深度学习实战-从源码解密AlphGo Zero背后基本原理

(本文由深度学习与NLP编译)
DeepMind在强化学习领域具有非常重要的作用,其创造了举世震惊的AI智能AlphaGo,以及后来的AlphaGo Zero。这是第一个在19 x 19棋盘上打败人类职业围棋手的计算机程序。还击败了围棋世界冠军李世石、柯洁(当时世界排名第一的玩家)和许多其他排名靠前的玩家。围棋比赛是一个复杂且困难的比赛,因为它在每一步都具有非常大的分支因素,这使得经典的搜索技术如alpha-beta剪枝和启发式搜索都变得无用。本文原作者dylandjian对AlphaGo的工作进行了复现,在次,下文将尽可能详细地介绍复制的具体工作。阅读本文需要一些机器学习和Python方面的背景知识,也需要一点关于围棋的知识。
(文末付实战完整代码下载地址)
简介
本文参考了文章《This Amazing Info Graphic by David Foster》,按照Deep mind发表的论文《Mastering the game of Go without human knowledge》来构建篇文章的结构。
AlphaGo简介
整个AlphaGo Zero pipeline被分成三个主要部分,每个部分都有各自独立的代码。第一个组成部分负责Self-Play,负责生产训练数据。第二个组成部分是Training,通过self-play部分新生成的数据用于改进当前的最佳网络。最后一部分是Evaluation,它决定训练好的Agent是否优于当之前的Agent。最后一部分至关重要,因为生成的数据应该总是来自最好的可用网络,因为只有更好的Agent可以生产更优质的数据,用于去训练更好的Agent。
为了更好地理解这些部分是如何相互作用的,我将分别描述各个模块的构建,然后将它们组成一起,形成一个全局的系统。
The Environment
理想情况下,一个好的环境应该是一个可以玩得很快并且融合了围棋的所有规则( Atari、ko、Komi等)。经过一些研究,我偶然发现了OpenAI Gym提供一个由Pachi_py编写的现成的环境(一个旧版本的Board Environment),Pachi_py是一个与c++ Pachi GoEngine绑定的Python语言。经过以下几步调整后,现实可用的环境就可以使用了。
第一个调整是Agent的输入是board的一个special representation,如下图所示。该状态由黑子的当前位置作为二进制图( 1表示黑子,0表示其他)以及过去的7个board state组成。白子也做同样的处理并于黑子状态特征图concatenate一起作为Agent的输入。这主要是在ko的情况下完成的。
最后,添加一个满是0或1的map来表示哪个玩家将要走下一步。为了易于实现,所以采用这种方式表示,但它也可以用一个比特位来编码。

第二个调整是确保有可能与Engine一起玩,无论只有一个Agent在玩(self-play、online)还是两个player(evaluation或played with another agent)。此外,为了充分利用CPU的资源,必须修改代码,以便并行运行Engine的多个实例。
除了这些调整之外,代码还必须进行调整,以便能够使用Tromp - Taylor评分来准确估计比赛中的获胜者,以防比赛提前结束(这将在下面的训练部分中详细解释)。
。。。
The Agent
该Agent由三个协同工作的神经网络组成:特征提取器(Feature extractor)、策略网络(Policy Network)和价值网络(Value network)。这也是为什么AlphaGo Zero有时被称为“Two Headed Beast”:一个身体,它是特征提取器,两个脑袋:policy和value。特征提取器模型创建自己的board state表示。策略网络输出所有可能move的概率分布,价值模型(value model)模型预测一个[- 1,1]范围内的标量值,用于表示在一个给定的board state状态下,走那一步更容易获胜。策略和价值模型都使用特征提取器的输出作为输入。让我们看看它们实际上是如何工作的。
特征提取器
特征提取器模型由一个残差神经网络(Residual Neural Network)构成,一种特殊的卷积神经网络( CNN )。它的特殊性在于它在层与层之间采用skip connection。这种类型的连接在进行ReLU激活之前使用,将block的最后一个连接的输出与输入相加,如下图所示。

下面是是在代码中的定义:

