围为 (同样地,如果我们使用双曲正切型激活函数,要使输出值域为 )。
),以保证其范围为 (同样地,如果我们使用双曲正切型激活函数,要使输出值域为 )。
我们的目标是针对参数 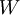 和 来求其函数 的最小值。为了求解神经网络,我们需要将每一个参数 和 初始化为一个很小的、接近零的随机值(比如说,使用正态分布
和 来求其函数 的最小值。为了求解神经网络,我们需要将每一个参数 和 初始化为一个很小的、接近零的随机值(比如说,使用正态分布 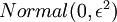 生成的随机值,其中
生成的随机值,其中 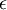 设置为
设置为 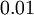 ),之后对目标函数使用诸如批量梯度下降法的最优化算法。因为 是一个非凸函数,梯度下降法很可能会收敛到局部最优解;但是在实际应用中,梯度下降法通常能得到令人满意的结果。最后,需要再次强调的是,要将参数进行随机初始化,而不是全部置为
),之后对目标函数使用诸如批量梯度下降法的最优化算法。因为 是一个非凸函数,梯度下降法很可能会收敛到局部最优解;但是在实际应用中,梯度下降法通常能得到令人满意的结果。最后,需要再次强调的是,要将参数进行随机初始化,而不是全部置为 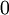 。如果所有参数都用相同的值作为初始值,那么所有隐藏层单元最终会得到与输入值有关的、相同的函数(也就是说,对于所有 ,
。如果所有参数都用相同的值作为初始值,那么所有隐藏层单元最终会得到与输入值有关的、相同的函数(也就是说,对于所有 ,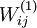 都会取相同的值,那么对于任何输入
都会取相同的值,那么对于任何输入 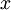 都会有:
都会有: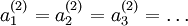 )。随机初始化的目的是使对称失效。
)。随机初始化的目的是使对称失效。
梯度下降法中每一次迭代都按照如下公式对参数 和 进行更新:
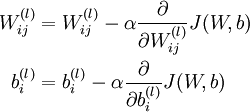
其中 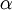 是学习速率。其中关键步骤是计算偏导数。我们现在来讲一下反向传播算法,它是计算偏导数的一种有效方法。
是学习速率。其中关键步骤是计算偏导数。我们现在来讲一下反向传播算法,它是计算偏导数的一种有效方法。
我们首先来讲一下如何使用反向传播算法来计算 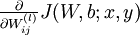 和
和 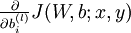 ,这两项是单个样例 的代价函数 的偏导数。一旦我们求出该偏导数,就可以推导出整体代价函数 的偏导数:
,这两项是单个样例 的代价函数 的偏导数。一旦我们求出该偏导数,就可以推导出整体代价函数 的偏导数:
![\begin{align}\frac{\partial}{\partial W_{ij}^{(l)}} J(W,b) &=\left[ \frac{1}{m} \sum_{i=1}^m \frac{\partial}{\partial W_{ij}^{(l)}} J(W,b; x^{(i)}, y^{(i)}) \right] + \lambda W_{ij}^{(l)} \\\frac{\partial}{\partial b_{i}^{(l)}} J(W,b) &=\frac{1}{m}\sum_{i=1}^m \frac{\partial}{\partial b_{i}^{(l)}} J(W,b; x^{(i)}, y^{(i)})\end{align}](http://img.e-com-net.com/image/info8/b5f5b07763e742fe91b0501983c4a131.png)
以上两行公式稍有不同,第一行比第二行多出一项,是因为权重衰减是作用于 而不是 。
反向传播算法的思路如下:给定一个样例 ,我们首先进行“前向传导”运算,计算出网络中所有的激活值,包括 的输出值。之后,针对第 层的每一个节点 ,我们计算出其“残差” 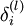 ,该残差表明了该节点对最终输出值的残差产生了多少影响。对于最终的输出节点,我们可以直接算出网络产生的激活值与实际值之间的差距,我们将这个差距定义为
,该残差表明了该节点对最终输出值的残差产生了多少影响。对于最终的输出节点,我们可以直接算出网络产生的激活值与实际值之间的差距,我们将这个差距定义为 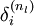 (第 层表示输出层)。对于隐藏单元我们如何处理呢?我们将基于节点(译者注:第 层节点)残差的加权平均值计算 ,这些节点以 作为输入。下面将给出反向传导算法的细节:
(第 层表示输出层)。对于隐藏单元我们如何处理呢?我们将基于节点(译者注:第 层节点)残差的加权平均值计算 ,这些节点以 作为输入。下面将给出反向传导算法的细节:
- 进行前馈传导计算,利用前向传导公式,得到
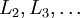 直到输出层 的激活值。
直到输出层 的激活值。 - 对于第 层(输出层)的每个输出单元 ,我们根据以下公式计算残差:
