分布式数据存储原理简介
什么是分布式数据存储系统
分布式存储系统的核心逻辑,就是将用户需要存储的数据根据某种规则存储到不同的机器上,当用户想要获取指定数据时,再按照规则到存储数据的机器里获取。
如下图所示,当用户(即应用程序)想要访问数据 D,分布式操作引擎通过一些映射方式,比如 Hash、一致性 Hash、数据范围分类等,将用户引导至数据 D 所属的存储节点获取数据。
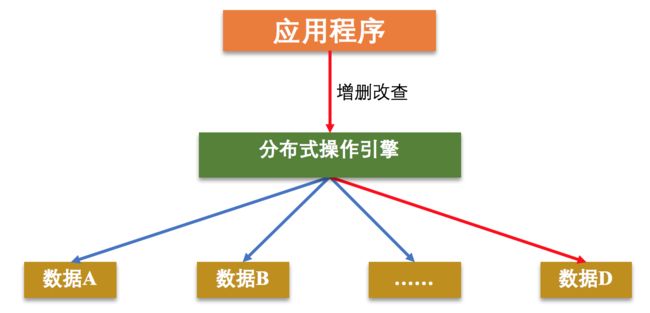
静下心来想一下,获取数据的整个过程与你到商店购物的过程是不是有些类似呢?
顾客到商店购物时,导购会根据顾客想要购买的商品引导顾客到相应的货架,然后顾客从这个货架上获取要购买的商品,完成购物。这里的顾客就是图中的应用程序,导购就相当于分布式操作引擎,它会按照一定的规则找到相应的货架,货架就是存储数据的不同机器节点。
其实,这个过程就是分布式存储系统中获取数据的通用流程,商品、导购和货架组成了分布式存储系统的三要素,分别对应着分布式领域中的数据(生产者 / 消费者)、数据索引和数据存储引擎。
分布式数据存储系统三要素
- 商品:数据模型
- 文件模型:hdfs(非结构化)
- 关系模型:结构化
- 键值模型:半结构化 hbase、google bigtable
- 导购:确定数据位置 (数据分片)
- 哈希分片
- 顺序分片
- 货架:数据存储引擎
- 哈希存储引擎
- B+树存储引擎
- LSM树存储引擎
分布式系统的基本概念
事情的根源:分布式系统的异常不可避免
由单机应用转变成分布式应用,必然引入网络因素,然而由于网络本身的不可靠性,导致分布式系统的通信也是不可靠的。并且由于分布式系统有多台廉价机器节点组成,其服务器节点也同样不可靠。举个极端的例子,一个集群有360台机器组成,平均每台机器一年出现一次故障,那么这个集群基本是不可用的。所以,分布式系统要解决的另一个核心问题是自动容错。
分布式系统带来的麻烦:数据一致性
上面说到分布式系统要解决的另一个核心问题是自动容错(高可用),那么对于分布式数据存储来说,怎么解决这个问题呢?
答案就是复制(数据副本)。将一份数据复制成多份,当某个副本所在的存储节点出现故障时,分布式存储系统能够自动的将服务切换到其他副本,从而实现自动容错。但是这也带来了另一个问题,如何确保多个副本之间的数据一致性。
如何理解数据一致性
上面说到,由于异常的存在分布式数据存储系统会将数据存储多份。可以这么认为,副本是分布式存储系统解决自动容错的唯一手段。但副本会带来数据一致性问题,那么怎么理解数据一致性呢?
首先,我们要从两个角度理解数据一致性:
第一个角度是用户,或者说是客户端,即客户端读写操作是否符合某种特性;第二个角度是存储系统,即存储系统的多个副本是否一致、更新的顺序是否相同。
从存储系统的角度看待数据一致性
对存储系统来说,一致性的含义是:多个副本之间的数据在同一个事务之后是否一致。怎么理解呢,比如client向一个分布式系统提交更新操作(同一个事务),分布式系统在执行更新操作并响应用户之后,所有节点存储的数据是一致的。
还有一个含义,更新顺序一致性:存储系统的多个副本之间是否按照相同的顺序执行更新操作。
从存储系统的角度来看,一致性包含两种情况:
- 强一致性:在一个事务内,主分片的数据与副本的数据一致。
- 同步复制
- Paxos(多节点写入)
- Raft(leader选举、日志复制)
- Zab
- 最终一致性:异步复制,在一个事务内,主数据一旦修改完成即返回客户端,数据复制到从数据是异步执行的。
由于同步复制对性能的影响很大,所以对于存储系统来说,一般都只要求最终一致性即可。比如:
- mysql 传统的主从集群
- redis 哨兵集群
- elasticsearch集群
这些对一致性的要求不高,如果是金融业务,涉及到钱,对一致性的要求很高就必须使用强一致性,比如:
- Mysql 三节点企业版 阿里云提供 基于raft协议
