mmdetection(pytorch0.4.1版本)模型构建部分源码解析(转)
在mmdetection中,实现了许多现有two-stage目标检测方法以及one-stage目标检测方法,且包含完整的数据载入、模型构建、模型训练以及模型测试部分的源码。因此非常适合在此基础上扩展实现其他目标检测算法。关于数据载入、模型训练以及模型测试部分的源码,在上一篇博客中有详细介绍。后期打算在mmdetection基础上添加其他算法。因此了解模型构建这部分源码十分重要。在mmdetecion官方github介绍模型主要由四部分组成:backbone, neck, head, 以及ROI extractor。
阅读mmdetection源码最简单地主线就是根据模型配置文件configs/*.py文件中model部分去阅读。在mmdetection中,two-stage类目标检测方法model部分内容通常包含:backbone,neck,rpn_head,bbox_roi_extractor和bbox_head共五个部分。当然,在maskrcnn中还包括mask_roi_extractor和mask_head。以maskrcnn模型的配置文件中model部分为例,介绍模型构建部分,下面是maskrcnn模型中model部分配置:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
model = dict(
type='MaskRCNN', #模型名,对应模型声明在mmdet/modelsp/detectors/mask_rcnn.py文件中
pretrained='modelzoo://resnet50', #backbone的预训练模型
backbone=dict(
type='ResNet',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
style='pytorch',
dcn=dict(
modulated=False,
deformable_groups=1,
fallback_on_stride=False),
stage_with_dcn=(False, True, True, True)),
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
num_outs=5),
rpn_head=dict(
type='RPNHead',
in_channels=256,
feat_channels=256,
anchor_scales=[8],
anchor_ratios=[0.5, 1.0, 2.0],
anchor_strides=[4, 8, 16, 32, 64],
target_means=[.0, .0, .0, .0],
target_stds=[1.0, 1.0, 1.0, 1.0],
use_sigmoid_cls=True),
bbox_roi_extractor=dict(
type='SingleRoIExtractor',
roi_layer=dict(type='RoIAlign', out_size=7, sample_num=2),
out_channels=256,
featmap_strides=[4, 8, 16, 32]),
bbox_head=dict(
type='SharedFCBBoxHead',
num_fcs=2,
in_channels=256,
fc_out_channels=1024,
roi_feat_size=7,
num_classes=81,
target_means=[0., 0., 0., 0.],
target_stds=[0.1, 0.1, 0.2, 0.2],
reg_class_agnostic=False),
mask_roi_extractor=dict(
type='SingleRoIExtractor',
roi_layer=dict(type='RoIAlign', out_size=14, sample_num=2),
out_channels=256,
featmap_strides=[4, 8, 16, 32]),
mask_head=dict(
type='FCNMaskHead',
num_convs=4,
in_channels=256,
conv_out_channels=256,
num_classes=81))
|
注意:
- 上面的pretrained参数只是针对backbone部分的预训练权重,在mmdetection中除了支持pytorch的modelzoo之外,mmdetection也提供了部分预训练权重,具体可以查看mmcv/runner/checkpoint.py文件。
- 如果想对整个模型进行预训练,比如我使用coco数据集预训练模型去训练pascal voc,则可以在configs/*.py文件中load_from参数,来指定coco预训练模型权重文件路径。
Backbone && neck
目前官方实现了backbone包括:resnet,resnext以及ssd_vgg。作者在resnet基础上还实现了dcn。至于neck部分目前只有FPN,而且对于two-stage方法,neck只能设置为FPN,对应代码实现部分在mmdet/models/necks/fpn.py。backbone和neck相关的配置参数如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
backbone=dict(
type='ResNet',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1, #由于stage1的feature map比较大,因此冻结住,训练阶段可以节省内存
style='pytorch', #预训练模型载入来源,可以是caffe