定义好Residual Block之后,参考原始文章,将其加入到最终特征提取器模型中。

最终的网络仅仅是result或convolution layer,该层的输出被作为其他层的输入。
Policy Head
策略网络模型是一个简单的卷积网络(在特征提取器输出的channel上进行1×1卷积编码)、一个批处理归一化(batch normalization)层和一个全连接的层构成,该层的输出board上的概率分布,以及一个额外的pass move。


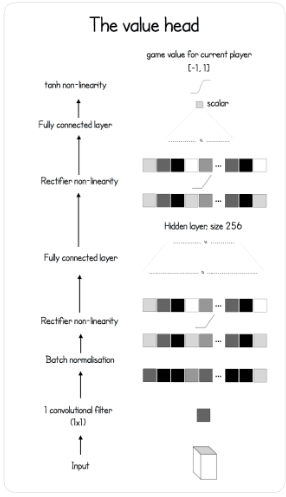
Value Head
价值网络模型更加复杂。它包含一个couple convolution、batch normalization、ReLU和一个全连接层,在此基础上增加了另一个完全连接的层构成。最后,应用双曲正切函数来输出一个[ - 1,1 ]的值,表示在当前游戏状态下玩家获胜的可能性。

蒙特卡罗树搜索
AlphaGo Zero的另一个主要组成部分是异步蒙特卡罗树搜索( MCTS )。这种树搜索算法是有用的,因为它使网络能够提前思考,并通过它所做的模拟选择最佳的move,而无需在每一步都探索所有节点。由于Go是一款完美的Information Game,有了完美的模拟器,就有可能模拟环境的状态,并像人类一样提前思考计划对手可能的反应。让我们看看这些步骤是如何做到的。
Node
树中的每个节点代表一个board state,并存储不同的统计数据:节点被访问的次数( n )、总的action value( w )、到达该节点的先验概率( p )、平均动作值( q,即q = w / n )以及从父节点到达该节点的move、指向父节点的指针,最后是从该节点开始的所有合法move,这些move拥有具有非零概率的子孩子(children)。

Rollout
PUCT选择算法
树搜索中的第一个action是选择最大化多项式上限树( Polynomial Upper Confidence Trees,PUCT )公式variant的action。借助探索常数(exploration constant)C_puct,网络可以在早期探索看不见的路径,或者在以后进一步搜索可能的最佳move。
选择公式定义如下。
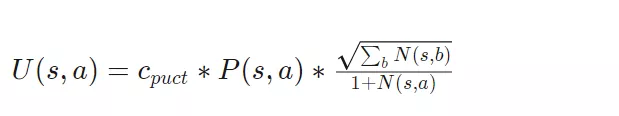
其中,P ( s,a )表示处于该状态的概率,N ( s,a )表示在模拟过程中访问该特定状态的次数。
下面表述在代码中如何定义和实现。这个版本的可读性稍差,因为它是使用numba优化的。

ENDING
Selection过程一直持续到达到一个叶子节点为止。叶子节点表示尚未扩展的节点,这意味着它没有子节点。

一旦遇到叶子节点,就使用值和策略网络来评估它包含的状态的random rotation或reflection(因为Go规则在rotation或reflection条件下是不变的,更多是针对训练部分),以获得当前状态的value和所有下一次move的概率。所有forbidden move的概率都变为0,然后概率向量被重新归一化为1。
在此之后,在给定节点状态的情况下,节点会随着每一次的合法move(在probas数组中具有非零概率的move)而扩展,其函数如下。

BACKUP
一旦expansion完成之后,节点及其父节点的统计信息将使用以下函数和loop以及值网络预测的值进行更新。

Move Selection
现在simulation部分就完成了,每一次潜在的下一次move都包含了描述move质量的统计数据。move的选择遵循两种情况。
第一种是AlphaGo进行competition的地方,所选的move是最优的simulated move。这种情况在除了evaluation和training之外的一般比赛中应用。
第二种情况是,通过使用以下方案将访问计数矩阵转换为概率分布,随机选择move。