- MySQL官方的 Group Replication (MGR)方案 Mysql Group Replication
- zookeeper 基于zab协议
从用户(客户端)的角度看待数据一致性
对客户端来说,一致性的含义是:读操作能读到最新的写操作结果。一旦有写操作提交成功,其他的读操作都能读取到最新的写操作的结果。
从客户端的角度来看,一致性包含三种情况:
- 强一致性:确保读最新的读
- 弱一致性:不确保读最新的读
- 最终一致性:确保最终会读最新的读。对于这种情况,因为主数据与副本数据,副本与副本之间的数据都有可能不同,那客户端的读取方式就有不同的效果,这些不同的读取方式就形成了最终一致性的变体:
- 读写(Read-your-writes)一致性:读自己的写,凡是自己写的数据,都从主库读,凡是别人写的,都从从库读。
- 会话一致性
- 单调读:每个用户总是从同一个节点进行读取(不同的用户可以从不同的节点读取)
- 单调写
从客户端的角度来看,一般要求存储系统能够支持读写一致性、会话一致性、单调读、单调写等特性。
场景理解
上面的概念比较难理解,下面举例说明:
首先定义如下场景,
- 存储系统:分布式存储系统,有数据K,K有k1、k2两个副本,副本复制使用异步复制。
- 客户端A、B、C相互独立,均可对存储系统做读操作和写操作
可能出现的场景(从客户端的角度看)如下:
强一致性:
定义:
假如A先写入了一个k的值到存储系统,存储系统能够保证后续的A、B、C的读取都返回最新值。
实现方式:
我们发现,由于存储系统采用了异步复制(存储系统放弃了强一致性,保留了可用性),为了实现强一致性,对于某个数据(k或者主键),客户端读写操作都必须在同一台机器上,这个时候,对于客户端来说是强一致性的。但是,读写都在同一个分片上,那副本的价值体现在哪呢?这个时候,副本的价值只体现在高可用上面,如果主分片所在的机器节点挂了,系统会在副本中选一个升级为主分片,继续提供服务。
实现这种强一致性的数据库有:
- hbase hbase的一致性详解
- redis 哨兵集群:可能你会疑惑,上面说到redis哨兵集群对存储系统来说是最终一致的,但是因为客户端始终连接的是master节点,所以,对于客户端来说,redis哨兵集群是强一致性的。
hbase的每个值只会出现在一个region中(咋一看,hbase没有数据副本?),而region的存储实例HFile是存在于hdfs的,hbase的自动容错依赖于hdfs。当某一个RegionServer崩溃时,master会将这个rs上面的所有region分配给其他rs(因为region的数据存储在hdfs上,分配动作比较轻量级),继续提供服务。
弱一致性:
假如A先写入了一个值到存储系统,存储系统不能够保证后续的A、B、C的读取都返回最新值。
这种情况很麻烦,一般不会选择这种场景。
最终一致性:
最终一致性是弱一致性的一种特例。假如A先写入了一个值到存储系统,存储系统能够保证,A、B、C的读取操作“最终”都会读取到A所写入的最新值。“最终”一致性有一个“不一致窗口”的概念,它的大小取决于交互延迟以及复制协议要求同步的副本数。
实现最终一致性的数据库有:
- 主从复制的mysql集群,写主读从的情况。
- elasticsearch,写操作在主分片,读操作所有分片,所以可能出现主分片的数据还没有复制到副本分片的情况。
综上我们看出,对于大数据领域的大数据存储系统,因为数据量大,对性能的要求比较高,一般都会采用最终一致性。
CAP理论
根据CAP理论,我们知道在满足P(分区容错性)的情况下,C(强一致性)与A(可用性)只能二选一。
选CP策略放弃A:
- hbase
- redis哨兵集群
- Mysql 三节点企业版
- zookeeper
当master挂掉,需要选举新的master。这段时间系统是不能提供服务的。
选AP策略放弃C:
- Cassandra
- elasticsearch
- mysql传统主从集群
分布式一致性算法
首先,这些算法解决什么问题?