dcn=dict( #dcn参数配置,如果仅仅使用普通resnet50,可以设置dcn=None
modulated=False,
deformable_groups=1,
fallback_on_stride=False),
stage_with_dcn=(False, True, True, True)),
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048], #对应于resnet的4个stage(C2,C3,C4,C5)输出通道数
out_channels=256, #对应(P2,P3,P4,P5,P6)的输出通道数
num_outs=5), #5个输出,对应P2-P6
|
backbone部分代码实现部分在mmdet/models/backbones/*.py文件中。neck部分代码实现部分在mmdet/models/necks/fpn.py文件中。这两部分代码的实现不难,不予介绍,FPN结构如下图所示。值得注意的是,RetinaNet模型中neck部分也是采用的FPN,对应neck部分配置却不一样,RetinaNet模型中neck部分参数如下:
1 2 3 4 5 6 7 |
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
start_level=1,
add_extra_convs=True,
num_outs=5)
|
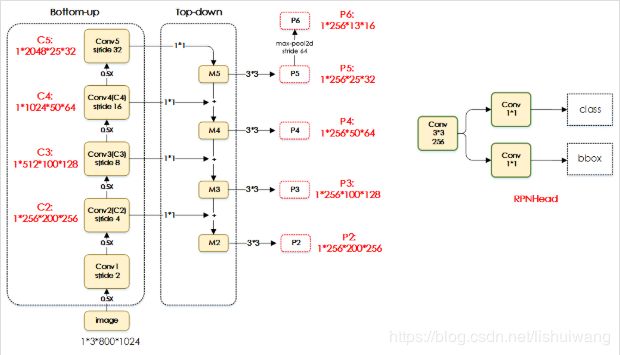
额外添加了start_level和add_extra_convs两个参数。start_level=1表示从C3开始,因为RetinaNet模型中FPN的输出并不是P2-P6这5个输出,在RetinaNet中FPN的输出采用的是P3-P7这5个输出。在maskrcnn的FPN结构中是直接通过对P5进行maxpool得到P6,而在RetinaNet中,P6通过对P5进行stride=2卷积操作得到的,而P7则是同样对P6进行stride=2卷积操作得到。这一部分的区别,可以看源码mmdet/models/necks/fpn.py文件中第72行。
rpn_head
这一部分主要涉及到anchor的相关操作,在mmdet/models/anchor_heads文件夹下实现了多种anchor_heads,其中包括基类AnchorHead(实现在anchor_head.py文件中),RetinaNet模型相关的RetinaHead类(实现在retina_head.py文件中),two-stage方法的RPNHead类(实现在rpn_head.py文件中)以及SSD方法SSDHead(实现在ssd_head.py文件中)。后面三个类都继承自AnchorHead基类。在maskrcnn中使用的anchor_head是RPNHead类,对应配置参数如下:
1 2 3 4 5 6 7 8 9 10 |
rpn_head=dict(
type='RPNHead',
in_channels=256, # FPN中每个level的输出通道数,通常都为256
feat_channels=256, # RPN的feature map的通道数
anchor_scales=[8], # anchor的尺度,在使用FPN结构时,每个level只有一种尺度
anchor_ratios=[0.5, 1.0, 2.0], #anchor比例:1:2,1:1,2:1这三种
anchor_strides=[4, 8, 16, 32, 64], #对应于FPN中每个level的featuremap上每个pixel的感受野大小;
target_means=[.0, .0, .0, .0],
target_stds=[1.0, 1.0, 1.0, 1.0],
use_sigmoid_cls=True) #anchor前景背景分类采用sigmoid,在早期的fasterrcnn采用的是softmax,在mmdetection中没有实现softmax分类
|
对应RPNHead类的实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
class (AnchorHead): #继承自AnchorHead类
def __init__(self, in_channels, **kwargs):
super(RPNHead, self).__init__(2, in_channels, **kwargs)
def _init_layers(self):
self.rpn_conv = nn.Conv2d(
self.in_channels, self.feat_channels, 3, padding=1)
self.rpn_cls = nn.Conv2d(self.feat_channels,
self.num_anchors * self.cls_out_channels, 1)
self.rpn_reg = nn.Conv2d(self.feat_channels, self.num_anchors * 4, 1)
def init_weights(self):
normal_init(self.rpn_conv, std=0.01)
normal_init(self.rpn_cls, std=0.01)
normal_init(self.rpn_reg, std=0.01)
def forward_single(self, x): #表示输入FPN的一个level,比如P6输入,P6:1*256*13*16
x = self.rpn_conv(x) #conv不改变featuremap大小,且feat_channels=256,故x:1*256*13*16
x = F.relu(x, inplace=True)
rpn_cls_score = self.rpn_cls(x) #对应于anchor的前景背景分类 1*3*13*16