-
- 对
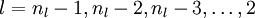 的各个层,第 层的第 个节点的残差计算方法如下:
的各个层,第 层的第 个节点的残差计算方法如下:
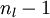 与的关系替换为与的关系,就可以得到:
与的关系替换为与的关系,就可以得到:
-
- 计算我们需要的偏导数,计算方法如下:
-
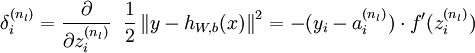
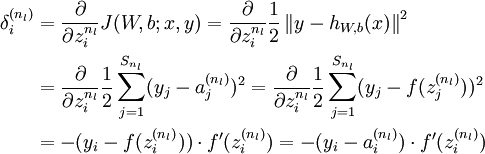
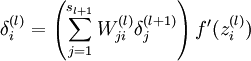
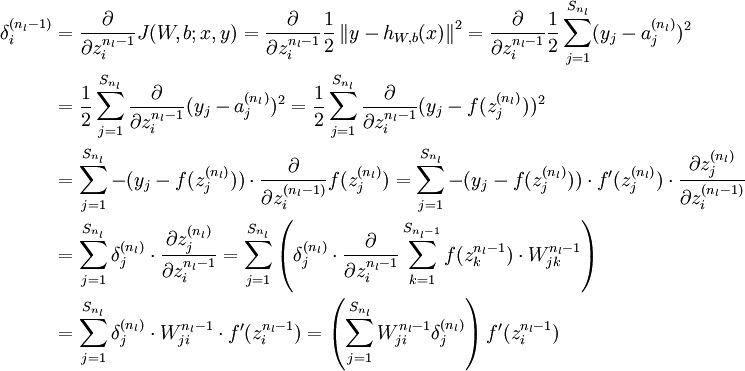

最后,我们用矩阵-向量表示法重写以上算法。我们使用“ ” 表示向量乘积运算符(在Matlab或Octave里用“.*”表示,也称作阿达马乘积)。若
” 表示向量乘积运算符(在Matlab或Octave里用“.*”表示,也称作阿达马乘积)。若 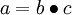 ,则
,则 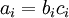 。在上一个教程中我们扩展了 的定义,使其包含向量运算,这里我们也对偏导数
。在上一个教程中我们扩展了 的定义,使其包含向量运算,这里我们也对偏导数 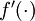 也做了同样的处理(于是又有
也做了同样的处理(于是又有 ![\textstyle f'([z_1, z_2, z_3]) = [f'(z_1), f'(z_2), f'(z_3)]](http://img.e-com-net.com/image/info8/e61d268f30004818a7d1eca2a96f46e5.png) )。
)。
那么,反向传播算法可表示为以下几个步骤:
- 进行前馈传导计算,利用前向传导公式,得到 直到输出层 的激活值。
- 对输出层(第 层),计算:
-
- 对于 的各层,计算:
-
- 计算最终需要的偏导数值:
-
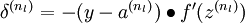
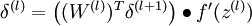
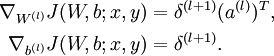
实现中应注意:在以上的第2步和第3步中,我们需要为每一个 值计算其 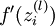 。假设
。假设 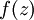 是sigmoid函数,并且我们已经在前向传导运算中得到了 。那么,使用我们早先推导出的
是sigmoid函数,并且我们已经在前向传导运算中得到了 。那么,使用我们早先推导出的 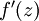 表达式,就可以计算得到
表达式,就可以计算得到 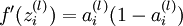 。
。
最后,我们将对梯度下降算法做个全面总结。在下面的伪代码中,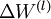 是一个与矩阵
是一个与矩阵 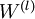 维度相同的矩阵,
维度相同的矩阵,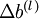 是一个与
是一个与 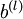 维度相同的向量。注意这里“”是一个矩阵,而不是“
维度相同的向量。注意这里“”是一个矩阵,而不是“ 与 相乘”。下面,我们实现批量梯度下降法中的一次迭代:
与 相乘”。下面,我们实现批量梯度下降法中的一次迭代:
- 对于所有 ,令
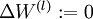 ,
, 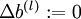 (设置为全零矩阵或全零向量)
(设置为全零矩阵或全零向量) - 对于
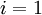 到 ,
到 ,
- 使用反向传播算法计算
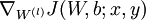 和
和 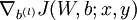 。
。 - 计算
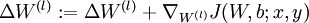 。
。 - 计算
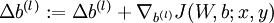 。
。
- 使用反向传播算法计算
- 更新权重参数:
-
![\begin{align}W^{(l)} &= W^{(l)} - \alpha \left[ \left(\frac{1}{m} \Delta W^{(l)} \right) + \lambda W^{(l)}\right] \\b^{(l)} &= b^{(l)} - \alpha \left[\frac{1}{m} \Delta b^{(l)}\right]\end{align}](http://img.e-com-net.com/image/info8/0656d8a4931d43f7be0e3f57eab1a9fe.png)
现在,我们可以重复梯度下降法的迭代步骤来减小代价函数 的值,进而求解我们的神经网络。