在分布式系统中,为了保证数据的高可用,通常我们会将数据保留多个副本,这些副本会放置在不同的物理的机器上。副本要保持一致,那么所有副本的更新序列也要保持一致。因为数据的增删改查操作一般都存在多个客户端并发操作,到底哪个客户端先做,哪个客户端后做,更新顺序要保证。
但是,在分布式环境中,网络是不可靠的,通信是不可靠的。比如说,数据库的主从拷贝,如果有一个副本的数据更新失败,那么在一个分布式系统中聚会出现两个不一致的值。分布式一致性算法就是为了解决这类问题。
- Paxos Paxos通俗解释
- Raft raft动画详解
- Zab
分布式数据存储系统的架构设计
数据存储引擎
数据存储引擎是存储系统的发动机,直接决定了存储系统的性能与功能。存储引擎的基本功能有:增、删、读、改,其中读取操作又分随机读和顺序扫描。
| 存储引擎 | 增删改 | 随机读取 | 顺序扫描 | 读写特征 | 数据库 |
|---|---|---|---|---|---|
| 哈希存储引擎 | 支持 | 支持 | 不支持 | 读写均很快 | redis |
| B+树存储引擎 | 支持 | 支持 | 支持 | 读快写慢 | mysql |
| LSM树存储引擎 | 支持 | 支持 | 支持 | 读慢写快 | hbase、levelDB |
存储引擎性能对比
哈希存储引擎
哈希存储引擎是哈希表的持久化实现,通过哈希函数直接定位到key的位置,所以随机读写很快,但是不支持顺序扫描。
B+树存储引擎
具体讲解可以参考 B+索引
我们只要知道,当写比读多时,LSM树相比于B+树有更好的性能,因为随着insert操作,为了维护B+树结构,节点分裂,时间复杂度相比读取更高一些,并且读磁盘的随机读写概率也会变大,性能会逐渐减弱。
LSM树存储引擎
LSM树本质上和B+树一样,是一种磁盘数据的索引结构。但和B+树不同的是,LSM树的索引对写入请求更友好。因为无论是何种写入请求,LSM树都会将写入操作处理为一次顺序写。
LSM树的索引一般由两部分组成,一部分是内存部分,一部分是磁盘部分。内存部分一般采用跳跃表来维护一个有序的KeyValue集合。磁盘部分一般由多个内部KeyValue有序的文件组成。
简单地说,LSM 的设计目标是提供比传统的 B+ 树更好的写性能。LSM 通过将磁盘的随机写转化为顺序写来提高写性能。
数据分布
分布式系统与单机系统的主要区别在于能将数据分布到多太机器上去,并在多台机器之间实现负载均衡。
数据分布的方式主要有两种:
- 哈希分布
- 普通哈希
- 一致性哈希
- 哈希槽
- 顺序分布:将每张表的数据按照主键排序,再进行分割,每台机器分配一定范围的数据。
负载均衡
负载均衡是分布式系统的必备功能,多个节点组成的分布式系统必须通过负载均衡机制保证各个节点之间负载的均衡性,一旦出现负载非常集中的情况,就很有可能导致对应的部分节点响应变慢,进而拖慢甚至拖垮整个集群。
在实际生产线环境中,负载均衡机制最重要的一个应用场景是系统扩容。分布式系统通过增加节点实现扩展性,但如果说扩容就是增加节点其实并不准确。扩容操作一般分为两个步骤:首先,需要增加节点并让系统感知到节点加入;其次,需要将系统中已有节点负载迁移到新加入节点上。第二步负载迁移在具体实现上需要借助于负载均衡机制。
在分布式数据库的设计中,负载均衡主要体现在数据上,数据的分布,数据本身的读写负载。比如,hbase级就有两种策略:SimpleLoadBalancer策略和StochasticLoadBalancer策略。
- SimpleLoadBalancer:保证每个RegionServer的Region个数基本相等
- StochasticLoadBalancer:StochasticLoadBalancer策略相比SimpleLoadBalancer策略更复杂,它对于负载的定义不再是Region个数这么简单,而是由多种独立负载加权计算的复合值,这些独立负载包括:
- Region个数
- Region负载
- 读请求数
- 写请求数
- Storefile大小
一致性与可用性
上面的CAP理论我们都知道,在满足P的情况下,CA只能选择一个。
如果采取强同步复制,保证了存储系统的一致性,然而,当主备副本之间出现故障时,写操作将被阻塞,系统的可用性无法得到满足。如果采用异步复制,虽然保证了存储系统的可用性,但无法做到强一致性。
存储系统设计时需要在一致性与可用性直接做权衡。例如,现在大多数的分布式系统的数据复制都有三种模式可选:
- 最大保护模式:强同步复制模式,写操作要求主库同步复制至少一个备库才返回客户端。
- 最大性能模式:异步复制。
- 最大可用模式:上面两种模式的折衷。正常情况下相当于最大保护模式,如果主备之间出现网络问题,则切换成最大性能模式。
hbase强一致性的特殊性
这里特别介绍一下hbase,hbase的底层数据存储依赖hdfs,并且hbase的同一个数据只会出现在一个region。hbase数据的容错依赖hdfs的多副本。
自动容错
集群规模越大,故障发生的概率就越大,当集群的规模大到一定程度,故障基本每天都会发生。所以,自动容错是分布式存储系统设计的重要目标。
想要做到自动容错,首先要先发现故障,然后再将错误节点的数据迁移到其他正常的节点。所以,自动容错包含两部分:
- 故障检测:故障检测使用租约(Lease协议) 分布式系统理论之租约机制学习
- 故障恢复:当master检测到datenode发送故障时,会将服务迁移到其他正常的datenode。
hbase的读写流程
hbase的寻址流程

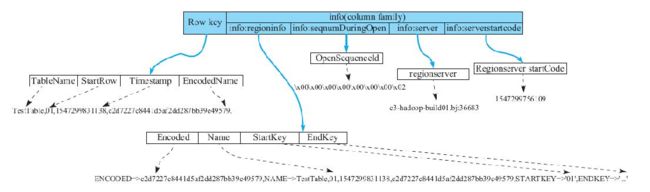
hbase的meta结构
Region写入流程