rpn_bbox_pred = self.rpn_reg(x) #对应于anchor的回归 1*12*13*16
return rpn_cls_score, rpn_bbox_pred
def loss(self, cls_scores, bbox_preds, gt_bboxes, img_metas, cfg):
losses = super(RPNHead, self).loss(cls_scores, bbox_preds, gt_bboxes,
None, img_metas, cfg)
return dict(
loss_rpn_cls=losses['loss_cls'], loss_rpn_reg=losses['loss_reg'])
|
RPNHead类中实现的函数只是对AnchorHead类中部分函数的重写。由于RPNHead继承自AnchorHead类,在实际训练和测试中,直接调用的是还是继承自AnchorHead类的forward的函数。在RPN中通过在13x16的featuremap上生成13x16x3个anchors(注意,这里使用的是FPN结构,在不同level上,每个点只生成3个anchor,因此生成的anchors数是13x16x3)。经过后处理选择出proposal进行后续的bbox_roi_extractor。其中后处理操作包括:
- 删除背景框(13x16x3);
- NMS处理去除重合度大的框中分数低的那个;
- 取分数最大的K(top-k)个框用于后续bbox_roi_extractor;
这部分比较复杂,还涉及到一些RPN损失函数,比如smoth_l1_loss,focal loss以及delta2box的转换等等操作,直接看源码比较容易理解。关于Anchors这部分,推荐博客讲解的比较清楚,推荐看。
ROI extractor
在maskrcnn模型中,这部分涉及到box的操作以及mask的操作:bbox_roi_extractor和mask_roi_extractor。相关的配置如下:
1 2 3 4 5 6 7 8 9 10 |
bbox_roi_extractor=dict(
type='SingleRoIExtractor',
roi_layer=dict(type='RoIAlign', out_size=7, sample_num=2), #roi输出大小为7*7
out_channels=256, #roi输出通道数
featmap_strides=[4, 8, 16, 32]), #对应4个level的proposal
mask_roi_extractor=dict(
type='SingleRoIExtractor',
roi_layer=dict(type='RoIAlign', out_size=14, sample_num=2),
out_channels=256,
featmap_strides=[4, 8, 16, 32]),
|
在上面的配置参数可以看出,bbox_roi_extractor和mask_roi_extractor的roi_layer层类型都是SingleRoIExtractor。这个层的实现在mmdet/models/roi_extractors/single_level.py文件中。在FPN+RPN分别输出4个不同level的proposal,因此或生成4个对应的roi_layer,每个roi_layer输出的特征通道数out_channels=256。对于box,每个roi的大小为7x7;对于mask,每个roi的输出大小14x14。
经过ROI extractor操作之后就是bbox的回归和分类以及mask的生成分类。这部分的配置参数如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
bbox_head=dict(
type='SharedFCBBoxHead',
num_fcs=2, #2个全连接层
in_channels=256, #roi输出特征通道数
fc_out_channels=1024, #2个全连接层的节点数
roi_feat_size=7,
num_classes=81, #81个类别输出(80目标+1背景)
target_means=[0., 0., 0., 0.],
target_stds=[0.1, 0.1, 0.2, 0.2],
reg_class_agnostic=False),
mask_head=dict(
type='FCNMaskHead',
num_convs=4, #4个卷积层
in_channels=256, #roi输出特征通道数
conv_out_channels=256, #4个卷积层的通道数均为256
num_classes=81)) #mask的类别是81,
|
这一部分的实现对应于下图,该图截图自maskrcnn原文,如下图所示
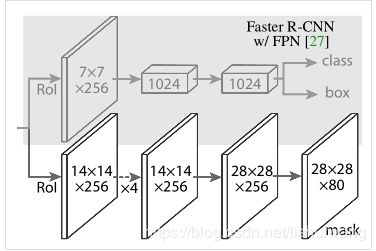
值得注意的是,在上面mask branch中倒数第二层应该是28x28x256的上采样层,在上面的参数配置中没有体现,但在mmdetection的代码有实现,可以看mmdet/models/mask_heads/fcn_mask_head.py中FCNMaskHead默认的上采样层类型是deconv,层的实现在第58行。
模型构建
上面根据模型配置文件结构介绍了构建maskrcnn模型的4个子模块,如何将这四个子模块拼接构成一个完整的maskrcnn模型?在mmdetecion中实例化一个具体模型,需要在mmdet/models/detectors/文件夹下中实现相应的模型,比如maskrcnn模型的实现在该文件夹下mask_rcnn.py文件中,实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