这种选择方法允许AlphaGo在training期间早期探索更多潜在选项。经过一定量的move(temperature constant),move选择将变得有竞争力。
Final pipeline
现在已经分别解释了每一个单独的block,现在让我们把它们拼接起来看看AlphaGo实际上是如何训练的。
在项目开始时,至少启动了两个“核心”流程。第一个是self-play,第二个是training。理想情况下,两个进程都将通过RAM进行通信。然而,在不同的过程之间传递信息并不简单,在这种情况下,它将self-play过程中生成的游戏状态发送到训练过程中,以便用最佳质量的游戏数据来更新数据集,使Agent更快地从更好的游戏state中学习。为了做到这一点,本文将采用MongoDB数据库存储数据,使每个进程能够独立运行,同时只有一个真正的信息源。
Self-play
self-play部分负责生成数据。它通过使用当前最好的Agent来于自己对抗。游戏结束后(采用两个玩家模式,采用一人走一次或多次的模式进行play),游戏的每个registered动作都会随着游戏的获胜者而更新,从( board_state,move,player_color )变为( board_state,move,winner )。每次生成一个batch数据时,该过程都会验证用于生成游戏的当前Agent仍然是最佳Agent。下面的函数是如何进行self-play的一个rough sketch。

Training
Training则相对简单。使用新生成的游戏state数据训练当前最佳Agent。数据中的所有state都采用中使用均方的二面角旋转(dihedral rotations of a square)(旋转和对称)来扩充数据。每经过几次迭代,训练过程都会检查数据库,看看self-play过程是否已经生成了新的游戏数据,如果是,训练过程就会提取新的数据并更新相应的数据集。在经过几次迭代之后,训练好的Agent被异步发送到另一个过程中进行评估,如下面的函数所述。

用来训练agent的损失函数是游戏实际输赢值和预测值之间的均方差之和,以及move分布和预测概率分布之间的交叉熵构成的损失函数。它在代码中定义如下。

Evaluation
Evaluation由使用最新训练的agent与当前最优的Agent进行比赛。他们会互相玩一定数量的游戏,如果最新训练的的Agent在一定时间内打败了当前的最佳Agent(论文中55 %的时间),那么最新训练的Agent就会被保存下来,成为新的最佳Agent。

Results
在本地的服务器上训练了一周之后,Agent人在9x 9围棋棋盘上玩了大约20k个self-played的游戏,使用了128个MCTS模拟,并行玩了10个游戏,更新了大约463k参数,更换了417次最佳Agent。这是一段最佳agent与自己对战的片段。
视频显示,Agent并没有学习游戏的“基本原理”,比如life 和death,甚至Atari。然而,它似乎已经学习到answer locally似乎是一个很好的move。看起来agent也知道Go是关于territory,而不是正面作战的游戏,这在最初的几个动作中有所显示。Shapes也很糟糕,Agent仍然只在在自己的living groups中play,通过剥夺自由来杀死他们。
Discussion
最终没能获得一个不错的结果。这提出了一个问题,是否是在代码实现中除了错误,或者也许是使用了错误的超参数。AlphaGo Zero使用490万个游戏进行训练,但是模拟次数( 1600次)更高,所以较差的结果也可能是由于计算更新次数不够导致的。
参考文献
1. Mastering the game of Go without human knowledge—DeepMind
2. Very nice infographic on AlphaGo Zero - David Foster
3. Pachi Go game engine——佩特·鲍迪斯
本文所有代码
https://github.com/dylandjian/superGo
往期精彩内容推荐
《纯干货》2018-2019年国际AI会议最全信息整理分享
最新深度学习面试题目及答案集锦
模型汇总20-TACOTRON一种端到端的Text-to-Speech合成模型
纯干货10 强化学习视频教程分享(从入门到精通)
优化策略5 Label Smoothing Regularization_LSR原理分析
深度学习模型、概念思维导图分享
《模型汇总-20》深度学习背后的秘密:初学者指南-深度学习激活函数大全
《纯干货16》调整学习速率以优化神经网络训练
神经机器翻译(NMT)的一些重要资源分享
模型汇总22 机器学习相关基础数学理论、概念、模型思维导图分享