from .two_stage import TwoStageDetector
from ..registry import DETECTORS
@DETECTORS.register_module
class MaskRCNN(TwoStageDetector):
def __init__(self,
backbone,
neck,
rpn_head,
bbox_roi_extractor,
bbox_head,
mask_roi_extractor,
mask_head,
train_cfg,
test_cfg,
pretrained=None):
super(MaskRCNN, self).__init__(
backbone=backbone,
neck=neck,
rpn_head=rpn_head,
bbox_roi_extractor=bbox_roi_extractor,
bbox_head=bbox_head,
mask_roi_extractor=mask_roi_extractor,
mask_head=mask_head,
train_cfg=train_cfg,
test_cfg=test_cfg,
pretrained=pretrained)
|
从上面可以看出maskrcnn模型的构建继承自TwoStageDetector类。TwoStageDetector类是一个通用的two-stage目标检测方法的基类,具体实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 |
import torch
import torch.nn as nn
from .base import BaseDetector
from .test_mixins import RPNTestMixin, BBoxTestMixin, MaskTestMixin
from .. import builder
from ..registry import DETECTORS
from mmdet.core import bbox2roi, bbox2result, build_assigner, build_sampler
@DETECTORS.register_module
class TwoStageDetector(BaseDetector, RPNTestMixin, BBoxTestMixin,
MaskTestMixin):
#继承了四个基类BaseDetector(主要是一些模型常见训练,单多尺度测试相关操作的虚函数),RPNTestMixin,BBoxTestMixin,MaskTestMixin主要是模型单尺度/多尺度测试
def __init__(self,
backbone,
neck=None,
rpn_head=None,
bbox_roi_extractor=None,
bbox_head=None,
mask_roi_extractor=None,
mask_head=None,
train_cfg=None,
test_cfg=None,
pretrained=None):
super(TwoStageDetector, self).__init__()
self.backbone = builder.build_backbone(backbone) #根据配置文件构架backbone
if neck is not None:
self.neck = builder.build_neck(neck) #根据配置文件构架neck,这里主要是FPN
else:
raise NotImplementedError
if rpn_head is not None:
self.rpn_head = builder.build_head(rpn_head) #根据配置文件构架rpn
#根据配置文件构架bbox_roi_extractor,bbox_head
if bbox_head is not None:
self.bbox_roi_extractor = builder.build_roi_extractor(
bbox_roi_extractor)
self.bbox_head = builder.build_head(bbox_head)
#根据配置文件构架mask_roi_extractor,mask_head
if mask_head is not None:
self.mask_roi_extractor = builder.build_roi_extractor(
mask_roi_extractor)
self.mask_head = builder.build_head(mask_head)
self.train_cfg = train_cfg
self.test_cfg = test_cfg
#模型参数权重初始化
self.init_weights(pretrained=pretrained)
@property
def with_rpn(self):
return hasattr(self, 'rpn_head') and self.rpn_head is not None
def init_weights(self, pretrained=None):
super(TwoStageDetector, self).init_weights(pretrained)
self.backbone.init_weights(pretrained=pretrained)
if self.with_neck:
if isinstance(self.neck, nn.Sequential):
for m in self.neck:
m.init_weights()
else:
self.neck.init_weights()
if self.with_rpn:
self.rpn_head.init_weights()
if self.with_bbox:
self.bbox_roi_extractor.init_weights()
self.bbox_head.init_weights()
if self.with_mask:
self.mask_roi_extractor.init_weights()
self.mask_head.init_weights()
#提取特征(包括经过bakcbone,neck)
def extract_feat(self, img):
x = self.backbone(img)
if self.with_neck:
x = self.neck(x)
return x
def forward_train(self,
img,
img_meta,
gt_bboxes,
gt_bboxes_ignore,
gt_labels,
gt_masks=None,
proposals=None):
x = self.extract_feat(img)
losses = dict()
# RPN 前向计算和损失
if self.with_rpn:
rpn_outs = self.rpn_head(x)
rpn_loss_inputs = rpn_outs + (gt_bboxes, img_meta,
self.train_cfg.rpn)
rpn_losses = self.rpn_head.loss(*rpn_loss_inputs)
losses.update(rpn_losses)
proposal_inputs = rpn_outs + (img_meta, self.test_cfg.rpn)
proposal_list = self.rpn_head.get_bboxes(*proposal_inputs)
else:
proposal_list = proposals
# assign gts and sample proposals
if self.with_bbox or self.with_mask:
bbox_assigner = build_assigner(self.train_cfg.rcnn.assigner)
bbox_sampler = build_sampler(
self.train_cfg.rcnn.sampler, context=self)
num_imgs = img.size(0)
sampling_results = []
for i in range(num_imgs):
assign_result = bbox_assigner.assign(
proposal_list[i], gt_bboxes[i], gt_bboxes_ignore[i],
gt_labels[i])
sampling_result = bbox_sampler.sample(
assign_result,
proposal_list[i],
gt_bboxes[i],
gt_labels[i],
feats=[lvl_feat[i][None] for lvl_feat in x])
sampling_results.append(sampling_result)
# bbox head forward and loss
if self.with_bbox:
rois = bbox2roi([res.bboxes for res in sampling_results])
# TODO: a more flexible way to decide which feature maps to use
bbox_feats = self.bbox_roi_extractor(
x[:self.bbox_roi_extractor.num_inputs], rois)
cls_score, bbox_pred = self.bbox_head(bbox_feats)
bbox_targets = self.bbox_head.get_target(
sampling_results, gt_bboxes, gt_labels, self.train_cfg.rcnn)
loss_bbox = self.bbox_head.loss(cls_score, bbox_pred,
*bbox_targets)
losses.update(loss_bbox)
# mask head forward and loss
if self.with_mask:
pos_rois = bbox2roi([res.pos_bboxes for res in sampling_results])
mask_feats = self.mask_roi_extractor(
x[:self.mask_roi_extractor.num_inputs], pos_rois)
mask_pred = self.mask_head(mask_feats)
mask_targets = self.mask_head.get_target(
sampling_results, gt_masks, self.train_cfg.rcnn)
pos_labels = torch.cat(
[res.pos_gt_labels for res in sampling_results])
loss_mask = self.mask_head.loss(mask_pred, mask_targets,
pos_labels)
losses.update(loss_mask)
return losses
def simple_test(self, img, img_meta, proposals=None, rescale=False):
"""Test without augmentation."""
def aug_test(self, imgs, img_metas, rescale=False):
"""Test with augmentations. |